
day01-MYSQL
关系型数据库:
主要是用来描述实体与实体之间的关系
实体指实实在在存在的事物:学生和班级,员工和部门
E-R关系图:实体-联系图(Entity Relationship Diagram),包括:实体(方框)、属性(椭圆形)、关系(菱形)
mysql:中小型企业,被sun收购,后sun被oracle收购
oracle:,甲骨文公司,大型电商企业
sqlserer:windows里面,政府网站
db2:
NOSQL非关系型数据库:(key:value)
mongodb:
redis:
MYSQL数据库服务器
MYSQL数据库:数据库管理软件
服务器:就是一台电脑,这台安装相关的服务器软件,这些软件会监听不同的端口号,根据用户访问的端口号提供不同的服务。
MYSQL的安装和卸载(windows)
卸载:
打开控制面板,删除软件
删除mysql安装目录的所有文件C:\Program Files\MySQL
删除mysql数据存放文件C:\ProgramData\MySQL(说明:文件夹ProgramData是个隐藏文件夹,设置为显示即可)
安装:
运行安装程序:在启动配置教程之前,一路下一步,没有下一步的话就直接finish
第一次finish之后启动服务器配置教程
第一个include mysql bin directory to windows path(为以后在dos窗口执行mysql命令设置path路径)
第二个:端口号不要去修改,字符集要选择UTF8,密码不要忘记了
MAC电脑配置可参考:
https://blog.csdn.net/liuzr_/article/details/125718229
https://cloud.tencent.com/developer/article/1606801?from=15425&areaSource=102001.1&traceId=TB8fPoFRXOuDicMzt7Zta
MYSQL的Sql语言分类
DDL:数据定义语言:定义数据库,数据表他们的结构:create、drop、alter
DML:数据操作语言:主要是用来操作数据:insert、update、delete
DCL:数据控制语言:定义访问权限,取消访问权限,安全设置:grant
DQL:数据查询语言:select、from子句、where子句
数据库的CRUD的操作
首先要登录数据库服务器:mysql -uroot -proot //注意:-u和-p后面不可以有空格;语句末尾处不可以有分号结束
创建数据库
create database 数据库的名字; create database day06; create database 数据库的名字 character set 字符集; create database day06_1 character set utf8; create database 数据库的名字 character 字符集 collate 校对规则; create database day06_2 character utf8 collate utf8_bin;
查看数据库
--查看数据库定义的语句 show create database 数据库的名字 show create database day06; --查看所有数据库 show databases;
修改数据库的操作
--修改数据的字符集 alter database 数据库的名字 character set 字符集 alter database day06_1 character set gbk;
删除数据库
drop database 数据库的名字; drop database day06_2;
其他数据库操作命令
--切换数据库(选中数据库) use 数据库名字 use day06; --查看一下当前正在使用的数据库 select database();
表结构的操作
创建表
create table 表名( 列名 列的类型(长度) 约束, 列名 列的类型(长度) 约束 );
列的类型:
java sql
int int
char/string char/varchar
char:固定长度
varchar:可变长度
char(3):-空格空格
varchar(3):-
长度代表的是字符的个数
double double
float float
boolean boolean
date date:YYYY-MM-DD
time:hh:mm:ss
datetime:YYYY-MM-DD hh:mm:ss 默认值是null
timestamp:YYYY-MM-DD hh:mm:ss 默认使用当前时间
text:主要是用来存放文本
blob:存放的是二进制
列的约束:
主键约束:primary key
唯一约束:unique
非空约束:not null
自动增长:
auto_increment
创建表:
create table student(
sid int primary key,
sname varchar(31),
sex int,
age int
);
查看表
--查看所有的表
show tables;
--查看表的定义(查看表的创建语句)
show create table student;
--查看表结构
desc student;
修改表
--添加列(add)
alter table 表名 add 列名 列的类型 列的约束
alter table student add chengji int not null;
--修改列(modify)
alter table student modify sex varchar(2);
--修改列名(change)
alter table student change sex gender varchar(2);
--删除列(drop)
alter table student drop chengji;
--修改表名(rename)
rename table student to heima;
--修改表的字符集
alter table heima character set gbk;
删除表
drop table heima;
Sql完成对表中数据的CRUD操作
插入数据
insert into 表名(列名1,列名2,列名3)values(值1,值2,值3); insert into student(sid,sname,sex,age) values(1,'zhangsan',1,23);
--简单写法:如果插入的是全列名的数据,表名后面的列名可以省略
insert into student values(2,'zhangsan',1,23); //全列名插入
