
下载地址:https://jmeter-plugins.org/install/Install/
下载后文件为一个jar包,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。
启动jemter,点击选项,最下面的一栏,如下图所示:

打开插件的界面如下图:

Installed Plugins(已安装的插件):即插件jar包中已经包含的插件,可以通过选中勾选框,来使用这些插件;
Available Plugins(可下载的插件):即该插件扩展的一些插件,可以通过选中勾选框,来下载你所需要的插件;
Upgrades(可更新的插件):即可以更新到最新版本的一些插件,可以通过点击截图右下角的Apply Changes and Restart Jmeter按钮来下载更新;
二、常用插件
1、Transactions per Second(TPS)
即TPS:每秒事务数,性能测试中,最重要的2个指标之一。该插件的作用是在测试脚本执行过程中,监控查看服务器的TPS表现————比如整体趋势、实时平均值走向、稳定性等。
这个插件包含在Basic Graphs中,如下图

安装Basic Graphs后,一共有三个插件:
-
ransactions per Second:TPS插件
-
Response Times Over Time:事务响应时间插件
-
Active Threads Over Time:每秒的活动线程数插件
安装好后,重启jmeter,从监视器中就可以看到这三个插件,如下图所示:

TPS变化展示图:

2、Response Times Over Time(事物响应时间)
即*TRT:事务响应时间*,性能测试中,最重要的两个指标的另外一个。该插件的主要作用是在测试脚本执行过程中,监控查看响应时间的实时平均值、整体响应时间走向等。

3、Response Times Over Time(每秒活跃线程数)
统计每秒活动的线程总数

4、PerfMon Metrics Collector
即*服务器性能监控数据采集器*。在性能测试过程中,除了监控TPS和TRT,还需要监控服务器的资源使用情况,比如CPU、memory、I/O等。该插件可以在性能测试中实时监控服务器的各项资源使用。
在插件管理中安装PerfMon

安装完成后重启Jmeter,在监听器中可以看到该插件

还需下载一个服务端插件ServerAgent,下载地址:https://github.com/undera/perfmon-agent
将下载好的ServerAgent上传到被测服务器,解压,进入目录,Windows环境,双击ServerAgent.bat启动;linux环境执ServerAgent.sh启动,默认使用4444端口。
在Jmeter中启动PerfMon Metrics Collector插件,配置需要监听的项

前言 Transactions per Second 也就是每秒事务数,在性能测试中非常重要的一个指标,我们在聚合报告里面能看到最后的测试结果TPS值。 如果我们想查看更详细的报告,查看压测过程中不同时间段的每秒事务数,可以使用 Transactions per Second 插件来查看。
Transactions per Second jmeter安装后,添加监听器,是默认不带 Transactions per Second 
先安装jmeter插件管理器,前面一篇已经介绍过https://www.cnblogs.com/yoyoketang/p/14180667.html
在插件管理界面,勾选 jpgc - Standard Set,点安装

安装完成会自动重启jmeter
监听器-jp@gc - Transactions per Second Transactions per Second 插件的作用是在测试脚本执行过程中,监控查看服务器的TPS表现————比如整体趋势、实时平均值走向、稳定性等。 添加监听器-jp@gc - Transactions per Second 
设置线程5,循环100次开始压测,聚合报告看到吞吐量9.6/sec

再查看 jp@gc - Transactions per Second 插件的报告,可以看到更详细的实时的TPS

红色是代表全部成功的,有报错的话会绿色显示
前⾔
压测的时候,我们会经常关注2个重要的指标 TPS 和 RT
TPS 每秒处理的事务数(Transactions per Second),jmeter的Throughput为吞吐量(请求数/秒)
RT 响应时间(Reponse Time),从发起请求到完全接收到应答的时间消耗。
每秒处理的事务数(Transactions per Second)
前⾯介绍了监听器每秒事务数(Transactions per Second),可以查看前⾯的这篇
先了解下什么是TPS ?
TPS:每秒处理的事务数,jmeter的Throughput为吞吐率(请求数/秒)
宏观上:TPS=并发数/响应时间,jmeter的Throughput = (number of requests) / (total time)
很多⼩伙伴会死记硬背公式来推算TPS值,这⾥涉及到⼀个概念并发数,这个并发数是指单位时间内发出去的请求数。
这⾥的单位时间并不是1秒,是⼀个绝对的同⼀时间,⽐如0.0001秒,甚⾄更⼩的时间。
那么这⾥的绝对并发,我们是没法知道的,我们通常说的并发是⼀个相对的并发,相对并发,也就是我们线程组⾥⾯设置的(线程数)虚拟⽤户数,可以这么理解。

