



今天完成spark实验6:Spark Streaming编程初级实践。
1、安装Flume
Flume 是 Cloudera 提供的一个分布式、可靠、可用的系统,它能够将不同数据源的海量 日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。Flume 的 核心是把数据从数据源收集过来,再送到目的地。请到 Flume 官网下载 Flume1.7.0 安装文 件,下载地址如下: http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz 或者也可以直接到本教程官网的 “ 下 载 专 区 ” 中 的 “ 软 件 ” 目 录 中 下 载 apache-flume-1.7.0-bin.tar.gz。 下载后,把 Flume1.7.0 安装到 Linux 系统的“/usr/local/flume”目录下,具体安装和使用方法可以参考教程官网的“实验指南”栏目中的“日志采集工具 Flume 的安装与使用方法”。

2、使用Avro数据源测试Flume
Avro 可以发送一个给定的文件给 Flume,Avro 源使用 AVRO RPC 机制。请对 Flume 的相关配置文件进行设置,从而可以实现如下功能:在一个终端中新建一个文件 helloworld.txt(里面包含一行文本“Hello World),在另外一个终端中启动 Flume 以后, 可以把 helloworld.txt 中的文本内容显示出来。
⑴agent 配置文件
![]()
然后,我们在 avro.conf 写入以下内容
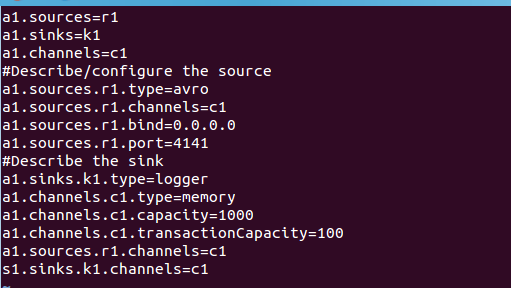
上面 Avro Source 参数说明如下: Avro Source 的别名是 avro,也可以使用完整类别名 称 org.apache.flume.source.AvroSource,因此,上面有一行设置是 a1.sources.r1.type = avro,表示数据源的类型是 avro。bind 绑定的 ip 地址或主机名,使用 0.0.0.0 表示绑定机 器所有的接口。a1.sources.r1.bind = 0.0.0.0,就表示绑定机器所有的接口。port 表示绑定 的端口。a1.sources.r1.port = 4141,表示绑定的端口是 4141。a1.sinks.k1.type = logger, 表示 sinks 的类型是 logger。
⑵启动 flume agent a1

⑶创建指定文件
先打开另外一个终端,在/usr/local/flume 下写入一个文件 log.00,内容为 hello,world:
启动日志控制台
![]()
我们再打开另外一个终端,执行:

此时我们可以看到第一个终端(agent 窗口)下的显示,也就是在日志控制台,就会把 log.00 文件的内容打印出来:
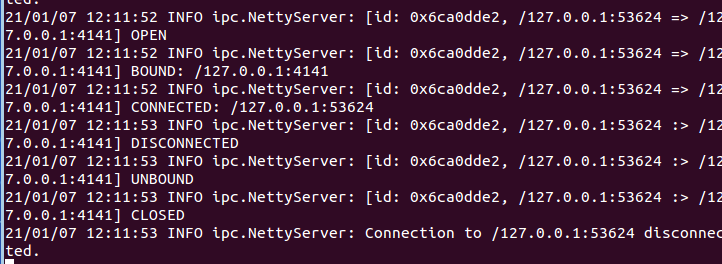
avro source 执行成功!
3、使用netcat数据源测试Flume
请对 Flume 的相关配置文件进行设置,从而可以实现如下功能:在一个 Linux 终端(这里称为“Flume 终端”)中,启动 Flume,在另一个终端(这里称为“Telnet 终端”)中, 输入命令“telnet localhost 44444”,然后,在 Telnet 终端中输入任何字符,让这些字符可以 顺利地在 Flume 终端中显示出来。
⑴创建 agent 配置文件

在 example.conf 里写入以下内容:
1.#example.conf: A single-node Flume configuration 2.# Name the components on this agent 3.a1.sources = r1 4.a1.sinks = k1 5.a1.channels = c1 6.# Describe/configure the source 7.a1.sources.r1.type = netcat 8.a1.sources.r1.bind = localhost 9.a1.sources.r1.port = 44444 10.#同上,记住该端口名 11.# Describe the sink 12.a1.sinks.k1.type = logger 13.# Use a channel which buffers events in memory 14.a1.channels.c1.type = memory 15.a1.channels.c1.capacity = 1000 16.a1.channels.c1.transactionCapacity = 100 17.# Bind the source and sink to the channel 18.a1.sources.r1.channels = c1 19.a1.sinks.k1.channel = c1
⑵启动 flume agent (即打开日志控制台):
再打开一个终端,输入命令:telnet localhost 44444