--批量插入
insert into student values(4,'zhangsan',1,23),(5,'zhangsan',1,23),(6,'zhangsan',1,23);
--单条插入和批量插入的效率
批量插入的效率高,因为关键字insert仅需要识别一次,但是批量插入若其中一条数据有问题,影响整个数据的插入。
--查看表中数据
select * from student;
命令行下插入中文乱码问题
临时解决方案:set name gbk;相当于是告诉mysql服务器软件,我们当前在命令行下输入的内容是GBK编码,当命令窗口关闭之后,它再输入中文就会存在问题。
永久解决办法:修改my.ini配置文件(在mysql软件安装路径里)
1.暂停mysql的服务
2.在mysql安装路径中找到my.ini配置文件:C:\Program Files\MySQL\MySQL Server 5.5
3.将57行的编码改成gbk
4.保存文件退出exit
5.启动mysql服务
删除记录
delete from 表名 [where 条件] delete from student where sid=10;
delete from student;如果没有指定条件,会将表中数据一条一条全部删除
--面试问题:请说一下 delete删除数据和truncate删除数据有什么差别
delete:DML:一条一条删除表中的数据
truncate:DDL:先删除表再重建表
关于哪条执行效率高:具体要看表中的数据量
如果数据量比较少,delete比较高效
如果是数据比较多,truncate比较高效
更新表记录
update 表名 set 列名=列的值,列名2=列的值2 [where 条件]
--将sid为5的名字修改
--如果参数是字符串,日期要加上单引号
update student set sname='李四' where sid=5;
update student set sname='里斯',sex=0;
查询记录
select [distinct] [*] [列名1,列名2] from 表名 [where 条件] distinct:去除重复的数据
create table category(
cid int primary key auto_increment,
cname varchar(10),
cdesc varchar(31)
);
insert into category values(null,'手机数码','电子产品');
create table product(
pid int primary key auto_increment,
pname varchar(10),
price double,
pdate timestamp,
cno int
);
insert into product values(null,'小米mix4',998,null,1);
--别名查询。as关键字,as关键字是可以省略的
--表别名:select p.pname,p.price from product p;(主要是用在多表查询)
--列别名:select pname as 商品名称,price as 商品价格 from product;
省略as关键字:select pname 商品名称,price 商品价格 from product;
--去掉重复的值
select distinct price from product;
--select运算查询:仅仅在查询结果上做了运算(+ - * /),并未改变原值
select *,price*1.5 as 折后价 from product;
--条件查询[where关键字]
--where后的条件写法
--关系运算符:> >= < <= = != <>
!=:不等于:非标准SQL语法,最早出现在sqlserver中
<>:不等于:标准SQL语法
--判断某一列是否为空:is null is not null
--查询商品价格在10到100之间(between...and)
select * from product where price>10 and price <100;
select * from product where price between 10 and 100;
--逻辑运算:and or not
--like:模糊查询
_:代表的是一个字符
%:代表的是多个字符
--查询出名字中带有饼的所有商品
select * from product where pname like '%饼%';
--查询名字第二个字是熊的所有商品 '_熊%'
select * from product where pname like '_熊%';
--in 在某个范围中获得值
--排序查询:order by 关键字
asc:ascend 升序(默认的排序方式)
desc:descend 降序
--查询名称中有小的商品,按价格降序排序
select * from product where pname like '%小%' order by price desc;
--聚合函数
sum():求和
avg():求平均值
count():统计数量
max():最大值
min():最小值
注意:where条件后面不能接聚合函数
--查询出商品价格大于平均价格的所有商品
select * from product where price > (select avg(price) from product);
select * from product where price > avg(price); //这句话是错误的,报错:Invalid use of group function
--分组:group by
--根据cno字段分组,分组后统计商品的个数
select cno,count(*) from product group by cno;
--根据cno字段分组,分组统计每组商品的平均价格,并且商品平均价格>60
select cno,avg(price) from product group by cno having avg(price)>60;
--having关键字可以接聚合函数的 出现在分组之后
--where关键字 它是不可以接聚合函数,出现在分组之前
--编写顺序
select..from..where..group by..having..order by
--执行顺序
from..where..group by..having..select..order by
day02-多表操作
多表之间的关系如何来维护?
