


大佬的链接:https://blog.csdn.net/weixin_45901519/article/details/108393658?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduend~default-2-108393658.nonecase&utm_term=pandas%20%E4%B8%A4%E8%A1%A8%E6%8B%BC%E6%8E%A5&spm=1000.2123.3001.4430
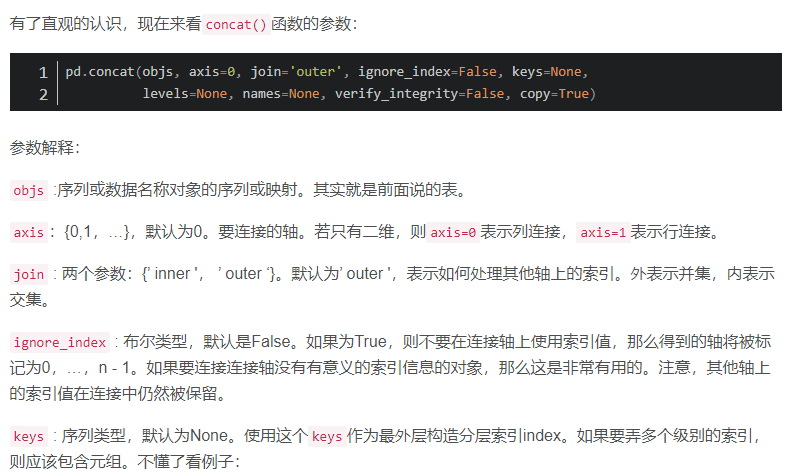
1、concat()
concat()函数一般是若干个数据结构相同的表格进行拼接。
现在有三个DataFrame表:df1、df2、df3,列名columns相同,而索引index不同,直接合并就是下面这样的结果:
>>> import pandas as pd >>> df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3]) >>> df1 A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 >>> df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'C': ['C4', 'C5', 'C6', 'C7'], 'D': ['D4', 'D5', 'D6', 'D7']}, index=[4, 5, 6, 7]) >>> df2 A B C D 4 A4 B4 C4 D4 5 A5 B5 C5 D5 6 A6 B6 C6 D6 7 A7 B7 C7 D7 >>> df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'], 'B': ['B8', 'B9', 'B10', 'B11'], 'C': ['C8', 'C9', 'C10', 'C11'], 'D': ['D8', 'D9', 'D10', 'D11']}, index=[8, 9, 10, 11]) >>> df3 A B C D 8 A8 B8 C8 D8 9 A9 B9 C9 D9 10 A10 B10 C10 D10 11 A11 B11 C11 D11 >>> frames = [df1, df2, df3] >>> result = pd.concat(frames) >>> result A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 4 A4 B4 C4 D4 5 A5 B5 C5 D5 6 A6 B6 C6 D6 7 A7 B7 C7 D7 8 A8 B8 C8 D8 9 A9 B9 C9 D9 10 A10 B10 C10 D10 11 A11 B11 C11 D11
2、append()
对于concat()操作,一个有用的快捷方式是Series和DataFrame上的append()实例方法。沿axis=0进行拼接,即索引。
result = df1.append(df2)结果:
3、merge()
pandas提供的函数merge()主要作为两个表的横向拼接
4、join()
join()是一种方便的方法,主要用于索引上的合并。可以将两个可能具有不同索引的数据变量的列组合为单个结果数据变量。下面是一个非常基本的例子:
In [79]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [80]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [81]: result = left.join(right)结果:
结果:

In [83]: result = left.join(right, how='inner')结果:


