
原文标题:What Your Computer Does While You Wait
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
本文以一个现代的、实际的个人电脑为对象,分析其中CPU(Intel Core 2 Duo 3.0GHz)以及各类子系统的运行速度——延迟和数据吞吐量。通过粗略的估算PC各个组件的相对运行速度,希望能给大家留下一个比较直观的印象。本文中的数据来自实际应用,而非理论最大值。时间的单位是纳秒(ns,十亿分之一秒),毫秒(ms,千分之一秒),和秒(s)。吞吐量的单位是兆字节(MB)和千兆字节(GB)。让我们先从CPU和内存开始,下图是北桥部分:
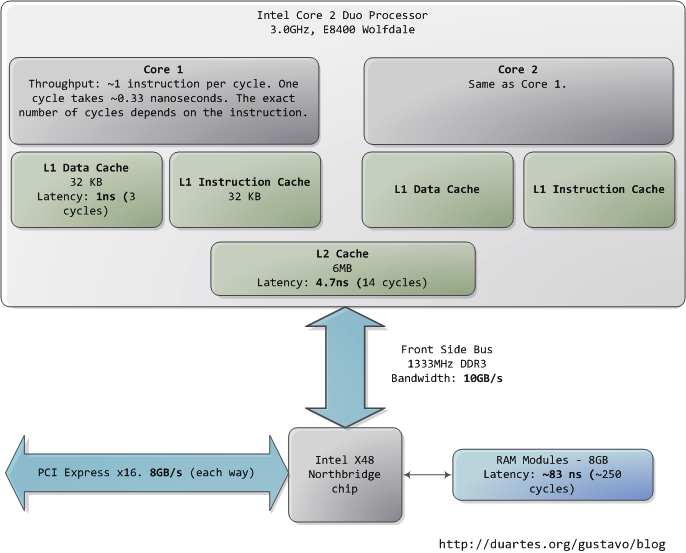
第一个令人惊叹的事实是:CPU快得离谱。在Core 2 3.0GHz上,大部分简单指令的执行只需要一个时钟周期,也就是1/3纳秒。即使是真空中传播的光,在这段时间内也只能走10厘米(约4英寸)。把上述事实记在心中是有好处的。当你要对程序做优化的时候就会想到,执行指令的开销对于当今的CPU而言是多么的微不足道。
当CPU运转起来以后,它便会通过L1 cache和L2 cache对系统中的主存进行读写访问。cache使用的是静态存储器(SRAM)。相对于系统主存中使用的动态存储器(DRAM),cache读写速度快得多、造价也高昂得多。cache一般被放置在CPU芯片的内部,加之使用昂贵高速的存储器,使其给CPU带来的延迟非常低。在指令层次上的优化(instruction-level optimization),其效果是与优化后代码的大小息息相关。由于使用了高速缓存技术(caching),那些能够整体放入L1/L2 cache中的代码,和那些在运行时需要不断调入/调出(marshall into/out of)cache的代码,在性能上会产生非常明显的差异。
正常情况下,当CPU操作一块内存区域时,其中的信息要么已经保存在L1/L2 cache,要么就需要将之从系统主存中调入cache,然后再处理。如果是后一种情况,我们就碰到了第一个瓶颈,一个大约250个时钟周期的延迟。在此期间如果CPU没有其他事情要做,则往往是处在停机状态的(stall)。为了给大家一个直观的印象,我们把CPU的一个时钟周期看作一秒。那么,从L1 cache读取信息就好像是拿起桌上的一张草稿纸(3秒);从L2 cache读取信息则是从身边的书架上取出一本书(14秒);而从主存中读取信息则相当于走到办公楼下去买个零食(4分钟)。
主存操作的准确延迟是不固定的,与具体的应用以及其他许多因素有关。比如,它依赖于列选通延迟(CAS)以及内存条的型号,它还依赖于CPU指令预取的成功率。指令预取可以根据当前执行的代码来猜测主存中哪些部分即将被使用,从而提前将这些信息载入cache。
看看L1/L2 cache的性能,再对比主存,就会发现:配置更大的cache或者编写能更好的利用cache的应用程序,会使系统的性能得到多么显著的提高。如果想进一步了解有关内存的诸多信息,读者可以参阅Ulrich Drepper所写的一篇经典文章《What Every Programmer Should Know About Memory》。