我们可以根据聚合报告看到,平均响应时间是94毫秒,吞吐量27.9/sec

通过上⾯的公式 tps = 线程数3/平均响应时间0.094秒 ,算出的结果是31.9,跟统计的27.9差不多。
也可以这样理解这个公式,绝对的并发是不存在的,请求发出的时间总有先后,绝对的TPS也是⽆法计算的,统计的⾓度看TPS = 服务器处理请求总数/花费的总时间
我们设置线程组的持续压测时间为5秒,设置线程数3,于是压测的结果TPS值是27.5

根据公式TPS = 总请求数139/总时长5秒,得到的结果是27.8,这样就很接近报告的TPS值了
为了找到服务器的最⼤TPS值,我们⼀般设置不同的并发数(线程组)来压测。
响应时间(Reponse Time)
RT 也就是平均响应时间(Reponse Time), 在聚合报告⾥⾯可以看平均值(单位是毫秒),如果我们想查看更详细的报告,跟着每个时间段的平均响应时间。添加-监听器-jp@gc - Response Times Over Time

压测后,先看聚合报告的平均值92毫秒
再看实时监控的平均响应时间

前言
jmeter压测的时候,在执行测试的过程中每个线程组有多少个活跃的线程数,可以通过监听器Active Threads Over Time查看
线程数与Ramp-Up时间
线程数就是我们设置是虚拟用户数,可以理解为1个线程,就是一个虚拟用户。 Ramp-Up时间 也就是启动时间,或者说是准备时间,比如我们设置线程数为10,那么这些用户不是一瞬间就来的,它需要有一个准备的时间。 线程数10, Ramp-Up时间设置为1秒,那么在1秒内会启动这些线程。 线程数10, Ramp-Up时间设置为2秒,那么在2秒内会启动这些线程。 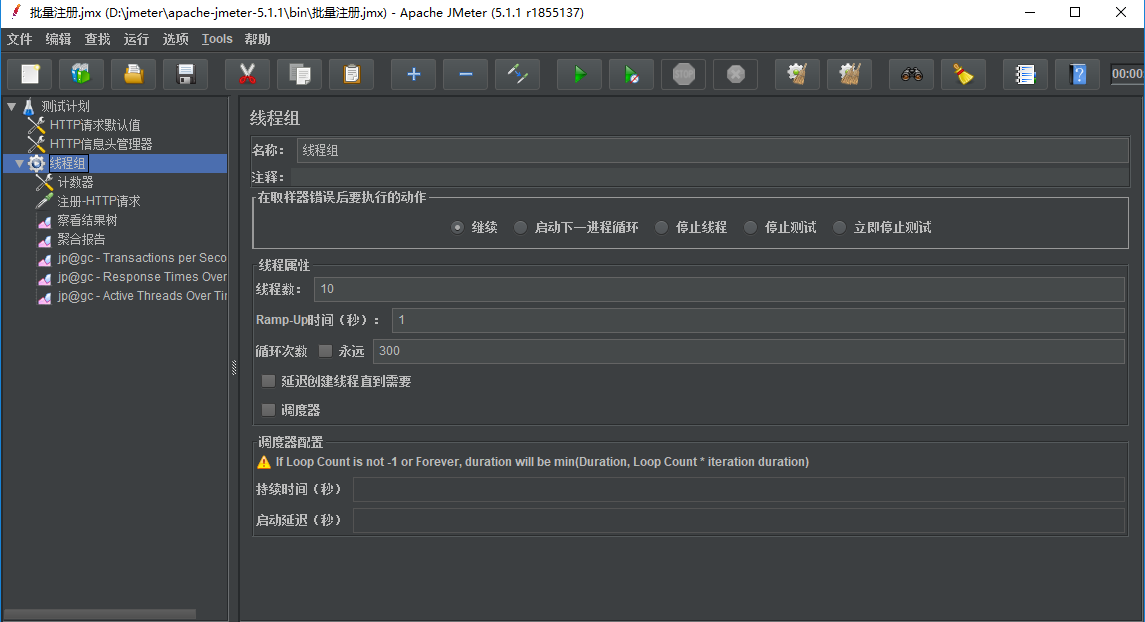