外键约束:foreign key
给product中的这个cno添加一个外键约束
alter table product add foreign key(cno) references category(cid);
添加约束后:
1.子表product不能insert表category中不存在的cid的记录;
2.父表category不能删除子表中已存在对应cid=pno的记录,需先删除product表中对应的cid=pno的记录才行;
多表之间的建表原则:
一对多:商品和分类
建表原则:在多的一方添加一个外键,指向一的一方的主键
多对多:学生和课程
建表原则:多建一张中间表,将多对多的关系拆成一对多的关系,中间表至少要有两个外键:这两个外键分别指向原来的那两张表
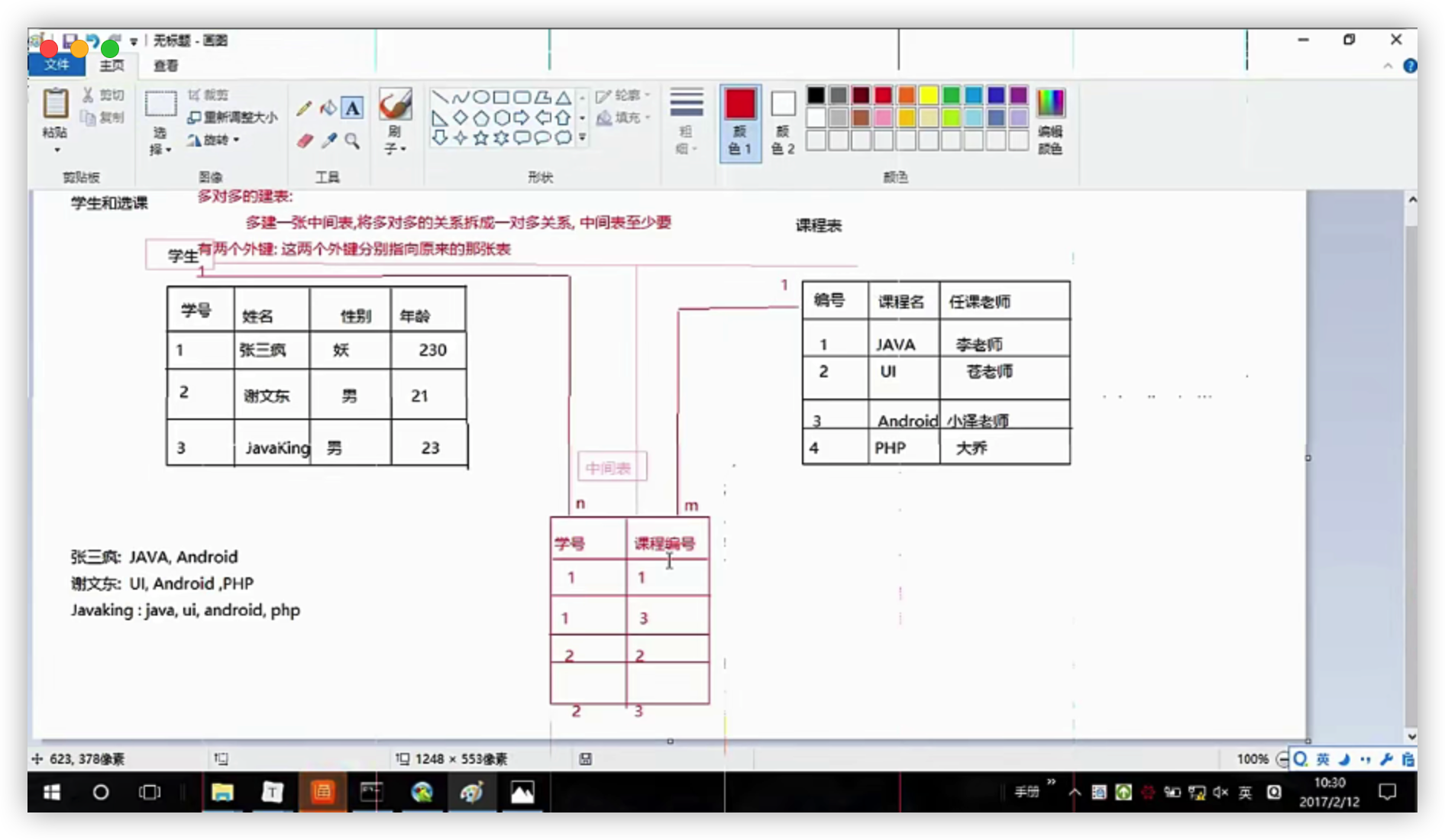
一对一:公民和身份证
建表原则:
1.将一对一的情况,当作是一对多的情况处理,在任意一张表添加一个外键,并且这个外键要唯一,指向另外一张表
2.直接将两张表合并成一张表
3.将两张表的主键建立起连接,让两张表里面主键相等
实际用途:不常用,拆表操作
主键约束:默认就是不能为空,唯一
外键都是指向另外一张表的主键
主键一张表只能有一个
唯一约束:列面的内容必须是唯一,不能出现重复情况,为空
唯一约束不可以作为其他表的外键
可以有多个唯一约束
多表查询
--交叉连接查询
--笛卡尔积,查出来是两张表的乘积,查出来的结果没有意义
select * from product,category;
--过滤出有意义的数据
select * from product,category where cno=cid;
select * from product p,category c where p.cno=c.cid; //别名
--内连接查询(结果为左右表的交集)
--隐式内连接
select * from product p,category c where p.cno=c.cid;
--显示内连接
select * from product p inner join category c on p.cno=c.cid;
--区别:
隐式内连接:在查询出结果的基础上去做的where条件过滤
显示内连接:带着条件去查询结果,执行效率要高
--左外连接:(结果为左右表的交集+左表独有的数据)
会将左表中的所有数据都查询出来,如果右表中没有对应的数据,用null代替
select * from product p left outer join category c on p.cno=c.cid;
--右外连接 :(结果为左右表的交集+右表自身独有的数据)
会将右表所有数据都查询出来,如果左表没有对应数据的话,用null代替
select * from product p right outer join category c on p.cno=c.cid;
说明:关键字inner、outer是可以省略的
分页查询
第一个参数是索引
第二个参数显示的个数
说明:起始索引是0
select * from product limit 0,3;
select * from product limit 3,3;
扩展:
需求:index代表显示第几页,页数从1开始,每页显示3条记录,求每页的起始索引
startIndex = (index-1)*3
子查询
--查询分类名称为手机数码的所有商品
select * from product where cno = (select cid from category wehre cname='手机数码');
--查询出(商品名称、商品分类名称)信息
select pname,(select cname from category c where p.cno=c.cid) as 商品分类名称 from product p;
拓展知识:
any,all关键字必须与一个比较操作符一起使用。
区别:
1、类型不同
这两个都是用于子查询的,any 是任意一个,all 是所有。
2、用法不同
select * from student where 班级='01' and age > all (select age from student where 班级='02');
就是说,查询出01班中,年龄大于 02班所有人 的 同学
相当于
