

目录
- 前言
- 1.adagrad
- 2.动量(Momentum)
- 3.RMSProp
- 4.Adam
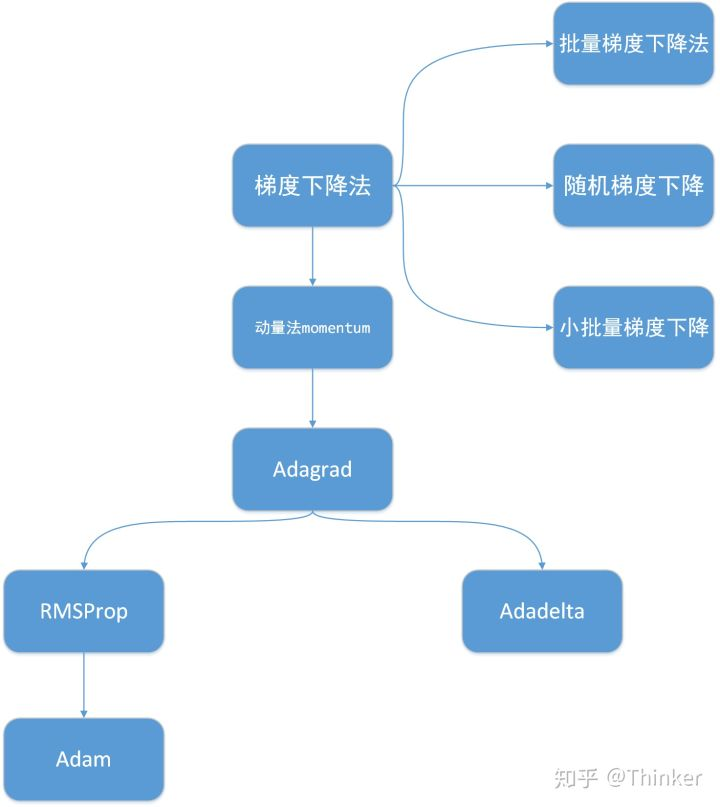
附1 基于梯度的优化算法前后关系
- 附二 Gradient Descent补充
前言:
https://www.zhihu.com/question/323747423/answer/790457991
Adam本质上实际是RMSProp+动量。但如果你对随机梯度下降SGD的知识,以及Adam之前的几个更新方法一无所知。那么当你看到一个“复杂的”Adam看了就头大(请不要嘲笑初学者,当年我也觉得深度学习各个地方都超复杂)。
现在假设你对反向传播的计算梯度的内容比较了解,一旦能使用反向传播计算解析梯度,梯度就能被用来进行参数更新了