当Ramp-Up时间设置为2的时候,如何知道是不是2秒内,启动了10个线程呢?可以用监听器 jp@gc - Active Threads Over Time 来查看
监听器Active Threads Over Time
Active Threads Over Time 单位时间内活动的线程数 添加-监听器-jp@gc - Active Threads Over Time
设置线程数10, Ramp-Up时间设置为1秒
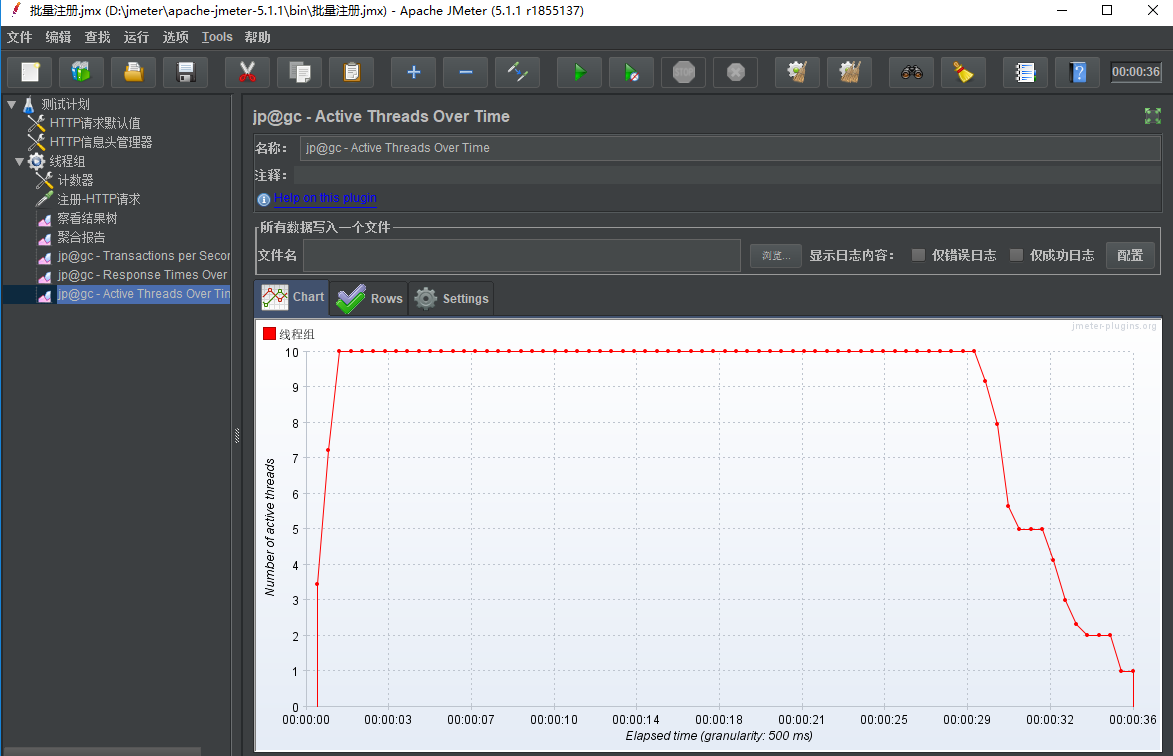
从上面结果看出在1秒内,线程全部启动完毕
设置线程数10, Ramp-Up时间设置为2秒
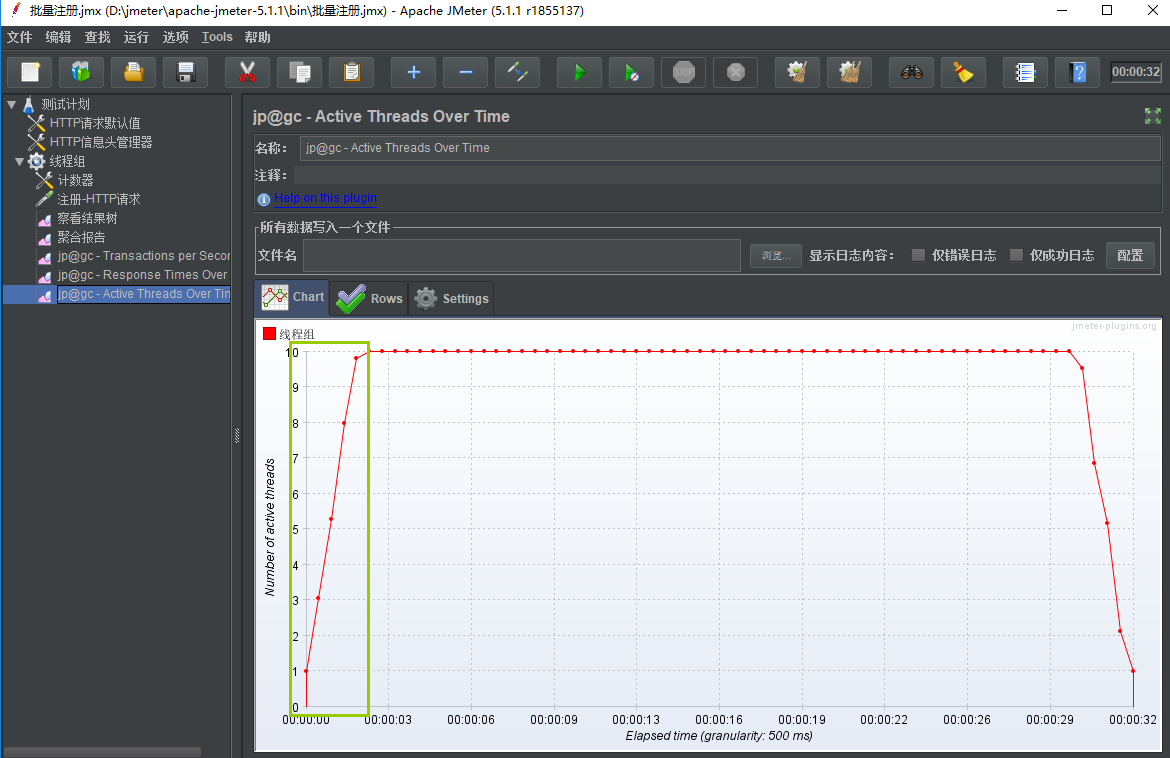
从上面结果看出在2秒内,线程全部启动完毕
性能测试之插件详解
@gc - Active Threads Over Timeip 活动线程时间
@gc - AutoStop Listener 自动停止侦听器
@gc - Bytes Throughput Over Timejp 字节吞吐量随时间变化
@gc -Composite Graph 综合图
@gc - Connect Times Over Timejp 连接时间
@gc -Console Status Loggerjp 控制台状态记录器
@gc - DbMon Samples Collectorjp (DbMon Collectorjp样品收集器
@gc -Flexible File Writer 监听器之灵活的文件写入
@gc - Graphs Generatorjip 图形发生器
@gc - Hits per Second 每秒点击次数
@gc -JMXMon Samples Collectorjp (JMXMon样品收集器
@gc - Page Data Extractor 页面数据提取器
@gc - PerfMon Metrics Collectorjip 性能指标收集器
@gc - Response Codes per Secondjip 每秒响应数
@gc - Response Latencies Over Timejip 随时间间隔变化的响应延迟
@gc - Response Times Distributionjip 响应时间分布图
@gc - Response Times Over Timeip 随时间变化的响应时间
@gc - Response Times Percentilesjip 响应时间百分位数
@gc - Response Times vs Threadsjp 响应时间vs线程
@gc - Synthesis Report (filtered) 综合报告(过滤)
@gc - Transaction Throughput vs Threadsjip 整个线程的事务
@gc - Transactions per Second 每秒事务数