人们通常把CPU与内存之间的瓶颈叫做冯·诺依曼瓶颈(von Neumann bottleneck)。当今系统的前端总线带宽约为10GB/s,看起来很令人满意。在这个速度下,你可以在1秒内从内存中读取8GB的信息,或者10纳秒内读取100字 节。遗憾的是,这个吞吐量只是理论最大值(图中其他数据为实际值),而且是根本不可能达到的,因为主存控制电路会引入延迟。在做内存访问时,会遇到很多零 散的等待周期。比如电平协议要求,在选通一行、选通一列、取到可靠的数据之前,需要有一定的信号稳定时间。由于主存中使用电容来存储信息,为了防止因自然 放电而导致的信息丢失,就需要周期性的刷新它所存储的内容,这也带来额外的等待时间。某些连续的内存访问方式可能会比较高效,但仍然具有延时。而那些随机 的内存访问则消耗更多时间。所以延迟是不可避免的。
图中下方的南桥连接了很多其他总线(如:PCI-E, USB)和外围设备:
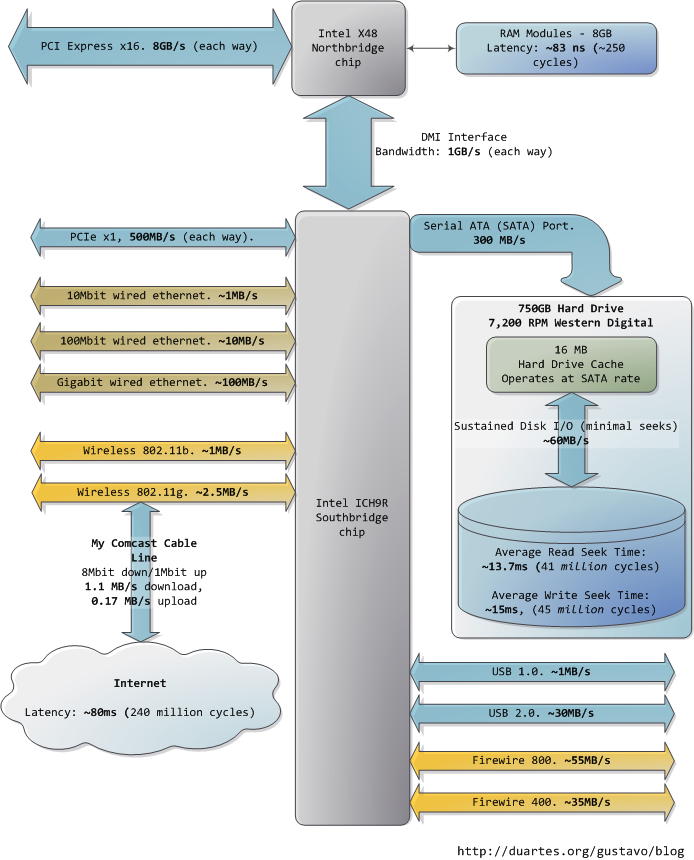
令人沮丧的是,南桥管理了一些反应相当迟钝的设备,比如硬盘。就算是缓慢的系统主存,和硬盘相比也可谓速度如飞了。继续拿办公室做比喻,等待硬盘寻道的时间相当于离开办公大楼并开始长达一年零三个月的环球旅行。这就解释了为何电脑的大部分工作都受制于磁盘I/O,以及为何数据库的性能在内存缓冲区被耗尽后会陡然下降。同时也解释了为何充足的RAM(用于缓冲)和高速的磁盘驱动器对系统的整体性能如此重要。
虽然磁盘的"连续"存取速度确实可以在实际使用中达到,但这并非故事的全部。真正令人头疼的瓶颈在于寻道操作,也就是在磁盘表面移动读写磁头到正确的磁道上,然后再等待磁盘旋转到正确的位置上,以便读取指定扇区内的信息。RPM(每分钟绕转次数)用来指示磁盘的旋转速度:RPM越大,耽误在寻道上的时间就越少,所以越高的RPM意味着越快的磁盘。这里有一篇由两个Stanford的研究生写的很酷的文章,其中讲述了寻道时间对系统性能的影响:《Anatomy of a Large-Scale Hypertextual Web Search Engine》
当 磁盘驱动器读取一个大的、连续存储的文件时会达到更高的持续读取速度,因为省去了寻道的时间。文件系统的碎片整理器就是用来把文件信息重组在连续的数据块 中,通过尽可能减少寻道来提高数据吞吐量。然而,说到计算机实际使用时的感受,磁盘的连续存取速度就不那么重要了,反而应该关注驱动器在单位时间内可以完 成的寻道和随机I/O操作的次数。对此,固态硬盘可以成为一个很棒的选择。
硬盘的cache也有助于改进性能。虽然16MB的cache只能覆盖整个磁盘容量的0.002%,可别看cache只有这么一点大,其效果十分明显。它可以把一组零散的写入操作合成一个,也就是使磁盘能够控制写入操作的顺序,从而减少寻道的次数。同样的,为了提高效率,一系列读取操作也可以被重组,而且操作系统和驱动器固件(firmware)都会参与到这类优化中来。
最后,图中还列出了网络和其他总线的实际数据吞吐量。火线(fireware)仅供参考,Intel X48芯片组并不直接支持火线。我们可以把Internet看作是计算机之间的总线。去访问那些速度很快的网站(比如google.com),延迟大约45毫秒,与硬盘驱动器带来的延迟相当。事实上,尽管硬盘比内存慢了5个数量级,它的速度与Internet是在同一数量级上的。目前,一般家用网络的带宽还是要落后于硬盘连续读取速度的,但"网络就是计算机"这句话可谓名符其实。如果将来Internet比硬盘还快了,那会是个什么景象呢?