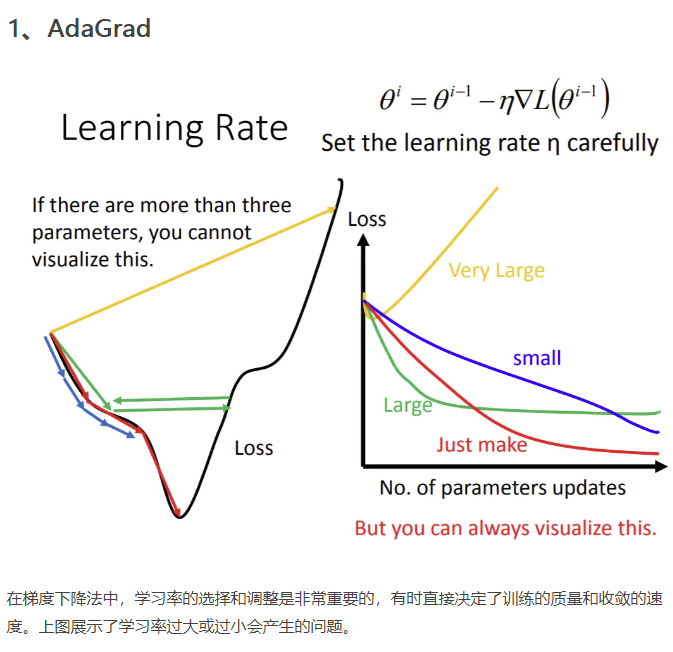
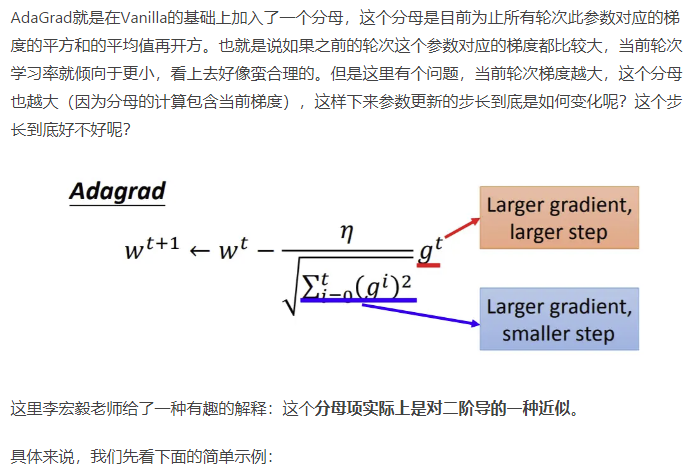
1.adagrad



