结对第二次作业
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业 |
| 结对学号 | 221801112|221801116 |
| 这个作业的目标 | 1.根据网页原型,搭建web网站 2.学习Github协作编程 3.学习网站搭建的前后端技术 4.将网站部署到云服务器 |
| 其他参考文献 | SpringBoot2入门 centos服务器使用教学 bootstrap官方文档 |
一、git仓库链接和代码规范链接
1.1 github仓库链接
1.2 代码规范链接
1.3 项目链接
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 45 | 30 |
| Development | 开发 | 4335 | 4670 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 240 |
| • Design Spec | • 生成设计文档 | 50 | 40 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| • Design | • 具体设计 | 40 | 50 |
| • Coding | • 具体编码 | 4000 | 4200 |
| • Code Review | • 代码复审 | 30 | 35 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 90 | 110 |
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 50 |
| 合计 | 4470 | 4810 |
三、成品展示
3.1 登录注册
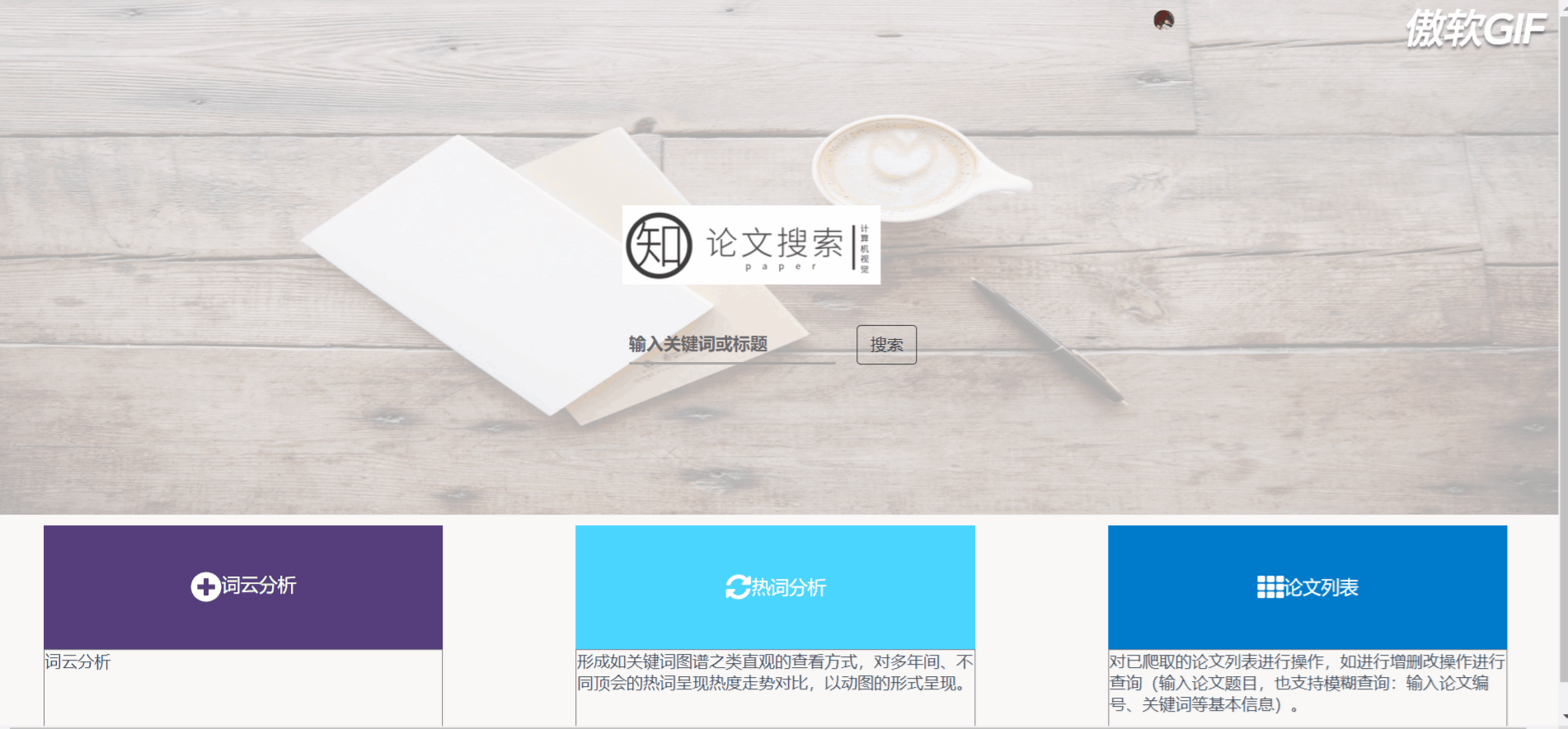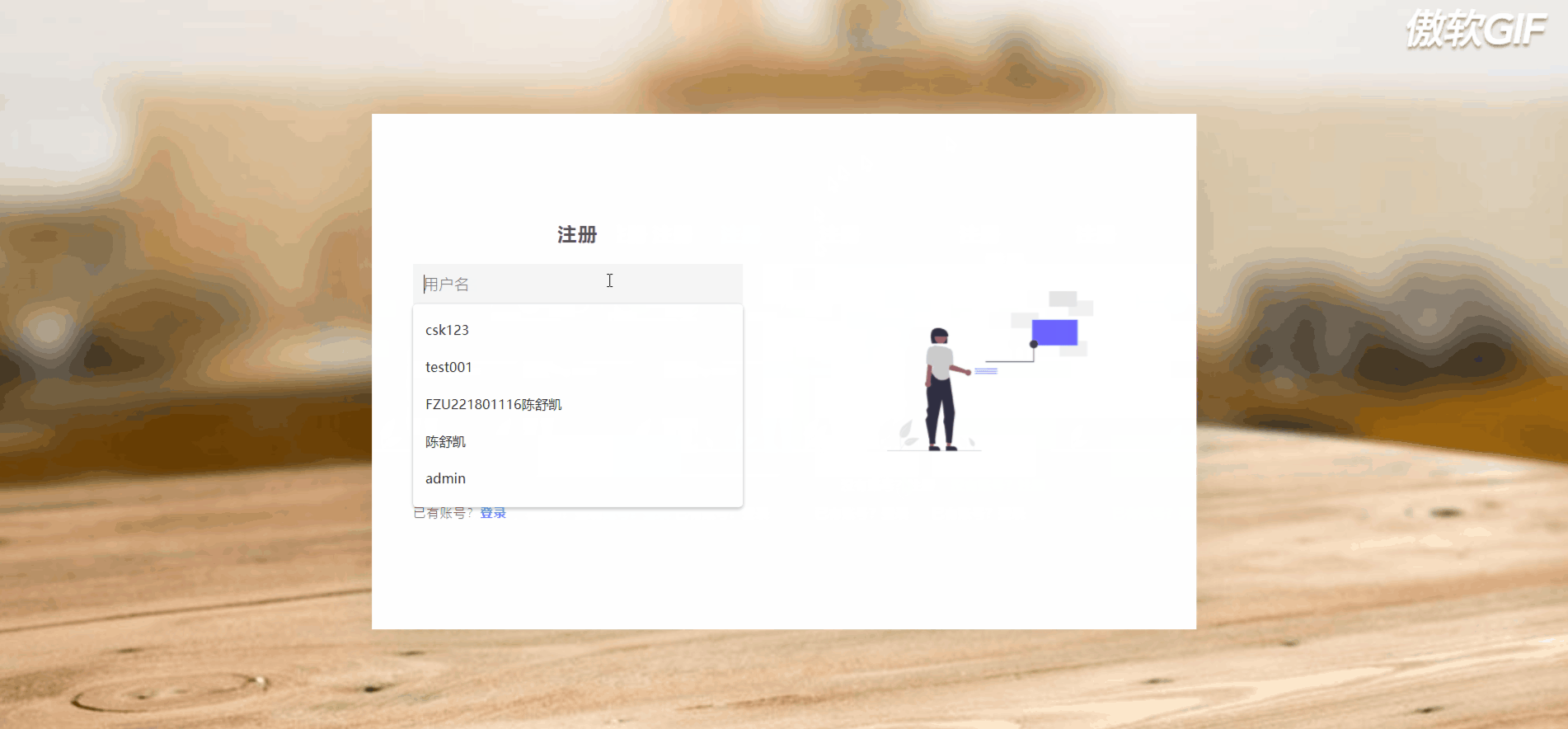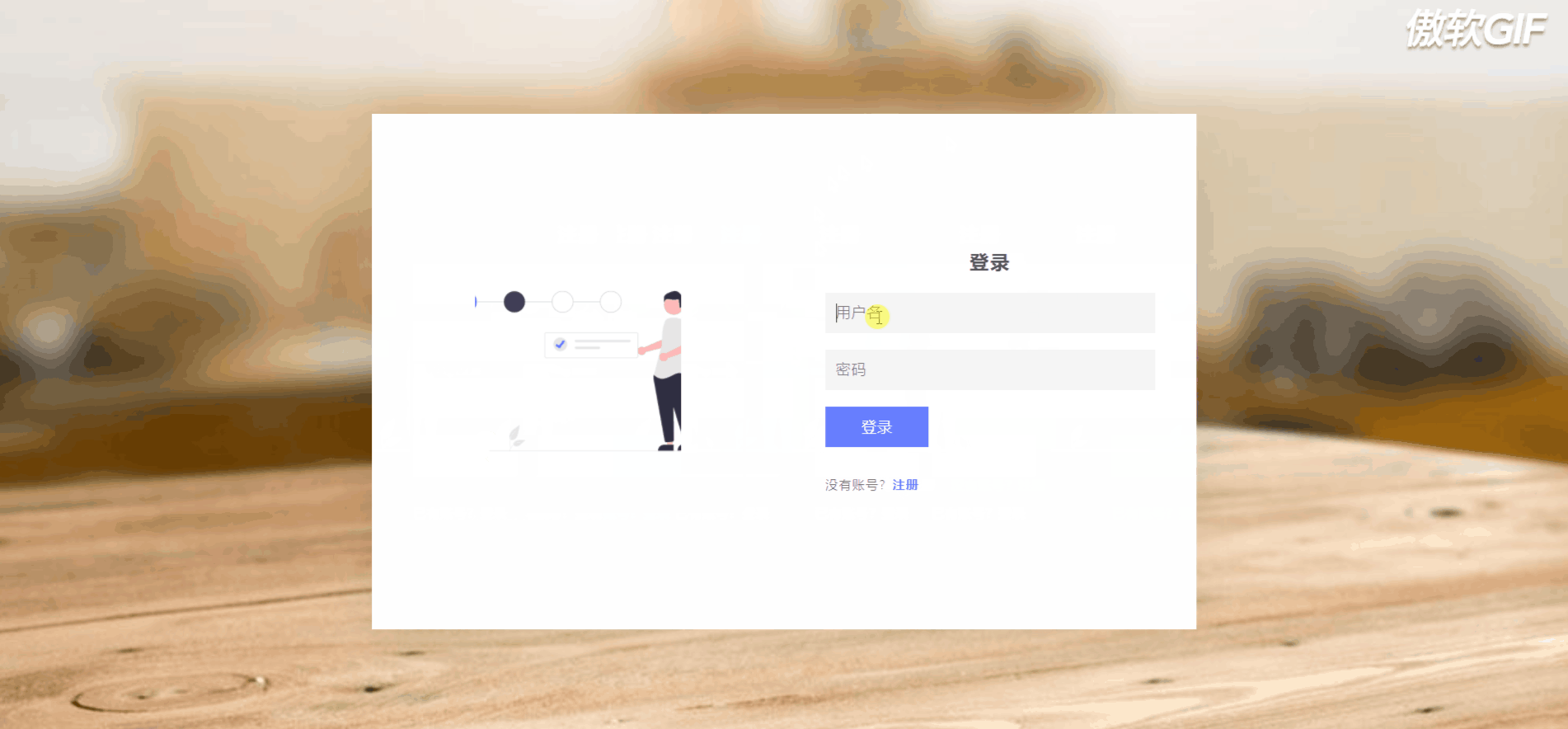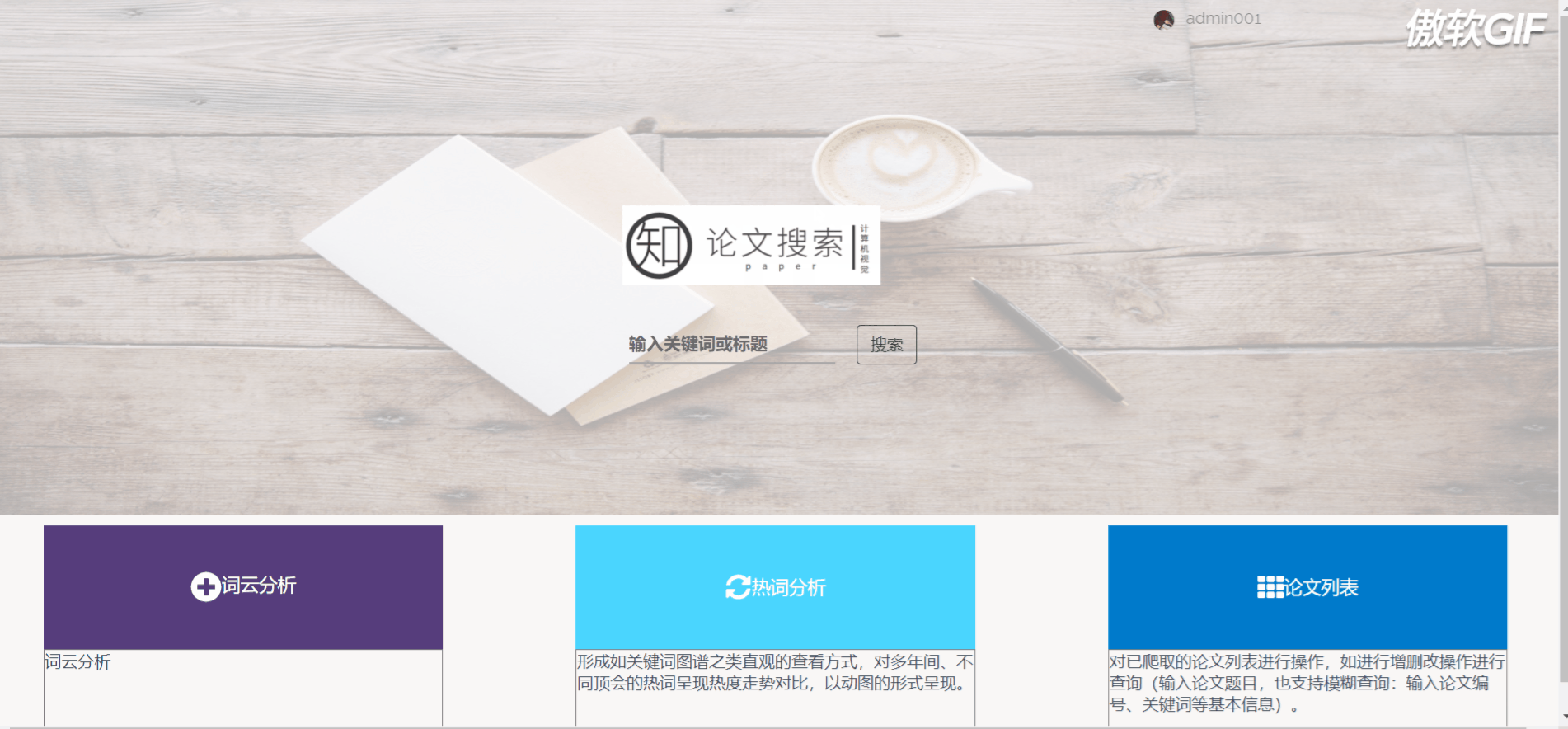
3.2 首页搜索跳转

3.3 论文列表跳转

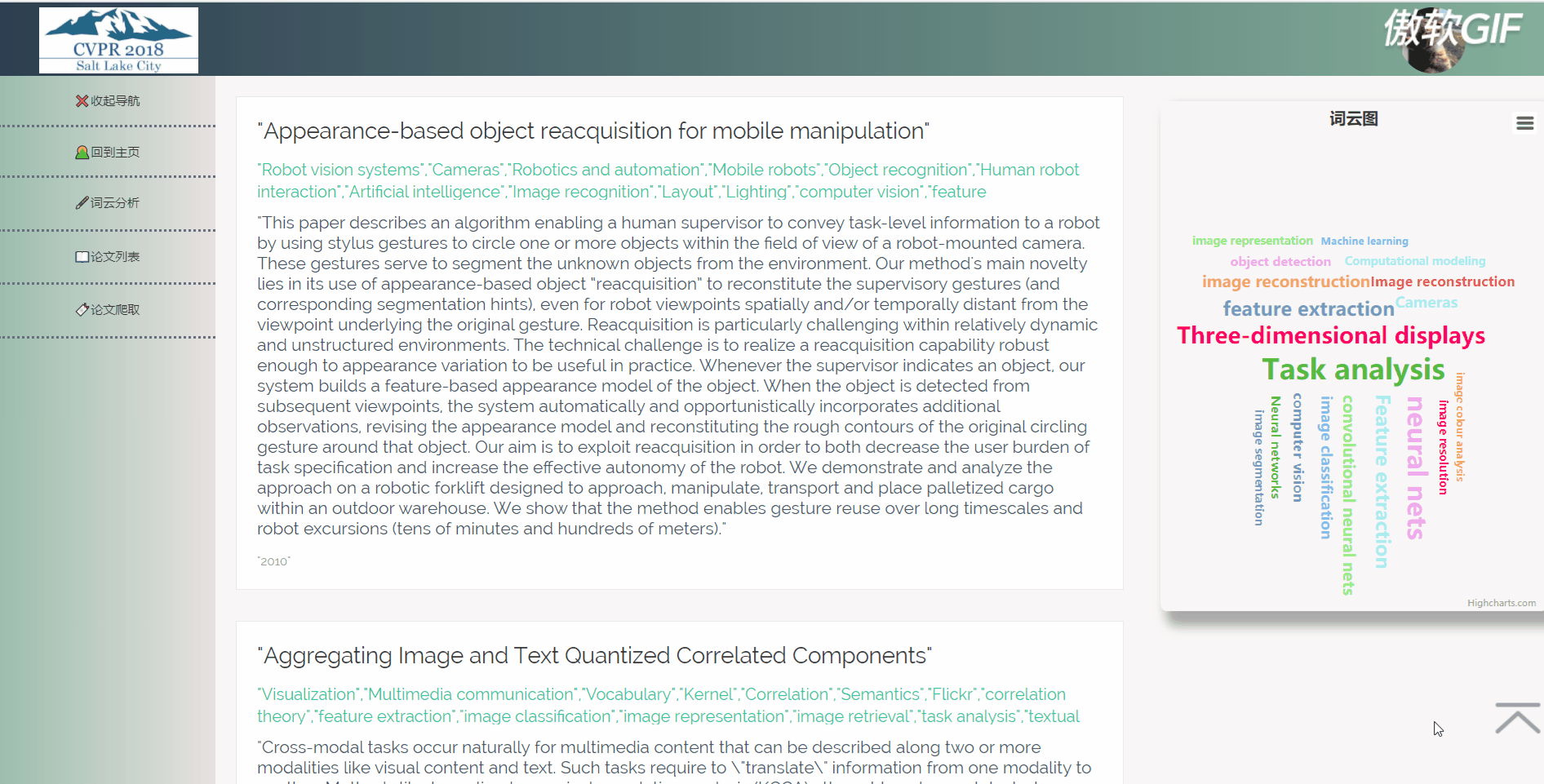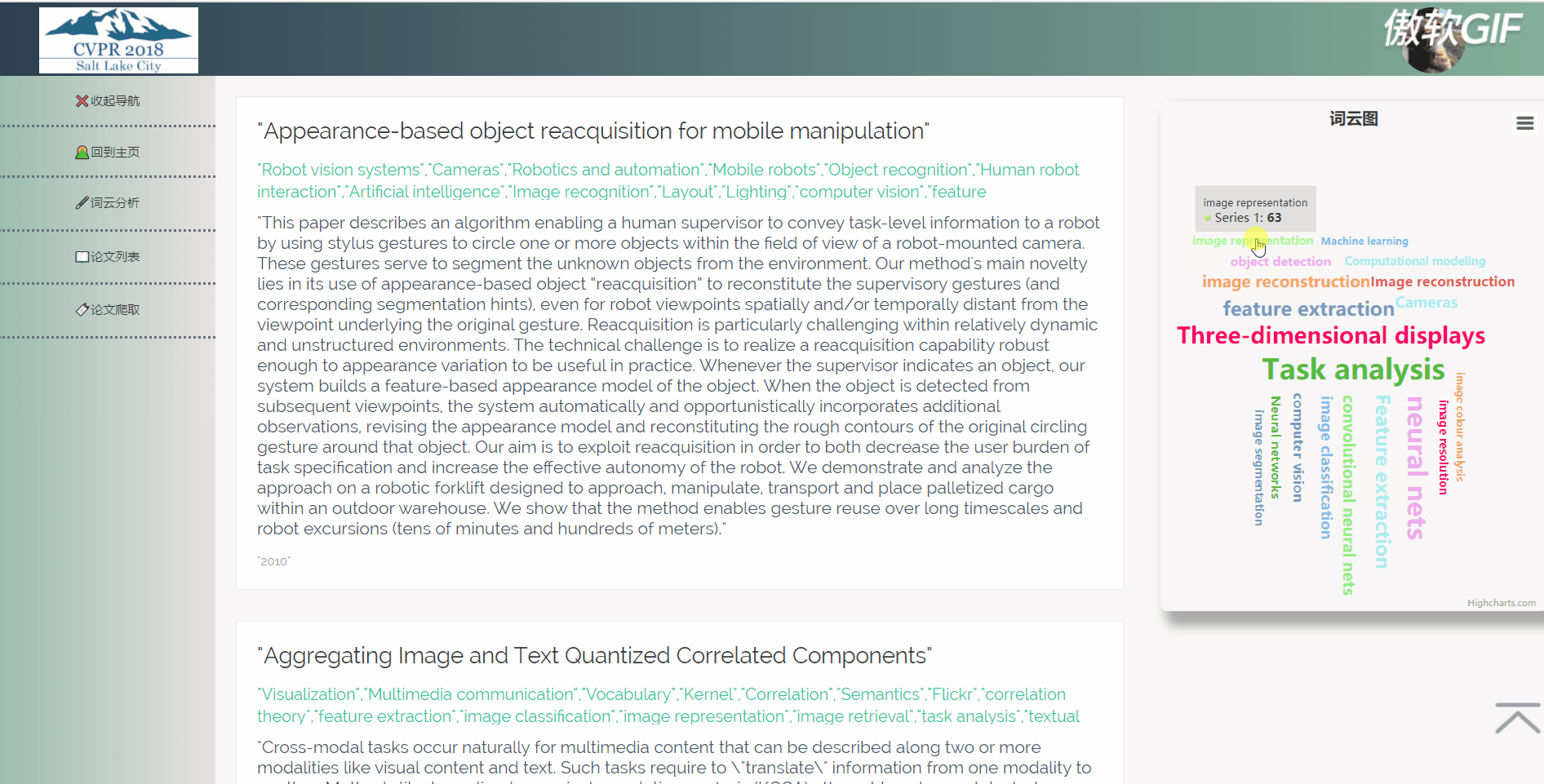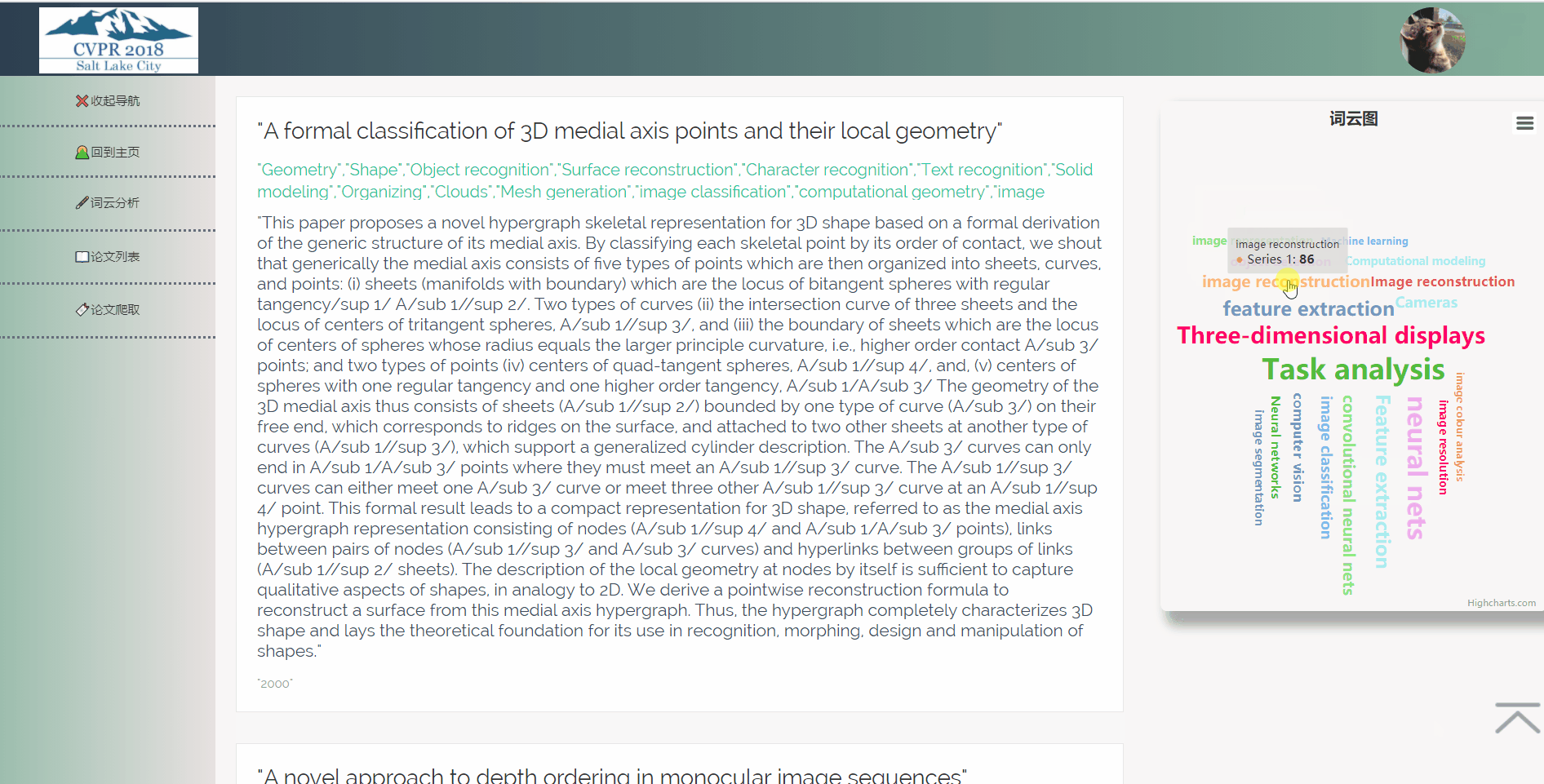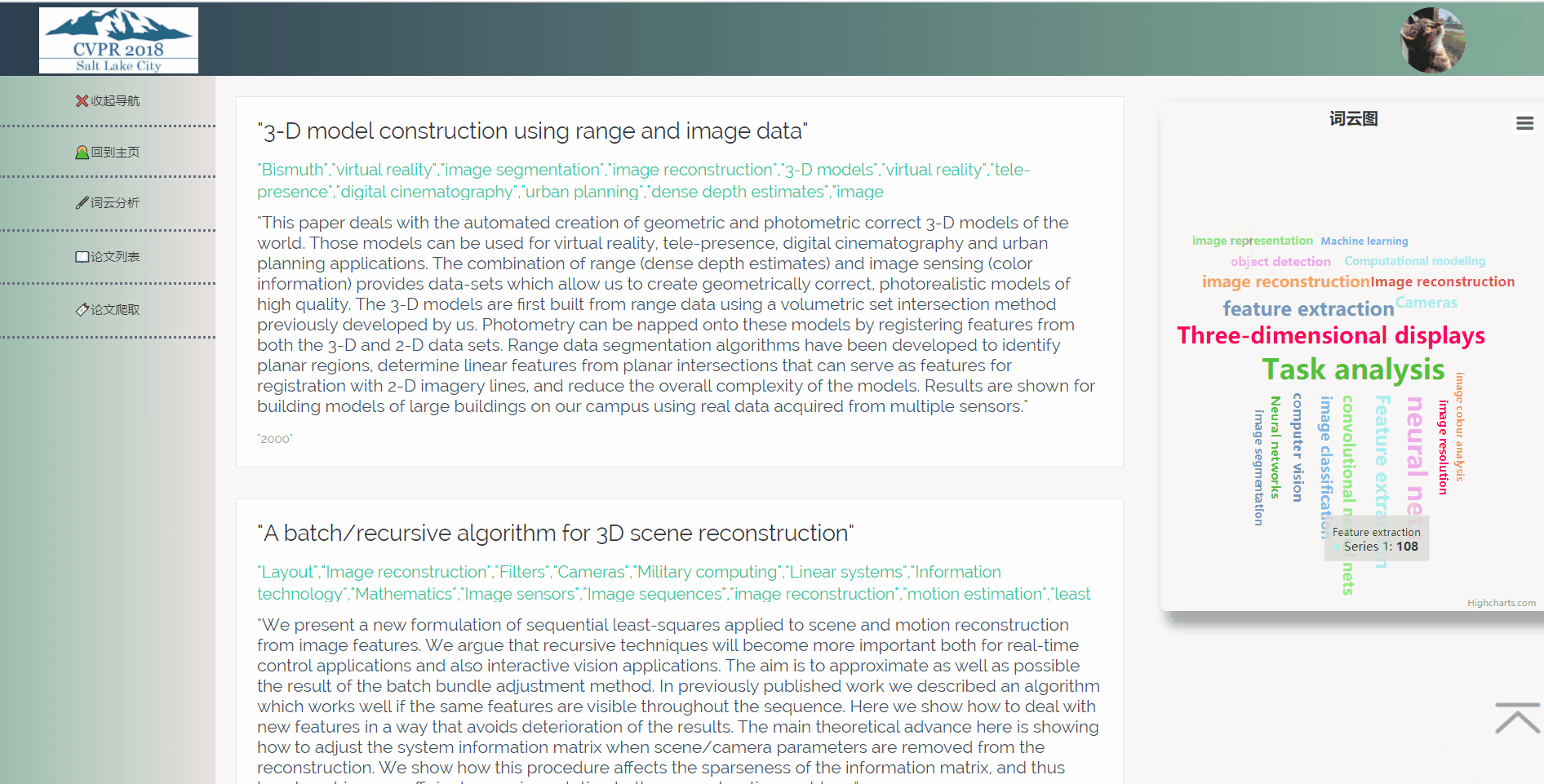
3.4 词云分析
3.5 点击论文出现详情页(含有原文链接)
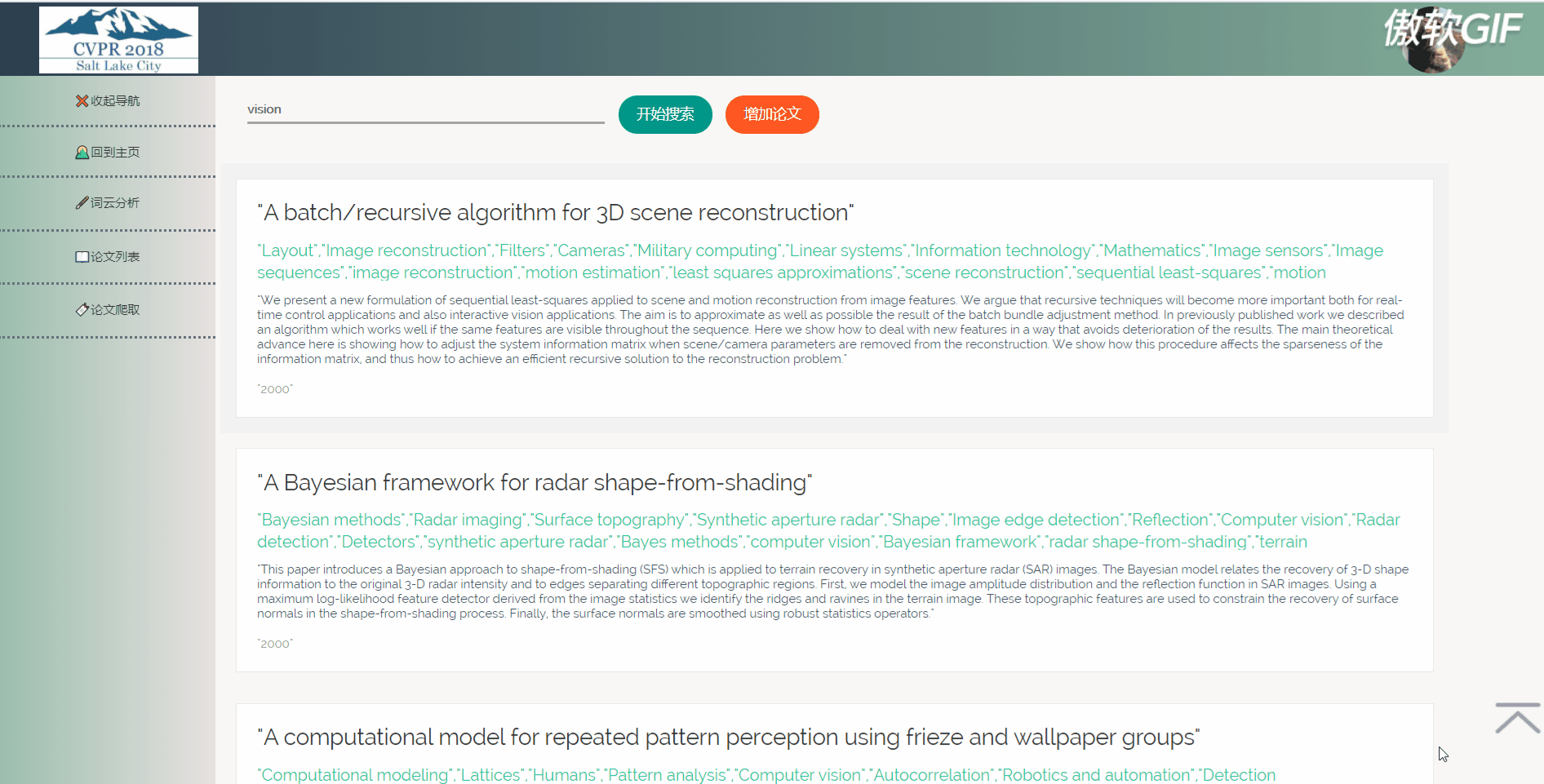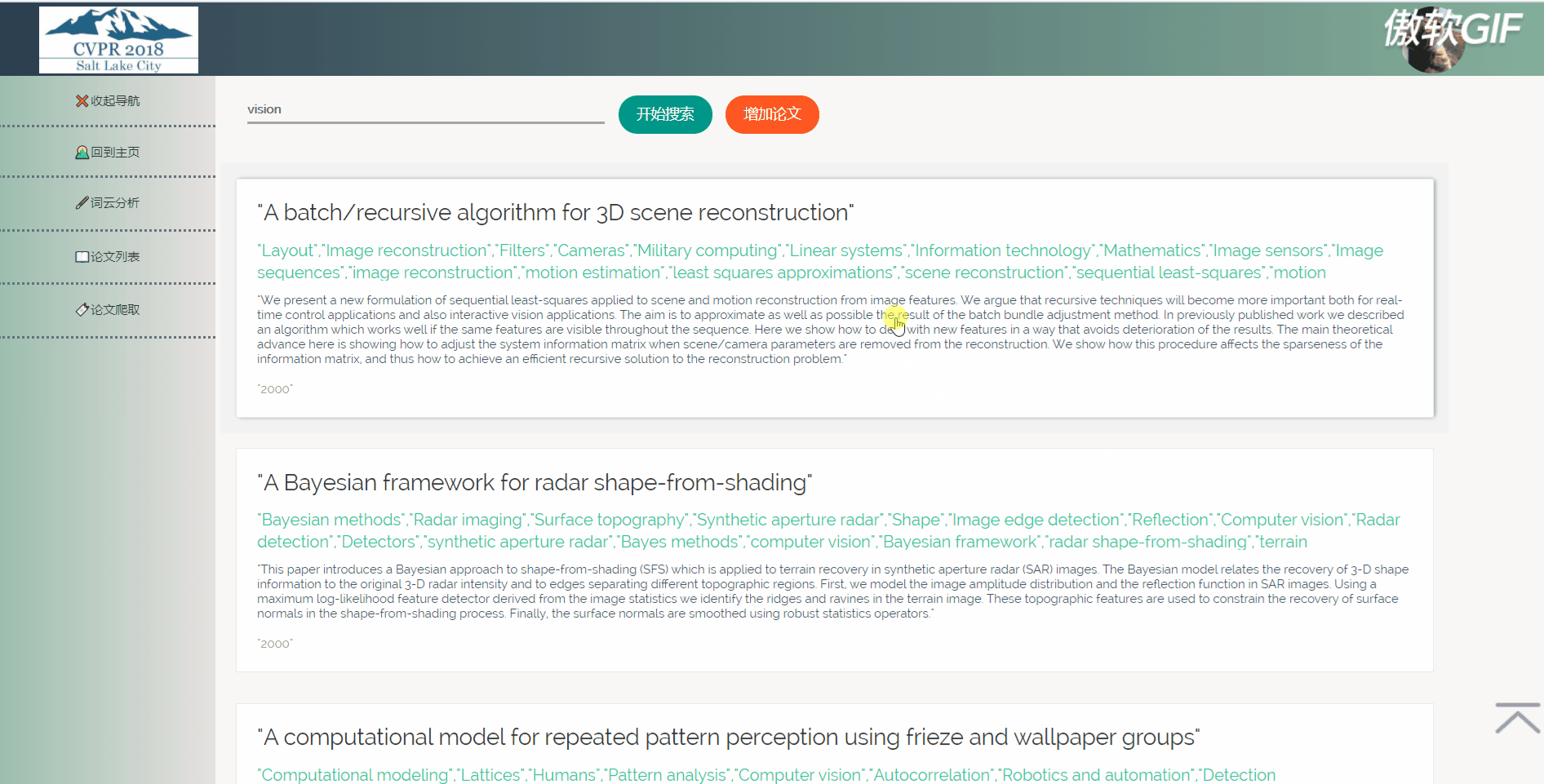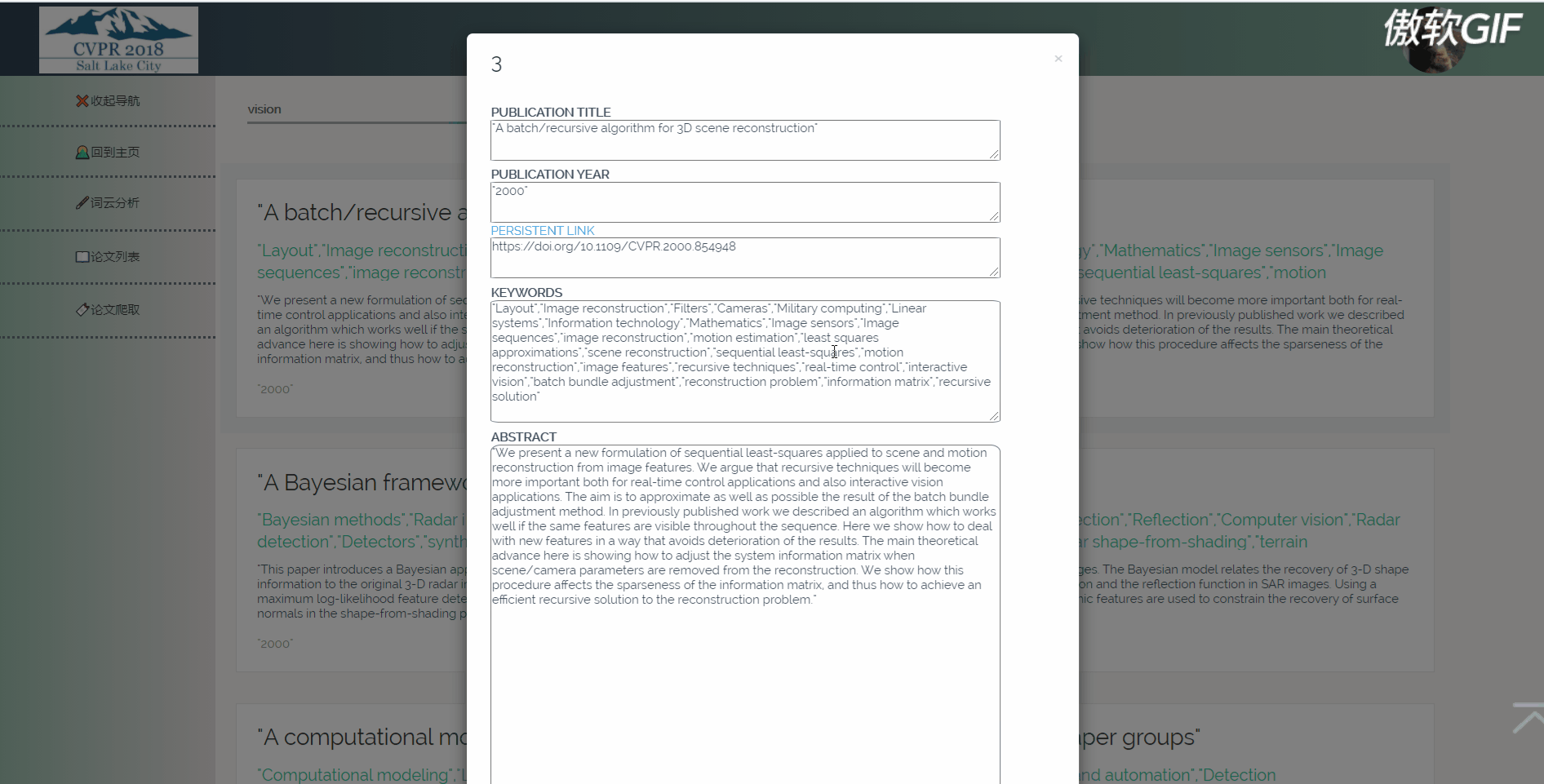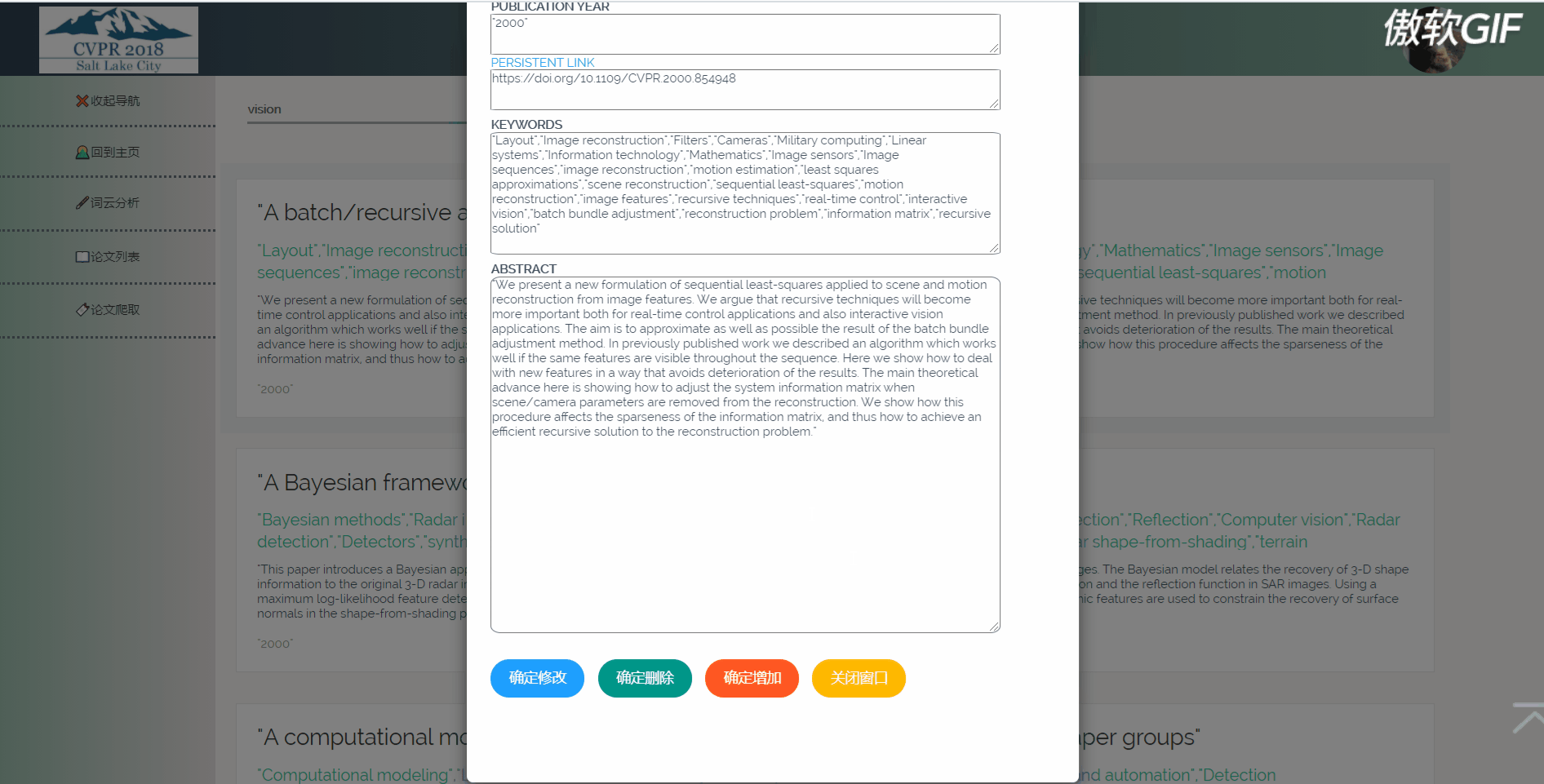
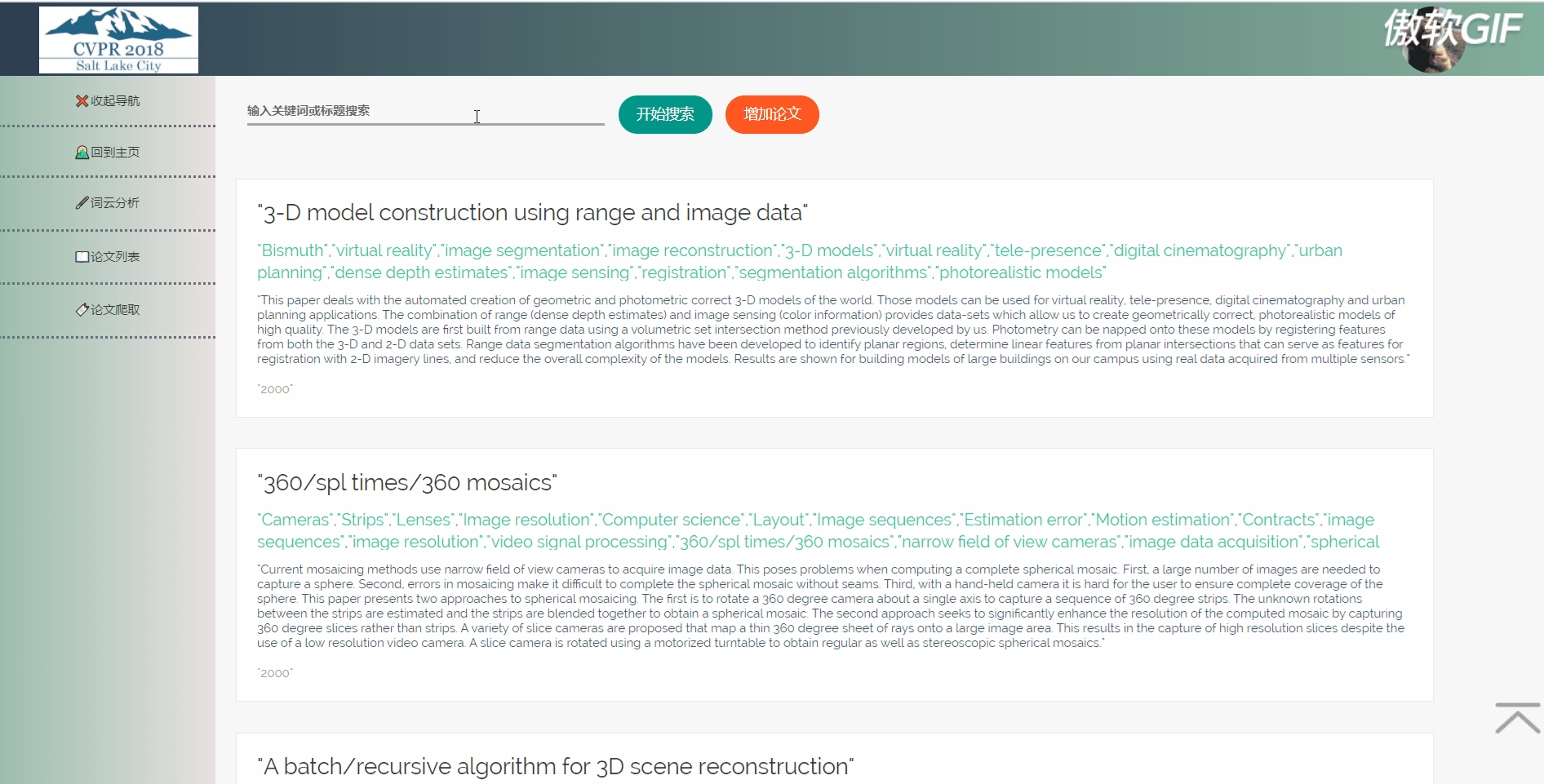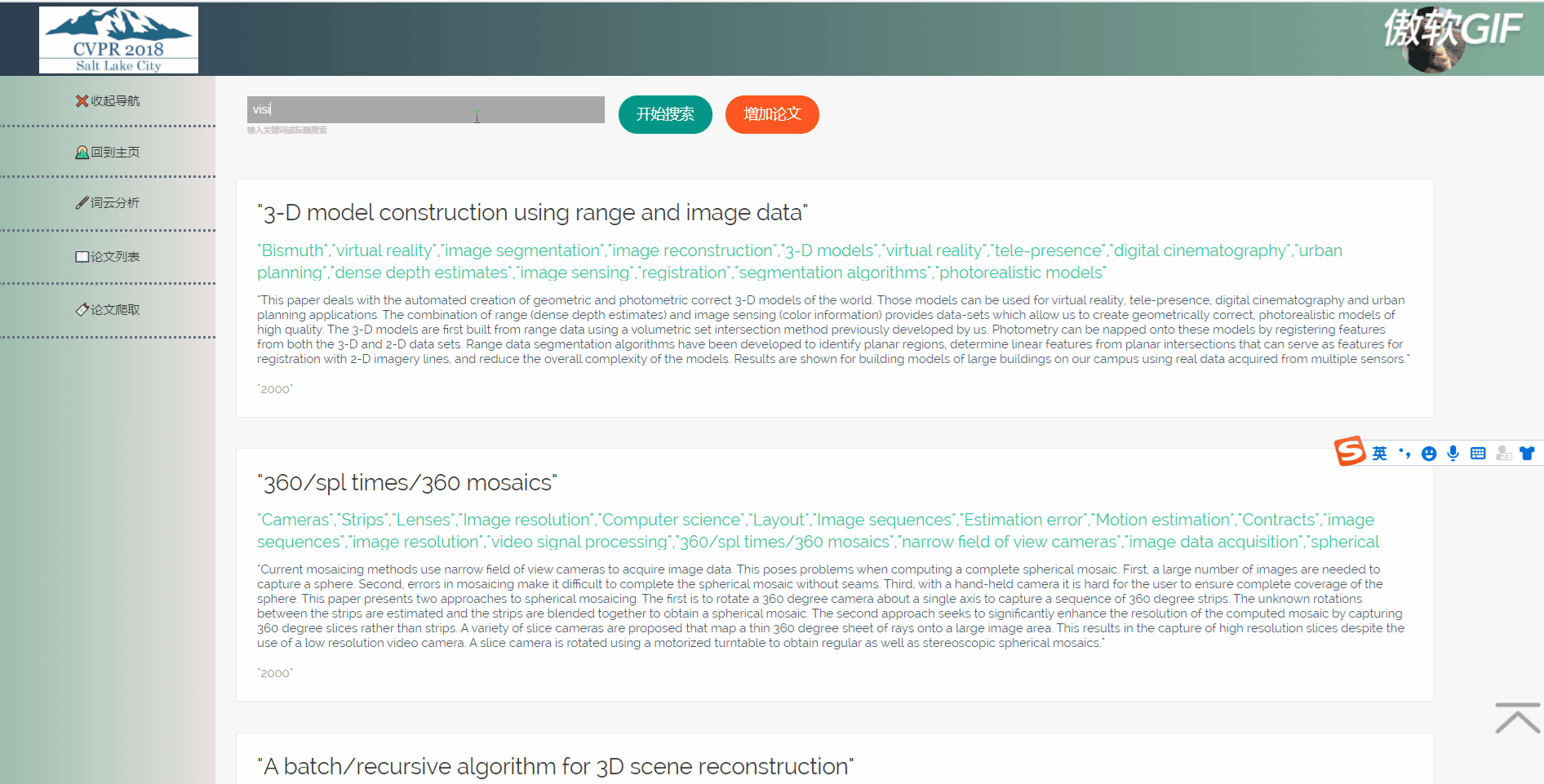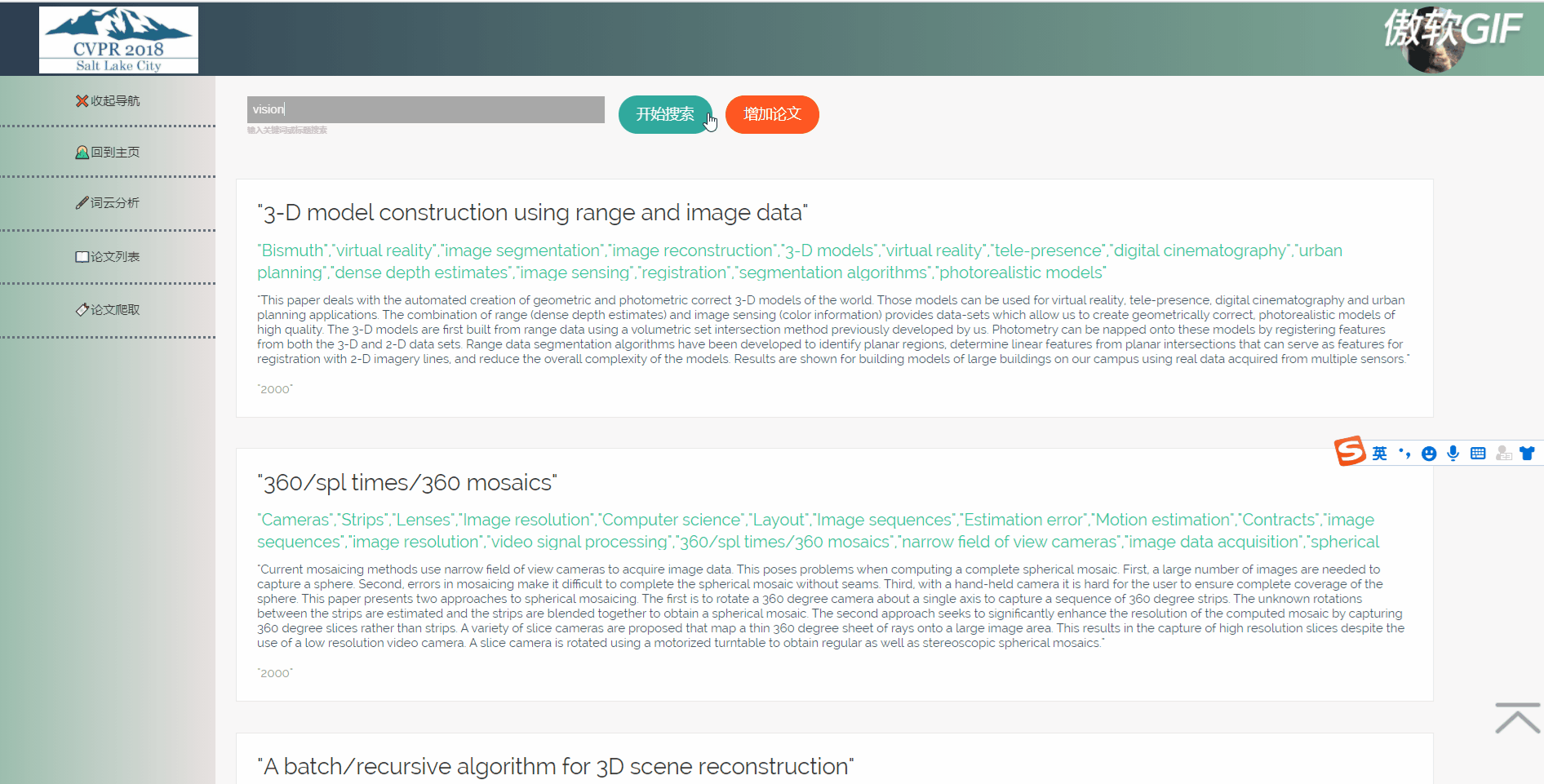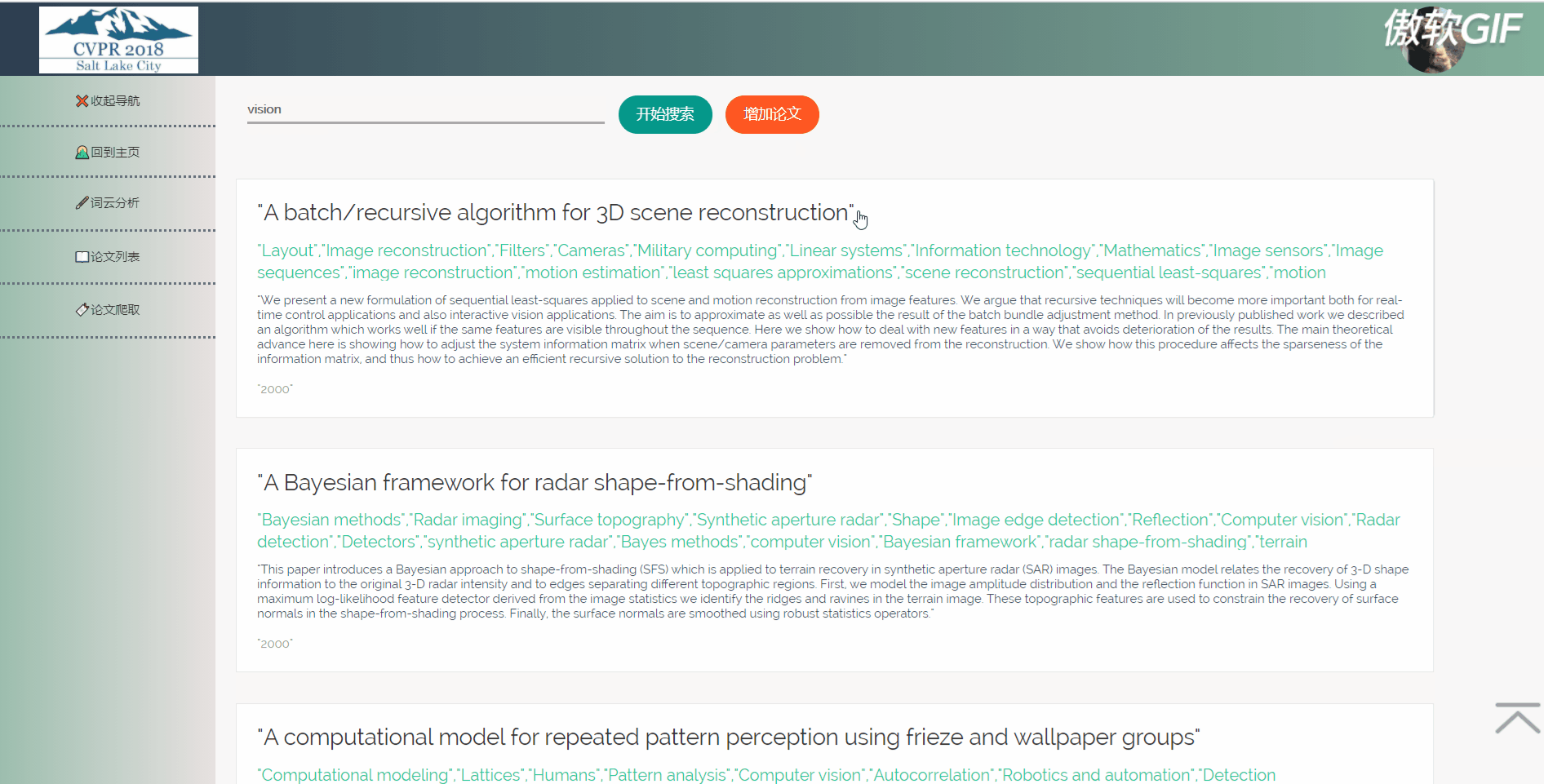
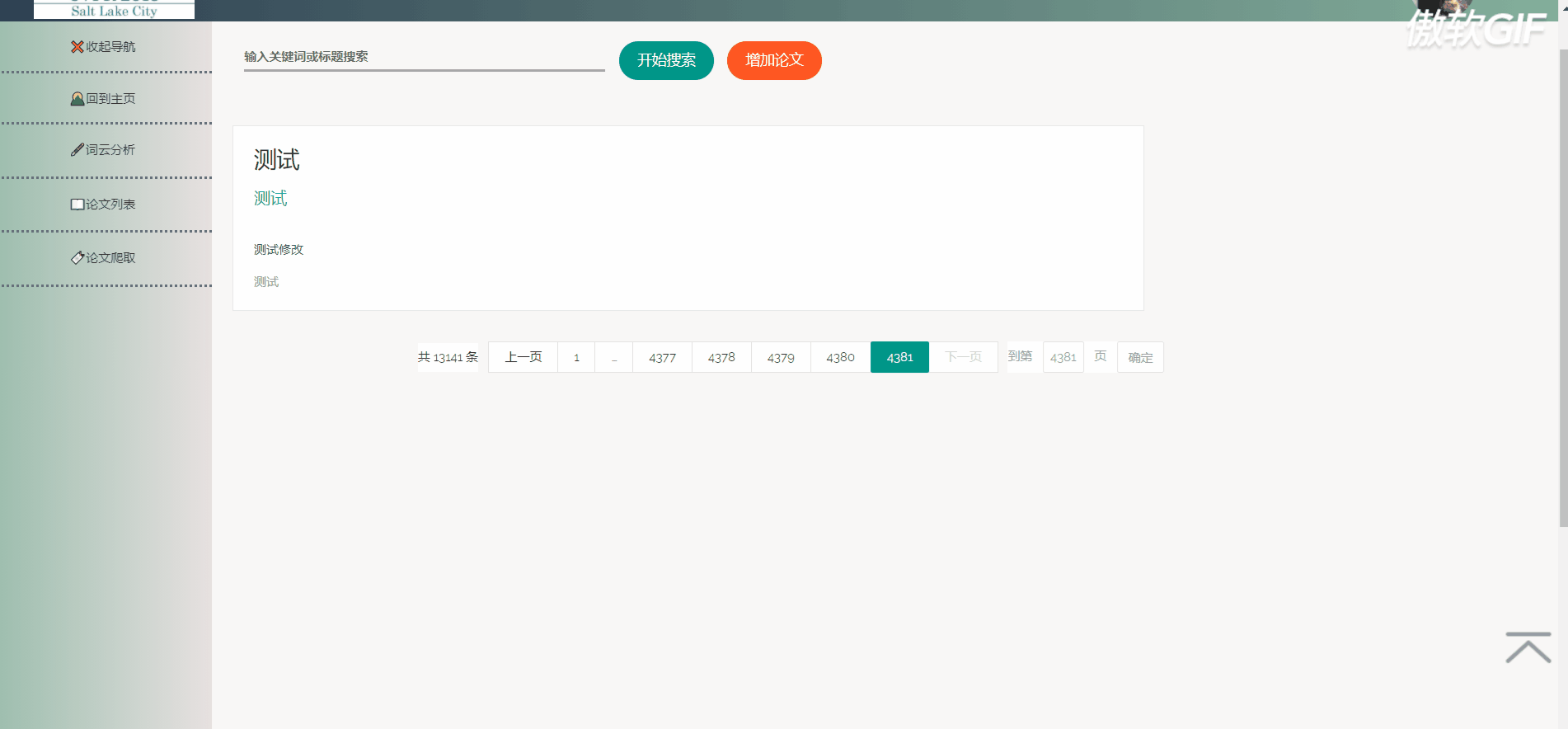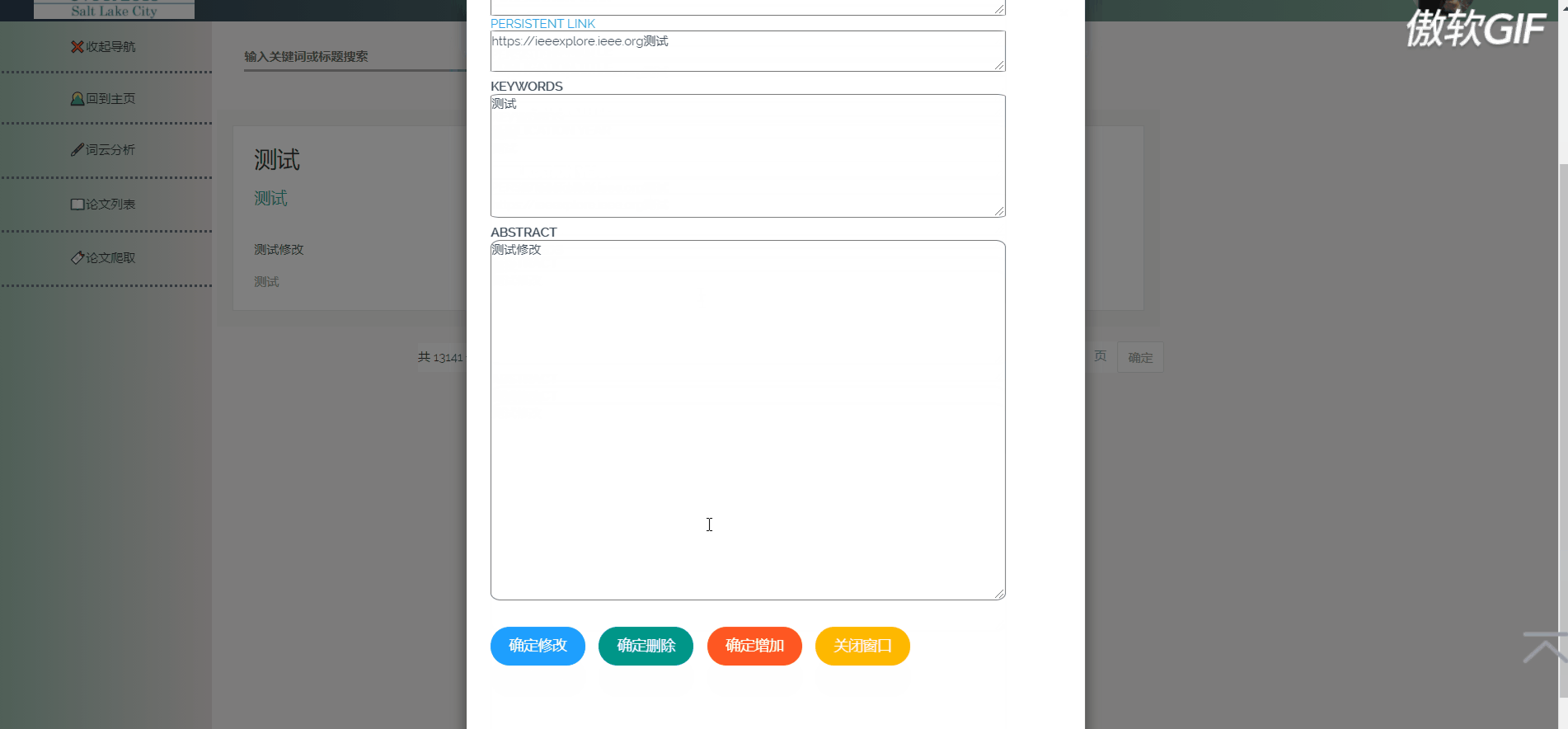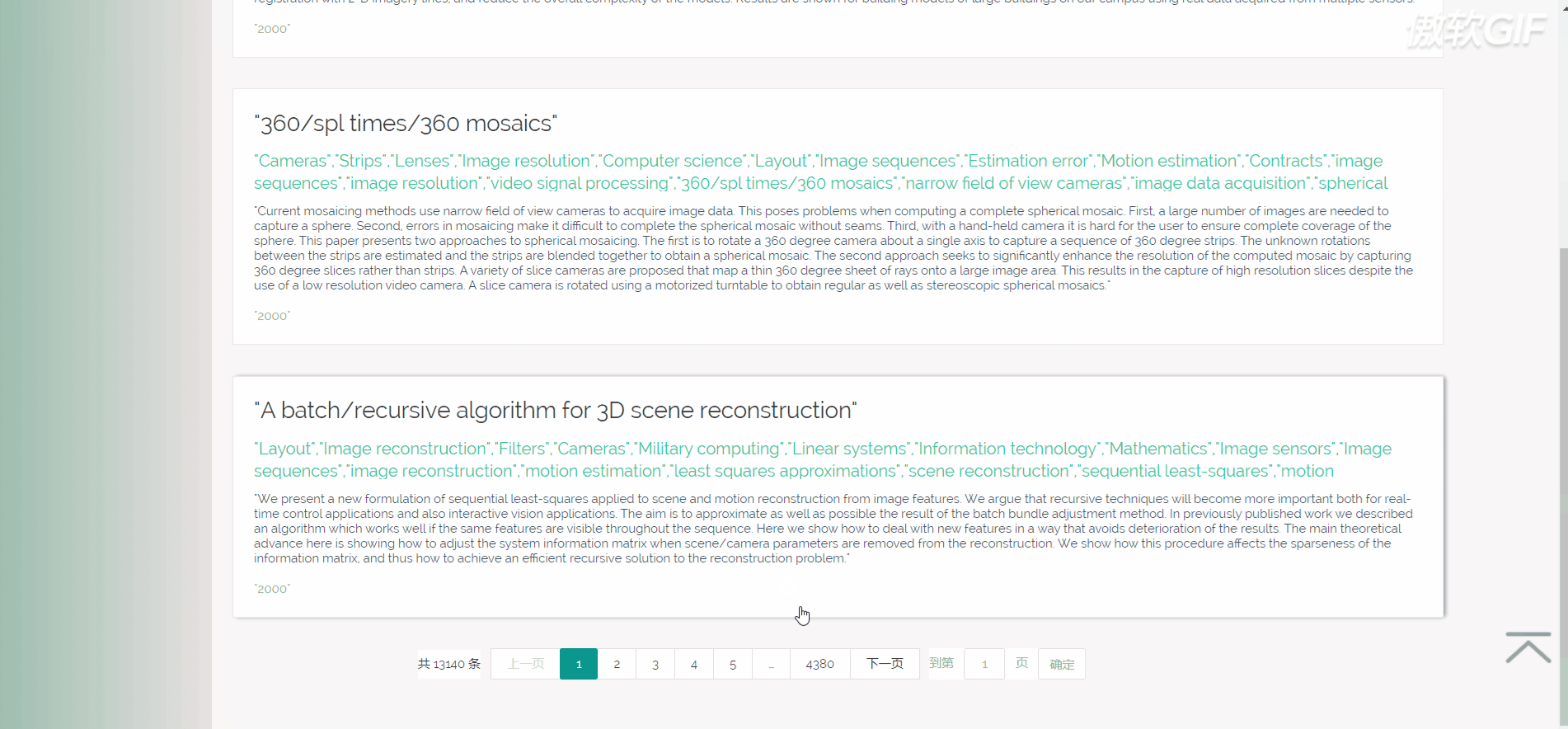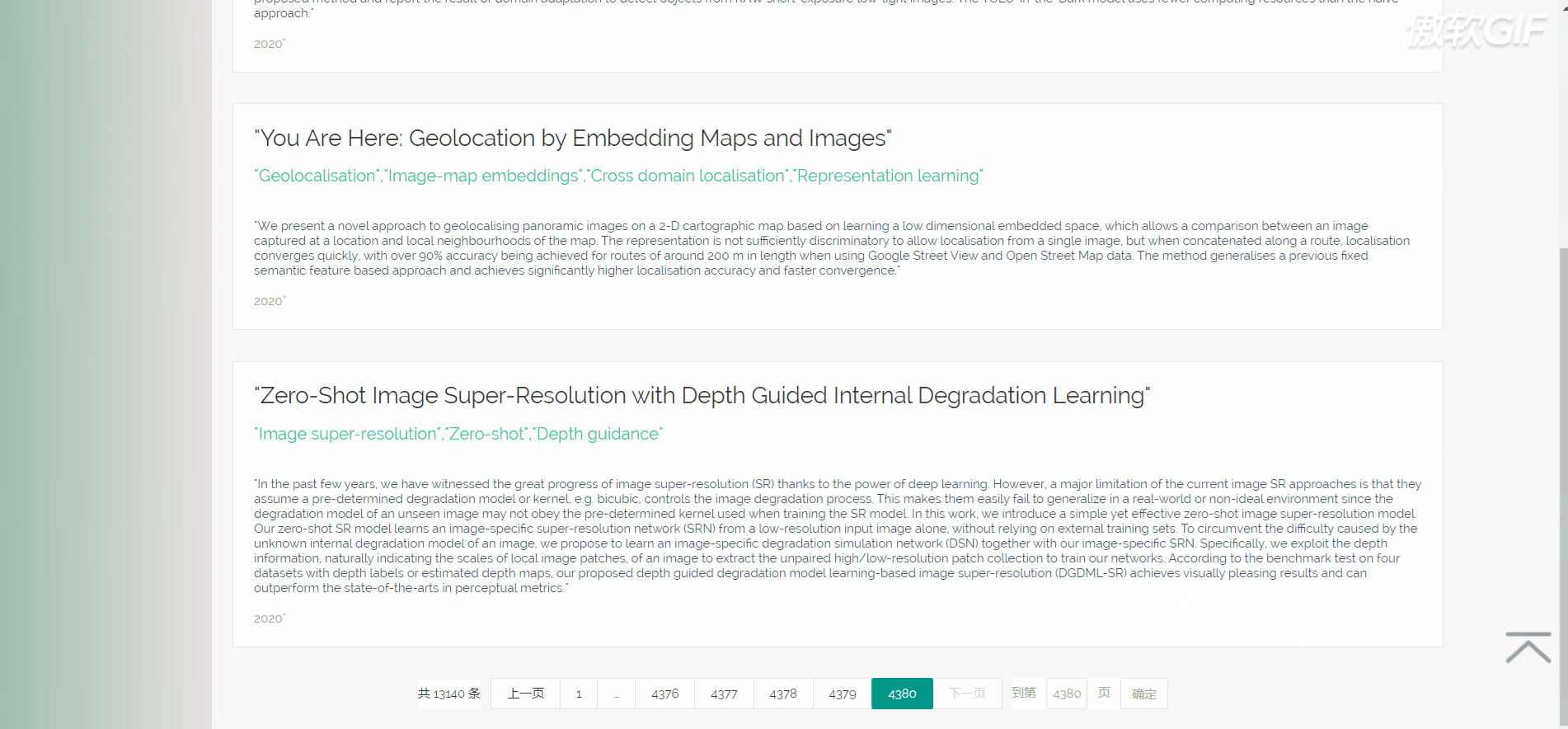
3.6 论文列表搜索
3.7 论文增加
3.8 论文删除和修改
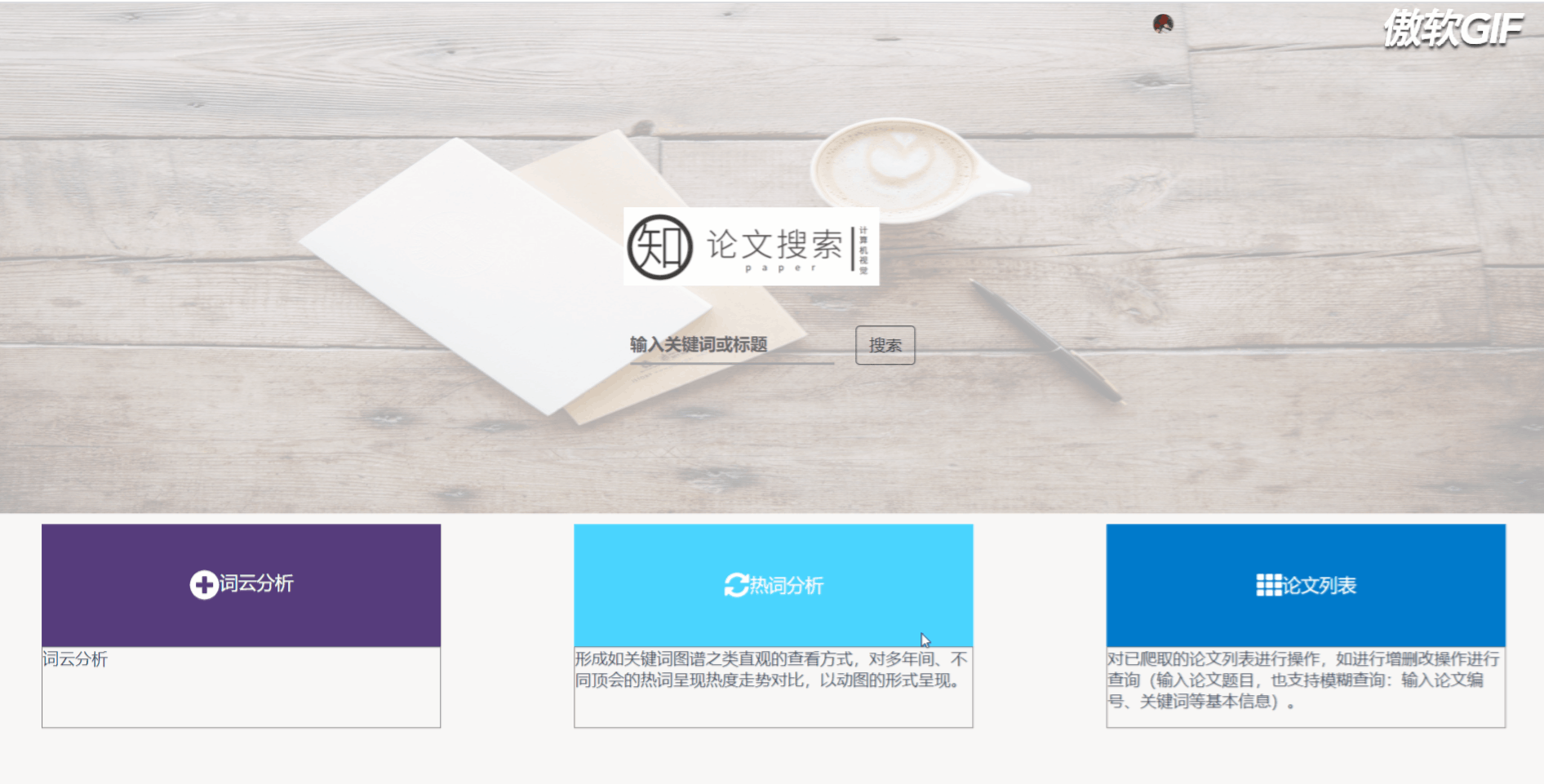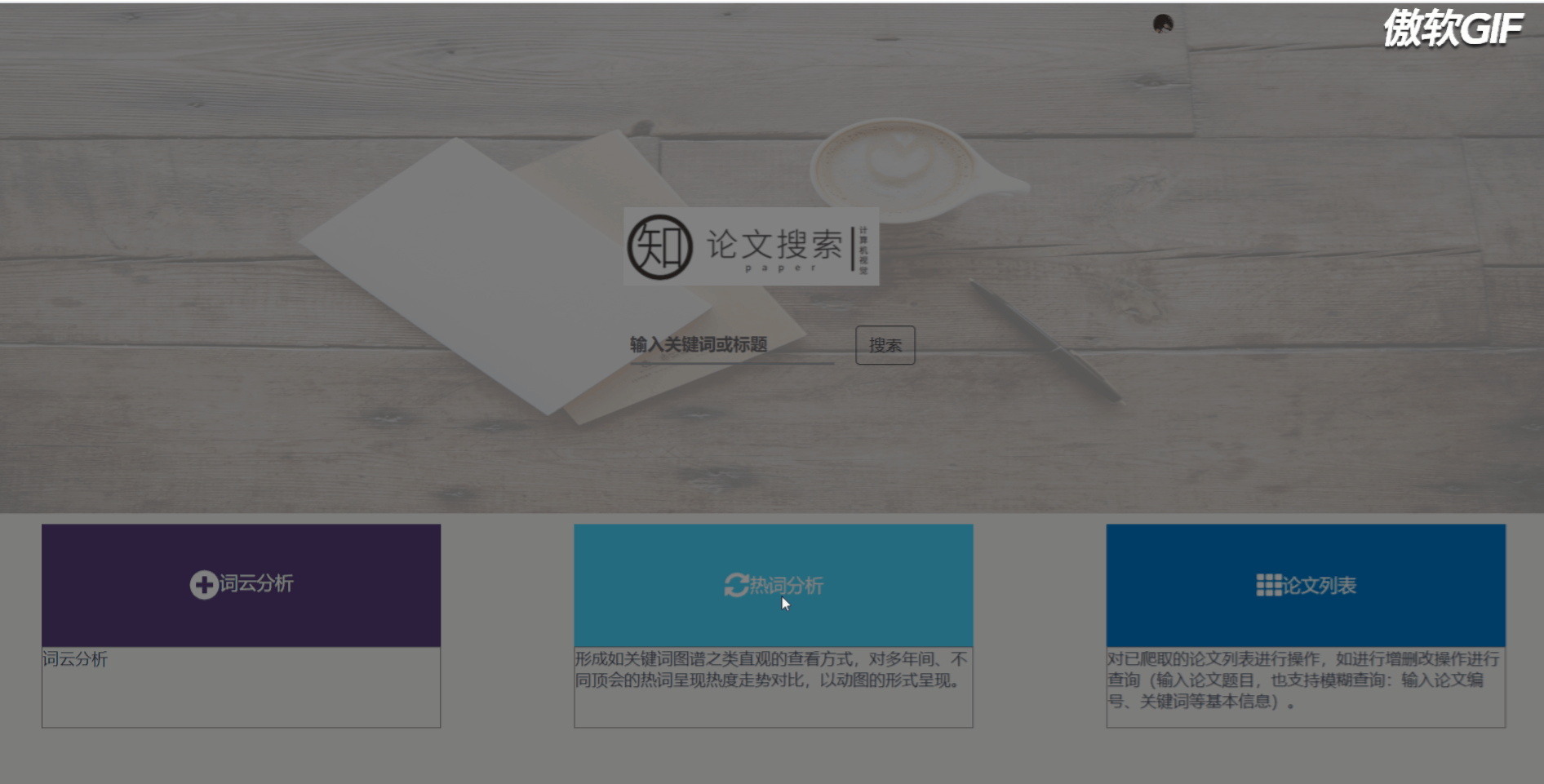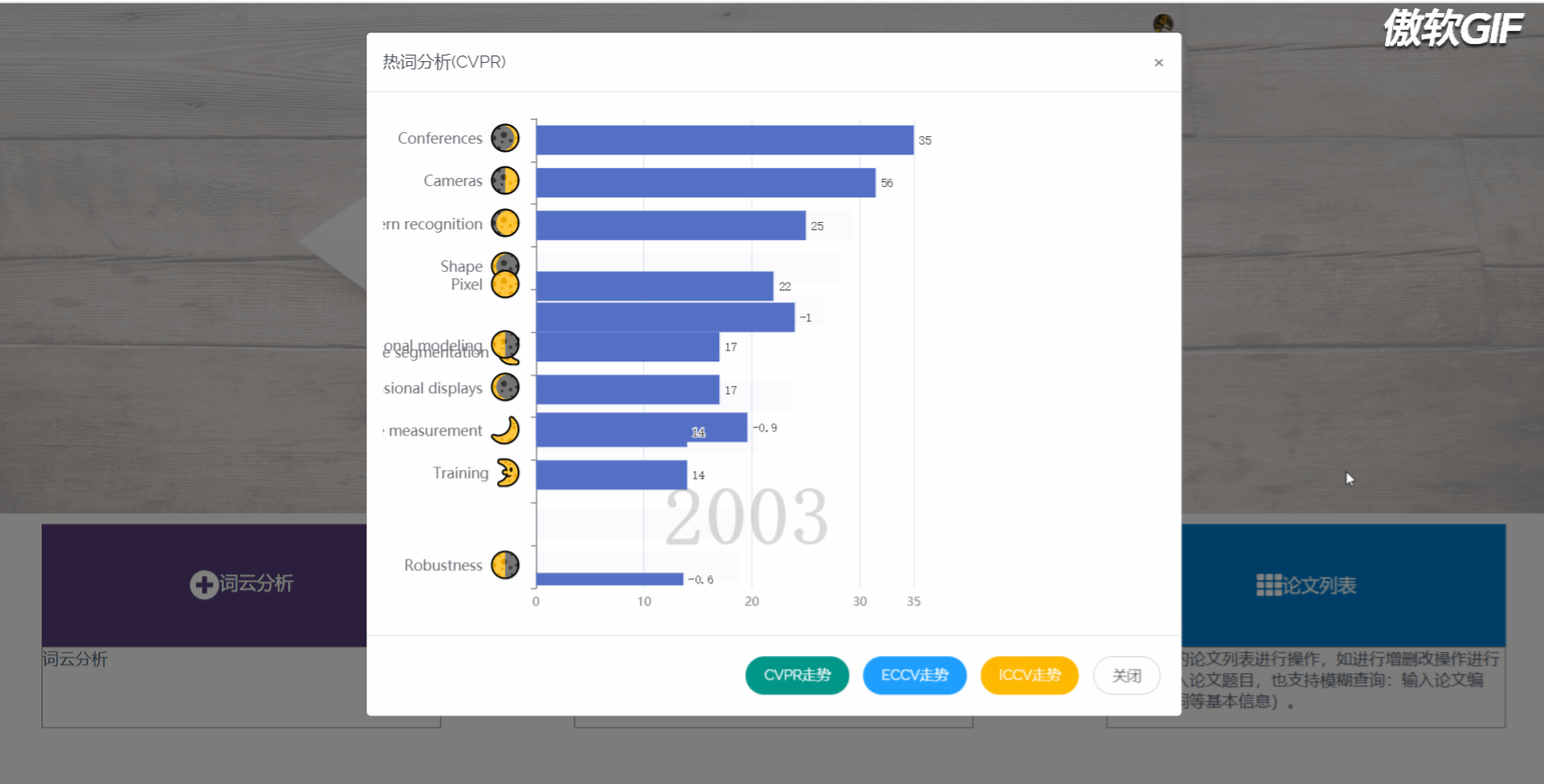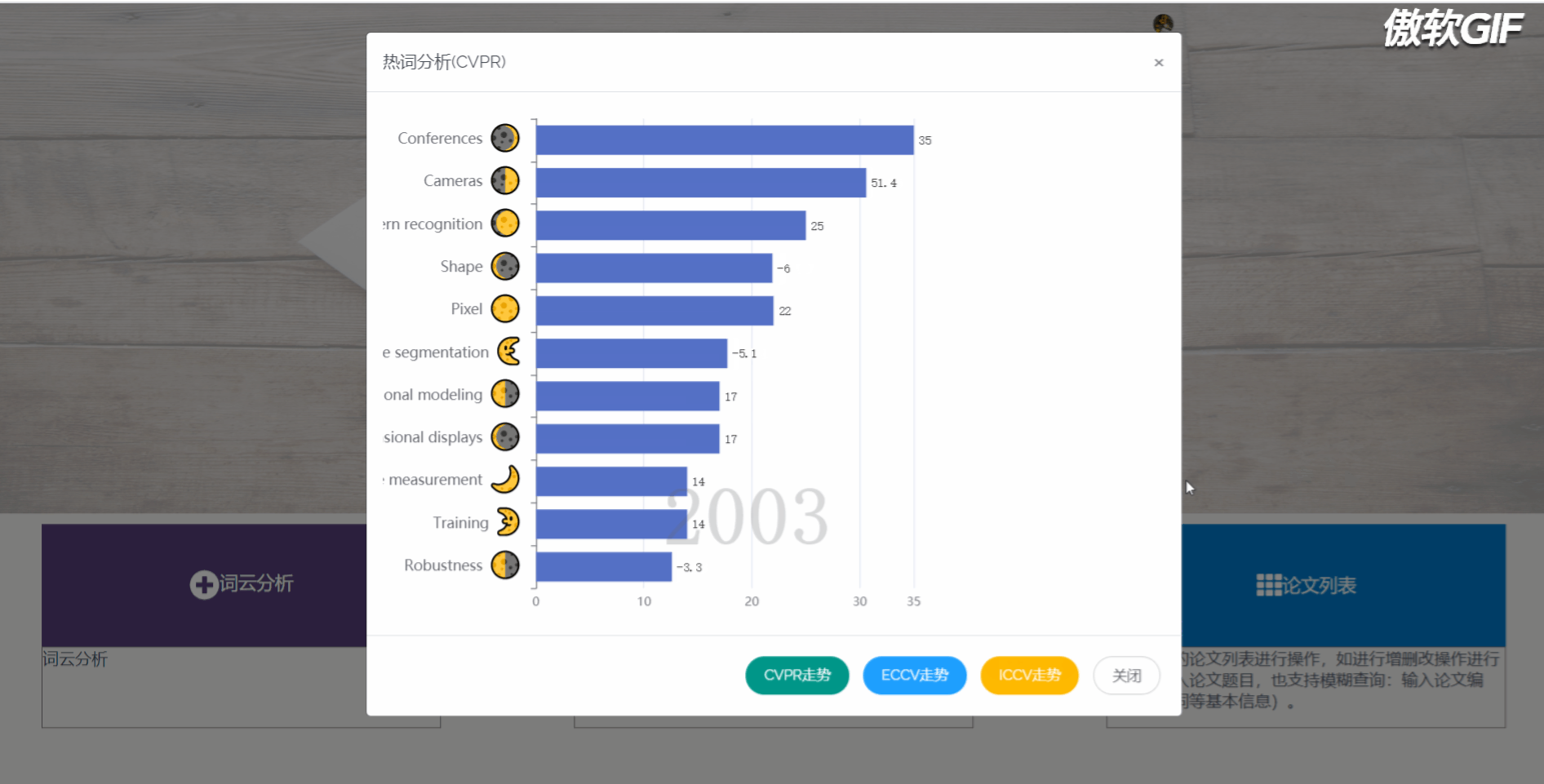
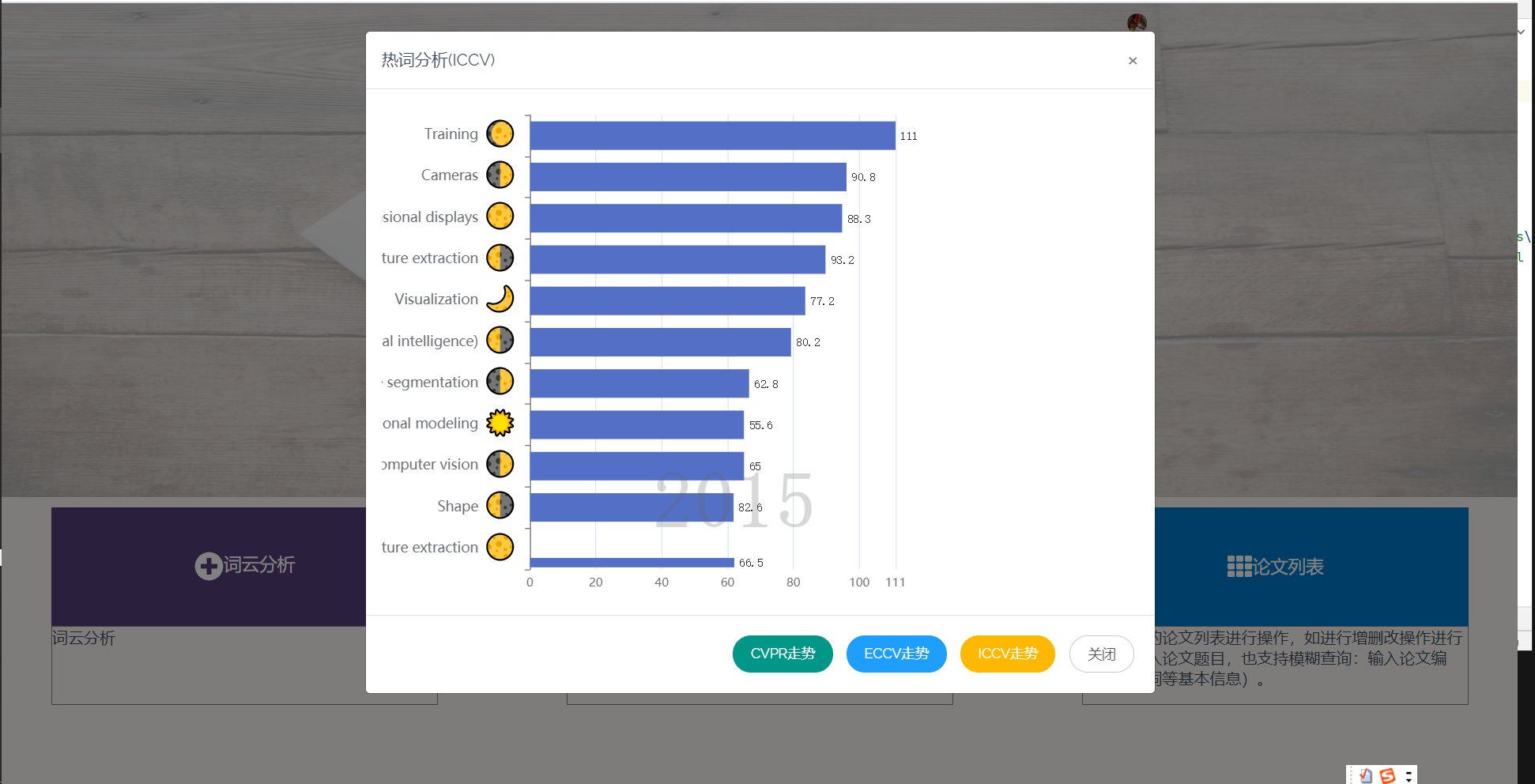
3.9 热词热度分析走势图
3.10 论文爬取
四、结对讨论过程描述
