

一、Flink提交任务的流程
Flink任务提交后,Client向HDFS上传Flink的jar包和配置,之后向Yarn ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动
ApplicationMaster,ApplicationMaster启动后加载Flink的jar包和配置构建环境,然后启动JobManager;之后Application Master向ResourceManager申请资源启动TaskManager
,ResourceManager分配Container资源后,由ApplicationMaster通知资源所在的节点的NodeManager启动TaskManager,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动向JobManager发送心跳,并等待JobManager向其分配任务。
二、Flink任务调度原理
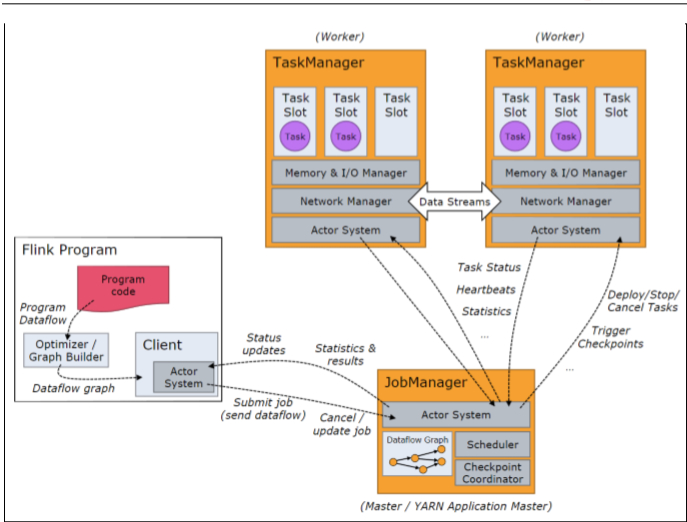
1、Program Code:我们编写的Flink应用程序代码。
2、JobClient:JobClient不是Flink程序执行的内部部分,但它是任务执行的起点。JobClient负责接受用户的程序代码,然后创建数据流,将数据流提交给
JobManager以便进一步执行。执行完成后,JobClient将结果返回给用户。
3、JobManager:主进程(也称为作业管理器)协调和管理程序的执行。它的主要指责包括安排任务,管理checkpoint,故障恢复等。机器集群中至少要有一个master,
master负责调度task,协调checkpoints和容灾,高可用设置的话可以有多个master,但要保证一个是leader,其他是standby;JobManager包含ActorSystem、Scheduler、
CheckPoint三个重要的组件。
4、TaskManager:从JobManager处接收需要部署的Task。TaskManager是在JVM中一个或多个线程中执行任务的工作节点。任务执行的并行性由每个TaskManager上可用
的任务槽决定。每个任务代表分配给任务槽的一组资源。例如:如果TaskManager有四个插槽,那么它将为每个插槽分配25%的内存。可以在任务槽中运行一个或多个线程。
同一插槽中的线程共享相同的JVM。同一JVM中的任务共享TCP连接和心跳信息。TaskManager的一个Slot代表一个可用线程,该线程具有固定的内存,注意Slot只对内存隔离,
没有对CPU隔离。
默认情况下,Flink允许子任务共享Slot,即使它们是不同的task的subtask,只要他们来自相同的job。这种共享可以有更好的资源利用率。
TaskManager是Flink的worker节点,他负责Flink中本机slot资源的管理以及具体task的执行。
TaskManager上的基本资源单位是slot,一个作业的task最终会部署在一个TM的slot上运行,TM会负责维护本地的slot资源列表,
并来与Flink Master和JobManager通信。
三、Work与Slot
每一个worker(TaskManager)是一个JVM进程,他可能会在独立的线程上执行一个或多个subtask。为了控制一个worker能接收到多少个task,worker通过task slot来进行控制
(一个worker至少要有一个task slot)。
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个subtask将不需要跟来自其他的job的subtask竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离
task的受管理的内存。
通过调整task slot的数量,允许用户定义subtask之间如何互相隔离。如果一个TaskManager一个slot,那将意味着每个task group运行在独立的JVM中(该JVM可能是通过一个特定的容器启动的),而一个TaskManager多个slot意味着更多的subtask可以共享同一个JVM。而在同一个JVM进程中的task将共享TCP连接(基于多路复用)和心跳信息。他们也
可能共享数据集和数据结构,因此这减少了每个task的负载。
四、Flink程序架构
每个Flink程序都包含以下的若干流程
获得一个执行环境:(Execution Environment) 相当于Spark中的SparkContext
加在/创建初始数据:(Source)
指定转换这些数据:(Transformation)
指定放置计算结果的位置:(Sink)
触发程序执行
五、 Environment
执行环境StreamExecutionEnvironment是所有Flink程序的基础。
StreamExecutionEnvironment.getExecutionEnvironment(根据运行情况,返回本地或者集群的运行环境) 默认分区是8
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境:如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,
getEexecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
StreamExecutionEnvironment.createLocalEnvironment(1) -》开始只有一个分区
返回本地执行环境,需要在调用时指定默认的并行度。
StreamExecutionEnvironment.createRemoteEnvironment("localhost",8800)
返回集群执行环境,将Jar提交到远程服务器。需要在调用时指定JobManager的IP和端口号,并指定要在集群中运行的Jar包。
六、Source
1、基于File的数据源
1.1、readTextFile(path)
1.1、readTextFile(path)
一列一列的读取遵循TextInputFormat规范的文本文件,并将结果作为String返回。

