loguru 异步日志库 - 官方文档汉化
loguru 异步日志库
- loguru 异步日志库
- 安装
- Loguru 指南
- 帮助与指南
- 从logging切换到 Loguru
- 1、日志和loguru之间的基本区别是什么?
- 2、替换getLogger()函数
- 3、替换Logger对象
- 4、替换Handler、Filter和Formatter对象
- 5、替换消息的%格式化方式
- 6、替换exc_info参数
- 7、替换extra参数和LoggerAdapter对象
- 8、替换isEnabledFor()方法
- 9、替换addLevelName()和getLevelName()函数
- 10、替换basicConfig()和dictConfig()函数
- 11、替换captureWarnings()函数
- 12、替换unittest库中的assertLogs()方法
- 13、替换pytest库中的caplog fixture
- Loguru 的代码片段和示例
- 当使用Loguru时的安全考虑事项
- 避免日志在终端打印两次的方法
- 更改现有处理程序的级别
- 配置Loguru供库或应用程序使用
- 在网络或进程之间发送和接收日志消息
- 解决UnicodeEncodeError和其他编码问题
- 使用装饰器记录函数的输入和输出日志
- 使用基于自定义添加级别的日志函数
- 设置创建的日志文件的权限
- 保留整个模块的opt()参数
- 使用自定义函数序列化日志消息
- 基于大小和时间进行日志文件轮换
- 自定义日志消息的颜色和格式
- 动态格式化消息以使值垂直对齐
- 自定义异常的格式化
- 显示堆栈跟踪而不使用错误上下文
- 通过操作换行符写入同一行的多个日志
- 将标准输出、标准错误和警告捕获
- 绕过
__name__值缺失的模块 - 与tqdm迭代的互操作性
- 在Cython模块中使用Loguru的日志记录器
- 创建具有独立处理程序集的独立日志记录器
- 使用
enqueue参数与多进程的兼容性
- 从logging切换到 Loguru
- API 参考
安装
pip install loguru -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
Loguru 指南
欢迎来到 Loguru 指南!Loguru 是一个旨在为 Python 提供愉快的日志记录体验的库。
Loguru 的主要概念是只有一个日志记录器,无需繁琐的配置即可直接使用。
为了方便起见,日志记录器已经预先配置并输出到 stderr(但这完全可配置)。
from loguru import logger
logger.debug("就是这样,简单又美观的日志记录!")
日志记录器只是一个接口,将日志消息分发给配置的处理程序。简单吧?
没有处理程序、格式化程序、过滤器的烦恼:一个函数搞定一切。
如何添加处理程序?如何设置日志格式?如何过滤消息?如何设置日志级别?
答案就是使用 add() 函数。
logger.add(sys.stderr, format="{time} {level} {message}", filter="my_module", level="INFO")
这个函数用于注册处理日志消息的汇聚点(sink),汇聚点负责管理带有记录字典的上下文化的日志消息。汇聚点可以采用多种形式:一个简单的函数、一个字符串路径、一个类似文件的对象、一个协程函数或一个内置处理程序。
请注意,您还可以使用添加处理程序时返回的标识符来移除先前添加的处理程序。这在您想要替代默认的 stderr 处理程序时非常有用:只需调用 logger.remove() 即可重新开始。
轻松实现文件日志记录,支持日志轮转、保留和压缩
如果您想将日志消息发送到文件,只需将字符串路径作为汇聚点使用。为了方便起见,您还可以自动进行定时:
logger.add("file_{time}.log")
如果需要,您可以轻松进行配置,实现日志轮转、删除旧日志或在关闭时压缩文件。
logger.add("file_1.log", rotation="500 MB") # 自动轮转过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建一个新文件
logger.add("file_3.log", rotation="1 week") # 当文件过旧时进行轮转
logger.add("file_X.log", retention="10 days") # 一段时间后进行清理
logger.add("file_Y.log", compression="zip") # 压缩文件节省空间
希望您享受使用 Loguru 带来的愉快日志记录体验!
使用大括号样式的现代字符串格式化
Loguru 更倾向于使用更优雅和强大的 {} 格式化,而不是 %,日志记录函数实际上等同于 str.format()。
logger.info("如果您正在使用 Python {},当然更喜欢 {feature}!", 3.6, feature="f-strings")
线程或主线程中的异常捕获
您是否曾经遇到程序在没有在日志文件中看到任何内容的情况下意外崩溃?您是否注意到在线程中发生的异常没有被记录?使用 catch() 装饰器/上下文管理器可以解决这个问题,它确保任何错误都正确地传播到日志记录器中。
@logger.catch
def my_function(x, y, z):
# 出错了?无论如何都会被捕捉到!
return 1 / (x + y + z)
漂亮的彩色日志
如果您的终端兼容,Loguru 会自动为日志添加颜色。您可以在汇聚点的格式中使用标记标签来定义您喜欢的样式。
logger.add(sys.stdout, colorize=True, format="<green>{time}</green> <level>{message}</level>")
异步、线程安全、多进程安全
默认情况下,添加到日志记录器的所有汇聚点都是线程安全的。它们不是多进程安全的,但是您可以将消息排队以确保日志完整性。如果您需要异步日志记录,也可以使用相同的参数。
logger.add("somefile.log", enqueue=True)
还支持将协程函数用作汇聚点,并且应该使用 complete() 进行等待。
完整描述的异常信息
在跟踪错误时,记录代码中发生的异常非常重要,但是如果不知道为什么失败,这样做就毫无意义。Loguru 可以通过显示整个堆栈跟踪来帮助您识别问题,包括变量的值。
# 代码示例:
logger.add("out.log", backtrace=True, diagnose=True) # 注意,在生产环境中可能会泄露敏感数据
def func(a, b):
return a / b
def nested(c):
try:
func(5, c)
except ZeroDivisionError:
logger.exception("What?!")
nested(0)
结果输出:
2018-07-17 01:38:43.975 | ERROR | __main__:nested:10 - What?!
Traceback (most recent call last):
File "test.py", line 12, in <module>
nested(0)
└ <function nested at 0x7f5c755322f0>
> File "test.py", line 8, in nested
func(5, c)
│ └ 0
└ <function func at 0x7f5c79fc2e18>
File "test.py", line 4, in func
return a / b
│ └ 0
└ 5
ZeroDivisionError: division by zero
请注意,由于无法获取帧数据,此功能在默认的 Python REPL 上无法使用。
按需进行结构化日志记录
希望将日志序列化以便更轻松地解析或传递吗?使用 serialize 参数,每条日志消息在发送到配置的汇聚点之前将被转换为 JSON 字符串。
logger.add(custom_sink_function, serialize=True)
使用 bind(),您可以通过修改 extra 记录属性来上下文化您的日志消息。
logger.add("file.log", format="{extra[ip]} {extra[user]} {message}")
context_logger = logger.bind(ip="192.168.0.1", user="someone")
context_logger.info("Contextualize your logger easily")
context_logger.bind(user="someone_else").info("Inline binding of extra attribute")
context_logger.info("Use kwargs to add context during formatting: {user}", user="anybody")
通过 contextualize(),您可以临时修改上下文本地状态:
with logger.contextualize(task=task_id):
do_something()
logger.info("End of task")
通过结合 bind() 和 filter,您还可以对日志进行更精细的控制:
logger.add("special.log", filter=lambda record: "special" in record["extra"])
logger.debug("This message is not logged to the file")
logger.bind(special=True).info("This message, though, is logged to the file!")
最后,patch() 方法允许将动态值附加到每条新消息的记录字典中:
logger.add(sys.stderr, format="{extra[utc]} {message}")
logger = logger.patch(lambda record: record["extra"].update(utc=datet
昂贵函数的延迟求值
有时候你希望在生产环境中记录详细信息,而又不希望降低性能,你可以使用 opt() 方法来实现这一点。
logger.opt(lazy=True).debug("If sink level <= DEBUG: {x}", x=lambda: expensive_function(2**64))
另外,“opt()”有很多用法:
logger.opt(exception=True).info("Error stacktrace added to the log message (tuple accepted too)")
logger.opt(colors=True).info("Per message <blue>colors</blue>")
logger.opt(record=True).info("Display values from the record (eg. {record[thread]})")
logger.opt(raw=True).info("Bypass sink formatting\n")
logger.opt(depth=1).info("Use parent stack context (useful within wrapped functions)")
logger.opt(capture=False).info("Keyword arguments not added to {dest} dict", dest="extra")
可自定义的日志级别
Loguru 提供了所有标准的日志级别,还增加了 trace() 和 success() 等级别。如果你需要更多的级别,可以使用 level() 函数来创建。
new_level = logger.level("SNAKY", no=38, color="<yellow>", icon="🐍")
logger.log("SNAKY", "Here we go!")
更好的日期时间处理 标准的日志记录中存在诸如 datefmt 或 msecs、%(asctime)s 和 %(created)s、不带时区信息的 naive datetimes、不直观的格式等问题。Loguru 解决了这些问题:
logger.add("file.log", format="{time:YYYY-MM-DD at HH:mm:ss} | {level} | {message}")
适用于脚本和库
在脚本中使用日志记录器很容易,你可以在启动时配置它。如果你想要从库中使用 Loguru,请记住永远不要调用 add(),而是使用 disable(),这样日志记录函数将变为无操作。如果开发人员希望看到你的库的日志,他们可以重新启用它。
# 对于脚本
config = {
"handlers": [
{"sink": sys.stdout, "format": "{time} - {message}"},
{"sink": "file.log", "serialize": True},
],
"extra": {"user": "someone"}
}
logger.configure(**config)
# 对于库,应该是你的库的 `__name__`
logger.disable("my_library")
logger.info("No matter added sinks, this message is not displayed")
# 在你的应用程序中,启用库中的日志记录器
logger.enable("my_library")
logger.info("This message however is propagated to the sinks")
增加对该章节的理解?
my_library在上述示例中是一个代表自定义的库的名称,它可以是你自己编写的任何Python库的名称。示例中使用了logger.disable("my_library")和logger.enable("my_library")来禁用和启用该库的日志记录器。
在实际情况中,你可以将my_library替换为你自己的库的名称。这样做的目的是,你可以有选择地控制特定库的日志记录输出。通过禁用库的日志记录器,你可以阻止该库的日志消息被传播到配置的处理程序中,而通过启用库的日志记录器,你可以允许该库的日志消息被传播到处理程序中。
在实际开发中,你可以根据自己的项目需求和代码结构,为不同的模块或库定义不同的名称,并使用logger.disable()和logger.enable()方法来灵活控制日志记录的输出。这样可以帮助你更好地调试和排查问题,并根据需要调整日志级别和输出方式。
与标准日志记录完全兼容
希望将内置的日志记录 Handler 作为 Loguru 的汇聚点吗?
