


快速排序的基本思想是,通过一轮的排序将序列分割成独立的两部分,其中一部分序列的关键字(这里主要用值来表示)均比另一部分关键字小。继续对长度较短的序列进行同样的分割,最后到达整体有序。在排序过程中,由于已经分开的两部分的元素不需要进行比较,故减少了比较次数,降低了排序时间。
详细描述:首先在要排序的序列 a 中选取一个中轴值,而后将序列分成两个部分,其中左边的部分 b 中的元素均小于或者等于 中轴值,右边的部分 c 的元素 均大于或者等于中轴值,而后通过递归调用快速排序的过程分别对两个部分进行排序,最后将两部分产生的结果合并即可得到最后的排序序列。
“基准值”的选择有很多种方法。最简单的是使用第一个记录的关键字值。但是如果输入的数组是正序或者逆序的,就会将所有的记录分到“基准值”的一边。较好的方法是随机选取“基准值”,这样可以减少原始输入对排序造成的影响。但是随机选取“基准值”的开销大。
为了实现一次划分,我们可以从数组(假定数据是存在数组中)的两端移动下标,必要时交换记录,直到数组两端的下标相遇为止。为此,我们附设两个指针(下角标)i 和 j, 通过 j 从当前序列的有段向左扫描,越过不小于基准值的记录。当遇到小于基准值的记录时,扫描停止。通过 i 从当前序列的左端向右扫描,越过小于基准值的记录。当遇到不小于基准值的记录时,扫描停止。交换两个方向扫描停止的记录 a[j] 与 a[i]。 然后,继续扫描,直至 i 与 j 相遇为止。扫描和交换的过程结束。这是 i 左边的记录的关键字值都小于基准值,右边的记录的关键字值都不小于基准值。
通过两个不相邻元素交换,可以一次交换消除多个逆序,加快排序速度。快速排序方法在要排序的数据已经有序的情况下最不利于发挥其长处。
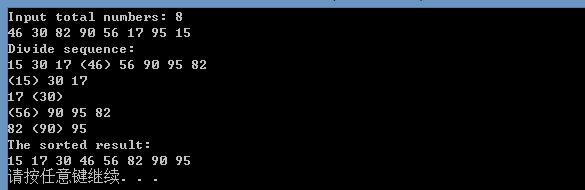
下面我们通过一个案例来演示一下快速排序的基本步骤: 以序列 46 30 82 90 56 17 95 15 共8个元素
初始状态: 46 30 82 90 56 17 95 15 选择46 作为基准值,i = 0, j = 7
i = 0 j = 7
15 30 82 90 56 17 95 46 15 < 46, 交换 15 和 46,移动 i, i = 1
i = 1 j = 7
15 30 82 90 56 17 95 46 30 < 46, 不需要交换,移动 i , i = 2
i = 2 j = 7
15 30 46 90 56 17 95 82 82 > 46, 交换82 和 46,移动 j , j = 6
i = 2 j = 6
15 30 46 90 56 17 95 82 95 > 46, 不需要交换,移动 j , j = 5
i = 2 j = 5
15 30 17 90 56 46 95 82 17 < 46, 交换46 和 17,移动 i, i = 3
i = 3 j = 5
15 30 17 46 56 90 95 82 90 > 46, 交换90 和 46,移动 j , j = 4
3 = i j = 4
15 30 17 46 56 90 95 82 56 > 46, 不需要交换,移动 j , j = 3
i = j = 3
i = j = 3, 这样序列就这样分割成了两部分,左边部分{15, 30, 17} 均小于 基准值(46);右边部分 {56, 90,95,82},均大于基准值。这样子我们就达到了分割序列的目标。在接着对子序列用同样的办法进行分割,直至子序列不超过一个元素,那么排序结束,整个序列处于有序状态。
参考代码:


1 #include <stdio.h> 2 3 #define MAX_NUM 80 4 5 void quicksort(int* a, int p,int q) 6 { 7 int i = p; 8 int j = q; 9 int temp = a[p]; 10 11 while(i < j) 12 { 13 // 越过不小于基准值的数据 14 while( a[j] >= temp && j > i ) j--; 15 16 if( j > i ) 17 { 18 a[i] = a[j]; 19 i++; 20 21 // 越过小于基准值的数据 22 while(a[i] <= temp && i < j ) i++; 23 if( i < j ) 24 { 25 a[j] = a[i]; 26 j--; 