然后我们可以在终端下输入任何字符,第一个终端的日志控制台也会有相应的显示,如 我们输入”hello,world”,得出
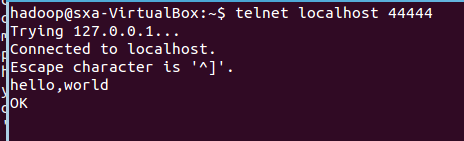
第一个终端的日志控制台显示:

netcatsource 运行成功!
这里补充一点,flume 只能传递英文和字符,不能用中文.
4、使用Flume作为Spark Streaming数据源
Flume 是非常流行的日志采集系统,可以作为 Spark Streaming 的高级数据源。请把 Flume Source 设置为 netcat 类型,从终端上不断给 Flume Source 发送各种消息,Flume 把消息汇集 到 Sink,这里把 Sink 类型设置为 avro,由 Sink 把消息推送给 Spark Streaming,由自己编写的Spark Streaming 应用程序对消息进行处理。
⑴配置 Flume 数据源
请登录 Linux 系统,打开一个终端,执行如下命令新建一个 Flume 配置文件 flume-to-spark.conf:

flume-to-spark.conf 文件中写入如下内容:
#flume-to-spark.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 33333 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port =44444 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 1000000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
在上面的配置文件中,我们把 Flume Source 类别设置为 netcat,绑定到 localhost 的 33333 端口,这样,我们后面就可以通过“telnet localhost 33333”命令向 Flume Source 发 送消息。
同时,我们把 Flume Sink 类别设置为 avro,绑定到 localhost 的 44444 端口,这样, Flume Source 把采集到的消息汇集到 Flume Sink 以后,Sink 会把消息推送给 localhost 的 44444 端口,而我们编写的 Spark Streaming 程序一直在监听 localhost 的 44444 端口,一 旦有消息到达,就会被 Spark Streaming 应用程序取走进行处理。
特别要强调的是,上述配置文件完成以后,暂时“不要”启动 Flume Agent,如果这个时 候使用“flume-ng agent”命令启动 agent,就会出现错误提示“localhost:44444 拒绝连接”,也 就是 Flume Sink 要发送消息给 localhost 的 44444 端口,但是,无法连接上 localhost 的 44444 端口。
为什么会出现这个错误呢?因为,这个时候我们还没有启动 Spark Streaming 应用程序,也就没有启动 localhost 的44444 端口,所以,Sink 是无法向这个端口发送消息 的。
⑵Spark 的准备工作
Kafka 和 Flume 等高级输入源,需要依赖独立的库(jar 文件)。按照我们前面安装好 的 Spark 版本,这些 jar 包都不在里面,为了证明这一点,我们现在可以测试一下。请打开 一个新的终端,然后启动 spark-shell:

启动成功后,在 spark-shell 中执行下面 import 语句:

你可以看到,马上会报错,因为找不到相关的 jar 包。所以,现在我们就需要下载 spark-streaming-flume_2.11-2.1.0.jar,其中2.11表示对应的Scala版本号,2.1.0表示Spark 版本号。
现在请在 Linux 系统中,打开一个火狐浏览器,打开下方的网址http://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume_2.11/2.1.0,里面有提供 spark-streaming-flume_2.11-2.1.0.jar 文件的下载。
下载后的文件会被默认保存在当前 Linux 登录用户的下载目录下,本教程统一使用 hadoop 用户名登录 Linux 系统,所以,文件下载后会被保存到“/home/hadoop/下载”目录下面。现在,我们在“/usr/local/spark/jars”目录下新建一个“flume”目录,就把这个文件复制到 Spark 目录的“/usr/local/spark/jars/flume”目录下。请新打开一个终端,输入下面命令:

![]()
我们就成功地把 spark-streaming-flume_2.11-2.1.0.jar 文件拷贝到了 “/usr/local/spark/jars/flume”目录下。
下面还要继续把 Flume 安装目录的 lib 目录下的所有 jar 文件复制到 “/usr/local/spark/jars/flume”目录下,请在终端中执行下面命令:

![]()
这样,我们就已经准备好了 Spark 环境,它可以支持 Flume 相关编程了。
⑶编写 Spark 程序使用 Flume 数据源
下面,我们就可以进行程序编写了。请新打开一个终端,然后,执行命令创建代码目录:
请在 FlumeEventCount.scala 代码文件中输入以下代码
package org.apache.spark.examples.streaming import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming._ import org.apache.spark.streaming.flume._ import org.apache.spark.util.IntParam object FlumeEventCount { def main(args: Array[String]) { if (args.length < 2) { System.err.println( "Usage: FlumeEventCount <host> <port>") System.exit(1) } StreamingExamples.setStreamingLogLevels() val Array(host, IntParam(port)) = args val batchInterval = Milliseconds(2000) // Create the context and set the batch size val sparkConf = new SparkConf().setAppName("FlumeEventCount").setMaster("local [2]") val ssc = new StreamingContext(sparkConf, batchInterval) // Create a flume stream val stream = FlumeUtils.createStream(ssc, host, port, StorageLevel.MEMORY_ONLY_S ER_2) // Print out the count of events received from this server in each batch stream.count().map(cnt => "Received " + cnt + " flume events." ).print() ssc.start() ssc.awaitTermination() } }
保存 FlumeEventCount.scala 文件并退出 vim 编辑器。FlumeEventCount.scala 程序在 编译后运行时,需要我们提供 host 和 port 两个参数,程序会对指定的 host 和指定的 port 进行监听,Milliseconds(2000)设置了时间间隔为 2 秒,所以,该程序每隔 2 秒就会从指定 的端口中获取由 Flume Sink 发给该端口的消息,然后进行处理,对消息进行统计,打印出 “Received 0 flume events.”这样的信息。
然后再使用 vim 编辑器新建 StreamingExamples.scala 文件,输入如下代码,用于控制日志输出格式:
package org.apache.spark.examples.streaming import org.apache.log4j.{Level, Logger} import org.apache.spark.internal.Logging object StreamingExamples extends Logging { /** Set reasonable logging levels for streaming if the user has not configured log4 j. */ def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { // We first log something to initialize Spark's default logging, then we overri de the // logging level. logInfo("Setting log level to [WARN] for streaming example." + " To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }
保存 StreamingExamples.scala 文件并退出 vim 编辑器。
这样,我们在“/usr/local/spark/mycode/flume/src/main/scala”目录下,就有了如下两个 代码文件:
FlumeEventCount.scala
StreamingExamples.scala
然后,新建一个 simple.sbt 文件:
在 simple.sbt 中输入以下代码:
name := "Simple Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0" libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.1.0" libraryDependencies += "org.apache.spark" % "spark-streaming-flume_2.11" % "2.1.0"
保存文件退出 vim 编辑器。然后执行下面命令,进行打包编译:

打包成功后,就可以执行程序测试效果了。
⑷测试程序效果
关闭之前打开的所有终端。首先,请新建第 1 个 Linux 终端,启动 Spark Streaming 应 用程序,命令如下:
1.cd /usr/local/spark
2. ./bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/flume/* --class "org.apache.spark.examples.streaming.FlumeEventCount" /usr/local/spark/mycode/flume/target/scala-2.11/simpleproject_2.11-1.0.jar localhost 44444
通过上面命令,我们为应用程序提供 host 和 port 两个参数的值分别为 localhost 和 44444,程序会对 localhost 的 44444 端口进行监听,Milliseconds(2000)设置了时间间隔为 2 秒,所以,该程序每隔 2 秒就会从指定的端口中获取由 Flume Sink 发给该端口的消息, 然后进行处理,对消息进行统计,打印出“Received 0 flume events.”这样的信息。
执行该命令后,屏幕上会显示程序运行的相关信息,并会每隔 2 秒钟刷新一次信息, 大量信息中会包含如下重要信息:
-------------------------------------------
Time: 1488029430000 ms
-------------------------------------------
Received 0 flume events.
因为目前 Flume 还没有启动,没有给 FlumeEventCount 发送任何消息,所以 Flume Events 的数量是 0。第 1 个终端不要关闭,让它一直处于监听状态。
现在,我们可以再另外新建第 2 个终端,在这个新的终端中启动 Flume Agent,命令如 下:
1.cd /usr/local/flume
2.bin/flume-ng agent --conf ./conf --conf-file ./conf/flume-to-spark.conf --name a1 -Dflume.root.logger=INFO,console
启动 agent 以后,该 agent 就会一直监听 localhost 的 33333 端口,这样,我们下面就 可以通过“telnet localhost 33333”命令向 Flume Source 发送消息。第 2 个终端也不要关闭, 让它一直处于监听状态。
请另外新建第 3 个终端,执行如下命令:
1.telnet localhost 33333
执行该命令以后,就可以在这个窗口里面随便敲入若干个字符和若干个回车,这些消息都会被 Flume 监听到,Flume 把消息采集到以后汇集到 Sink,然后由 Sink 发送给 Spark 的 FlumeEventCount 程序进行处理。然后,你就可以在运行 FlumeEventCount 的前面那个终端窗口内看到类似如下的统计结果:
-------------------------------------------
Time: 1488029430000 ms
-------------------------------------------
Received 0 flume events.
#这里省略了其他屏幕信息
-------------------------------------------
Time: 1488029432000 ms
-------------------------------------------
Received 8 flume events.
#这里省略了其他屏幕信息
-------------------------------------------
Time: 1488029434000 ms
-------------------------------------------
Received 21 flume events.
从屏幕信息中可以看出,我们在 telnet 那个终端内发送的消息,都被成功发送到 Spark 进行处理了。
至此,本实验顺利完成。
实验结束后,要关闭各个终端,只要切换到该终端窗口,然后 按键盘的 Ctrl+C 组合键,就可以结束程序运行。