4.1 结对讨论过程
因为我们两个人的技术栈比较相似,本身都学习过一些后端开发的知识,所以在拿到选题的时候,我们就决定各自分别负责展开前端与后端的工作,以功能模块划分我们的开发。结合Springboot框架和前端三套件,我们可以很快搭建出一个网站的模板。总的来说,我们的结对编程进度推进的还算顺利,也没有git提交代码冲突,因为我们是舍友,遇到问题也能马上讨论解决方案。
4.2 结对讨论截图

五、设计实现过程描述
5.1 功能结构图
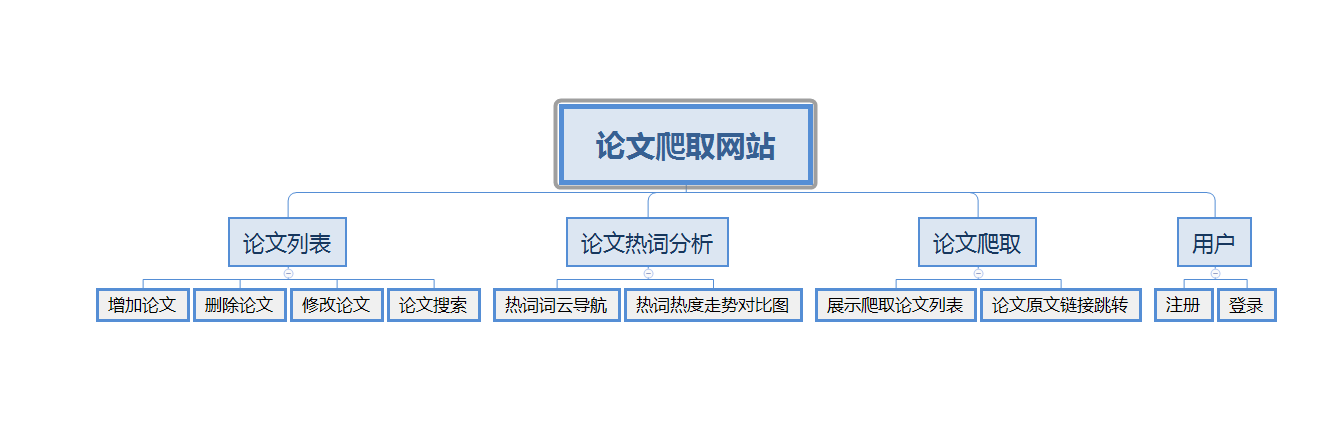
5.2 功能模块介绍
5.2.1 首页导航
首页点击右上角登录可以进入登录/注册界面,用户登录后用SESSSION来保存用户信息。首页搜索框搜索会导向论文列表页面并且展示搜索结果。点击热词分析框会弹出热词热度走势对比图。
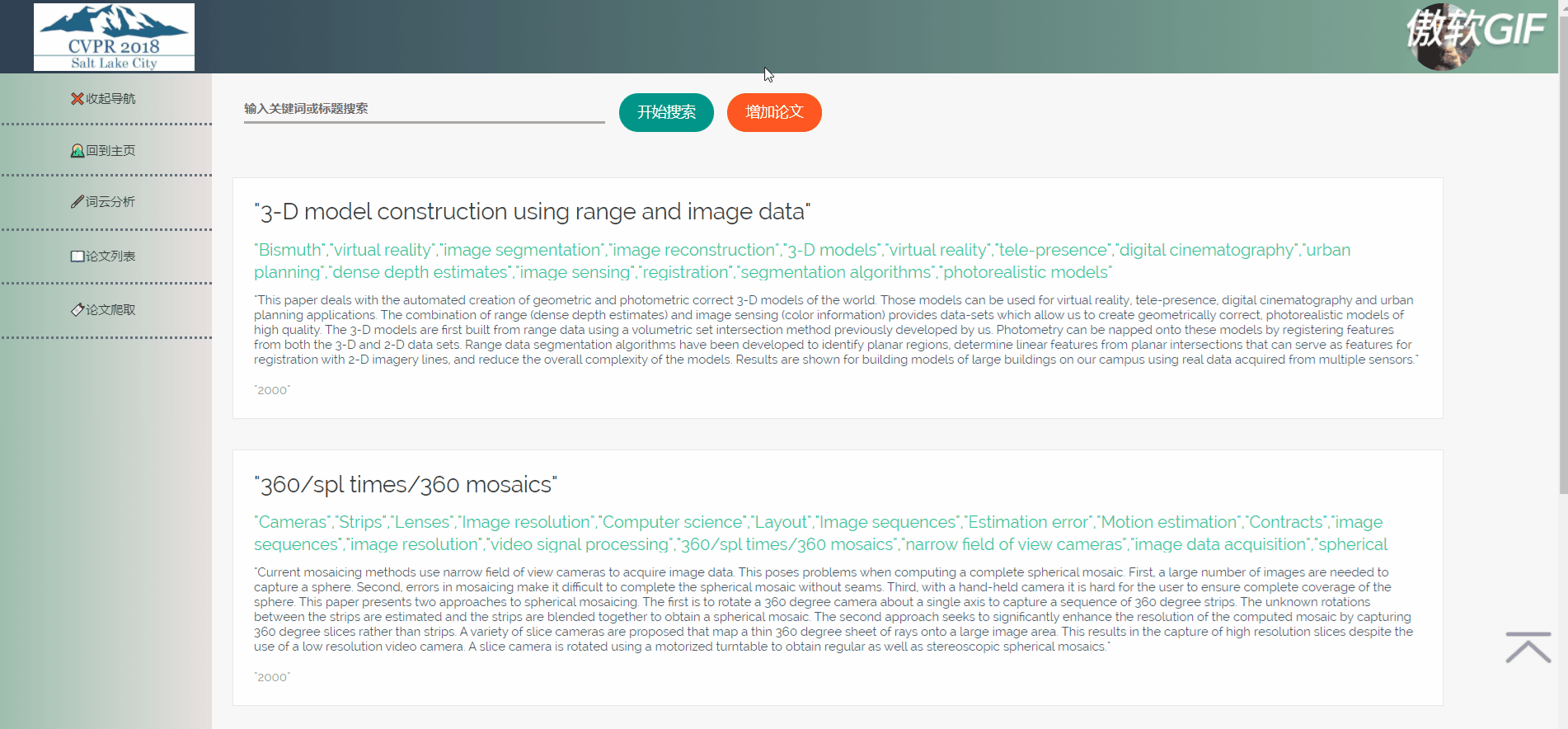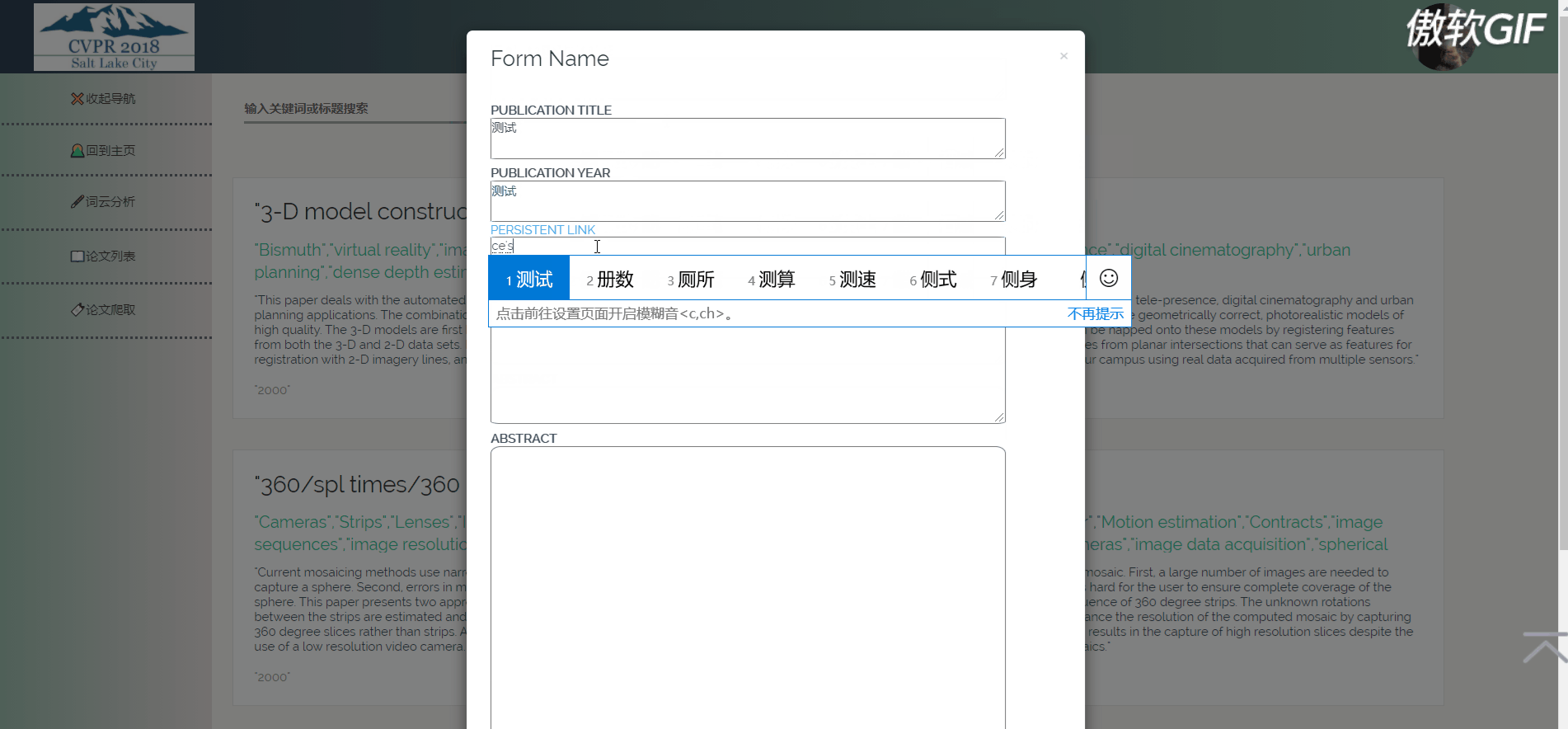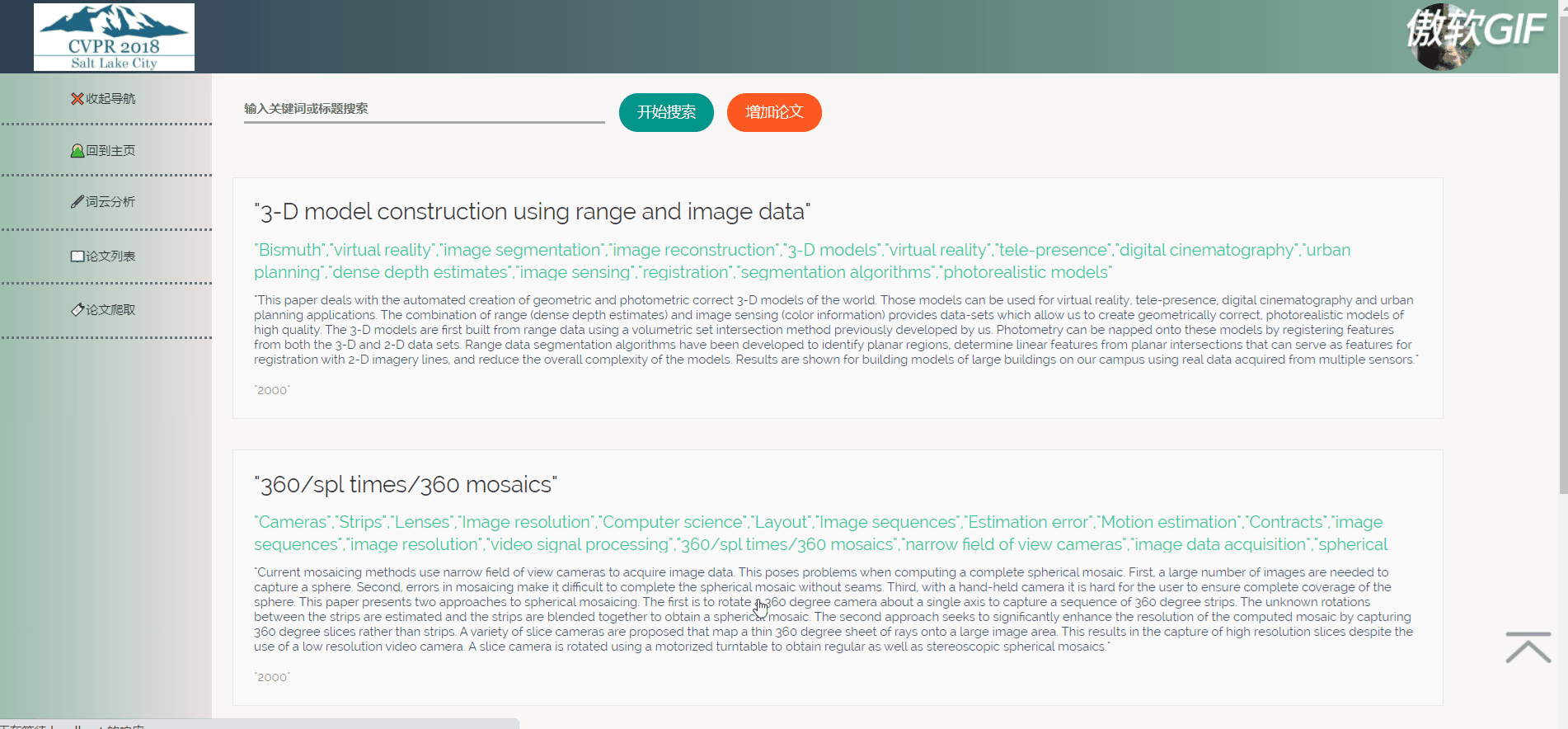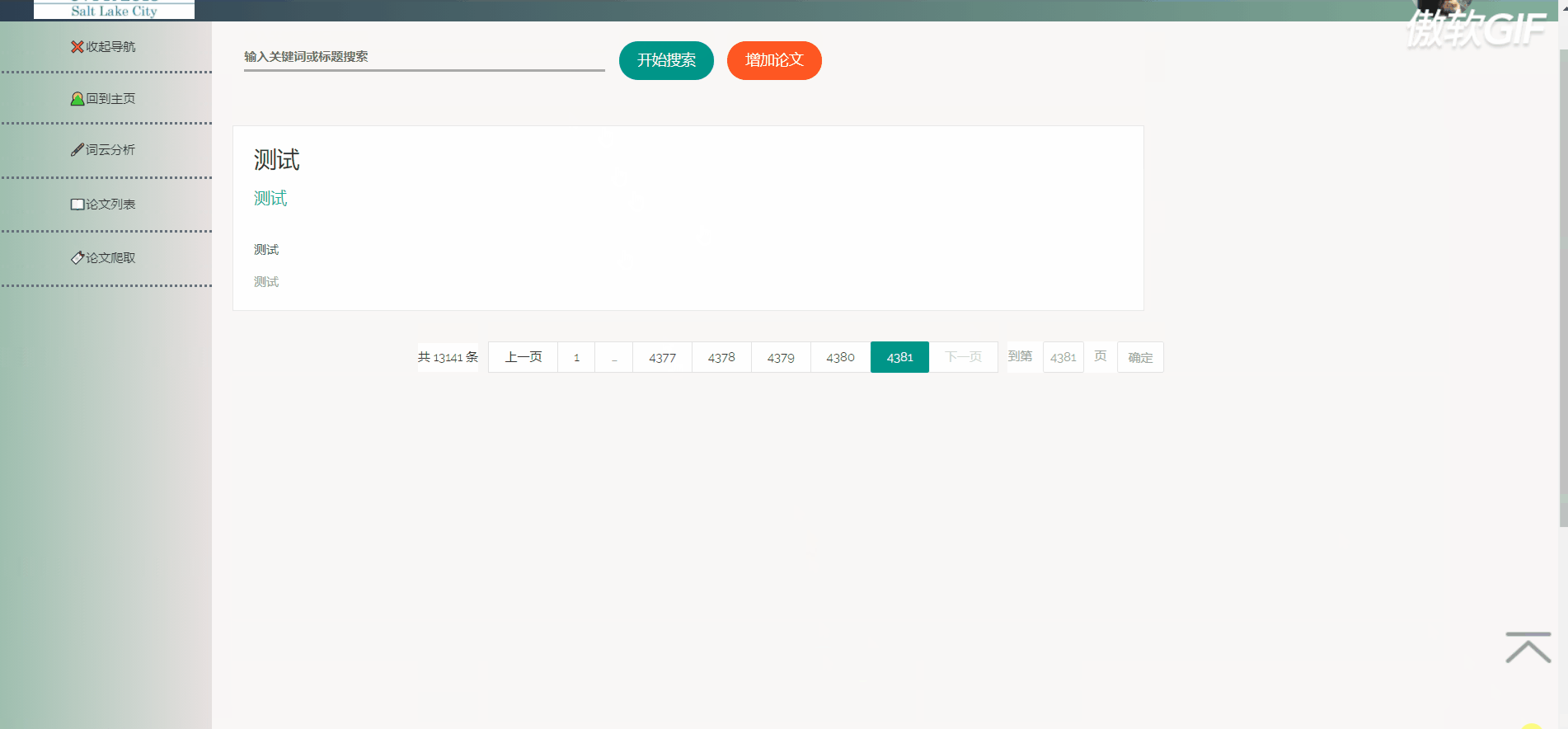
5.2.2 论文列表
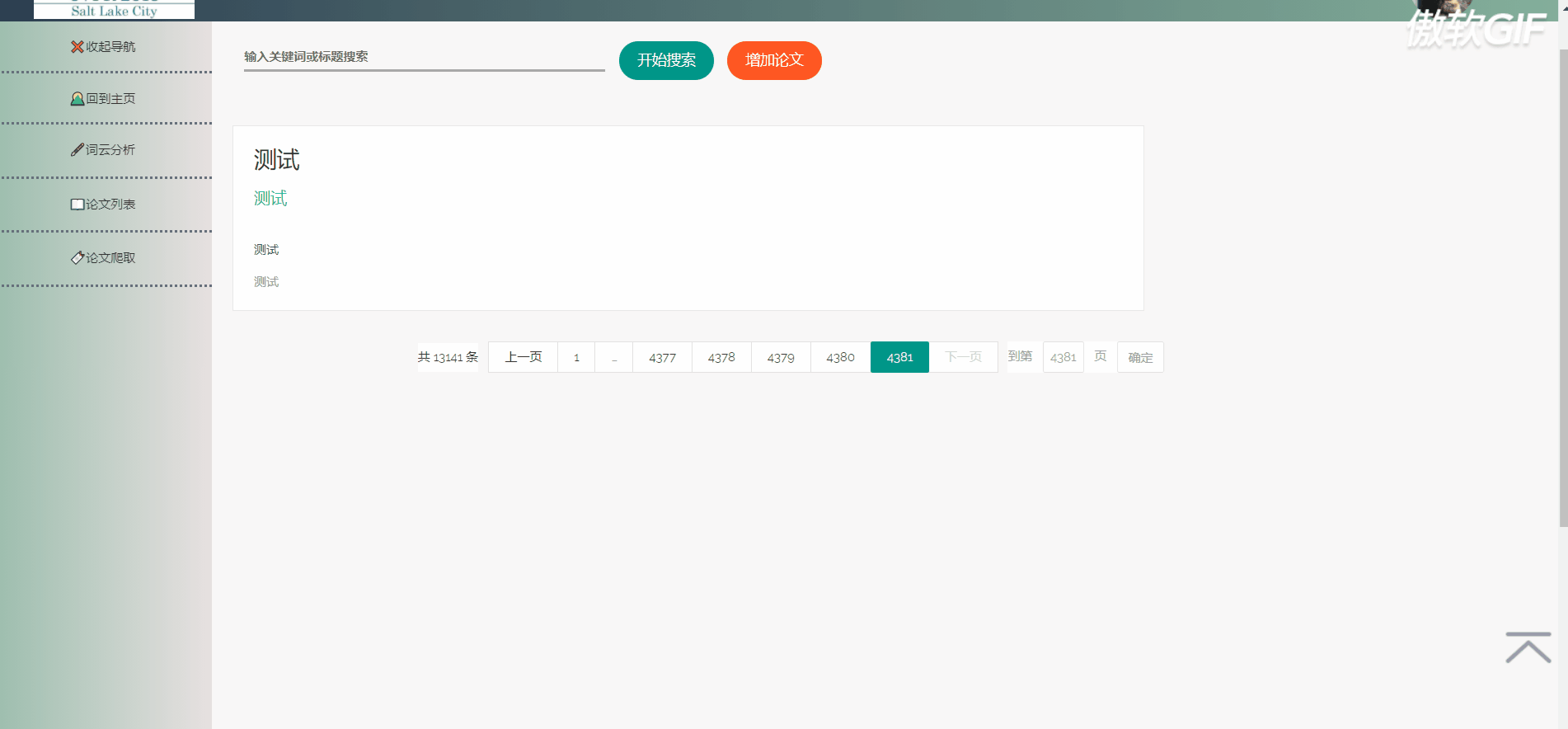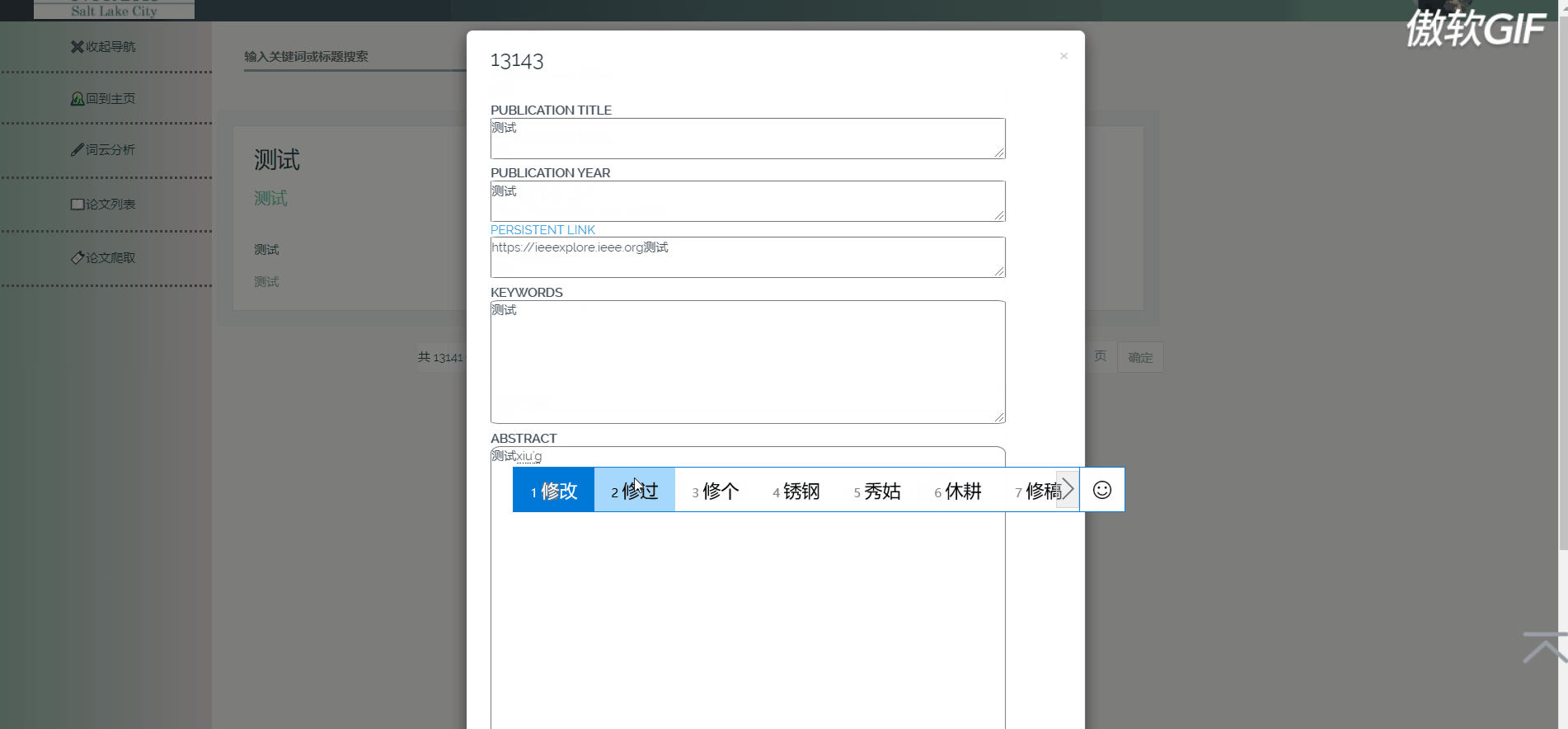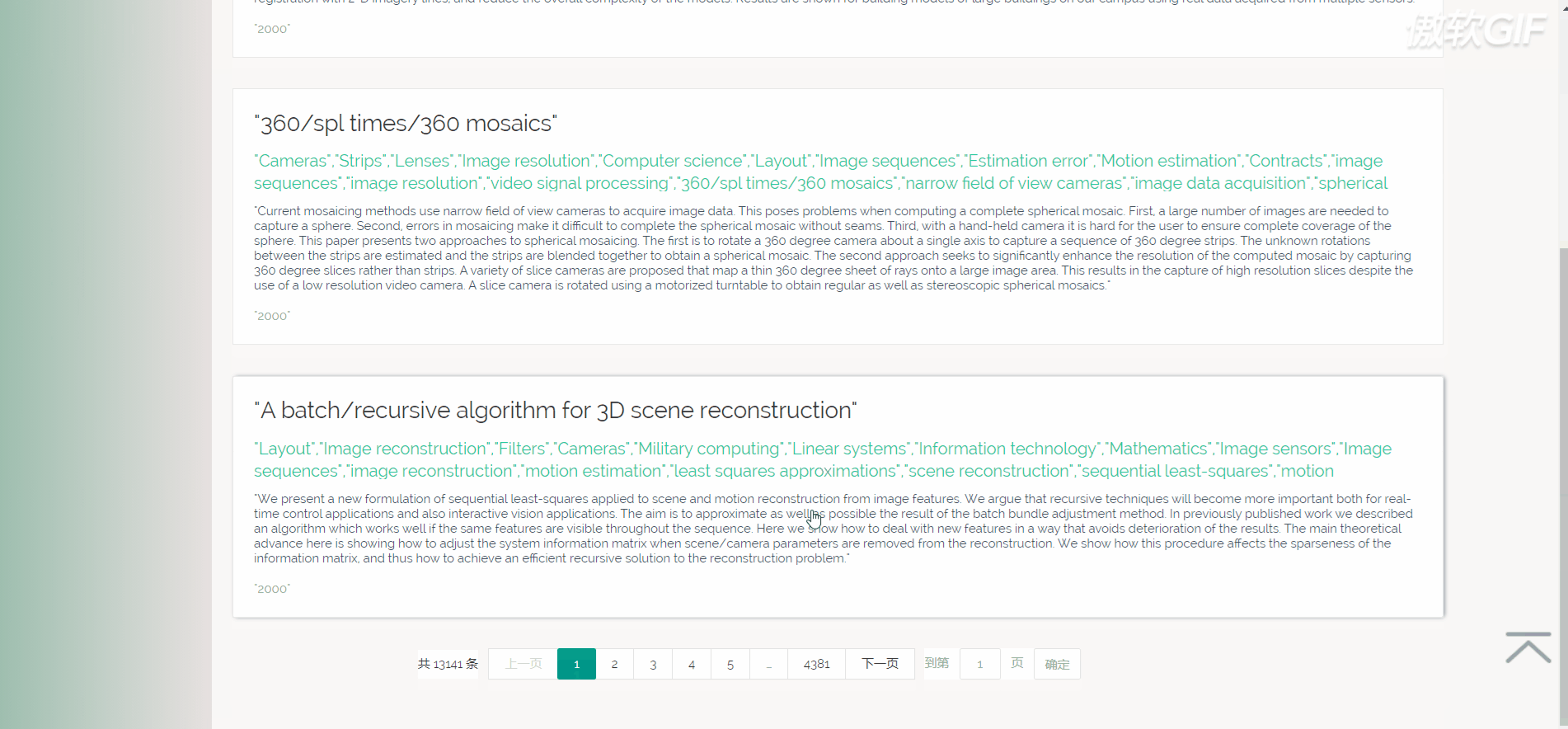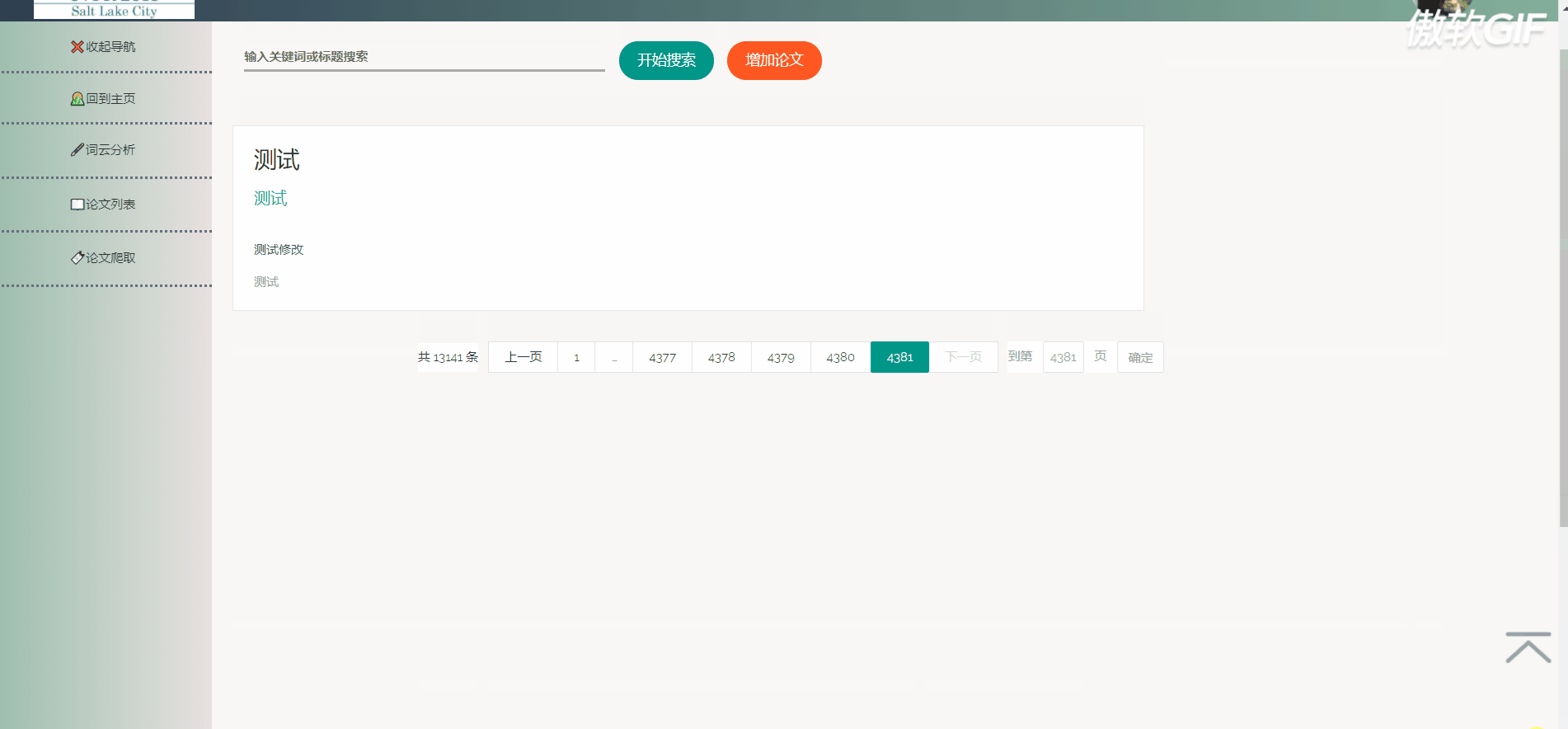
论文列表以一个个卡片表格的形式展示已经爬取到的论文,并且在后端写好了分页,点击分页器页码按钮会再次向后端发起请求,渲染表格展示新的数据。点击论文卡片会以模态框的形式弹出论文详情页,可以在论文详情页对论文进行删除,修改操作。论文表格上方有论文搜索框和论文增加按钮,可以用关键词或论文标题进行模糊搜索。增加论文后新论文在最后一页最后一条。
5.2.3 热词分析
热度对比图,我们先是采用取得数据库所有关键词,按顶会不同和年份不同区分,再将他们排序输出,最后计算与传输所耗费的时间过长,该方案被我们淘汰,最后我们选择将分析所得的数据通过json的形式直接存入数据库,每次使用直接取出即可,如果有新数据加入,会再次计算关键词热度。
热词分析部分首先通过动态柱状图,统计每个顶会不同年间,关键词热度变化,可切换不同顶会,查看其动态变化。
5.2.4 词云分析
在数据库中取得所有关键词列表,将他们排序分析,并将出现频率最高的二十个词展示在词云图中,用户可以通过点击词云图跳转到带有相应关键词的论文列表。
5.2.5 在线爬取
通过用户需要查找的关键词,在线通过ieee搜索出相应的论文,然后修改请求头截取ajax请求的方式获得json文件,再利用程序提取json中的数据并进行分析处理,显示到网站。
六、关键代码和思路
6.1 在线爬取
通过HttpClient(设置请求头,请求参数),获取ieee网站响应数据,并对其处理分析。
public static String getJson(String path,String params)
{
try
{
trustAllHttpsCertificates();
} catch (Exception e)
{
e.printStackTrace();
}
HttpsURLConnection.setDefaultHostnameVerifier(hv);
HttpURLConnection httpURLConnection = null;
String data = "";
try {
httpURLConnection=show(path);
httpURLConnection.connect();
String p = params;
OutputStream out = httpURLConnection.getOutputStream();
out.write(p.getBytes());
out.flush();
//关闭
out.close();
int code = httpURLConnection.getResponseCode();
if (code == 200) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(httpURLConnection.getInputStream()));
String line;
while ((line = reader.readLine()) != null) {
data += line + "\n";
}
//关闭
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 5. 断开连接
if (null != httpURLConnection) {
try {
httpURLConnection.disconnect();
} catch (Exception e) {
e.printStackTrace();
}
}
}
return data;
}
public static HttpURLConnection show(String path) throws IOException
{
HttpURLConnection httpURLConnection = null;
URL url = new URL(path);
httpURLConnection = (HttpURLConnection) url.openConnection();
httpURLConnection.setRequestMethod("POST");
httpURLConnection.setConnectTimeout(6000);
httpURLConnection.setDoOutput(true);
httpURLConnection.setDoInput(true);
httpURLConnection.setUseCaches(false);
httpURLConnection.setInstanceFollowRedirects(true);
httpURLConnection.setRequestProperty("Content-Type", "application/json");
httpURLConnection.setRequestProperty("Accept", "application/json,text/plain,*/*");
httpURLConnection.setRequestProperty("Accept-Language", "zh-TW,zh;q=0.9,en-US;q=0.8,en;q=0.7");
httpURLConnection.setRequestProperty("Connection", "keep-alive");
httpURLConnection.setRequestProperty("Content-Length", "122");
httpURLConnection.setRequestProperty("Accept-Encoding", "gzip,deflate,br");
return httpURLConnection;
}
6.2 数据分析(热词分析)
通过将关键词和年份拼接作为map的key ,数量作为value,对不同年份关键词的数量进行统计,并按数量和年份进行排序得到最终数据并将数据存入数据库,减少计算量。
public List<Map.Entry<String, Integer>> alalysePaperToGetTopKeyWords(Paper paper) {
List<Paper> paperList = userMapper.selPaperByConference(paper);
Map<String, Integer> keyMap = new HashMap<>();
for (int i = 0; paperList != null && i < paperList.size(); i++) {
System.out.println("获取paper" + paperList.get(i).getPublicationYear() + "条数:" + i);
if (paperList.get(i).getKeywords() == null) {
continue;
}
String[] arr = paperList.get(i).getKeywords().replaceAll("\"", "").split(",");
if (paperList.get(i).getPublicationYear() == null)
paperList.get(i).setPublicationYear("0");
