

一.前言
JDK1.8 Hashmap采用的是数组+链表+红黑树的数据结构
二.基本参数介绍
/** * The default initial capacity - MUST be a power of two.
* 桶的容量,默认16 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30.
* 桶的最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30
/**
* The load factor used when none specified in constructor.
* 负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage.
* 树化阀值
*/ static final int TREEIFY_THRESHOLD = 8; /** * The bin count threshold for untreeifying a (split) bin during a * resize operation. Should be less than TREEIFY_THRESHOLD, and at * most 6 to mesh with shrinkage detection under removal.
* 树退化阀值 */ static final int UNTREEIFY_THRESHOLD = 6; /** * The smallest table capacity for which bins may be treeified. * (Otherwise the table is resized if too many nodes in a bin.) * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts * between resizing and treeification thresholds.
* 最小树化容量阀值即容量必要大于64才开始树化
* 避免树化和扩容冲突
*/ static final int MIN_TREEIFY_CAPACITY = 64;
三.扩容
先看下JDK1.7Hashmap扩容源码

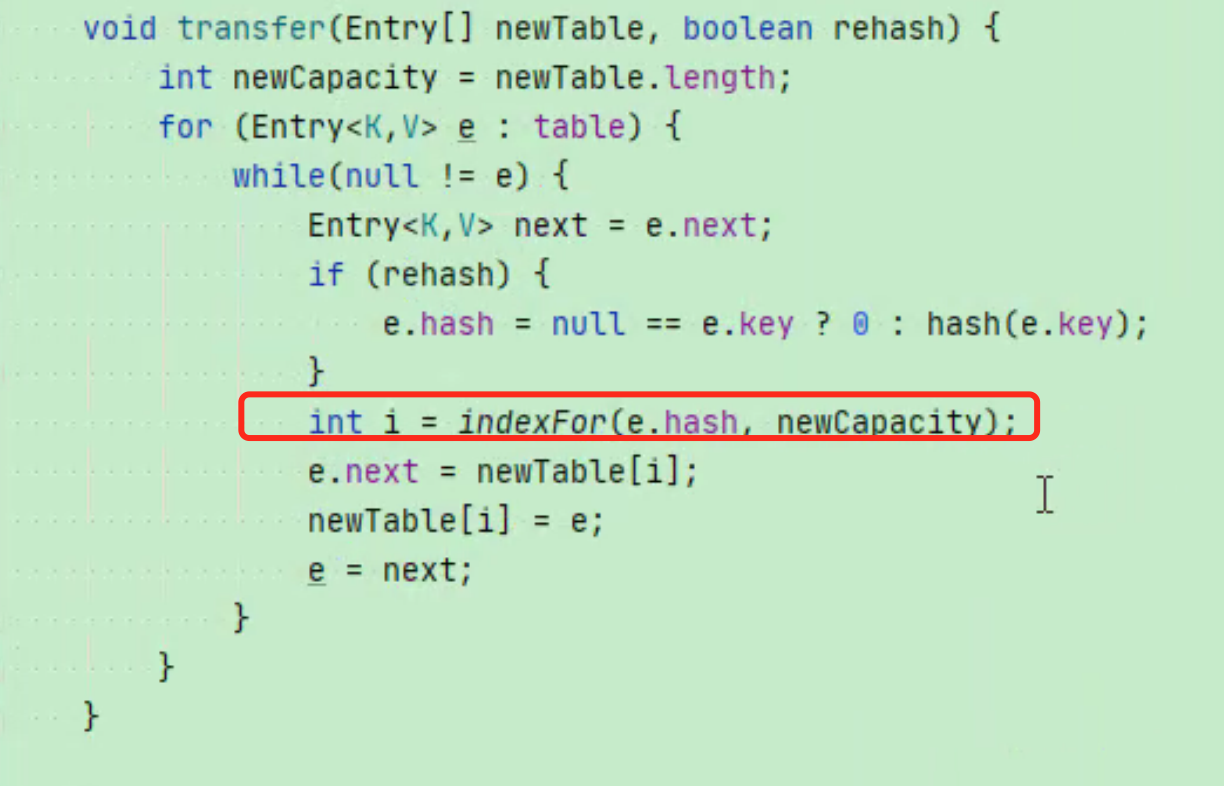
明显我们看出在JDK1.7中,先扩容,再存储。
扩容条件:当前数量大于 容量* 负载因子 并且数组下标的值不为空,即假如新插入的数据位置在一个数组位置而不是链表上,则插入成功而不扩容(有人只看前面条件,后面条件被忽视)
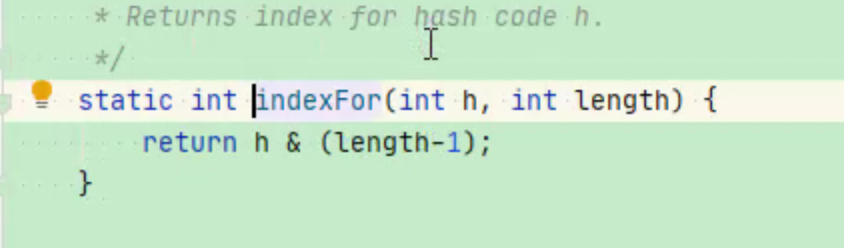
扩容后的位置怎么计算尼?