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
需要将 Loguru 的消息传播到标准日志记录吗?
class PropagateHandler(logging.Handler):
def emit(self, record):
通过环境变量个性化默认设置
不喜欢默认的日志记录格式?希望使用其他的 DEBUG 颜色?没问题:
# Linux / OSX
export LOGURU_FORMAT="{time} | <lvl>{message}</lvl>"
# Windows
setx LOGURU_DEBUG_COLOR "<green>"
方便的解析器
从生成的日志中提取特定信息通常很有用,这就是为什么 Loguru 提供了一个 parse() 方法,可以帮助处理日志和正则表达式。
pattern = r"(?P<time>.*) - (?P<level>[0-9]+) - (?P<message>.*)" # 带有命名组的正则表达式
caster_dict = dict(time=dateutil.parser.parse, level=int) # 转换匹配的组
for groups in logger.parse("file.log", pattern, cast=caster_dict):
print("Parsed:", groups)
# {"level": 30, "message": "Log example", "time": datetime(2018, 12, 09, 11, 23, 55)}
全面的通知器
Loguru 可以轻松与伟大的 notifiers 库(必须单独安装)结合使用,以在程序意外失败时接收电子邮件通知,或发送许多其他类型的通知。
import notifiers
params = {
"username": "you@gmail.com",
"password": "abc123",
"to": "dest@gmail.com"
}
# 发送单个通知
notifier = notifiers.get_notifier("gmail")
notifier.notify(message="The application is running!", **params)
# 在每个错误消息上接收提醒
from notifiers.logging import NotificationHandler
handler = NotificationHandler("gmail", defaults=params)
logger.add(handler, level="ERROR")
比内置日志记录快10倍
尽管日志记录对性能的影响在大多数情况下可以忽略不计,但零成本的日志记录器将使其可以在任何地方使用,而无需太多考虑。在即将发布的版本中,Loguru 的关键函数将使用 C 实现,以获得最大的速度。
文档
帮助与指南
从logging切换到 Loguru
1、日志和loguru之间的基本区别是什么?
尽管loguru是从头开始编写的,不依赖于标准日志库,但这两个库的目的是相同的:提供功能以实现灵活的事件记录系统。主要区别在于,标准日志库要求用户显式实例化命名的Logger,并使用Handler、Formatter和Filter进行配置,而loguru则试图减少配置步骤的数量。
除此之外,使用方式基本相同。一旦创建或导入了日志记录器对象,就可以使用适当的严重性级别记录消息(logger.debug("开发消息"),logger.warning("危险!")等),然后将这些消息发送到配置的处理器中。
至于标准日志库,默认日志会被发送到sys.stderr而不是sys.stdout。POSIX标准指定stderr是“诊断输出”的正确流。将日志记录到stderr的主要有力的案例是它避免了将应用程序的实际输出与调试信息混合在一起。例如,考虑像python my_app.py | other_app这样的管道重定向,如果日志被输出到stdout,这是不可能的。另一个重要的好处是,Python在sys.stderr上解决了编码问题,通过转义错误字符(使用“backslashreplace”策略),而在sys.stdout上会引发UnicodeEncodeError(使用“strict”策略)。
2、替换getLogger()函数
通常在每个文件的开头调用getLogger()函数来获取并在模块中使用一个日志记录器,例如:logger = logging.getLogger(name)。
使用Loguru时,不需要显式地获取和命名日志记录器,只需使用from loguru import logger。每次使用导入的logger时,都会创建一条记录,并自动包含上下文的__name__值。
对于标准日志记录,可以使用name属性来格式化和过滤日志记录。
3、替换Logger对象
Loguru通过适当的输出定义替换了标准Logger配置。您不再需要配置一个logger,而是应该添加()并为您的处理器设置参数。setLevel()和addFilter()被配置的输出级别和过滤器参数所取代。传播属性(propagate attribute)和disable()函数也可以通过filter选项来替换。makeRecord()方法可以使用record["extra"]字典来进行替换。
有时,对特定的logger需要更精细的控制。在这种情况下,Loguru提供了bind()方法,可以用来生成一个具有特定名称的logger。
例如,通过调用other_logger = logger.bind(name="other"),使用other_logger记录的每条消息都会在record["extra"]字典中添加name值,而使用logger则不会。这样可以在您的输出或过滤函数中区分来自logger或other_logger的日志。
假设您只想记录特定的一些消息到一个输出中:
def specific_only(record):
return "specific" in record["extra"]
logger.add("specific.log", filter=specific_only)
specific_logger = logger.bind(specific=True)
logger.info("通用消息") # 这条消息会被特定的输出过滤掉
specific_logger.info("模块消息") # 这条消息会被特定的输出接受(以及其他输出)
另一个例子,如果您想将一个输出附加到一个命名的logger上:
# 只记录来自 "a" logger 的消息
logger.add("a.log", filter=lambda record: record["extra"].get("name") == "a")
# 只记录来自 "b" logger 的消息
logger.add("b.log", filter=lambda record: record["extra"].get("name") == "b")
logger_a = logger.bind(name="a")
logger_b = logger.bind(name="b")
logger_a.info("消息 A")
logger_b.info("消息 B")
4、替换Handler、Filter和Formatter对象
标准的日志记录要求您创建一个Handler对象,然后调用addHandler()方法。而使用Loguru,则使用add()方法来启动处理器。输出定义了处理器如何处理传入的日志消息,类似于handle()或emit()方法。要从多个模块记录日志,您只需要导入logger对象,所有消息都将被分派到添加的处理器上。
在调用add()方法时,level参数取代了setLevel(),format参数取代了setFormatter(),filter参数取代了addFilter()。Loguru会自动管理线程安全性,因此不需要createLock()、acquire()和release()。removeHandler()的等效方法是remove(),它应该与add()返回的标识符一起使用。
请注意,并不一定需要替换Handler对象,因为add()方法接受它们作为有效的输出。
简而言之,您可以将以下代码替换为:
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler("spam.log")
fh.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.ERROR)
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)
使用以下代码替换:
fmt = "{time} - {name} - {level} - {message}"
logger.add("spam.log", level="DEBUG", format=fmt)
logger.add(sys.stderr, level="ERROR", format=fmt)
5、替换消息的%格式化方式
Loguru只支持{}-style的格式化。
您需要将logger.debug("Some variable: %s", var)替换为logger.debug("Some variable: {}", var)。所有传递给日志记录函数的args和**kwargs参数都用于调用message.format(args, **kwargs)。在消息字符串中不出现的参数将被忽略。请注意,通过这种方式将参数传递给日志记录函数可能有助于(稍微)提高性能:如果级别太低以至于不会传递给任何配置的处理器,它避免了对消息进行格式化。
要转换Formatter使用的通用格式,请参考可用记录标记的列表。
要转换datefmt使用的日期格式,请参考可用日期标记的列表。
6、替换exc_info参数
在调用标准的日志记录函数时,您可以将exc_info作为参数传递,以将堆栈跟踪添加到消息中。取而代之,您应该使用opt()方法,并使用exception参数,将logger.debug("Debug error:", exc_info=True)替换为logger.opt(exception=True).debug("Debug error:")。
格式化的异常信息将包括完整的堆栈跟踪和变量。为了防止这种情况发生,请确保在添加输出时使用backtrace=False和diagnose=False。
7、替换extra参数和LoggerAdapter对象
为了将上下文信息传递给日志消息,可以通过内联bind()方法来替换extra:
context = {"clientip": "192.168.0.1", "user": "fbloggs"}
logger.info("Protocol problem", extra=context) # 标准的日志记录
logger.bind(**context).info("Protocol problem") # Loguru
这将将上下文信息添加到您记录的消息的record["extra"]字典中,因此请确保适当配置您的处理器格式:
fmt = "%(asctime)s %(clientip)s %(user)s %(message)s" # 标准的日志记录
fmt = "{time} {extra[clientip]} {extra[user]} {message}" # Loguru
您还可以通过在使用之前调用logger = logger.bind(clientip="192.168.0.1"),或将绑定的logger分配给类实例来替换LoggerAdapter:
class MyClass:
def __init__(self, clientip):
self.logger = logger.bind(clientip=clientip)
def func(self):
self.logger.debug("Running func")
8、替换isEnabledFor()方法
如果您希望记录调试日志的有用信息,但在未配置调试处理程序的发布模式下不想承担性能损失,标准日志记录提供了isEnabledFor()方法:
if logger.isEnabledFor(logging.DEBUG):
logger.debug("Message data: %s", expensive_func())
您可以使用opt()方法和lazy选项来进行替换:
# 参数应该是需要调用的函数
logger.opt(lazy=True).debug("Message data: {}", expensive_func)
这样,只有在需要记录调试日志时,才会实际调用expensive_func()函数,以避免在没有必要时产生不必要的性能损失。
9、替换addLevelName()和getLevelName()函数
要添加一个新的自定义级别,您可以使用level()函数替换addLevelName():
logging.addLevelName(33, "CUSTOM") # 标准的日志记录
logger.level("CUSTOM", no=45, color="<red>", icon="🚨") # Loguru
同样的函数也可以用来替换getLevelName():
logger.getLevelName(33) # => "CUSTOM"
logger.level("CUSTOM") # => (name='CUSTOM', no=33, color="<red>", icon="🚨")
请注意,与标准日志记录相反,Loguru不将严重程度数字与任何级别关联,级别仅通过其名称进行标识。
10、替换basicConfig()和dictConfig()函数
basicConfig()和dictConfig()函数被configure()方法所取代。
不过,configure()方法不接受config.ini文件,所以您需要自己处理,可以使用您喜欢的格式。
11、替换captureWarnings()函数
将警告模块中的警告重定向到日志系统的captureWarnings()函数可以通过以下方式实现,简单地替换warnings.showwarning()函数:
import warnings
from loguru import logger
showwarning_ = warnings.showwarning
def showwarning(message, *args, **kwargs):
logger.warning(message)
showwarning_(message, *args, **kwargs)
warnings.showwarning = showwarning
12、替换unittest库中的assertLogs()方法
unittest标准库中定义的assertLogs()方法用于捕获和测试记录的日志消息。但它无法与Loguru兼容。您需要用一个自定义的上下文管理器来替换它,可能实现如下:
from contextlib import contextmanager
@contextmanager
def capture_logs(level="INFO", format="{level}:{name}:{message}"):
"""Capture loguru-based logs."""
output = []
handler_id = logger.add(output.append, level=level, format=format)
yield output
logger.remove(handler_id)
它提供了记录的消息列表,您可以访问每个消息的record属性。
13、替换pytest库中的caplog fixture
pytest是一个非常常用的测试框架。caplog fixture用于捕获日志输出,以便进行测试。例如:
from loguru import logger
def some_func(a, b):
if a < 0:
logger.warning("Oh no!")
return a + b
def test_some_func(caplog):
assert some_func(-1, 3) == 2
assert "Oh no!" in caplog.text
如果您按照迁移指南进行了操作,您会注意到此测试将失败。这是因为pytest链接到了标准库的logging模块。
为了修复这个问题,我们需要添加一个将Loguru传递给caplog处理程序的sink。通过覆盖caplog fixture来捕获其处理程序来实现。在您的conftest.py文件中,添加以下内容:
import pytest
from loguru import logger
from _pytest.logging import LogCaptureFixture
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(
caplog.handler,
format="{message}",
level=0,
filter=lambda record: record["level"].no >= caplog.handler.level,
enqueue=False, # 如果您的测试正在生成子进程,请将其设置为'True'。
)
yield caplog
logger.remove(handler_id)
运行您的测试,一切应该正常工作。有关更多信息,请参阅GH#59和GH#474。您还可以安装和使用由@mcarans创建的pytest-loguru包。
请注意,如果您希望Loguru日志传播到Pytest终端报告器,您可以通过如下方式覆盖reportlog fixture:
import pytest
from loguru import logger
@pytest.fixture
def reportlog(pytestconfig):
logging_plugin = pytestconfig.pluginmanager.getplugin("logging-plugin")
handler_id = logger.add(logging_plugin.report_handler, format="{message}")
yield
logger.remove(handler_id)
Loguru 的代码片段和示例
当使用Loguru时的安全考虑事项
首先,如果您使用pickle来加载日志消息(例如从网络加载),请确保源是可信的,或者在反序列化之前对数据进行签名以验证其真实性。如果您不采取这些预防措施,恶意代码可能会被攻击者执行。您可以在这篇文章中阅读更多细节:What’s so dangerous about pickles?
import hashlib
import hmac
import pickle
def client(connection):
data = pickle.dumps("Log message")
digest = hmac.digest(b"secret-shared-key", data, hashlib.sha1)
connection.send(digest + b" " + data)
def server(connection):
expected_digest, data = connection.read().split(b" ", 1)
data_digest = hmac.digest(b"secret-shared-key", data, hashlib.sha1)
if not hmac.compare_digest(data_digest, expected_digest):
print("Integrity error")
else:
message = pickle.loads(data)
logger.info(message)
您还应避免记录可能被攻击者恶意制作的消息。调用logger.debug(message, value)大致相当于调用print(message.format(value)),并且相同的安全规则适用。特别是,攻击者可能强制打印您应用程序的假定隐藏变量。这是一篇解释可能存在的漏洞的文章:Be Careful with Python’s New-Style String Format.