for (int j = 0; j < arr.length; j++)
arr[j] = arr[j] + "&&&&&" + paperList.get(i).getPublicationYear().replaceAll("\"", "");
for (int j = 0; arr != null && j < arr.length; j++) {
if (keyMap.get(arr[j]) == null) {
keyMap.put(arr[j], 1);
} else
keyMap.put(arr[j], keyMap.get(arr[j]) + 1);
}
}
List<Map.Entry<String, Integer>> list = sortMapByValue(keyMap);
List<Map.Entry<String, Integer>> answer = new ArrayList<>();
Map<String, Integer> tmp_count = new HashMap<>();
for (int i = 0, j = 0, k; i < list.size(); i++) {
String[] years = list.get(i).getKey().split("&&&&&");
if (years != null && tmp_count.get(years[1]) == null)
tmp_count.put(years[1], 0);
else if (years != null && tmp_count.get(years[1]) < TOP_TEN * 2) {
tmp_count.put(years[1], tmp_count.get(years[1]) + 1);
answer.add(list.get(i));
}
}
return answer;
}
private List<Map.Entry<String, Integer>> sortMapByValue(Map<String, Integer> map) {
//将hashMap转化为list
List<Map.Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
//进行排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o2.getValue() == null || o1.getValue() == null)
return 0;
String[] str1 = o1.getKey().split("&&&&&");
String[] str2 = o2.getKey().split("&&&&&");
if (!str1[1].equals(str2[1]))
return str1[1].compareTo(str2[1]);
return o2.getValue().compareTo(o1.getValue());
}
});
return list;
}
6.3 对已有的json文件(论文数据)分析处理存入数据库:
通过本次作业助教提供的数据初始化数据库,通过文件递归获取字符流。
public List<Paper> getPaper() {
FileReader reader = null;
List<String> list = new ArrayList<>();
StringBuilder sb;
for (int i = 0; i < 3; i++) {
List<File> fileList = FileUtil.getFiles(path[i]);
for (File f : fileList) {
String tmp = null;
sb = new StringBuilder(INI_SIZE);
//读取json文件
try {
reader = new FileReader(path[i] + "\\" + f.getName());
BufferedReader bufferedReader = new BufferedReader(reader);
while ((tmp = bufferedReader.readLine()) != null) {
sb.append(tmp);
}
list.add(sb.toString());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