2.动量(Momentum)
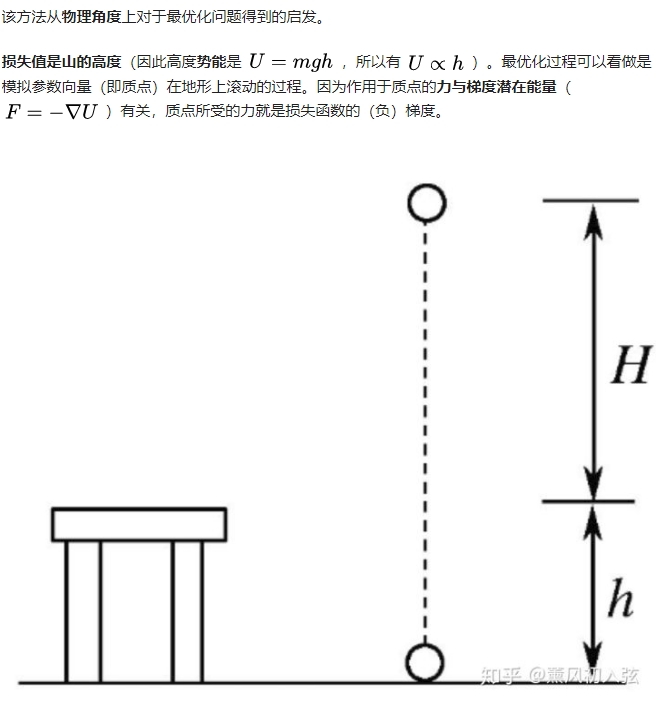

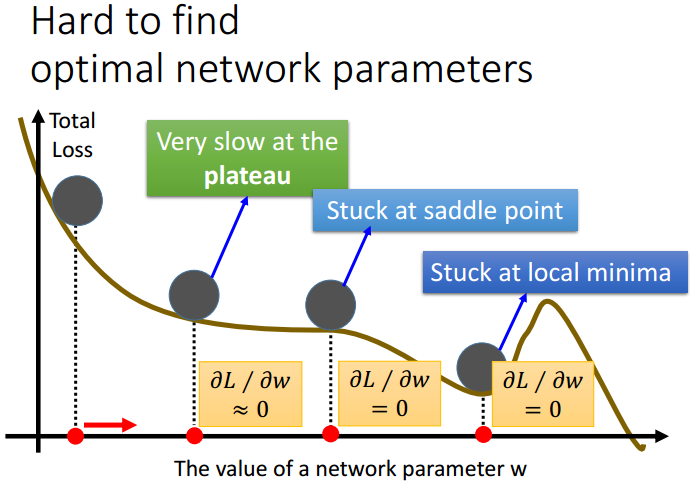
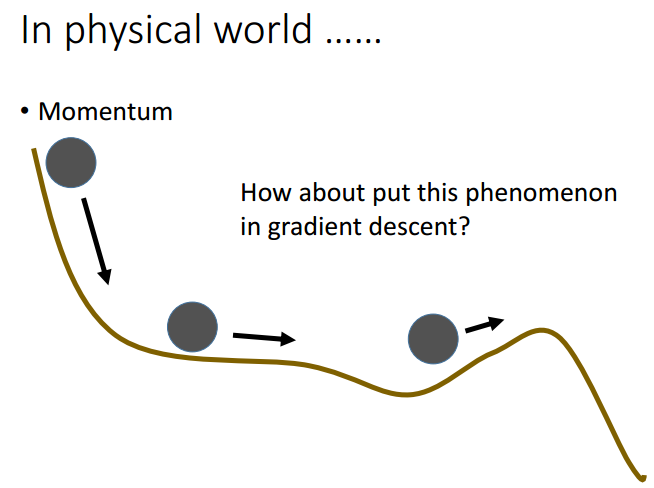
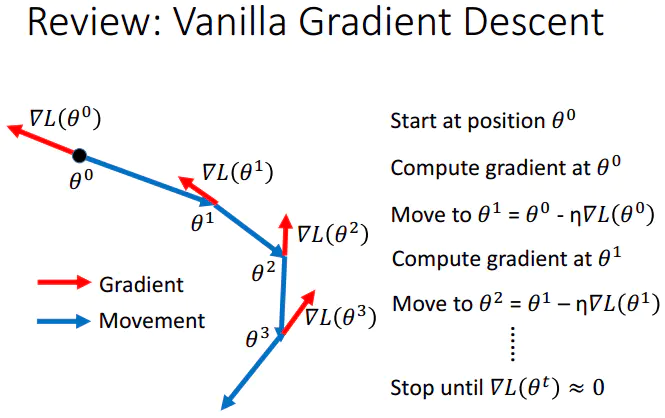