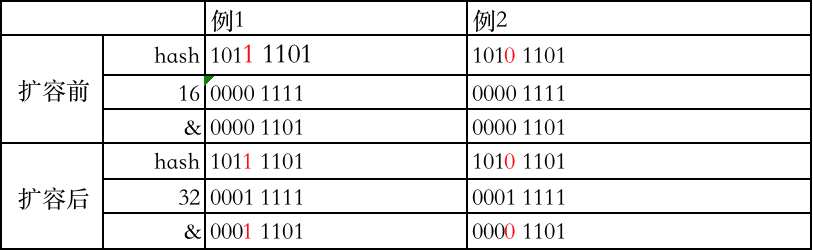
我们看例1,假设hash为1011 1101 即349,数组容量为16,但是我们数组是从0开始计算,则数组下标实际长度为15即0000 1111,通过&运算,得到数组下标值为13。扩容后,数组容量为32,通过&运算得到数组下标值为29。
我们再看例2,假设hash为1010 1101即317,&运算得到数组下标为13。扩容后,得到数组下标值为13。
我们可以看到表格中红色标注部分,扩容后,原值的hash受原数组容量影响。新值的下标是原下标或原下标+数组容量,如果数组存在链表,因为他们hash值相同,所以链表上的值 也跟着相应移动且位置发生倒转(即原来链表顺序是1,2,3 在新数组编程3,2,1)。
再看JDK1.8Hashmap扩容源码

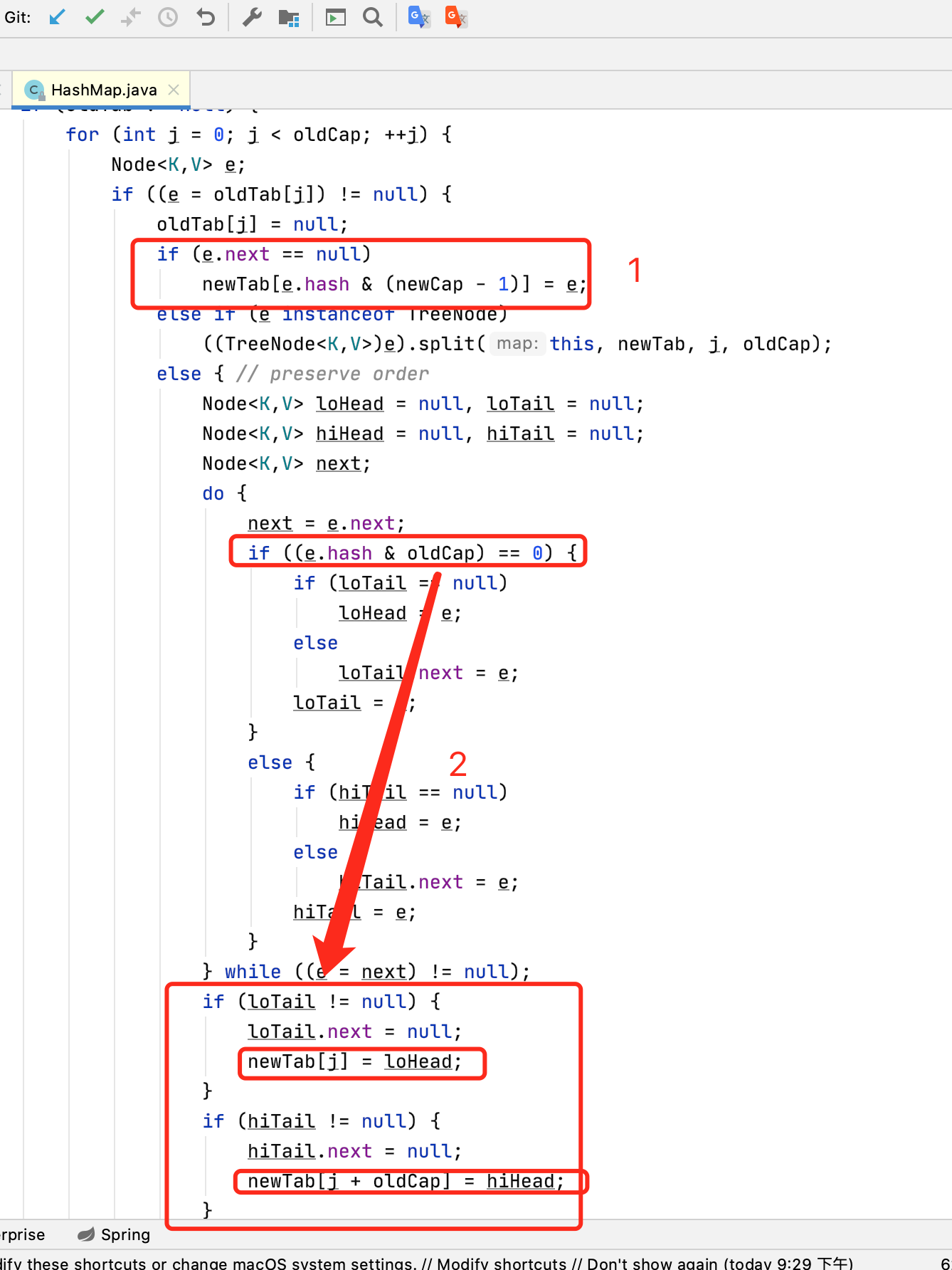
仔细看第一个图,我们发现++size,即JDK1.8是先存储,后扩容。扩容条件只有大于容量*负载因子
JDK1.8的数据结构是数组+链表+红黑树,Node<K,V>中存储着链表节点next 也是Node<K,V>结构。
我们可以看出图片标记1处 如果旧值不存在链表,则根据hash值和新容量&计算数组下标并赋值。但是存在链表
如果旧值的hash和旧的容量计算&为0,则扩容后的位置等于原来坐标。
如果旧值的hash和旧的容量计算&为1,则扩容后的位置等于原来坐标+旧的容量
四.扩展知识
- JDK1.7和JDK1.8Hashmap区别?