Paper paper = onepaperJsonToPaper(sb.toString(), conference[i]);
//保存至数据库
if (paper != null)
userMapper.insPaper(paper);
}
}
对获取的流进行分析,得到相应对象 ,调用数据库语句存入数据库。
private Paper onepaperJsonToPaper(String str, String conference) {
ObjectMapper objectMapper = new ObjectMapper();
JsonNode node = null;
try {
node = objectMapper.readTree(str);
} catch (IOException e) {
e.printStackTrace();
}
logger.debug(String.valueOf(node.get("abstract")));
Paper paper = new Paper();
paper.setConference(conference);
paper.setAbstrac(String.valueOf(node.get("abstract")));
paper.setPersistentLink(String.valueOf(node.get("htmlLink")));
paper.setPublicationTitle(String.valueOf(node.get("title")));
paper.setPublicationYear(String.valueOf(node.get("publicationYear")));
List<PaperAuthors> authorslist = paper.getAuthorsList();
List<Keywords> keywordsList = paper.getKeywordsList();
//关键词对象。
for (int j = 0; node.get("keywords") != null && j < node.get("keywords").size(); j++) {
//System.out.println("获得的关键词:" + String.valueOf(node.get("keywords").get(j)));
Keywords keywords = new Keywords();
keywords.setType(String.valueOf(node.get("keywords").get(j).get("type")));
List<String> stringList = new ArrayList<>();
for (int k = 0; k < node.get("keywords").get(j).get("kwd").size(); k++) {
stringList.add(String.valueOf(node.get("keywords").get(j).get("kwd").get(k)));
//利用,分割,以string形式保存
if (paper.getKeywords() == null)
paper.setKeywords(String.valueOf(node.get("keywords").get(j).get("kwd").get(k)));
else
paper.setKeywords(paper.getKeywords() + "," + node.get("keywords").get(j).get("kwd").get(k).toString());
}
keywords.setKedList(stringList);
keywordsList.add(keywords);
}
paper.setKeywordsList(keywordsList);
//authorslist.add(new PaperAuthors(node.get("keywords")))
return paper;
}
6.4 论文列表增删改查
利用mybatis框架对数据库论文进行增删查改
@Mapper
public interface LimitPaperMapper {
@Select("SELECT * FROM paper limit #{startPosition} ,#{pageSize}")