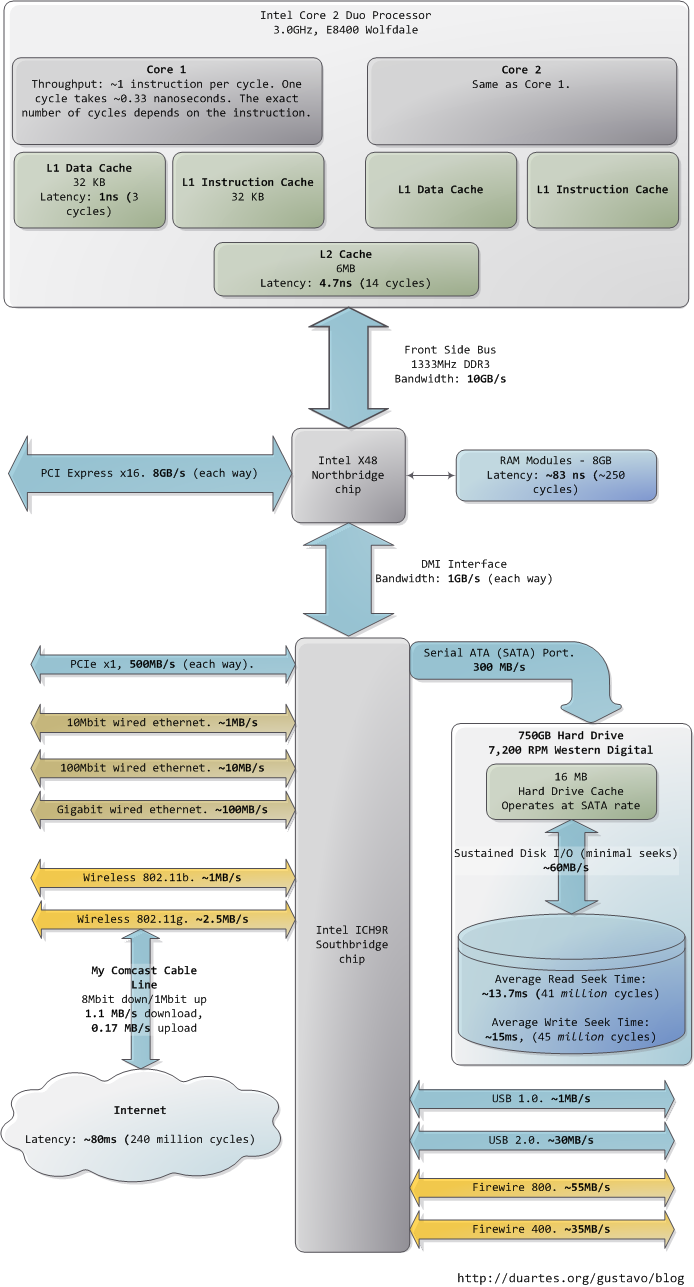
我希望这些图片能对您有所帮助。当这些数字一起呈现在我面前时,真的很迷人,也让我看到了计算机技术发展到了哪一步。前文分开的两个图片只是为了叙述方便,我把包含南北桥的整张图片也贴出来,供您参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号