SECRET_KEY = 'Y0UC4NTS33Th1S!'
class SomeValue:
def __init__(self, value):
self.value = value
# 如果用户输入了 "{value.__init__.__globals__[SECRET_KEY]}",那么秘密密钥将被显示。
message = "[Custom message] " + input()
logger.info(message, value=SomeValue(10))
由于外部输入,还存在日志注入攻击的可能性。请考虑在记录之前对用户值进行转义:Is your Python code vulnerable to log injection?
logger.add("file.log", format="{level} {message}")
# 如果value是 "Josh logged in.\nINFO User James",则会出现两条日志记录。
username = external_data()
logger.info("User " + username + " logged in.")
请注意,默认情况下,Loguru会在记录异常时显示现有变量的值。这对于调试非常有用,但可能导致凭据出现在日志文件中。确保在生产环境中关闭它(或设置LOGURU_DIAGNOSE=NO环境变量)。
logger.add("out.log", diagnose=False)
您还应考虑更改日志文件的访问权限。Loguru使用内置的open()函数创建文件,这意味着默认情况下,可能会由不同于所有者的用户读取文件。如果不希望出现这种情况,请确保修改默认访问权限。
def opener(file, flags):
return os.open(file, flags, 0o600)
logger.add("combined.log", opener=opener)
避免日志在终端打印两次的方法
为了方便起见,logger已经预配置了一个默认的处理程序,将消息写入sys.stderr。如果您计划添加另一个将消息记录到控制台的处理程序,您应该首先移除()默认处理程序,否则可能会出现重复的日志。
logger.remove() # 移除到目前为止添加的所有处理程序,包括默认处理程序。
logger.add(sys.stderr, level="WARNING")
更改现有处理程序的级别
一旦添加了处理程序,实际上是不可能更新它的。这是为了保持Loguru的API简洁而故意选择的。但是,如果您需要更改处理程序的配置级别,可以使用几种解决方案。选择最适合您用例的解决方案。
最简单的解决方法是使用更新后的级别参数,先移除()处理程序,然后重新添加()它。为此,您需要保留添加处理程序时返回的标识号的引用:
handler_id = logger.add(sys.stderr, level="WARNING")
logger.info("仅记录'WARNING'或更高级别的消息")
...
logger.remove(handler_id) # 对于默认处理程序,实际上是 '0'。
logger.add(sys.stderr, level="DEBUG")
logger.debug("也记录'DEBUG'消息")
或者,您可以将bind()方法与filter参数结合使用,根据日志级别动态过滤日志:
def my_filter(record):
if record["extra"].get("warn_only"): # "warn_only"绑定到logger并设置为'True'
return record["level"].no >= logger.level("WARNING").no
return True # 默认情况下,使用添加处理程序时配置的 'level'
logger.add(sys.stderr, filter=my_filter, level="DEBUG")
# 首先使用此记录器,调试消息被过滤掉
logger = logger.bind(warn_only=True)
logger.warn("初始化进行中")
# 然后您可以使用此记录器来记录所有消息
logger = logger.bind(warn_only=False)
logger.debug("回到调试消息")
最后,您可以通过将过滤器作为可调用对象使用,实现对处理程序级别的更高级别的控制:
class MyFilter:
def __init__(self, level):
self.level = level
def __call__(self, record):
levelno = logger.level(self.level).no
return record["level"].no >= levelno
my_filter = MyFilter("WARNING")
logger.add(sys.stderr, filter=my_filter, level=0)
logger.warning("OK")
logger.debug("NOK")
my_filter.level = "DEBUG"
logger.debug("OK")
配置Loguru供库或应用程序使用
在库或应用程序中使用Loguru时,必须明确区分。
对于应用程序,您可以在代码的任何位置添加处理程序。但建议在脚本的入口文件中的if name == "main"块内配置记录器。
然而,如果
您的工作是作为库来使用的,通常不应添加任何处理程序。这是用户负责根据其偏好配置日志记录,最好不要干扰。实际上,由于Loguru基于一个共同的记录器,由库添加的处理程序也将接收用户日志,这通常是不希望的。
默认情况下,第三方库不应发出日志,除非明确请求。因此,存在disable()和enable()方法。确保首先调用logger.disable("mylib")。这样可以避免库日志与用户日志混合。用户始终可以调用logger.enable("mylib")以访问您库的日志。
如果您希望为库用户简化日志配置,建议提供一个名为configure_logger()的函数,负责添加所需的处理程序。这将允许用户仅在需要时激活日志记录。
总结一下,让我们看一下这个假设的包(没有列出的文件是必需的,这完全取决于您计划如何使用项目):
mypackage
├── __init__.py
├── __main__.py
├── main.py
└── mymodule.py
文件与Loguru的关系如下:
-
File
__init__.py:- 当您的项目作为库被使用时(
import mypackage),它是入口点。 - 应该在顶层无条件地使用
logger.disable("mypackage")。 - 不应调用
logger.add(),因为它会修改处理程序的配置。
- 当您的项目作为库被使用时(
-
File
__main__.py:- 当您的项目作为应用程序运行时(
python -m mypackage),它是入口点。 - 可以在顶层无条件地进行日志配置。
- 当您的项目作为应用程序运行时(
-
File
main.py:- 当您的项目作为脚本运行时(
python mypackage/main.py),它是入口点。 - 可以在
if __name__ == "__main__"块内进行日志配置。
- 当您的项目作为脚本运行时(
-
File
mymodule.py:- 这是您的项目使用的内部模块。
- 它可以通过导入 logger 来使用它。
- 不需要进行任何配置。
在网络或进程之间发送和接收日志消息
如果需要的话,可以在不同的进程甚至不同的计算机之间传输日志。一旦建立了两个 Python 程序之间的连接,就需要在一方对日志记录进行序列化,而在另一方重构消息。
可以通过为客户端使用自定义的输出目标(sink)和使用 patch() 方法来实现这一点。
# 客户端代码 (`client.py`):
import sys
import socket
import struct
import time
import pickle
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("从客户端发送消息")
# 服务器端代码 (`server.py`):
import socketserver
import pickle
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()
请注意,使用pickle序列化是不安全的,请谨慎使用。
另一种可能性是使用第三方库,例如zmq。
# 客户端代码 (`client.py`):
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)
logger.add(handler)
logger.info("来自客户端的日志记录")
# 服务器端代码 (`server.py`):
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())
解决UnicodeEncodeError和其他编码问题
当您写入日志消息时,处理程序可能需要将接收到的Unicode字符串编码为特定的字节序列。执行此操作时使用的编码方式取决于处理程序类型和您的环境。如果您尝试写入一个处理程序编码不支持的字符,可能会出现问题。在这种情况下,Python很可能会引发UnicodeEncodeError错误。
例如,在打印到终端时可能会出现以下错误:
print("天")
# UnicodeEncodeError: 'charmap' codec can't encode character '\u5929' in positio
类似的错误可能会在使用不合适的编码方式打开文件后进行写入时发生。最常见的问题是在将日志记录到标准输出或Windows上的文件时发生。那么,如何避免这种错误呢?只需通过适当配置处理程序,使其能够处理任何类型的Unicode字符串即可。
如果在将日志记录到标准输出时遇到此错误,您有几个选项:
-
使用sys.stderr而不是sys.stdout(前者将转义错误字符而不是引发异常)
-
将PYTHONIOENCODING环境变量设置为utf-8
-
使用sys.stdout.reconfigure(),并指定encoding='utf-8'和/或errors='backslashreplace'
如果使用文件作为输出目标,您可以在添加处理程序时配置errors或encoding参数,例如logger.add("file.log", encoding="utf8")。所有其他的**kwargs参数都将传递给内置的open()函数。
对于其他类型的处理程序,您需要检查是否有一种方法来参数化编码或回退策略。
使用装饰器记录函数的输入和输出日志
在某些情况下,记录函数的输入和输出值可能很有用。虽然Loguru没有直接提供这样的功能,但可以通过使用Python装饰器来轻松实现:
import functools
from loguru import logger
def logger_wraps(*, entry=True, exit=True, level="DEBUG"):
def wrapper(func):
name = func.__name__
@functools.wraps(func)
def wrapped(*args, **kwargs):
logger_ = logger.opt(depth=1)
if entry:
logger_.log(level, "Entering '{}' (args={}, kwargs={})", name, args, kwargs)
result = func(*args, **kwargs)
if exit:
logger_.log(level, "Exiting '{}' (result={})", name, result)
return result
return wrapped
return wrapper
然后,您可以像这样使用它:
@logger_wraps()
def foo(a, b, c):
logger.info("Inside the function")
return a * b * c
def bar():
foo(2, 4, c=8)
bar()
这将产生以下结果:
2019-04-07 11:08:44.198 | DEBUG | __main__:bar:30 - Entering 'foo' (args=(2, 4), kwargs={'c': 8})
2019-04-07 11:08:44.198 | INFO | __main__:foo:26 - Inside the function
2019-04-07 11:08:44.198 | DEBUG | __main__:bar:30 - Exiting 'foo' (result=64)
这是另一个简单的示例,用于记录函数的执行时间:
def timeit(func):
def wrapped(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
logger.debug("Function '{}' executed in {:f} s", func.__name__, end - start)
return result
return wrapped
使用基于自定义添加级别的日志函数
在添加新级别后,通常习惯使用log()函数:
logger.level("foobar", no=33, icon="🤖", color="<blue>")
logger.log("foobar", "A message")
为了方便起见,可以分配一个新的日志函数,它会自动使用自定义添加的级别:
from functools import partialmethod
logger.__class__.foobar = partialmethod(logger.__class__.log, "foobar")
logger.foobar("A message")
只需添加一次新方法,它将适用于导入日志记录器的所有文件中。将方法分配给logger.__class__而不是直接给logger,确保在调用logger.bind()、logger.patch()和logger.opt()之后它仍然可用(因为这些函数返回一个新的日志记录器实例)。
设置创建的日志文件的权限
要设置所创建的日志文件的所需权限,请使用opener参数传递自定义opener和八进制权限:
import os
os.umask(0) # 更新当前的umask(它的值从"os.open()"权限中掩码出来)
def opener(file, flags):
return os.open(file, flags, 0o777)
logger.add("foo.log", rotation="100 kB", opener=opener)
使用opener参数时,包括在旋转期间创建的所有日志文件都将使用最初提供的opener。
保留整个模块的opt()参数
假设您希望为每条日志消息着色,而不必每次都调用logger.opt(colors=True),可以在模块的开头添加以下内容:
logger = logger.opt(colors=True)
logger.info("It <green>works</>!")