public List<Paper> getLimitPaper(@Param("startPosition") int startPosition, @Param("pageSize") int pageSize);
@Select("SELECT COUNT(*) FROM paper")
public Integer getCount();
@Select("SELECT * FROM paper WHERE persistentLink != 'null' and (keywords like concat('%', #{value}, '%')" +
"or publicationTitle like concat('%', #{value}, '%')) limit #{startPosition} ,#{pageSize}")
public List<Paper> searchByKeyWords(@Param("value") String keyword,@Param("startPosition") int startPosition, @Param("pageSize") int pageSize);
@Select("SELECT COUNT(*) FROM paper WHERE persistentLink != 'null' and (keywords like concat('%', #{value}, '%') " +
"or publicationTitle like concat('%', #{value}, '%'))")
public Integer getCuntS(@Param("value") String keyword);
@Delete("DELETE FROM paper WHERE paperId = #{id}")
public Integer deletePaper(@Param("id") int paperId);
@Update("UPDATE paper SET keywords = #{keywords},abstrac = #{abstrac},publicationTitle = #{publicationTitle}," +
"publicationYear = #{publicationYear}, persistentLink = #{persistentLink} where paperId = #{paperId}")
public Integer updatePaper(@Param("paperId") int paperId,@Param("keywords") String keywords,
@Param("abstrac") String abstrac,@Param("publicationTitle") String publicationTitle,
@Param("publicationYear") String publicationYear,@Param("persistentLink") String persistentLink);
@Insert("INSERT INTO paper (keywords,publicationTitle,abstrac,publicationYear,persistentLink) " +
"values (#{keywords},#{publicationTitle},#{abstrac},#{publicationYear},#{persistentLink})")
public Integer insertPaper(@Param("keywords") String keywords,@Param("abstrac") String abstrac,
@Param("publicationTitle") String publicationTitle,
@Param("publicationYear") String publicationYear,
@Param("persistentLink") String persistentLink);
}
6.5 后端论文数据接口
前端采用layui表格ajax发出请求,后端接收请求后返回数据
@Controller
public class LimitPaperController {
@Autowired