27 } 28 } 29 } 30 a[i] = temp; 31 32 for(int k = p; k <= q;k++) 33 { 34 if( k == i ) 35 { 36 printf("(%d) ",a[k]); 37 continue; 38 } 39 printf("%d ",a[k]); 40 } 41 printf("\n"); 42 43 if( p < (i-1)) quicksort(a,p,i-1); 44 if((j+1) < q ) quicksort(a,j+1,q); 45 } 46 47 int main(int argc, char* argv[]) 48 { 49 int a[MAX_NUM]; 50 int n; 51 52 printf("Input total numbers: "); 53 scanf("%d",&n); 54 55 if( n > MAX_NUM ) n = MAX_NUM; 56 57 for(int i = 0; i < n;i++) 58 { 59 scanf("%d",&a[i]); 60 } 61 62 printf("Divide sequence:\n"); 63 quicksort(a,0,n-1); 64 65 printf("The sorted result:\n"); 66 for(int i = 0; i < n;i++) 67 { 68 printf("%d ",a[i]); 69 } 70 printf("\n"); 71 72 73 74 return 0; 75 }
案例运行结果:(注:括号内表示的是基准值)
快速排序算法效率与稳定性分析
当基数值不能很好地分割数组,即基准值将数组分成一个子数组中有一个记录,而另一个子组组有 n -1 个记录时,下一次的子数组只比原来数组小 1,这是快速排序的最差的情况。如果这种情况发生在每次划分过程中,那么快速排序就退化成了冒泡排序,其时间复杂度为O(n2)。
如果基准值都能讲数组分成相等的两部分,则出现快速排序的最佳情况。在这种情况下,我们还要对每个大小约为 n/2 的两个子数组进行排序。在一个大小为 n 的记录中确定一个记录的位置所需要的时间为O(n)。若T(n)为对n个记录进行排序所需要的时间,则每当一个记录得到其正确位置,整组大致分成两个相等的两部分时,我们得到快速排序算法的最佳时间复杂性。
T(n) <= cn + 2T(n/2) c是一个常数
<= cn + 2(cn/2+2T(n/4)) = 2cn+ 4T(n/4)
<= 2cn + 4(cn/4+ 2T(n/8)) = 3cn + 8T(n/8)
…… ……
<= cnlogn + nT(1) = O(nlogn) 其中cn 是一次划分所用的时间,c是一个常数
最坏的情况,每次划分都得到一个子序列,时间复杂度为:
T(n) = cn + T(n-1)
= cn + c(n-1) + T(n - 2) = 2cn -c + T(n-2)
= 2cn -c + c(n - 2) + T(n-3) = 3cn -3c + T(n-3)
……
= c[n(n+1)/2-1] + T(1) = O(n2)
快速排序的时间复杂度在平均情况下介于最佳与最差情况之间,假设每一次分割时,基准值处于最终排序好的位置的概率是一样的,基准值将数组分成长度为0 和 n-1,1 和 n-2,……的概率都是 1/n。在这种假设下,快速排序的平均时间复杂性为:
T(n) = cn + 1/n(T(k)+ T(n-k-1)) T(0) = c, T(1) = c
这是一个递推公式,T(k)和T(n-k-1)是指处理长度为 k 和 n-k-1 数组是快速排序算法所花费的时间, 根据公式所推算出来的时间为 O(nlogn)。因此快速排序的平均时间复杂性为O(nlogn)。
快速排序需要栈空间来实现递归,如果数组按局等方式被分割时,则最大的递归深度为 log n,需要的栈空间为 O(log n)。最坏的情况下在递归的每一级上,数组分割成长度为0的左子数组和长度为 n - 1 的右数组。这种情况下,递归的深度就成为 n,需要的栈空间为 O(n)。
因为快速排序在进行交换时,只是根据比较基数值判断是否交换,且不是相邻元素来交换,在交换过程中可能改变相同元素的顺序,因此是一种不稳定的排序算法。
注:主要参考彭军、向毅主编的 《数据结构与算法》