但是需要注意的是,不可能链式调用opt(),使用此方法再次调用将会将颜色选项重置为其默认值(即False)。因此,还需要对opt()方法进行patch,以便所有后续调用继续使用所需的值:
from functools import partial
logger = logger.opt(colors=True)
logger.opt = partial(logger.opt, colors=True)
logger.opt(raw=True).info("It <green>still</> works!\n")
使用自定义函数序列化日志消息
使用serialize=True添加的每个处理程序都将通过将日志记录转换为有效的JSON字符串来创建消息。根据消息的目标接收器,可能有必要对生成的字符串进行更改。您可以实现自己的序列化函数,并直接在您的接收器中使用它,而不是使用serialize参数:
import json
def serialize(record):
subset = {"timestamp": record["time"].timestamp(), "message": record["message"]}
return json.dumps(subset)
def sink(message):
serialized = serialize(message.record)
print(serialized)
logger.add(sink)
如果你需要将结构化日志发送到文件(或任何类型的目标),可以使用自定义的格式化函数来实现类似的结果:
def formatter(record):
# 注意:这个函数返回的是要格式化的字符串,而不是实际要记录的消息
record["extra"]["serialized"] = serialize(record)
return "{extra[serialized]}\n"
logger.add("file.log", format=formatter)
你还可以使用patch()来实现,在多个目标中使用时只调用一次序列化函数:
def patching(record):
record["extra"]["serialized"] = serialize(record)
logger = logger.patch(patching)
# 注意,如果“format”不是一个函数,可能会将可能的异常附加到消息中
logger.add(sys.stderr, format="{extra[serialized]}")
logger.add("file.log", format="{extra[serialized]}")
基于大小和时间进行日志文件轮换
文件日志记录器的rotation参数接受大小限制或时间限制,但不支持两者同时使用,出于简化的原因。然而,你可以创建一个自定义函数来支持更高级的场景:
import datetime
class Rotator:
def __init__(self, *, size, at):
now = datetime.datetime.now()
self._size_limit = size
self._time_limit = now.replace(hour=at.hour, minute=at.minute, second=at.second)
if now >= self._time_limit:
# 当前时间已经超过目标时间,所以会立即进行轮换
# 添加一天以避免立即进行轮换
self._time_limit += datetime.timedelta(days=1)
def should_rotate(self, message, file):
file.seek(0, 2)
if file.tell() + len(message) > self._size_limit:
return True
excess = message.record["time"].timestamp() - self._time_limit.timestamp()
if excess >= 0:
elapsed_days = datetime.timedelta(seconds=excess).days
self._time_limit += datetime.timedelta(days=elapsed_days + 1)
return True
return False
# 如果文件超过500MB或者在每天午夜时分轮换
rotator = Rotator(size=5e+8, at=datetime.time(0, 0, 0))
logger.add("file.log", rotation=rotator.should_rotate)
自定义日志消息的颜色和格式
你可以使用Loguru中的标记标签来自定义日志的颜色,这些标签用于配置处理程序的格式。通过创建适当的格式化函数,你可以根据日志消息轻松定义颜色。
例如,如果你想将每个模块与唯一的颜色关联起来:
from collections import defaultdict
from random import choice
colors = ["blue", "cyan", "green", "magenta", "red", "yellow"]
color_per_module = defaultdict(lambda: choice(colors))
def formatter(record):
color_tag = color_per_module[record["name"]]
return "<" + color_tag + ">[{name}]</> <bold>{message}</>\n{exception}"
logger.add(sys.stderr, format=formatter)
如果你需要动态给record["message"]着色,确保颜色标签出现在返回的格式中,而不是修改消息本身:
def rainbow(text):
colors = ["red", "yellow", "green", "cyan", "blue", "magenta"]
chars = ("<{}>{}</>".format(colors[i % len(colors)], c) for i, c in enumerate(text))
return "".join(chars)
def formatter(record):
rainbow_message = rainbow(record["message"])
# 防止格式化期间将“{}”解析为占位符
escaped = rainbow_message.replace("{", "{{").replace("}", "}}")
return "<b>{time}</> " + escaped + "\n{exception}"
logger.add(sys.stderr, format=formatter)
动态格式化消息以使值垂直对齐
默认的格式化程序无法垂直对齐日志消息,因为{name}、{function}和{line}的长度不固定。
一种解决方法是使用一些最大值进行填充,这些最大值在大多数情况下应该足够。为此,你可以使用Python的字符串格式化指令,例如:
fmt = "{time} | {level: <8} | {name: ^15} | {function: ^15} | {line: >3} | {message}"
logger.add(sys.stderr, format=fmt)
这里,<、^和>将分别对齐左、居中和右对齐的键,并将它们填充到最大长度。
也可以通过使用格式化函数或类来使用其他解决方案。例如,可以根据先前遇到的值动态调整填充长度:
class Formatter:
def __init__(self):
self.padding = 0
self.fmt = "{time} | {level: <8} | {name}:{function}:{line}{extra[padding]} | {message}\n{exception}"
def format(self, record):
length = len("{name}:{function}:{line}".format(**record))
self.padding = max(self.padding, length)
record["extra"]["padding"] = " " * (self.padding - length)
return self.fmt
formatter = Formatter()
logger.remove()
logger.add(sys.stderr, format=formatter.format)
自定义异常的格式化
Loguru在使用logger.exception()或logger.opt(exception=True)时会自动添加发生异常的回溯信息:
def inverse(x):
try:
1 / x
except ZeroDivisionError:
logger.exception("Oups...")
if __name__ == "__main__":
inverse(0)
2019-11-15 10:01:13.703 | ERROR | __main__:inverse:8 - Oups...
Traceback (most recent call last):
File "foo.py", line 6, in inverse
1 / x
ZeroDivisionError: division by zero
如果处理程序使用backtrace=True添加,回溯信息将扩展以查看异常发生的位置:
2019-11-15 10:11:32.829 | ERROR | __main__:inverse:8 - Oups...
Traceback (most recent call last):
File "foo.py", line 16, in <module>
inverse(0)
> File "foo.py", line 6, in inverse
1 / x
ZeroDivisionError: division by zero
如果处理程序使用diagnose=True添加,回溯信息将进行注释以查看引发问题的原因:
Traceback (most recent call last):
File "foo.py", line 6, in inverse
1 / x
└ 0
ZeroDivisionError: division by zero
可以通过添加具有自定义格式化函数的处理程序来进一步个性化异常的格式化。例如,假设你想使用stackprinter库格式化错误:
import stackprinter
def format(record):
format_ = "{time} {message}\n"
if record["exception"] is not None:
record["extra"]["stack"] = stackprinter.format(record["exception"])
format_ += "{extra[stack]}\n"
return format_
logger.add(sys.stderr, format=format)
2019-11-15T10:46:18.059964+0100 Oups...
File foo.py, line 17, in inverse
15 def inverse(x):
16 try:
--> 17 1 / x
18 except ZeroDivisionError:
..................................................
x = 0
..................................................
ZeroDivisionError: division by zero
显示堆栈跟踪而不使用错误上下文
在某些情况下,显示日志消息时显示堆栈跟踪可能很有用,而此时尚未引发任何异常。虽然这个功能不是内置于Loguru中的,因为它与调试而不是日志记录更相关,但是可以使用logger.patch()来修补(logger)然后根据需要显示堆栈跟踪(使用traceback模块):
import traceback
def add_traceback(record):
extra = record["extra"]
if extra.get("with_traceback", False):
extra["traceback"] = "\n" + "".join(traceback.format_stack())
else:
extra["traceback"] = ""
logger = logger.patch(add_traceback)
logger.add(sys.stderr, format="{time} - {message}{extra[traceback]}")
logger.info("No traceback")
logger.bind(with_traceback=True).info("With traceback")
以下是另一个示例,演示如何使用完整调用堆栈前缀日志消息:
import traceback
from itertools import takewhile
def tracing_formatter(record):
# 过滤掉Loguru内部的帧
frames = takewhile(lambda f: "/loguru/" not in f.filename, traceback.extract_stack())
stack = " > ".join("{}:{}:{}".format(f.filename, f.name, f.lineno) for f in frames)
record["extra"]["stack"] = stack
return "{level} | {extra[stack]} - {message}\n{exception}"
def foo():
logger.info("Deep call")
def bar():
foo()
logger.remove()
logger.add(sys.stderr, format=tracing_formatter)
bar()
# 输出: "INFO | script.py:<module>:23 > script.py:bar:18 > script.py:foo:15 - Deep call"
通过操作换行符写入同一行的多个日志
你可以使用bind()、opt()和自定义格式化函数的组合来临时将消息记录在连续的行上。如果你想要展示正在进行的逐步过程,这是特别有用的,例如:
def formatter(record):
end = record["extra"].get("end", "\n")
return "[{time}] {message}" + end + "{exception}"
logger.add(sys.stderr, format=formatter)
logger.add("foo.log", mode="w")
logger.bind(end="").debug("Progress: ")
for _ in range(5):
logger.opt(raw=True).debug(".")
logger.opt(raw=True).debug("\n")
logger.info("Done")
[2020-03-26T22:47:01.708016+0100] Progress: .....
[2020-03-26T22:47:01.709031+0100] Done
需要注意的是,根据你使用的输出目标(sink),可能会遇到一些困难。日志记录并不总是适合用于此类型的最终用户消息。
将标准输出、标准错误和警告捕获
使用日志记录应优先于print(),但是可能发生这种情况:你不能直接控制在应用程序中执行的代码。如果你想捕获标准输出,可以使用自定义流对象和contextlib.redirect_stdout()来抑制sys.stdout(和sys.stderr)。你需要先移除默认处理程序,并且在重定向后不要添加新的stdout接收器,否则可能会导致死锁(可以使用sys.__stdout__):
import contextlib
import sys
from loguru import logger
class StreamToLogger:
def __init__(self, level="INFO"):
self._level = level
def write(self, buffer):
for line in buffer.rstrip().splitlines():
logger.opt(depth=1).log(self._level, line.rstrip())
def flush(self):
pass
logger.remove()
logger.add(sys.__stdout__)
stream = StreamToLogger()
with contextlib.redirect_stdout(stream):
print("Standard output is sent to added handlers.")