LimitPaperImpl limitPaperService;
@RequestMapping("/getLimitPaper")
@ResponseBody
public PaperResponsBody getLimitPaper(@RequestParam(defaultValue = "1") String start, @RequestParam(defaultValue = "8") String limit)
{
List<Paper> paperList = limitPaperService.getLimitPaper(Integer.parseInt(start),Integer.parseInt(limit));
for(Paper paper:paperList) {
if(paper.getPersistentLink().contains("https:")){
}else {
paper.setPersistentLink("https://ieeexplore.ieee.org"+paper.getPersistentLink());
}
}
PaperResponsBody paperResponsBody=new PaperResponsBody();
paperResponsBody.setCode("0");
paperResponsBody.setMsg("成功");
Integer count = limitPaperService.getCount();
paperResponsBody.setCount(count);
paperResponsBody.setData(paperList);
return paperResponsBody;
}
@RequestMapping("/searchByKeyWord")
@ResponseBody
public PaperResponsBody getLimitPaper(@RequestParam(defaultValue = "") String keywords,@RequestParam(defaultValue = "1") String start, @RequestParam(defaultValue = "8") String limit)
{
List<Paper> paperList = limitPaperService.searchByKeyWords(keywords,Integer.parseInt(start),Integer.parseInt(limit));
for(Paper paper:paperList) {
if(paper.getPersistentLink().contains("https:")){
}else {
paper.setPersistentLink("https://ieeexplore.ieee.org"+paper.getPersistentLink());
}
}
PaperResponsBody paperResponsBody=new PaperResponsBody();
paperResponsBody.setCode("0");
paperResponsBody.setMsg("成功");
Integer count = limitPaperService.getCountS(keywords);
paperResponsBody.setCount(count);
paperResponsBody.setData(paperList);
return paperResponsBody;
}
@PostMapping("/delete")
public String postDelete(HttpServletRequest request) {
String paperId = request.getParameter("paperId");
Integer result = limitPaperService.deletePaper(Integer.parseInt(paperId));
if(result == 1){
System.out.println("删除成功");
}else{
System.out.println("删除失败");
}
return "paperlist";
}
@PostMapping("/update")
public String postUpdate(HttpServletRequest request) {