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法。因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
扩容后数据存储位置的计算方式也不一样。见第三点
- 为什么负载因子不是0.5或1?
如果是0.5,临界值是8 则很容易就触发扩容,而且还有一半容量还没用
如果是1,当空间被占满时候才扩容,增加插入数据的时间
0.75即3/4,capacity值是2的幂,相乘得到结果是整数
- 为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者5呢?
根据注释中写到,理想情况下,在随机哈希码和默认大小调整阈值为 0.75 的情况下,存储桶中元素个数出现的频率遵循泊松分布,平均参数为 0.5,有关 k 值下,随机事件出现频率的计算公式为 (exp(-0.5) * pow(0.5, k) /factorial(k)))大体得到一个数值是8,那么退化树阀值为什么是6?如果退化树阀值也是8,则会陷入树化和退化的死循环中。如果退化阀值是7,假如对hash进行频繁的增删操作,同样会进入死循环中。如果退化树阀值小于5,我们知道红黑树在低元素查询效率并不比链表高,而且红黑树会存储很多索引,占有内存。所以退化阀值设为6比较合理。
- JDK1.7是先扩容再插入,而JDK1.8是先插入再扩容。为什么?
这个问题网上查找很多资料没有明确答案。可能原因是JDK1.7采用头插法,扩容后,计算hash,只需要插入链表头部就行。而JDK1.8采用尾插法,如果先扩容,扩容后需要遍历一遍,再找到尾部进行插入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号