你还可以通过替换warnings.showwarning()捕获应用程序发出的警告:
import warnings
from loguru import logger
showwarning_ = warnings.showwarning
def showwarning(message, *args, **kwargs):
logger.warning(message)
showwarning_(message, *args, **kwargs)
warnings.showwarning = showwarning
或者,如果你想基于记录的消息发出警告,可以简单地使用warnings.warn()作为接收器:
logger.add(warnings.warn, format="{message}", filter=lambda record: record["level"].name == "WARNING")
绕过__name__值缺失的模块
Loguru使用全局变量__name__来确定日志消息的来源。然而,在某些特定情况下(例如某些Dask分布式环境),可能未设置此值。在这种情况下,Loguru将使用None来替代缺失的值。这意味着如果你想禁用来自这种特殊模块的消息,你必须显式调用logger.disable(None)。
在处理filter属性时,也应考虑类似的情况。由于__name__缺失,Loguru将为record["name"]分配None值。这意味着一旦在日志消息中格式化,{name}占位符将等于"None"。你可以通过在有问题的模块中使用patch()手动覆盖record["name"]值来解决这个问题:
# 如果Loguru无法检索到正确的"name"值,请手动分配
logger = logger.patch(lambda record: record.update(name="my_module"))
除非你注意到代码受到此行为的影响,否则可能不需要担心所有这些。
与tqdm迭代的互操作性
在使用tqdm库包装的迭代过程中使用Loguru的日志记录器可能会干扰显示的进度条。作为解决方法,可以使用tqdm.write()函数将日志消息写入sys.stderr,而不是直接写入日志记录器:
import time
from loguru import logger
from tqdm import tqdm
logger.remove()
logger.add(lambda msg: tqdm.write(msg, end=""), colorize=True)
logger.info("初始化")
for x in tqdm(range(100)):
logger.info("迭代 #{}", x)
time.sleep(0.1)
在使用Spyder和Windows导入tqdm时,你可能会遇到日志颜色化的问题。这个问题在GH#132中有讨论。你可以在导入后立即调用colorama.deinit()来绕过这个问题。
在Cython模块中使用Loguru的日志记录器
Loguru和Cython之间的互操作性不是很好。这是因为Loguru(以及通常的日志记录)在很大程度上依赖于Python的堆栈帧,而Cython作为一种替代的Python实现,出于优化原因,试图摆脱这些帧。
从使用Cython编译的代码中调用日志记录器可能会引发以下类型的异常:
ValueError: call stack is not deep enough
当Loguru尝试访问被Cython屏蔽的堆栈帧时,就会出现此错误。Loguru无法检索到记录消息的上下文信息,但存在一种解决方法,至少可以防止应用程序崩溃:
# 在文件开头添加以下内容
logger = logger.opt(depth=-1)
注意,日志记录的消息应该能正确显示,但函数名称和其他信息将不正确。这个问题在GH#88中有讨论。
创建具有独立处理程序集的独立日志记录器
Loguru的基本设计是可与一个全局日志记录器对象配合使用,将日志消息分派到配置的处理程序。在某些情况下,可能需要将特定消息记录到特定的处理程序中。
例如,假设你想根据任意标识符将日志拆分为两个文件,可以通过结合bind()和filter来实现:
from loguru import logger
def task_A():
logger_a = logger.bind(task="A")
logger_a.info("Starting task A")
do_something()
logger_a.success("End of task A")
def task_B():
logger_b = logger.bind(task="B")
logger_b.info("Starting task B")
do_something_else()
logger_b.success("End of task B")
logger.add("file_A.log", filter=lambda record: record["extra"]["task"] == "A")
logger.add("file_B.log", filter=lambda record: record["extra"]["task"] == "B")
task_A()
task_B()
这样,"file_A.log"和"file_B.log"分别只包含task_A()和task_B()函数的日志。
现在,假设你有很多这样的任务。配置每个处理程序可能有点麻烦。更重要的是,这可能会不必要地减慢应用程序的运行速度,因为每个日志都需要通过每个处理程序的过滤函数进行检查。在这种情况下,建议依赖于copy.deepcopy()内置方法,它将创建一个独立的日志记录器对象。如果将处理程序添加到深度复制的日志记录器中,它将不与使用原始日志记录器的其他函数共享:
import copy
from loguru import logger
def task(task_id, logger):
logger.info("Starting task {}", task_id)
do_something(task_id)
logger.success("End of task {}", task_id)
logger.remove()
for task_id in ["A", "B", "
C", "D", "E"]:
logger_ = copy.deepcopy(logger)
logger_.add("file_%s.log" % task_id)
task(task_id, logger_)
请注意,如果尝试复制已添加了不可序列化处理程序的日志记录器,则可能会遇到错误。因此,通常建议在调用copy.deepcopy(logger)之前删除所有处理程序。
使用enqueue参数与多进程的兼容性
在Linux上,由于os.fork()的存在,在使用multiprocessing模块启动的子进程中使用日志记录器没有什么问题。子进程将自动继承已添加的处理程序,enqueue=True参数是可选的,但建议使用它,因为它可以避免对日志记录器的并发访问:
# Linux implementation
import multiprocessing
from loguru import logger
def my_process():
logger.info("Executing function in child process")
logger.complete()
if __name__ == "__main__":
logger.add("file.log", enqueue=True)
process = multiprocessing.Process(target=my_process)
process.start()
process.join()
logger.info("Done")
在Windows上情况会变得有点复杂。实际上,这个操作系统不支持fork,所以Python必须使用一种名为“spawning”的替代方法来创建子进程。此过程要求完全重新加载创建子进程的整个文件。这与Loguru的互操作性不是很好,会导致处理程序被重复添加而没有任何同步,或者完全不添加处理程序(取决于add()和remove()是在__main__分支内部还是外部调用)。因此,需要将日志记录器对象明确地作为子进程的初始化参数传递:
# Windows implementation
import multiprocessing
from loguru import logger
def my_process(logger_):
logger_.info("Executing function in child process")
logger_.complete()
if __name__ == "__main__":
logger.remove() # 默认的 "sys.stderr" sink 不可序列化
logger.add("file.log", enqueue=True)
process = multiprocessing.Process(target=my_process, args=(logger, ))
process.start()
process.join()
logger.info("Done")
在Windows上,要求添加的处理程序是可序列化的,否则在创建子进程时会引发错误。许多流对象(如标准输出和文件描述符)都不可序列化。在这种情况下,enqueue=True参数是必需的,因为它将允许子进程只继承发送日志的队列对象。
multiprocessing库还常用于使用map()或apply()启动工作池。在Linux上,它将无缝运行,但在Windows上需要进行一些调整。你可能无法将日志记录器作为工作器函数的参数传递,因为它需要是可序列化的,但是使用enqueue=True添加的处理程序既可“继承”,也可“序列化”。相反,你需要在创建Pool对象时使用initializer和initargs参数的方式,以允许工作器访问共享的日志记录器。你可以将其分配给类属性,或者覆盖子进程的全局日志记录器:
# workers_a.py
class Worker:
_logger = None
@staticmethod
def set_logger(logger_):
Worker._logger = logger_
def work(self, x):
self._logger.info("Square rooting {}", x)
return x**0.5
# workers_b.py
from loguru import logger
def set_logger(logger_):
global logger
logger = logger_
def work(x):
logger.info("Square rooting {}", x)
return x**0.5
# main.py
from multiprocessing import Pool
from loguru import logger
import workers_a
import workers_b
if __name__ == "__main__":
logger.remove()
logger.add("file.log", enqueue=True)
worker = workers_a.Worker()
with Pool(4, initializer=worker.set_logger, initargs=(logger, )) as pool:
results = pool.map(worker.work, [1, 10, 100])
with Pool(4, initializer=workers_b.set_logger, initargs=(logger, )) as pool:
results = pool.map(workers_b.work, [1, 10, 100])
logger.info("Done")
无论操作系统如何,请注意使用enqueue=True添加处理程序的进程负责内部使用的队列。这意味着如果任何子进程可能继续使用它,则应避免从父进程中.remove()此处理程序。更重要的是,注意在离开Process之前调用complete(),以确保队列处于稳定状态。
在处理多进程时需要牢记的另一件事是使用enqueue=True创建的处理程序在当前多进程上下文中内部创建一个队列。如果将它们传递给在不同上下文中实例化的子进程(例如在Linux上使用multiprocessing.get_context("spawn"),其中默认上下文是"fork"),那么很可能会导致子进程崩溃。这也在Python的multiprocessing文档中有提到。
因此,在Linux上使用默认上下文为fork的情况下,下面的代码将无法正常工作,因为处理程序是在不同的上下文中添加的:
# main.py
import multiprocessing
from loguru import logger
import workers_a
import workers_b
if __name__ == "__main__":
logger.remove()
logger.add("file.log", enqueue=True)
worker = workers_a.Worker()
with multiprocessing.get_context("spawn").Pool(4, initializer=worker.set_logger, initargs=(logger, )) as pool:
results = pool.map(worker.work, [1, 10, 100])
with multiprocessing.get_context("spawn").Pool(4, initializer=workers_b.set_logger, initargs=(logger, )) as pool:
results = pool.map(workers_b.work, [1, 10, 100])
logger.info("Done")
要解决这个问题,可以全局设置multiprocessing上下文,以便处理程序在与子进程运行的上下文相同的上下文中创建:
# main.py
import multiprocessing
from loguru import logger
import workers_a
import workers_b
if __name__ == "__main__":
multiprocessing.set_start_method("spawn")
logger.remove()
logger.add("file.log", enqueue=True)
worker = workers_a.Worker()
with multiprocessing.Pool(4, initializer=worker.set_logger, initargs=(logger, ))
as pool:
results = pool.map(worker.work, [1, 10, 100])
with multiprocessing.Pool(4, initializer=workers_b.set_logger, initargs=(logger, )) as pool:
results = pool.map(workers_b.work, [1, 10, 100])
logger.info("Done")
API 参考
一个用于将日志消息发送到配置处理程序的对象。
Logger 是 loguru 的核心对象,所有的日志配置和使用都通过调用它的方法来完成。只有一个 logger,所以在使用之前无需获取。
一旦导入了 logger,就可以使用它来记录代码中发生的事件。通过阅读应用程序的输出日志,您可以更好地了解程序的流程,更容易地追踪和调试意外行为。
使用 add() 方法添加接收日志消息的处理程序。请注意,您可以在导入后立即使用 Logger,因为它已经预先配置好了(默认情况下将日志输出到 sys.stderr)。消息可以使用不同的严重级别记录,并且可以使用大括号进行格式化(底层使用的是 str.format())。