String paperId = request.getParameter("paperId");
String title = request.getParameter("textarea-title");
String year = request.getParameter("textarea-year");
String link = request.getParameter("textarea-link");
String abstrac = request.getParameter("textarea-abstract");
String key = request.getParameter("textarea-key");
Integer result = limitPaperService.updatePaper(Integer.parseInt(paperId),title,key,abstrac,link,year);
if(result == 1){
System.out.println("更新成功");
}else{
System.out.println("更新失败");
}
return "paperlist";
}
@PostMapping("/insert")
public String postInsert(HttpServletRequest request) {
String title = request.getParameter("textarea-title");
String year = request.getParameter("textarea-year");
String link = request.getParameter("textarea-link");
String abstrac = request.getParameter("textarea-abstract");
String key = request.getParameter("textarea-key");
Integer result = limitPaperService.insertPaper(title,key,abstrac,link,year);
if(result == 1){
System.out.println("插入成功");
}else{
System.out.println("插入失败");
}
return "paperlist";
}
}
七、心路历程和收获
7.1 心路历程
221801112:
万事开头难,在本次完成作业的过程中,我们一开始决定使用已有的json数据来初始化数据库,打开助教爬取的一条json数据,里面包含了成百上千的数据,如何找到我们需要的数据?感觉无从下手,其次关键词等多个数据应该如何存入数据库?但是在和队友持续讨论和资料查询过程中,我们完成了数据库的初始化。数据完成了,新的问题又出现了,前端如何展示?后端如何分析数据?由于我们都对后端感兴趣,所以我们选择按功能分配任务,独立完成开发。
221801116:
在项目开发中,我负责将论文数据展示与排版,刚开始时我选择layui原生表格来展示数据,但是在取得一部分表格后我发现论文的关键词和摘要等部分的内容很庞大,使用原生表格给人的观感很不好,于是只能舍弃这个方案重新找寻其他方法,最后在layui独立模块的启发下,写了一个新的卡片式表格,利用layui封装好的数据请求,获取论文数据。成功的将论文以卡片的形式展示出来。
7.2 收获
221801112:
技术:学习并实践mybatis +springboot+thymeleaf。 其他:在与队友不断交流的过程,提升了自己表达的能力。
221801116:
技术:学习并实践mybatis +springboot+thymeleaf,layui模块式前端开发,服务器项目部署。
八、评价结对队友
221801112:
csk同学在这次作业中表现了强大的学习能力,和实践能力。是我们项目的有力推动者,每当我编程出现问题,sk同学都会竭尽全力,帮助是解决问题。
221801116:
cx同学的编码能力很强,在我还在考虑前端页面展示的大概样式时,他就已经开始对助教的数据进行分析处理,并且很快将处理好的数据投入使用。项目编程期间,cx同学很能吃苦,每天晚上都奋战到很晚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号