select * from student where 班级='01' and age > (select max(age) from student where 班级='02');
而
select * from student where 班级='01' and age > any (select age from student where 班级='02');
就是说,查询出01班中,年龄大于02班任意一个的同学
相当于
select * from student where 班级='01' and age > (select min(age) from student where 班级='02');
day03-JDBC
JDBC入门(使用JDBC的基本步骤-查询操作)
1.注册驱动
DriverManager.registerDriver(new com.mysql.jdbc.Driver());
2.建立连接。参数一:协议+访问的数据库 参数二:用户名 参数三:密码
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/student","root","root");
3.创建statement,跟数据库打交道,一定需要这个对象
Statement st = conn.createStatement();
4.执行查询,得到结果
String sql = "select * from t_stu";
ResultSet rs = st.executeQuery(sql);
5.遍历查询每一条记录
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
System.out.println("id="+id+"===name===="+name+"===age==="+age);
}
6.释放资源
rs.close();
st.close();
conn.close();
抽取JDBC工具类
1.释放资源工作的整合
说明:此方法调用放在try...catch...finally语句的finally模块中
说明:把Connection conn、Statement st、ResultSet rs三个对象都按照如下方法写好,最后在新的public方法中调用
public static void release(Connection conn,Statement st,ResultSet rs){
closeConn(Connection conn);
closeSt(Statement st);
closeRs(ResultSet rs);
}
private static void closeSt(Statement st){
try{
if(st != null){
st.close();
}
}catch(SQLException e){
e.printStackTrace();
}finally{
st = null;
}
}
2.驱动防止二次注册
Driver这个类里面有静态代码块,一上来就执行,所以等同于我们注册了两次驱动,其实没这个必要的。
//静态代码块--》随着类的加载而加载。 java.sql.DriverManager.registerDriver(new Driver());
最后形成以下代码即可:
Class.forName("com.mysql.jdbc.Driver");
3.使用properties配置文件
3.1.在src底下声明一个文件 xxx.properties,里面的内容如下:
url=jdbc:mysql://localhost/student
3.2.在工具类里面,使用静态代码块(static{}),读取属性
//1.创建一个属性配置对象 Properties properties = new Properties();
//若把文件放在项目的根目录下,也可以使用以下语句加载jdbc.properties文件
//InputStream is = new FileInputStream("jdbc.properties");
//使用类加载器,去读取src底下的资源文件 InputStream is = JDBCUtil.class.getClassLoader().getResourceAsStream("jdbc.properties");//注意:此处的jdbc.properties文件一定要放在src文件夹下,才能在加载类文件时一起加载 //导入输入流 properties.load(is); //读取属性 url = properties.getProperty("url");