当记录日志时,与之关联的是一个“记录”(record)。该记录是一个包含日志上下文信息的字典:时间、函数、文件、行、线程、级别等等。它还包含模块的 name,这就是为什么不需要命名日志记录器。
您不应该自己实例化 Logger,而是使用 from loguru import logger 导入。
Logger.add
add(
sink,
*,
level='DEBUG',
format='<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | <level>{level: <8}</level> | <cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> - <level>{message}</level>',
filter=None,
colorize=None,
serialize=False,
backtrace=True,
diagnose=True,
enqueue=False,
catch=True,
**kwargs)
添加一个处理程序,将日志消息发送到适当配置的接收器。
Parameters:
sink:(文件类对象、字符串、pathlib.Path、可调用对象、协程函数或logging.Handler)- 负责接收格式化的日志消息并将其传播到适当终点的对象。level:(int或str,可选)- 从中将日志消息发送到sink的最低严重级别。format:(str或可调用对象,可选)- 用于在发送到sink之前格式化日志消息的模板。filter:(可调用对象、字符串或字典,可选)- 一个指令,可选择地用于决定每条日志消息是否应发送到sink。colorize:(bool,可选)- 是否将格式化消息中的颜色标记转换为终端颜色代码,或者在其他情况下剥离颜色标记。如果为None,则根据sink是否为tty自动进行选择。serialize:(bool,可选)- 是否在发送到sink之前首先将日志消息及其记录转换为JSON字符串。backtrace:(bool,可选)- 是否应扩展异常跟踪格式,以显示生成错误的完整堆栈跟踪。diagnose:(bool,可选)- 是否应显示异常跟踪的变量值,以便于调试。在生产环境中应将其设置为False,以避免泄漏敏感数据。enqueue:(bool,可选)- 是否应将待记录的消息先通过一个多进程安全队列,然后再传递到sink。在通过多个进程记录到文件时,这很有用。这还具有使日志调用非阻塞的优点。catch:(bool,可选)- 是否自动捕获sink处理日志消息时发生的错误。如果为True,则在sys.stderr上显示异常消息,但异常不会传播给调用者,防止应用程序崩溃。**kwargs:仅对配置协程或文件sink的其他有效参数(请参见下文)。
仅当sink是协程函数时,以下参数适用:
Parameters:
- loop(AbstractEventLoop,可选)- 异步日志任务将被安排和执行的事件循环。如果为None,则使用当前运行的循环,即在日志调用时由asyncio.get_running_loop()返回的循环(如果当前没有运行的循环,则任务被丢弃)。
仅当sink是文件路径时,以下参数适用:
Parameters:
-
rotation(str、int、datetime.time、datetime.timedelta或可调用对象,可选)- 表示何时应关闭当前记录的文件并启动新文件的条件。
-
retention(str、int、datetime.timedelta或可调用对象,可选)- 指令,用于过滤在旋转或程序结束时应删除的旧文件。
-
compression(str或可调用对象,可选)- 在关闭时应将日志文件转换为的压缩或归档格式。
-
delay(bool,可选)- 是否在配置sink时立即创建文件,还是延迟到第一条记录的消息。默认为False。
-
watch(bool,可选)- 文件是否应该被监视,并在被外部程序删除或更改(基于其设备和inode属性)时重新打开。默认为False。
-
mode(str,可选)- 打开模式,与内置的open()函数相同。默认为"a"(以追加模式打开文件)。
-
buffering(int,可选)- 缓冲策略,与内置的open()函数相同。默认为1(行缓冲文件)。
-
encoding(str,可选)- 文件编码,与内置的open()函数相同。默认为"utf8"。
-
**kwargs - 其他参数传递给内置的open()函数。
retures:
- int - 与添加的sink关联的标识符,应用于remove()方法。
raises:
- ValueError - 如果传递给配置sink的任何参数无效。
注:
下面是扩展摘要。
sink 参数
sink 用于处理传入的日志消息并进行相应的写入操作。sink 可以采用多种形式:
-
像 sys.stderr 或 open("somefile.log", "w") 这样的文件对象。任何具有 .write() 方法的对象都被视为文件对象。自定义处理程序还可以实现 flush()(在每条日志消息后调用)、stop()(在 sink 终止时调用)和 complete()(由同名方法等待执行)。
-
作为字符串或 pathlib.Path 的文件路径。它可以使用一些附加参数进行参数化,详见下文。
-
像 lambda msg: print(msg) 这样的可调用对象(例如简单函数)。这允许根据用户的偏好和需求完全定义日志记录过程。
-
使用 async def 语句定义的异步协程函数。此类函数返回的协程对象将使用 loop.create_task() 添加到事件循环中。在使用 complete() 完成循环之前,应等待这些任务。
-
像 logging.StreamHandler 这样的内置 logging.Handler。在这种情况下,Loguru 记录会自动转换为 logging 模块所期望的结构。
请注意,日志函数不是可重入的。这意味着您应避免在任何 sink 内部或信号处理程序中使用日志记录器。否则,如果模块的 sink 没有明确禁用,可能会面临死锁的情况。
记录的消息
传递给所有添加的 sink 的记录消息实际上只是格式化日志的字符 串,与之关联的是一个特殊属性:.record,它是一个包含所有可能需要的上下文信息的字典(详见下文)。
记录的消息根据添加的 sink 的格式进行格式化。该格式通常是一个包含大括号字段的字符串,用于显示记录字典中的属性。
如果需要更精细的控制,格式也可以是一个以记录为参数并返回格式模板字符串的函数。然而,请注意,在这种情况下,您应该注意在返回的格式中添加换行符和异常字段,而如果格式是字符串,则会自动添加"\n{exception}"以方便使用。
filter 属性可用于控制哪些消息实际上会传递到 sink,哪些消息会被忽略。可以使用函数,接受记录作为参数,并在消息应该被记录时返回 True,否则返回 False。如果使用字符串,则只允许具有相同名称及其子级的记录。还可以传递将模块名称映射到最低要求级别的字典。在这种情况下,每个日志记录将在字典中查找其最近的父级,并将关联的级别用作过滤器。字典的值可以是 int 表示严重程度的数值、str 表示级别名称的字符串,或者 True 和 False 分别表示无条件授权和丢弃所有模块日志。为设置默认级别,应使用""作为模块名称,因为它是所有模块的父级(它不会抑制全局级别阈值)。
请注意,在调用日志记录方法时,关键字参数(如果有)会自动添加到额外的字典中,以方便上下文化(除了用于格式化)。
严重程度级别
每个记录的消息都与一个严重程度级别相关联。这些级别使得可以对消息进行优先级排序,并根据使用情况选择日志的冗长程度。例如,它允许将某些调试信息显示给开发人员,而对于运行应用程序的最终用户来说,这些信息是隐藏的。
每个添加的 sink 的 level 属性控制允许发出的日志消息的最低阈值。在使用日志记录器时,您负责配置适当的日志细粒度。可以使用 level() 方法添加更多自定义级别。
以下是标准级别及其默认的严重程度值,每个级别与同名的日志记录方法相关联:
| Level name | Severity value | Logger method |
|---|---|---|
TRACE |
5 | logger.trace() |
DEBUG |
10 | logger.debug() |
INFO |
20 | logger.info() |
SUCCESS |
25 | logger.success() |
WARNING |
30 | logger.warning() |
ERROR |
40 | logger.error() |
CRITICAL |
50 | logger.critical() |
record 字典
record 只是一个 Python 字典,可以通过 message.record 在 sink 中访问。它包含日志调用的所有上下文信息(时间、函数、文件、行号、级别等)。
可以在处理程序的格式中使用 record 的每个键,以便正确显示记录消息中的相应值(例如,"{level}" 将返回 "INFO")。某些记录的值是具有两个或多个属性的对象。可以使用 "{key.attr}" 格式化它们("{key}" 默认会显示其中一个)。
请注意,您可以使用 Python 的 str.format() 方法中可用的任何格式指令(例如,"{key: >3}" 将右对齐并在宽度为 3 个字符时填充)。这在时间格式化方面特别有用(见下文)。
| Key | 描述 | 属性 |
|---|---|---|
| elapsed | 程序启动以来经过的时间 | See datetime.timedelta |
| exception | 如果有异常的话,显示格式化后的异常信息;否则显示 None。 |
type, value, traceback |
| extra | 用户绑定的属性字典(参见 bind())。 |
None |
| file | 日志调用发生的文件。 | name (default), path |
| function | 日志调用发生的函数。 | None |
| level | 用于记录消息的严重级别。 | name (default), no, icon |
| line | 源代码中的行号。 | None |
| message | 已记录的消息(尚未格式化)。 | None |
| module | 在发出日志调用的模块。 | None |
| name | 发出日志调用的模块的 __name__ 属性。 |
None |
| process | 发出日志调用所在的进程。可以使用进程的名称或标识符来表示。 | name, id (default) |
| thread | 发出日志调用所在的线程。可以使用线程的名称或标识符来表示。默认情况下,使用线程的标识符作为线程的表示。 | name, id (default) |
| time | 发出日志调用时的本地时间。这是一个带有时区信息的datetime对象。 |
See datetime.datetime |
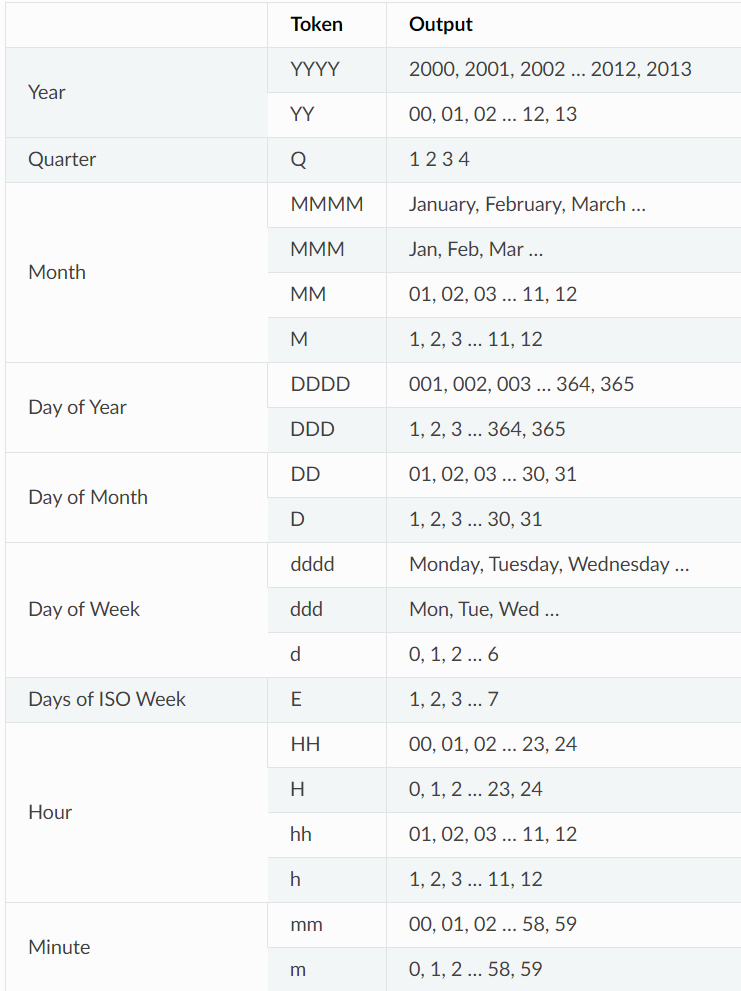
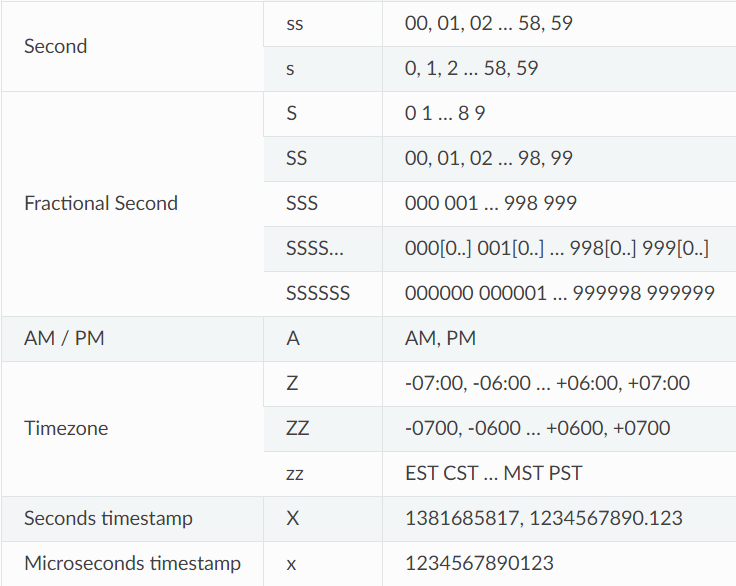
时间格式化
要使用您喜欢的时间表示方式,您可以直接在处理器格式的时间格式化指定符中设置,例如format="{time:HH:mm:ss} {message}"。请注意,此日期时间表示您的本地时间,并且它也被设置为具有时区意识,因此您可以显示UTC偏移量以避免歧义。
时间字段可以使用更人性化的标记进行格式化。这些标记是@sdispater的Pendulum库使用的子集。要转义标记,只需在其周围加上方括号,例如"[YY]"将直接显示"YY"。
如果您希望显示UTC时间而不是本地时间,可以在时间格式的最后添加"!UTC",例如{time:HH:mm:ss!UTC}。这样做会在格式化之前将日期时间转换为UTC。
如果没有使用时间格式化指定符,例如format="{time} {message}",默认格式将使用ISO 8601格式。
The file sinks
若使用str或pathlib.Path作为日志输出目标,将打开相应的文件以写入日志。路径中还可以包含特殊的"{time}"字段,该字段将在创建文件时使用当前日期进行格式化。
在记录每条消息之前,会进行轮换检查。如果已存在与要创建的文件同名的现有文件,则将在其基本名称后添加日期,以避免文件覆盖。此参数接受以下内容:
- 整数:表示在当前记录的文件大小达到该字节数之前,将关闭当前日志文件并启动新的日志文件。
- datetime.timedelta:指定每次轮换的频率。
- datetime.time:指定每日轮换应发生的小时数。
- 字符串:以人类可读的方式指定上述类型之一的参数。例如:"100 MB"、"0.5 GB"、"1 month 2 weeks"、"4 days"、"10h"、"monthly"、"18:00"、"sunday"、"w0"、"monday at 12:00"等。
- 可调用对象:在记录之前调用,接受两个参数:记录的消息和文件对象。如果应立即进行轮换,则返回True;否则返回False。
保留(Retention)功能发生在轮换或日志输出目标停止时(如果未设置轮换)。文件的选择基于与日志文件匹配的模式"basename(.).ext(.)"(时间字段将事先替换为.*)。
该参数接受以下内容:
- 整数:指定要保留的日志文件数量,旧文件将被删除。
- datetime.timedelta:指定要保留的文件的最长时间。
- 字符串:以人类可读的方式指定要保留的文件的最长时间。例如:"1 week, 3 days"、"2 months"等。
- 可调用对象:在保留过程之前调用,接受日志文件列表作为参数,并可以进行自定义处理(移动文件、删除文件等)。
压缩(Compression)功能发生在轮换或日志输出目标停止时(如果未设置轮换)。该参数接受以下内容:
- 字符串:指定压缩或归档文件的扩展名。可以是以下之一:"gz"、"bz2"、"xz"、"lzma"、"tar"、"tar.gz"、"tar.bz2"、"tar.xz"、"zip"。
- 可调用对象:在文件终止之前调用,接受日志文件的路径作为参数,并可以进行自定义处理(自定义压缩、网络发送、删除等)。
无论哪种方式,如果使用自定义函数,要特别小心不要在函数内部使用日志记录器,否则可能会导致程序死锁。
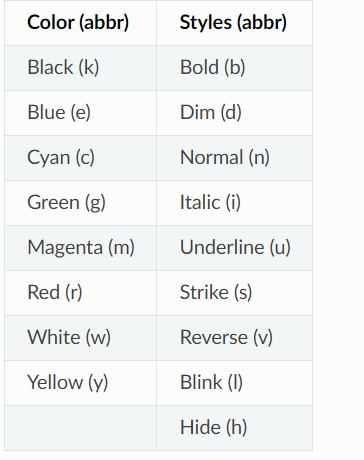
颜色标记
要为日志添加颜色,只需使用适当的标记将格式字符串括起来(例如<red>some message)。如果输出目标不支
持ANSI代码,则会自动删除这些标记。为了方便起见,您可以使用</>来关闭最后一个打开的标记,而无需重复使用标记名称(例如<red>another message</>)。
特殊标记<level>(可缩写为<lvl>)将根据配置的消息级别颜色进行转换。
无法识别的标记将在解析过程中引发异常,以通知您可能的误用。如果希望以文字形式显示标记标记,可以在标记前添加反斜杠进行转义,例如<blue>。如果出于某种原因,您需要以编程方式转义字符串,请注意,在内部用于解析标记标记的正则表达式为r"\?</?((?:[fb]g\s)?[^<>\s]*)>"。
请注意,在使用opt(colors=True)记录消息时,完全忽略格式化参数(args和kwargs)中包含的颜色标记。如果需要记录包含可能干扰颜色标记的标记的字符串(在这种情况下,请不要使用f-string)。
以下是可用的标记(请注意,兼容性可能因终端而异):

环境变量
sink参数的默认值可以进行完全定制。这在您不喜欢预配置的日志格式时特别有用。
可以通过设置LOGURU_[PARAM]环境变量来修改每个add()方法的默认参数。例如,在Linux上:export LOGURU_FORMAT="{time} - {message}"或export LOGURU_DIAGNOSE=NO。
默认级别的属性也可以通过设置LOGURU_[LEVEL]_[ATTR]环境变量来修改。例如,在Windows上:setx LOGURU_DEBUG_COLOR "
