

一:GitHub项目地址
https://github.com/syysumuro/WordCount
二:Personal Software Process(PSP)
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
| .Planning | 计划 | 10 | 10 |
| .Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| .Development | 开发 | 400 | 500 |
| .Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| .Design Spec | 生成设计文档 | 30 | 40 |
| .Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 40 |
| .Design | 具体计划 | 30 | 30 |
| .Coding | 具体编码 | 400 | 450 |
| .Coding Review | 代码复审 | 60 | 80 |
| .Test | 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| .Reporting | 报告 | 60 | 120 |
| .Test Report | 测试报告 | 60 | 70 |
| .Size Measurement | 计算工作量 | 20 | 15 |
|
.Postmortem & Process Improvement Plan
|
事后总结,并提出过程改进计划 | 15 | 15 |
| 合计 | 1285 | 1490 |
三:解题思路
如何思考:
拿到这个题目,第一反应是,程序需求说明过于复杂,并且有很多遗漏点。但是不妨碍初步分析题目。总体来说,这是一个对基于java对文件进行操作的一个程序。基本功能和附加功能可以实现,但是图形界面在这么有限的时间(对于要完成软件文档写作的我只有两天)基本上是不可能的。所以整体思路如下:
1:完成基本功能,统计字符数,行数和单词数,GitHub提交一次
2:完成附加三个功能,递归处理文件,统计代码行数/空白行数/注释行数,GitHub提交一次
3:完善程序,生成.exe,GitHub提交最终项目
如何查找资料:
主要在博客园,CSDN查找文件处理相关的函数,以及正则表达式的使用,文末有连接。
四:程序设计实现过程
由于这个程序整体上看并不复杂因此在整个项目中只设计了一个类以及六个功能函数和调用功能函数的main函数WordCount
1:类:class WordCount
2:函数:
public static void wc(InputStream f):完成基本功能,统计字符数,单词数和行数
public static void keepParam(String args[]):完成main函数参数的分析,即分析用户需求
public static void printResult(String fileName):打印出结果,并将结果输出到指定文
public static void readAllFile(String fileDir):递归解析文件目录
public static void codeCount(File f):统计代码行数,空白行数,注释行数
public static void countStopList(String fileName):统计停用单词数
public static void main(String args[]):主函数,调用功能函数完成统计工作
3:函数之间的关系图:
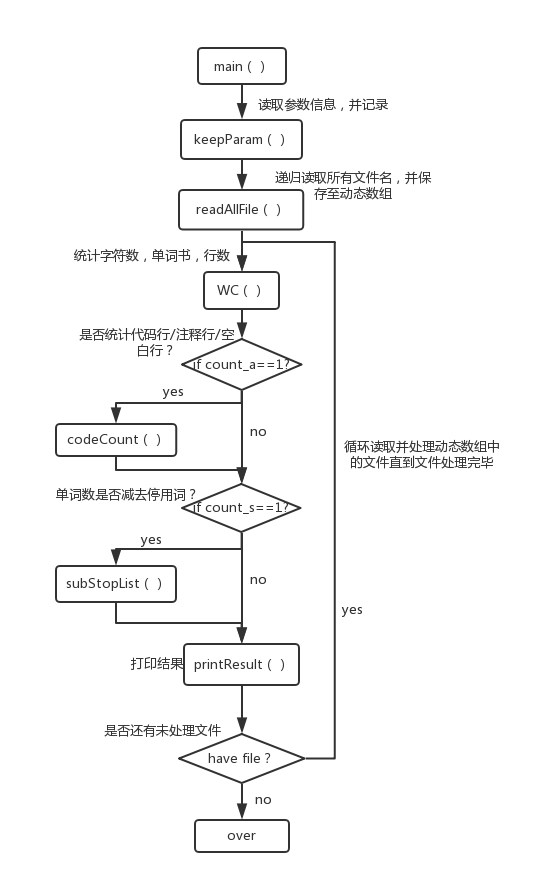
五:关键代码说明
完成基本功能函数:WC()
函数说明:一切字符(可显非可显)均统计在内,enter键盘统计为两个字符\n\r
空白行以及只有一个字符的行数都算作一行,没有字符的文件,初始化行数为一
以空格和逗号分隔开的均为单词,不做单词正确性检测
public static void wc(InputStream f) throws IOException { int c = 0; int last = 0;//用来记录上一个字符 boolean lastNotWhite = false;//记录前一个字符是否为合法字符,即非分隔符,用来排除两个空格统计为两个单词的情况 while ((c = f.read()) != -1) { chars++;//读到字符,字符数加一 if (c == '\n')//换行符,行数加一 { lines++; } if (last != ' ' && last != ',' && last != 0 && last != '\t' && last != '\r') { lastNotWhite = true; } else lastNotWhite = false; //如果为单词分隔符,且前一个为非空格,‘,’,换行,tab字符,则为一个单词 if ((c == ' ' || c == ',' || c == '\t' || c == '\r') && lastNotWhite == true) words++; last = c; } if ((c == -1 && last != '\n')) { words++; if (c == -1 && last == 0)//如果后续无字符,且last为0,则单词统计多一,需减去 words--; } }
递归读取文件函数:readAllFile()
函数说明:递归读取某个目录下的所有文件
//传入参数为文件或者目录名 public static void readAllFile(String fileDir){ File file=new File(fileDir); //如果为目录 if(file.isDirectory()){ File[]files=file.listFiles(); //处理此目录下的每一个文件或者文件夹 for(File fileIndex:files){ //如果目录下为目录则递归处理 if(fileIndex.isDirectory()){ readAllFile(fileIndex.getPath()); }else{ fileList.add(fileIndex);//为文件时,将文件名添加至记录所以文件的动态数组中 } } }else{ singleFile=1;//如果主函数传的文件名为文件而非目录,则记录为单个文件 } }
