
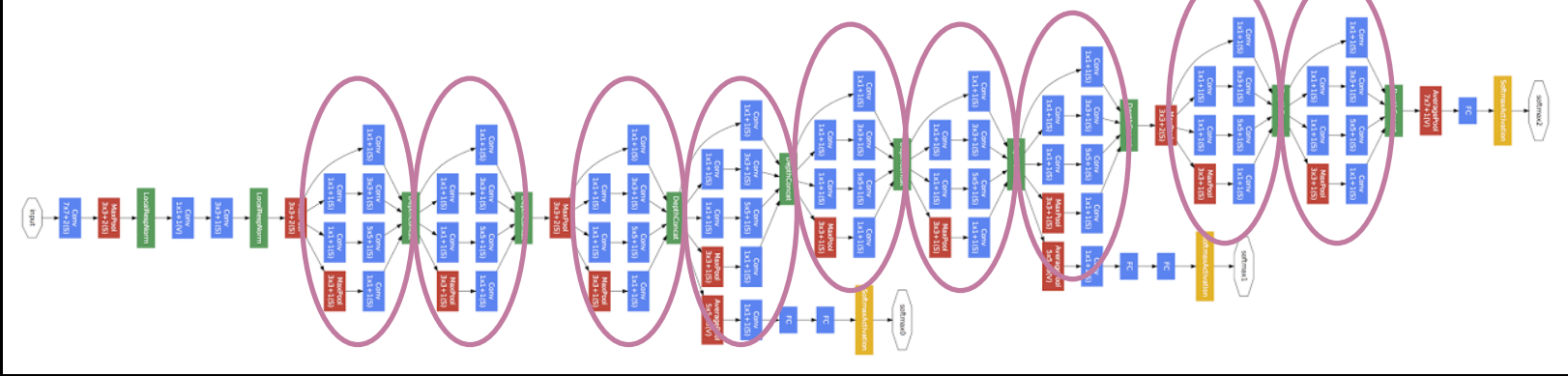
Inception Module
googlenet的Inception Module
Idea 1: Use 1x1, 3x3, and 5x5 convolutions in parallel to capture a variety of structures Also add a parallel max pooling path
The problem: Computational Expense quickly balloons
理念1:通过用平行的1*1,3*3,5*5的卷积来捕捉多样性的图片结构(包括使用一个最大池化)
缺点:计算量激增。
Idea 2:Use 1x1 convolutional layers for dimensional reduction. - Limits computational blow up from increasing parameters - The 1x1 convolutions also use ReLUs, so provide an added element of non-linearity
理念2:通过1*1的卷积减少维度。=》效果为,减少了计算量,通过relus激活函数的使用增加了非线性元素,(应该是有利于反向传播计算梯度)
参考
https://staff.fnwi.uva.nl/t.e.j.mensink/rdg/slides/4deepdeep.pdf
1*1 convolution 1*1卷积的作用:
1*1的卷积核并不会降低长宽的维度,所以输入的128*128像素的图片还是128*128,但是可以在channel,或者说feature 第三维上来减少维度。
参考
http://blog.csdn.net/visionfans/article/details/48270327
https://groups.google.com/forum/#!topic/caffe-users/ElVispDaYSE
https://www.zhihu.com/question/27393324

 浙公网安备 33010602011771号
浙公网安备 33010602011771号