如果要禁用预配置的sink,可以将LOGURU_AUTOINIT变量设置为False。
在Linux上,您可能需要编辑~/.profile文件以使更改持久化。在Windows上,请不要忘记重新启动终端以使更改生效。
示例:
logger.add(sys.stdout, format="{time} - {level} - {message}", filter="sub.module")
logger.add("file_{time}.log", level="TRACE", rotation="100 MB")
def debug_only(record):
... return record["level"].name == "DEBUG"
...
>>> logger.add("debug.log", filter=debug_only) # Other levels are filtered out
def my_sink(message):
... record = message.record
... update_db(message, time=record["time"], level=record["level"])
...
>>> logger.add(my_sink)
level_per_module = {
... "": "DEBUG",
... "third.lib": "WARNING",
... "anotherlib": False
... }
>>> logger.add(lambda m: print(m, end=""), filter=level_per_module, level=0)
async def publish(message):
... await api.post(message)
...
>>> logger.add(publish, serialize=True)
from logging import StreamHandler
>>> logger.add(StreamHandler(sys.stderr), format="{message}")
class RandomStream:
... def __init__(self, seed, threshold):
... self.threshold = threshold
... random.seed(seed)
... def write(self, message):
... if random.random() > self.threshold:
... print(message)
...
>>> stream_object = RandomStream(seed=12345, threshold=0.25)
>>> logger.add(stream_object, level="INFO")
Logger.remove
Logger.remove(handler_id=None)
您可以使用remove()方法从日志器中移除先前添加的处理程序,从而停止将日志发送到该处理程序的目标位置。
以下是方法的参数和示例:
-
参数:
handler_id(int or None):要移除的处理程序的ID,与其在添加(add())方法中返回的ID相同。如果为None,则移除所有处理程序。预先配置的处理程序的ID保证为0。
-
抛出异常:
ValueError:如果handler_id不为None,但没有具有该ID的活动处理程序。
示例:
i = logger.add(sys.stderr, format="{message}")
logger.info("Logging")
logger.remove(i)
logger.info("No longer logging")
Logger.complete
Logger.complete()
等待处理程序中使用enqueue=True添加的所有日志消息被处理后,等待异步任务的结束。
该方法分为两个步骤:首先等待所有添加到处理程序的日志消息(使用enqueue=True)被处理,然后返回一个可等待对象,用于完成由协程处理程序添加到事件循环中的所有日志任务。
它可以从非异步代码中调用。特别推荐在使用多进程时,确保将消息放入内部队列后再离开子进程。
在执行asyncio.run()或loop.run_until_complete()执行的协程结束之前,应等待返回的对象。方法会先调用asyncio.get_running_loop()函数,仅等待在与当前循环相同的循环中调度的任务。
返回值:
awaitable:一个可等待对象,在等待时确保所有异步日志调用都已完成。
示例:
# 异步
async def sink(message):
await asyncio.sleep(0.1) # IO processing...
print(message, end="")
async def work():
logger.info("Start")
logger.info("End")
await logger.complete()
>>>logger.add(sink)
1
>>>asyncio.run(work())
Start
End
def process():
logger.info("Message sent from the child")
logger.complete()
logger.add(sys.stderr, enqueue=True)
1
process = multiprocessing.Process(target=process)
process.start()
process.join()
Message sent from the child
Logger.catch
catch(
exception=<class 'Exception'>,
*,
level='ERROR',
reraise=False,
onerror=None,
exclude=None,
default=None,
message="An error has been caught in function '{record[function]}', process '{record[process].name}' ({record[process].id}), thread '{record[thread].name}' ({record[thread].id}):")
返回一个装饰器,用于自动记录可能捕获的错误并记录在被包装的函数中。
这对于确保意外异常被记录非常有用,可以将整个程序包装在此方法中。在使用线程传播错误到主记录器线程时,装饰Thread.run()方法非常有用。
请注意,变量值的可见性(使用来自@Qix-的better_exceptions库)取决于每个配置的处理程序的诊断选项。
返回的对象还可以用作上下文管理器。
参数:
exception(Exception, optional):要拦截的异常类型。如果需要捕获多个类型的异常,也可以使用异常元组。level(strorint, optional):记录消息时要使用的级别名称或严重性。reraise(bool, optional):是否应重新引发异常,从而将其传播给调用者。onerror(callable, optional):如果发生错误,将在记录消息后调用的函数。它应该接受异常实例作为其唯一参数。exclude(Exception, optional):一个异常类型(或类型元组),将故意忽略并传播给调用者,而不会被记录。default(Any, optional):如果发生错误但没有被重新引发,则由装饰的函数返回的值。message(str, optional):如果发生异常,将自动记录的消息。请注意,它将使用记录属性进行格式化。
返回值:
- 装饰器/上下文管理器:可用于装饰函数或作为上下文管理器以记录可能捕获的异常。
示例:
@logger.catch
def f(x):
100 / x
def g():
f(10)
f(0)
g()
# Output:
# ERROR - An error has been caught in function 'g', process 'Main' (367), thread 'ch1' (1398):
# Traceback (most recent call last):
# File "program.py", line 12, in <module>
# g()
# └ <function g at 0x7f225fe2bc80>
# File "program.py", line 10, in g
# f(0)
# └ <function f at 0x7f225fe2b9d8>
# File "program.py", line 6, in f
# 100 / x
# └ 0
# ZeroDivisionError: division by zero
with logger.catch(message="Because we never know..."):
main() # No exception, no logs
# 使用'onerror'来防止程序退出代码为0(如果'reraise=False'),同时避免堆栈跟踪在stderr上重复显示(如果'reraise=True')。
@logger.catch(onerror=lambda _: sys.exit(1))
def main():
1 / 0
Logger.opt
opt(*,
exception=None,
record=False,
lazy=False,
colors=False,
raw=False,
capture=True,
depth=0,
ansi=False)
对日志记录调用进行参数化,稍微更改生成的日志消息。
请注意,无法链接opt()调用,最后一个调用优先于其他调用,因为它将“重置”选项为其默认值。
参数:
exception(bool,tupleorException, optional):如果不为False,则格式化传递的异常并将其添加到日志消息中。可以是Exception对象或(type,value,traceback)元组,否则将从sys.exc_info()中获取异常信息。record(bool, optional):如果为True,可以使用记录字典来格式化日志消息,通过在日志消息中使用{record[key]}。lazy(bool, optional):如果为True,则用于格式化消息的日志调用属性应为仅在级别足够高时才调用的函数。如果不必要,可以使用此选项避免昂贵的函数调用。colors(bool, optional):如果为True,日志消息将根据可能包含的标记进行着色。raw(bool, optional):如果为True,则绕过每个处理程序的格式化,并将消息原样发送。capture(bool, optional):如果为False,则不会自动填充额外字典的日志消息的**kwargs(尽管它们仍然用于格式化)。depth(int, optional):指定要用于上下文化日志消息的堆栈跟踪。当从包装函数内部使用记录器以检索有价值的信息时,这非常有用。ansi(bool, optional):自版本0.4.1起已弃用:ansi参数将在Loguru 1.0.0中删除,它由更合适的名称colors替代。
返回值:
- Logger:包装核心记录器的记录器,但在发送之前适当地转换记录的消息。
示例:
try:
1 / 0
except ZeroDivisionError:
logger.opt(exception=True).debug("Exception logged with debug level:")
# Output:
# [18:10:02] DEBUG in '<module>' - Exception logged with debug level:
# Traceback (most recent call last, catch point marked):
# > File "<stdin>", line 2, in <module>
# ZeroDivisionError: division by zero
logger.opt(record=True).info("Current line is: {record[line]}")
# Output:
# [18:10:33] INFO in '<module>' - Current line is: 1
logger.opt(lazy=True).debug("If sink <= DEBUG: {x}", x=lambda: math.factorial(2**5))
# Output:
# [18:11:19] DEBUG in '<module>' - If sink <= DEBUG: 263130836933693530167218012160000000
logger.opt(colors=True).warning("We got a <red>BIG</red> problem")
# Output:
# [18:11:30] WARNING in '<module>' - We got a BIG problem
logger.opt(raw=True).debug("No formatting\n")
# Output:
# No formatting
logger.opt(capture=False).info("Displayed but not captured: {value}", value=123)
# Output:
# [18:11:41] Displayed but not
captured: 123
def wrapped():
logger.opt(depth=1).info("Get parent context")
def func():
wrapped()
func()
# Output:
# [18:11:54] DEBUG in 'func' - Get parent context
Logger.bind
bind(**kwargs)
将属性绑定到每个日志记录消息的额外字典中。
这用于为每个日志调用添加自定义上下文。
参数:
**kwargs:键和值之间的映射,将添加到额外字典中。
返回值:
- Logger:包装核心记录器的记录器,但发送带有自定义额外字典的记录。
示例:
logger.add(sys.stderr, format="{extra[ip]} - {message}")
class Server:
def __init__(self, ip):
self.ip = ip
self.logger = logger.bind(ip=ip)
def call(self, message):
self.logger.info(message)
instance_1 = Server("192.168.0.200")
instance_2 = Server("127.0.0.1")
instance_1.call("First instance")
# Output:
# 192.168.0.200 - First instance
instance_2.call("Second instance")
# Output:
# 127.0.0.1 - Second instance
Logger.contextualize
contextualize(**kwargs)
将属性绑定到上下文本地的额外字典中,在 with 块内部生效。
与 bind() 方法不同,这里不返回记录器对象,而是直接在原地修改和全局更新额外字典。最重要的是,它使用了 contextvars,这意味着上下文化的值对每个线程和异步任务都是唯一的。
一旦退出上下文管理器,额外字典将恢复其初始状态。
参数:
**kwargs:键和值之间的映射,将添加到上下文本地的额外字典中。
返回值:
- 上下文管理器 / 装饰器:一个上下文管理器(也可用作装饰器),在进入时绑定属性,并在退出时恢复额外字典的初始状态。
示例:
logger.add(sys.stderr, format="{message} | {extra}")
def task():
logger.info("Processing!")