JDBC注册驱动小细节
Class.forName("com.mysql.jdbc.Driver");可以不写,在jdk4版本的时候,默认注册了,在META-INF下可以看到具体的驱动名
JDBC CRUD(sql)
insert
insert into t_stu(name,age) values ('wangqiang',28)
insert into t_stu values (NULL,'wangqiang',28)
delete
delete from t_stu where id = 6
query
select * from t_stu
update
update t_stu set age=38 where id = 1
使用单元测试,测试代码
1.定义一个类,TestXXX,里面定义方法 testXXX。
2.添加junit的支持。
Eclipse:右键工程》add Library>Junit>Junit4
3.在方法的上面加上注解,其实就是一个标记。
@Test
public void testQuery(){
...
}
4.光标选中方法名字,然后右键执行单元测试。或者打开outline视图,然后选择方法右键执行。
JDBC CRUD(添加操作)
Connection conn = DriverManager.getConnection(url,username,password); Statement st = conn.createStatement(); String sql = "insert into t_stu values (NULL,'wangqiang',28)";
int result = st.executeUpdate(sql); //执行此sql影响的行数,如果大于0表明操作成功,否则失败
JDBC CRUD(删除和更新操作)
String sql = "insert into t_stu values (NULL,'wangqiang',28)"; //删除和更新金需要更改对应的sql即可 int result = st.executeUpdate(sql); //执行此sql影响的行数,如果大于0表明操作成功,否则失败
DAO模式(声明与实现分开)
Data Access Object 数据访问对象
1.新建一个dao的接口,里面声明数据库访问规则
2.新建一个dao的实现类,具体实现早前定义的规则
3.直接使用实现
Statement安全问题
1.Statement执行,其实是拼接sql语句的。先拼接sql语句,然后再一起执行。
如果变量里面带有了数据库的关键字,那么一并认为是关键字,不认为是普通的字符串,如:password='10086' or '1=1'
2.PrepareStatement(预处理sql语句,解决statement出现的安全问题)
该对象就是替换前面的Statement对象。
1.相比较以前的statement,预先处理给定的sql语句,对其执行语法检查,在sql语句里面使用?占位符来替代后续要传递进来的变量。后面进来的变量值,将会被看成是字符串,不会产生任何的关键字。
JDBC PrepareStatement 介绍
Connection conn = DriverManager.getConnection(url,username,password); String sql = "select * from t_user where username=? and password=?"; //预先对sql语句执行语法的校验,?对应的内容,后面不管传递什么进来,都把它看成是字符串。or select PreparedStatement ps = conn.prepareStatement(sql); //?对应的索引从1开始
//给占位符赋值 ps.setString(1,username); ps.setInt(2,password); int result = st.executeUpdate();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号