软件性能指标
1、响应时间(RT)
响应时间是一个系统最重要的指标之一,它的数值大小直接反应了系统的快慢。响应时间是指执行一个请求从开始到最后收到响应数据所花费的总体时间。
响应时间=发起请求网络传输时间+服务器处理时间+返回响应网络传输时间
2、平均响应时间、百分位响应时间
平均响应时间指的是所有请求平均花费的时间,如果有100个请求,其中 98 个耗时为 1ms,其他两个为 100ms。那么平均响应时间为 (98 * 1 + 2 * 100) / 100.0 = 2.98ms 。
百分位数( Percentile - Wikipedia )是一个统计学名词。以响应时间为例, 99% 的百分位响应时间 ,指的是 99% 的请求响应时间,都处在这个值以下。
拿上面的响应时间来说,其整体平均响应时间虽然为 2.98ms,但 99% 的百分位响应时间却是 100ms。
相对于平均响应时间来说,百分位响应时间通常更能反映服务的整体效率。现实世界中用的较多的是 98% 的百分位响应时间,比如 GitHub System Status 中就有一条 98TH PERC. WEB RESPONSE TIME 曲线。
平均响应时间: 所有请求的平均响应时间,取的平均值
95%percentile : 统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。
例如有100个请求, 每个请求的响应时间分别是 1-100 平均分布
平均响应时间: 1-100 的平均值,即 50.5
95% percentile : 按从小到大排序,累计第95百分位,也就是 95 (即样本里95% 的数据都不高于这个值)
3、并发用户数 (最大并发数,最佳并发数)
并发
狭义:指同一时间点,执行相同请求的操作(秒杀) ======集合点
广义:同一时间点,向服务器发起的请求(更多用于真正的性能测试)
并发数
并发数是指系统同时能处理的请求数量,这个也是反应系统的负载能力
并发用户数
同一时间点,执行请求的用户数
系统用户数:所有注册用户
在线用户数:在线用户,可能发起请求,可能没有发起请求
并发用户数(Jmeter中的线程数):在线,发起请求用户
如,10个人发起了20个请求
最佳并发用户数:当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待
最大并发用户数:系统的负载一直持续,有些用户在处理而有的用户在自己最大的等待时间内等待的时候我们需要保证
1、最佳并发用户数需大于系统的平均负载
2、系统的最大并发用户数要大于系统需要承受的峰值负载
4,TPS和HPS的区别
TPS(Transaction per second) 是估算应用系统性能的重要依据。其意义是应用系统每秒钟处理完成的交易数量。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。 系统整体处理能力取决于处理能力最低模块的TPS 值。依据经验,应用系统的处理能力一般要求在10-100左右。不同应用系统的TPS有着十分大的差别,一般需要通过性能测试进行准确估算。
HPS(Hits per Second)是指在一秒钟的时间内用户对Web页面的链接、提交按钮等点击总和。 它一般和TPS成正比关系,是B/S系统中非常重要的性能指标之一。
throughput:分为网络吞吐量和事务吞吐量,当作为事务吞吐量时,采用TPS来衡量。
当作为网络吞吐量时(LR分析器中的throughput统计图是网络吞吐量),与HPS有一定的联系,但是不是必然的正比关系。
当然在发送的报文或请求的大小一定的情况下,HPS越高,Throughput也相应的越大。
一般情况下,发送报文或请求较大时的HPS会比发送报文或请求较小时的HPS小,但较大报文或请求的Throughput不一定比较小报文或请求的Throughput小
点击数HPS (每秒点击次数):是指发起请求时, 服务端对请求进行响应的页面资源对应的请求数量.
注意:
-
日常操作中, 对页面的点击动作不是这里说的点击数
-
该指标只在 Web 项目中需要注意
5、吞吐量 、吞吐率
吞吐量:单位时间内处理的请求数量(事务/s)(衡量网络)
吞吐量是指单位时间内系统能处理的请求数量,体现系统处理请求的能力,这是目前最常用的性能测试指标。
QPS(每秒查询数)、TPS(每秒事务数)是吞吐量的常用量化指标,另外还有HPS(每秒HTTP请求数)。注,网络没有瓶颈的时候,服务器每秒处理的事物数应该等于吞吐量数值
跟吞吐量有关的几个重要是:并发数、响应时间。
QPS(TPS),并发数、响应时间它们三者之间的关系是:
QPS(TPS)= 并发数/平均响应时间
吞吐率:单位时间内通过的数据的平均速率(kB/s)
如,请求数据多少k,这个数据在网络中需要传输的时间
6、事务
指一个客户机向服务器发送请求然后服务器做出反应的过程。
Jmeter中默认一个接口请求就是一个事务。
Jmeter中也支持多个接口整体作为一个事务。
7、TPS/QPS(每秒事务数) (重点)
TPS:服务器每秒处理的事物数(衡量服务器处理能力的综合体现+最主要指标)
TPS是单位时间内处理事务的数量,从代码角度来说,一段代码或多段代码可以组成一个事务.单位时间内完成的事务数越多,服务器的性能越好