with logger.contextualize(task_id=123):
task()
# Output:
# Processing! | {'task_id': 123}
logger.info("Done.")
# Output:
# Done. | {}
Logger.patch
patch(patcher)
将一个函数附加到每个日志记录调用创建的记录字典。
该函数可以用于在记录传递给处理程序之前动态修改记录。这允许在日志消息中填充“extra”字典的动态值,并且可以对日志消息记录进行高级修改。该函数在将日志消息发送给不同处理程序之前调用一次。
建议在记录字典的“extra”字典上应用修改,而不是直接在记录字典本身上进行修改,因为Loguru内部使用了一些值,对它们进行修改可能会产生意外结果。
记录器可以多次进行修补。在这种情况下,函数按添加它们的顺序调用。
参数:
patcher(可调用对象):将记录字典作为唯一参数传递给该函数。该函数负责原地更新记录,无需返回任何值,修改后的记录对象将被重复使用。
返回值:
- 记录器(Logger):包装了核心记录器,但在发送到添加的处理程序之前通过patcher函数进行处理的记录。
示例:
logger.add(sys.stderr, format="{extra[utc]} {message}")
def patcher(record):
record["extra"].update(utc=datetime.utcnow())
logger = logger.patch(patcher)
logger.info("That's way, you can log messages with time displayed in UTC")
def wrapper(func):
@functools.wraps(func)
def wrapped(*args, **kwargs):
logger.patch(lambda r: r.update(function=func.__name__)).info("Wrapped!")
return func(*args, **kwargs)
return wrapped
def recv_record_from_network(pipe):
record = pickle.loads(pipe.read())
level, message = record["level"], record["message"]
logger.patch(lambda r: r.update(record)).log(level, message)
Logger.level
level(name, no=None, color=None, icon=None)
您可以添加、更新或检索日志级别。
日志级别通过其名称定义,与其严重性编号、ANSI颜色标签和图标相关联,并且可以在运行时进行修改。要记录到自定义级别,您必须使用其名称,严重性编号与级别名称无关(这意味着多个级别可以共享相同的严重性)。
要添加新级别,需要提供其名称和编号。也可以指定颜色和图标,否则默认为空。
要更新现有级别,请将其名称与要更改的参数一起传递。一旦级别已添加,就无法修改其编号。
要检索级别信息,仅名称就足够了。
参数:
name(str):日志级别的名称。no(int):要添加或更新的级别的严重性。color(str):要添加或更新的级别的颜色标记。icon(str):要添加或更新的级别的图标。
返回值:
Level:一个命名元组,包含有关级别的信息。
抛出:
ValueError:如果没有使用该名称注册的级别。
示例:
level = logger.level("ERROR")
print(level)
# Level(name='ERROR', no=40, color='<red><bold>', icon='❌')
logger.add(sys.stderr, format="{level.no} {level.icon} {message}")
# 1
logger.level("CUSTOM", no=15, color="<blue>", icon="@")
# Level(name='CUSTOM', no=15, color='<blue>', icon='@')
logger.log("CUSTOM", "Logging...")
# 15 @ Logging...
logger.level("WARNING", icon=r"/!\")
# Level(name='WARNING', no=30, color='<yellow><bold>', icon='/!\\')
logger.warning("Updated!")
# 30 /!\ Updated!
Logger.disable
disable(name)
您可以禁用来自指定模块及其子模块的日志消息记录。
在使用Loguru的库开发中,开发人员绝对应该禁用它,以避免向用户发送与库无关的日志消息。
请注意,在某些罕见情况下,Loguru无法确定模块的__name__值。在这种情况下,记录中的record["name"]将等于None,因此None也是有效的参数。
参数:
name(str或None):要禁用的父模块的名称。
示例:
logger.info("Allowed message by default")
# [22:21:55] Allowed message by default
logger.disable("my_library")
logger.info("While publishing a library, don't forget to disable logging")
Logger.enable
enable(name)
您可以启用来自指定模块及其子模块的日志消息记录。
一般情况下,通过导入的使用Loguru的库会禁用日志记录,因此此函数允许用户无论如何接收这些消息。
要启用来自所有模块的所有日志消息,可以传递一个空字符串""。
参数:
name(str或None):要重新允许的父模块的名称。
示例:
logger.disable("__main__")
logger.info("Disabled, so nothing is logged.")
logger.enable("__main__")
logger.info("Re-enabled, messages are logged.")
# [22:46:12] Re-enabled, messages are logged.
Logger.configure
configure(*,
handlers=None,
levels=None,
extra=None,
patcher=None,
activation=None)
要配置核心日志记录器(core logger)。
需要注意的是,使用此函数设置的额外值在所有模块中都可用,因此这是设置整体默认值的最佳方法。
参数:
handlers(listofdict, optional):要添加的每个处理器的列表。列表应包含作为关键字参数传递给add()函数的参数字典。如果不为None,则首先删除所有先前添加的处理器。levels(listofdict, optional):要添加或更新的每个日志级别的列表。列表应包含作为关键字参数传递给level()函数的参数字典。这不会删除先前创建的级别。extra(dict, optional):包含绑定到核心日志记录器的其他参数的字典。如果在多个文件模块中调用了bind()方法并希望共享公共属性,则此参数非常有用。如果不为None,则会删除先前配置的额外字典。patcher(callable, optional):应用于所有模块中的每个日志消息的记录字典的函数。该函数应该直接在原地修改字典而不返回任何内容。该函数在可能通过patch()方法添加的函数之前执行。如果不为None,则会替换先前配置的patcher函数。activation(listoftuple, optional):一个包含(name,state)元组的列表,用于指示应启用(如果state为True)或禁用(如果state为False)哪些日志记录器。调用enable()和disable()的顺序根据列表的顺序进行。这不会修改先前激活的日志记录器,因此如果您需要一个新的起点,请在列表前面加上("",False)或("",True)。
返回:
list of int:一个包含添加的处理器的标识符(如果有的话)的列表。
示例:
logger.configure(
handlers=[
dict(sink=sys.stderr, format="[{time}] {message}"),
dict(sink="file.log", enqueue=True, serialize=True),
],
levels=[dict(name="NEW", no=13, icon="¤", color="")],
extra={"common_to_all": "default"},
patcher=lambda record: record["extra"].update(some_value=42),
activation=[("my_module.secret", False), ("another_library.module", True)],
)
[1, 2]
# Set a default "extra" dict to logger across all modules, without "bind()"
extra = {"context": "foo"}
logger.configure(extra=extra)
logger.add(sys.stderr, format="{extra[context]} - {message}")
logger.info("Context without bind")
# => "foo - Context without bind"
logger.bind(context="bar").info("Suppress global context")
# => "bar - Suppress global context"
Logger.static
staticparse(file, pattern, *, cast={}, chunk=65536)
解析原始日志并将每个条目提取为字典。
必须指定日志格式作为正则表达式模式,然后将其用于解析文件并根据正则表达式中存在的命名组检索每个条目。
参数:
- file (str、pathlib.Path 或文件对象):要解析的日志文件的路径,或者已经打开的文件对象。
- pattern (str 或 re.Pattern):用于日志解析的正则表达式模式,它应该包含命名组,这些命名组将包含在返回的字典中。
- cast (可调用对象或字典,可选):用于将解析的正则表达式组(一个包含字符串值的字典)原地转换为更适当类型的函数。如果传递的是字典,则应该是解析的日志字典的键与应该用于转换相关值的函数之间的映射关系。
- chunk (int,可选):在迭代日志时读取的字节数,这样可以避免一次性加载整个文件到内存中。
Yields:
- dict:将正则表达式命名组映射到匹配值的字典,如 re.Match.groupdict() 所返回的,并根据 cast 参数进行可选转换。
示例:
reg = r"(?P<lvl>[0-9]+): (?P<msg>.*)" # If log format is "{level.no} - {message}"
for e in logger.parse("file.log", reg): # A file line could be "10 - A debug message"
print(e) # => {'lvl': '10', 'msg': 'A debug message'}
caster = dict(lvl=int) # Parse 'lvl' key as an integer
for e in logger.parse("file.log", reg, cast=caster):
print(e) # => {'lvl': 10, 'msg': 'A debug message'}
def cast(groups):
if "date" in groups:
groups["date"] = datetime.strptime(groups["date"], "%Y-%m-%d %H:%M:%S")
with open("file.log") as file:
for log in logger.parse(file, reg, cast=cast):
print(log["date"], log["something_else"])
Logger.trace
trace(_Logger__message, *args, **kwargs)
使用严重级别“TRACE”记录 message.format(*args, **kwargs)。
Logger.debug
debug(_Logger__message, *args, **kwargs)
使用严重级别“DEBUG”记录 message.format(*args, **kwargs)。
Logger.info
info(_Logger__message, *args, **kwargs)
# 使用严重级别“INFO”记录 message.format(*args, **kwargs)。
Logger.success
success(_Logger__message, *args, **kwargs)
# 使用严重级别“SUCCESS”记录 message.format(*args, **kwargs)。
Logger.warning
warning(_Logger__message, *args, **kwargs)
# 使用严重级别“WARNING”记录 message.format(*args, **kwargs)。
Logger.error
error(_Logger__message, *args, **kwargs)
# 使用严重级别“ERROR”记录 message.format(*args, **kwargs)。
Logger.critical
critical(_Logger__message, *args, **kwargs)
# 使用严重级别“CRITICAL”记录 message.format(*args, **kwargs)。
Logger.exception
exception(_Logger__message, *args, **kwargs)
# 方便地记录带有异常信息的“ERROR”。
Logger.log
log(_Logger__level, _Logger__message, *args, **kwargs)
# 使用指定的严重级别 level 记录 message.format(*args, **kwargs)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号