附加功能函数:codeCount()
函数说明:统计空白行,去掉空白字符,字符数小于或者等于一的为空白行
注释行统计//或者块注释/**/之内的行都为注释行
除去注释行和空白行的为代码行
//统计空白行,注释行和代码行 public static void codeCount(File f) { BufferedReader br = null; boolean comment = false; try { br = new BufferedReader(new FileReader(f)); String line = null;//记录读取到的每一行 while ((line = br.readLine()) != null) { line = line.trim(); if (line.length()==0) { blankLines++;//匹配空白行正则表达式成功,则空白行统计加一 } else if (line.startsWith("/*") && !line.endsWith("*/")) { noteLines++;//匹配块注释正则表达式成功,则块注释统计加一 comment = true; } else if (line.startsWith("/*") && line.endsWith("*/")) { noteLines++;//单行使用/**/注释的情况 } else if (true == comment) { noteLines++; if (line.endsWith("*/")) { comment = false; } } else if (line.startsWith("//")) { noteLines++;//单行注释,注释行数加一 } else { codeLines++;//上述都不成立则代码行数加一 } } } catch (FileNotFoundException e) {//错误处理 e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (br != null) { try { br.close(); br = null; } catch (IOException e) { e.printStackTrace(); } } } }
words个数减去停用词个数:subStopList()
函数说明:使用正则匹配来匹配读入的句子中是否有stopList中的单词,查到一个在原有的words个数基础上减一
public static void subStopList(File inputFile){ try { /*读入停用词,并用一个动态数组存放*/ //读待统计文件 BufferedReader br = null; try { br = new BufferedReader(new FileReader(inputFile)); } catch (FileNotFoundException e) { e.printStackTrace(); } String line;//存放读取的一行 try { while ((line = br.readLine()) != null) { line = line.trim(); //去掉字符串前后的空白 for (String stopWord : stopWords) { //遍历停用词表中的每个词 Pattern pattern[] = new Pattern[4]; pattern[0] = Pattern.compile("(\\s|,)" + stopWords + "(\\s|,)");//左右有间隔 for (int i = 0; i < 4; i++) { m[i] = pattern[i].matcher(line); } for (int i = 0; i < 4; i++) { //匹配 while (m[i].find()) { words--; } } } } }catch (IOException e) { e.printStackTrace(); } }
六:测试设计过程
测试原理:此次测试,我主要编写了十个个测试用例来完成测试工作。五个测试用例分别在五个.txt文件中,五个测试用例覆盖了程序可能执行的所有路径,并且设置了对所有我能考虑到的边界值的测试
一:高风险点分析
1.对于特殊字符的统计,如:转义字符'\t','\n','\r'等。
2.对于一行中首尾单词的统计
3.对于不同分隔符分割的单词的统计
4.对于特殊注释行与代码行的区别
5.对于连续空行的统计
6.对于大容量文件的统计
二:对于测试用例的设计
1:test1.txt:仅一个单词,并且为停用词
if
2:test2.txt:仅一个单词,但此单词为非停用词
apple
3:test3.txt:四行,if和while为停用词,且包含了停用词的所有情况:前后无间隔,前后有间隔,仅前有间隔,仅后有间隔
while
a if
if a
a if a
4:test4.txt:五行,分别为两种形式的注释行,一个空行,一个代码行
//a b
/*a b
c d*/
a b c d
5:test5.txt:一个超级伪代码,包含了基本功能和附加功能的测试
int main(){
int a,b;
a=1;
//abcd
/*ab
cd*/
if(hhh)
}
6:test6.txt:特殊符号
@#¥% &
*
7:test7.txt
first word last(此处有换行)
8:test8.txt
word1 word2,word3,word4 word5(此处为空格)
9:test9.txt
sfdsff//codeline
{//commomline
dsafsdg
codeline*/
/*commomline
commomline
commomline*/
10:test10.txt
this is line1
this is line4
11:test11.txt(导入一个超过10000行的文件)
七:参考文献
[1]:http://blog.csdn.net/magic_jss/article/details/51472205
[2]:http://www.runoob.com/java/java-regular-expressions.html
[3]:https://www.cnblogs.com/xyou/p/7427779.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号