QPS:每秒查询率(如登录,可能会查询是否用户已存在,是否已登录,密码是否正确等)
TPS和QPS的区别?
TPS(transaction per second)是单位时间内处理事务的数量,QPS(query per second)是单位时间内请求的数量。TPS代表一个事务的处理,可以包含了多次请求。很多公司用QPS作为接口吞吐量的指标,也有很多公司使用TPS作为标准,两者都能表现出系统的吞吐量的大小,TPS的一次事务代表一次用户操作到服务器返回结果,QPS的一次请求代表一个接口的一次请求到服务器返回结果。当一次用户操作只包含一个请求接口时,TPS和QPS没有区别。当用户的一次操作包含了多个服务请求时,这个时候TPS作为这次用户操作的性能指标就更具有代表性了。
个人理解如下:
1、Tps即每秒处理事务数,包括了
1)用户请求服务器
2)服务器自己的内部处理
3)服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是N;
2、Qps基本类似于Tps,但是不同的是,对于一个页面的一次访问,形成一个Tps;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“Qps”之中。
例如:访问一个页面会请求服务器3次,一次访问,产生一个“T”,产生3个“Q”
8、点击率、点击量
“吞吐率”图和“点击率”图的区别:
“吞吐率”图,是每秒服务器处理的HTTP申请数。
“点击率”图,是客户端每秒从服务器获得的总数据量。
点击数:是衡量Web服务器处理能力的一个重要指标。它的统计是客户端向Web服务器发了多少次HTTP请求计算的。通常我们也用每秒点击次数(Hits per Second)指标来衡量Web服务器的处理能力。
9、错误率
定义: 错误率指系统在负载情况下,失败交易的概率。
错误率 = (失败交易数/交易总数)*100%
注意:
-
大多系统都会要求无限接近于 100% 成功率, 因此, 错误率一般都非常低
-
相对稳定的系统产生的错误率又称超时率(由网络传输导致的)
10、资源的利用率(包含cpu、内存、磁盘I/O等):
定义: 系统资源(CPU/内存/磁盘/网络)使用占比(使用量/总量*100%)
利用率指标:(没有特殊要求情况下)
-
CPU 不超过 75%-85%
-
内存不超过 80%
-
硬盘不超过 90%(容量占有率/读写时间比)
CPU进行判断和处理,能反应系统的繁忙程度,一般分系统CPU与用户CPU
Load Average:指一段时间内,CPU正在处理和等待CPU处理的任务,即CPU使用队列的长度统计信息
Memory:数据从内存上读取要比从磁盘上读取的速度要快,而内存经常出现内存泄露或内存溢出的现象
队列:队列较长,说明处理能力达到了极限或者遇到阻塞
IO:与磁盘交互
网络:重点关注网络流量,看是否存在网络带宽瓶颈
注:一般要求资源利用率不超过80%
硬件性能:
cpu
内存
磁盘(disk I/O)
网络(NETWORK I/0)
1、CPU
定义:
CPU指标主要指的CPU利用率,包括用户态(user)、系统态(sys)、等待态(wait)、空闲态(idle)。
参考标准
CPU 利用率要低于业界警戒值范围之内,即小于或者等于75%;
CPU sys%小于或者等于30%;
CPU wait%小于或者等于5%;
2、内存
定义:
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大
参考标准
现在的操作系统为了最大利用内存,在内存中存放了缓存,因此内存利用率100%并不代表内存有瓶颈,衡量系统内存是否有瓶颈主要靠SWAP(与虚拟内存交换)交换空间利用率,一般情况下,SWAP交换空间利用率要低于70%,太多的交换将会引起系统性能低下。
3、磁盘
定义:
定义和解释:磁盘吞吐量简称为Disk Throughput,是指在无磁盘故障的情况下单位时间内通过磁盘的数据量。
参考标准
磁盘指标主要有每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待时间,空间利用率。其中磁盘繁忙率是直接反映磁盘是否有瓶颈的的重要依据,一般情况下,磁盘繁忙率要低于70%。
4、网络
定义:
网络吞吐量简称为Network Throughput,是指在无网络故障的情况下单位时间内通过的网络的数据数量。单位为Byte/s。网络吞吐量指标用于衡量系统对于网络设备或链路传输能力的需求。当网络吞吐量指标接近网络设备或链路最大传输能力时,则需要考虑升级网络设备。
参考标准
网络吞吐量指标主要有每秒有多少兆流量进出,一般情况下不能超过设备或链路最大传输能力的70%。
CPU对数据进行判断以及逻辑处理,本身不能存储数据;这时cpu从内存取数据进行逻辑计算,如果内存没有数据,才会从硬盘读数据到内存,再对数据进行处理
就像人吃饭一样,cpu就是人,内存就是碗,硬盘就是饭锅!
当cpu进程等待,会造成内存开销的增加,内存不够用的时候会用到虚拟内存,导致虚拟内存的增加,这时磁盘IO开销就会增加,系统态sy%提升,cpu开销增加;内存里数据不够用,才用磁盘中取数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号