3.RMSProp


4.Adam


附1 基于梯度的优化算法前后关系
附二 Gradient Descent补充
https://www.jianshu.com/p/8b7105a2c242

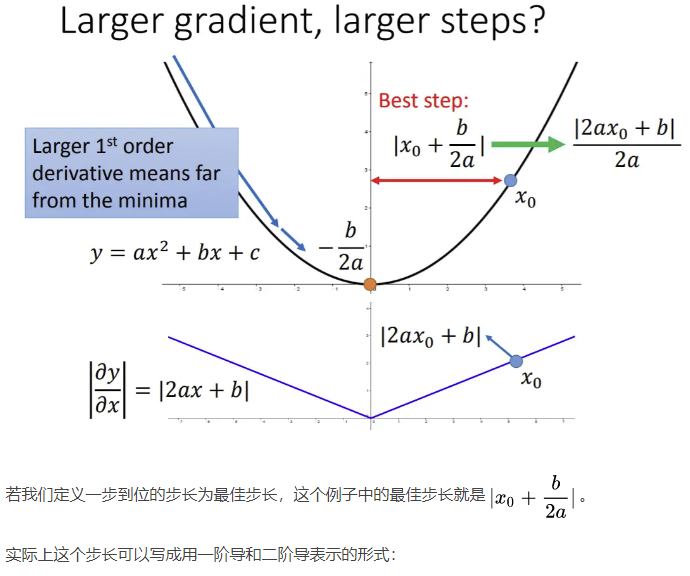
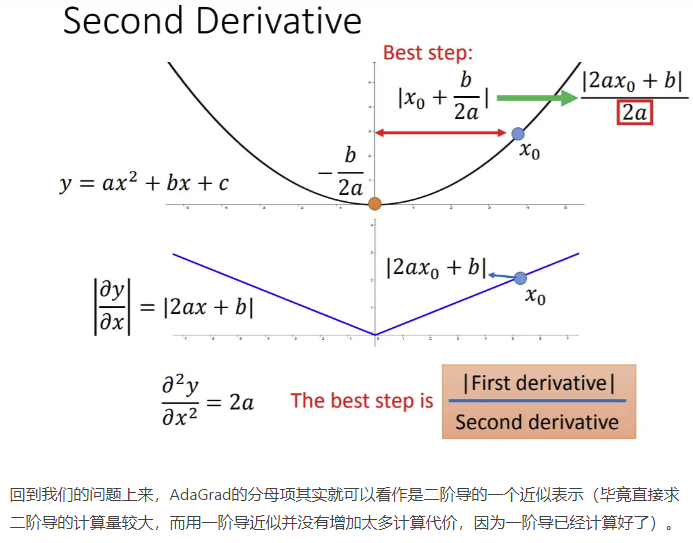
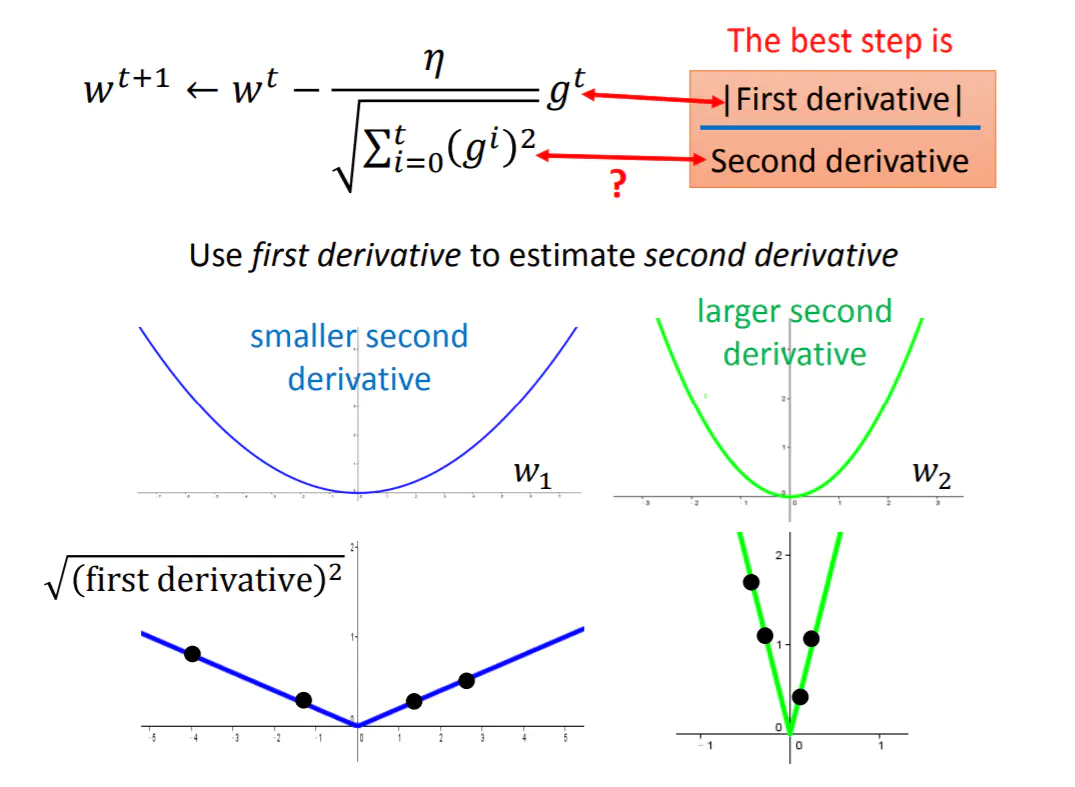

 浙公网安备 33010602011771号
浙公网安备 33010602011771号