
------------恢复内容开始------------
1.IMDB数据集
该数据集包含来自互联网电影数据库(IMDB)的 50 000 条严重两极分
化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试
集都包含 50% 的正面评论和 50% 的负面评论
1.1加载数据集
from tensorflow.keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
第一次运行代码会下载该数据集
参数 num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。低频单
词将被舍弃。这样得到的向量数据不会太大,便于处理。
1.2准备数据
你不能将整数序列直接输入神经网络。你需要将列表转换为张量
转换方法:对列表进行 one-hot 编码,将其转换为 0 和 1 组成的向量。举个例子,序列 [3, 5] 将会
被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。然后网络第
一层可以用 Dense 层,它能够处理浮点数向量数据
import numpy as np
def vectorize_sequences(sequences,dimension=10000): #创建一个形状为【len(sequences),dimension】 results = np.zeros((len(sequences),dimension)) for i,sequence in enumerate(sequences): result[i,sequence] = 1. return results x_train = vectorize_sequences(train_data) #训练数据向量化 x_test = vectorize_sequences(test_data) #测试数据向量化 #标签向量化 y_train = vectorize_sequences(train_labels) y_test = vectorize_sequences(test_labels)
1.3 构建网络
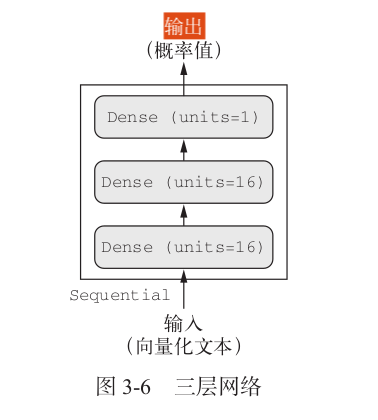
from tensorflow.keras import models #构建模型 from tensorflow.keras import layers
model = models.Sequential() #模型·定义 model.add(layers.Dense(16,activation='relu',input_shape=(10000,))) model.add(layers.Dense(16,activation='relu')) model.add(layers.Dense(1,activation='sigmoid'))
最后,你需要选择损失函数和优化器。由于你面对的是一个二分类问题,网络输出是一
个概率值(网络最后一层使用 sigmoid 激活函数,仅包含一个单元),那么最好使用 binary_
crossentropy (二元交叉熵)损失。这并不是唯一可行的选择,比如你还可以使用 mean_
squared_error (均方误差)。但对于输出概率值的模型,交叉熵(crossentropy)往往是最好
的选择。交叉熵是来自于信息论领域的概念,用于衡量概率分布之间的距离,在这个例子中就
是真实分布与预测值之间的距离。
1.4编译模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'] )
1.5配置优化器
from tensorflow.keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr = 0.001), loss = 'binary_crossentropy', metrics=['accuracy'] )
1.6使用自定义的损失和指标
可以这个上面1.4,1.5的代码
from tensorflow.keras import losses #使用自定义的损失和指标 from tensorflow.keras import metrics
model.compile(optimizer = optimizers.RMSprop(lr=0.001), loss = losses.binary_crossentropy, metrics=[metrics.binary_accuracy] )
1.7留出验证集
x_val = x_train[:10000] #为了在训练过程中监控模型在前所未见的数据上的精度,你需要将原始训练数据留出10000 #个样本作为验证集。 partial_x_train = x_train[10000:] y_val = y_train[:10000] partial_y_train = y_train[10000:]
1.8训练模型
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val,y_val) )
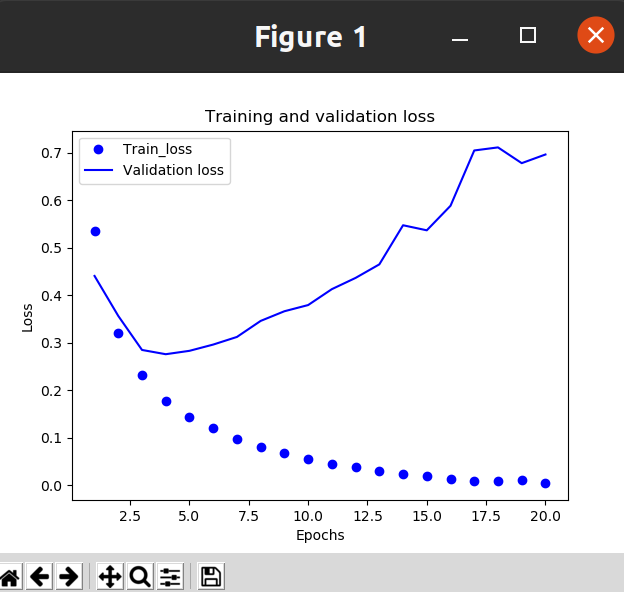
1.9绘制训练损失和验证损失
import matplotlib.pyplot as plt history_dic = history.history loss_values = history_dic['loss'] val_loss_values = history_dic['val_loss'] epochs = range(1,len(loss_values)+1) plt.plot(epochs,loss_values,'bo',label='Train_loss') #'bo'代表蓝色圆点 plt.plot(epochs,val_loss_values,'b',label='Validation loss') #'b'代表蓝色实线 plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()
效果:
1.10绘制训练精度和验证精度
plt.clf() acc = history_dict['binary_accuracy'] val_acc = history_dict['val_binary_accuracy'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()
效果:
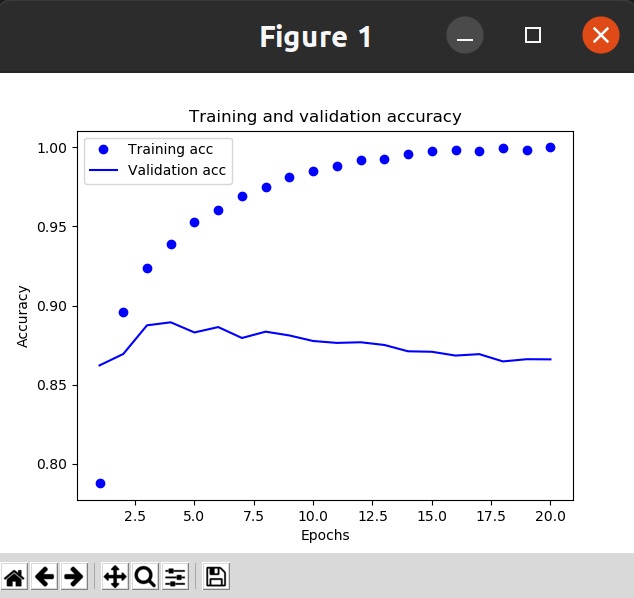
模型在训练数据上的表现越来越好,
但在前所未见的数据上不一定表现得越来越好。准确地说,你看到的是过拟合(overfit):在第
二轮之后,你对训练数据过度优化,最终学到的表示仅针对于训练数据,无法泛化到训练集之
外的数据。
在这种情况下,为了防止过拟合,你可以在 3 轮之后停止训练
1.11从新调整参数
将迭代次数改为4次
model.fit(x_train,y_train,epochs = 4 , batch_size=512) results = model.evaluate(x_test,y_test) print(results)
结果为: [0.2992907762527466, 0.880840003490448]
这种相当简单的方法得到了 88% 的精度。利用最先进的方法,你应该能够得到接近 95% 的
精度。
1.12使用训练好的网络在新数据上生成预测结果
print(model.predict(x_test))
结果:[[0.19584858]
[0.9992134 ]
[0.8974607 ]
...
[0.10779706]
[0.07069406]
[0.55532295]]
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号