

当然,在学习过程中也是参考了很多其他的资料,代码都是一行一行敲出来的。
一、将多个文件合并成一个文件,避免频繁的打开和关闭
1 import sys 2 3 for line in sys.stdin: 4 ss = line.strip().split('\t') 5 file_name = ss[0].strip() 6 file_context = ss[1].strip() 7 word_list = file_context.split(' ') 8 9 word_set = set() 10 for word in word_list: 11 word_set.add(word) 12 13 for word in word_set: 14 print '\t'.join([word, '1'])
执行命令:就可以得到合并后的文件啦!!!
python convert.py input_tfidf_dir/ > merge_files.data
tf-idf计算流程图:
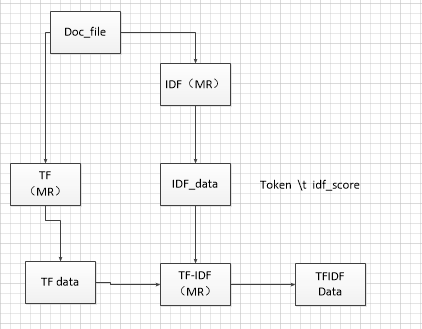
二 、计算IDF的值:
map阶段:读取每一行
1 import sys 2 3 for line in sys.stdin: 4 ss = line.strip().split('\t') 5 file_name = ss[0].strip() 6 file_context = ss[1].strip() 7 word_list = file_context.split(' ') 8 9 word_set = set() 10 for word in word_list: 11 word_set.add(word) 12 13 for word in word_set: 14 print '\t'.join([word, '1'])
reduce阶段:
1 import sys 2 import math 3 4 current_word = None 5 doc_cnt = 508 6 count_pool = [] 7 sum = 0 8 9 for line in sys.stdin: 10 ss = line.strip().split('\t') 11 if len(ss) != 2: 12 continue 13 14 word, val = ss 15 if current_word == None: 16 current_word = word 17 if current_word != word: 18 for count in count_pool: 19 sum += count 20 21 idf_score = math.log(float(doc_cnt) / (float(sum) + 1)) 22 print '\t'.join([current_word, str(idf_score)]) 23 24 current_word = word 25 count_pool = [] 26 sum = 0 27 28 count_pool.append((int(val))) 29 30 for count in count_pool: 31 sum += count 32 33 idf_score = math.log(float(doc_cnt) / (float(sum) + 1)) 34 print '\t'.join([current_word, str(idf_score)])
三、计算TF的值:
1 # 计算tf 2 # 读取合并后的数据 3 # 执行命令 cat merge_files.data | python map_tf.py mapper_func idf.data 4 5 import sys 6 7 word_dict = {} 8 idf_dict = {} 9 10 # 读取计算的idf数据文件 11 def read_idf_file_func(idf_file_fd): 12 with open() as fd: 13 for line in fd: 14 ss = line.strip().split('\t') 15 if len(ss) != 2: 16 continue 17 token = ss[0].strip() 18 idf_score = ss[1].strip() 19 idf_dict[token] = float(idf_score) 20 return idf_dict 21 22 # cat merge_files.data | python map_tf.py mapper_func 23 def mapper_func(idf_file_fd): 24 idf_dict = read_idf_file_func(idf_file_fd) 25 # 标准输入 26 for line in sys.stdin: 27 ss = line.strip().split('\t') 28 file_name = ss[0].strip() 29 file_context = ss[1].strip() 30 word_list = file_context.split(' ') 31 32 for word in word_list: 33 if word not in word_dict: 34 word_dict[word] = 1 35 else: 36 word_dict[word] += 1 37 38 for k,v in word_dict.item(): 39 if k not in idf_dict: 40 continue 41 print(file_name,k,v,idf_file_fd[k]) 42 print(k,v) 43 44 if __name__ == "__main__": 45 module = sys.modules[__name__] 46 func = getattr(module, sys.argv[1]) 47 args = None 48 if len(sys.argv) > 1: 49 args = sys.argv[2:] 50 func(*args)

