

一 三大编程范式
正本清源一:有人说,函数式编程就是用函数编程--->傻逼
编程范式即编程的方法论,标识一种编程风格
大家学习了基本的python语法后,大家就可以写python代码了,然后每个人写代码的风格不同,这些不同的风格就代表了不同的流派
如果把python的基本语法比作武术的基本功,那么不同的编程风格就好比不同的武林门派。
虽然大家风格不同,但是都可以完成你的编程需求,python是一门面向对象编程语言,但是到目前为止,你从未接触面向对象编程,然而你已经可以解决很多问题了,在python中并没有人强制你使用哪一种固定的风格。
根本就没有什么门派是天下无敌的,不同的风格在不同的场景下都有各自的牛逼之处,
三大编程范式:
1.面向过程编程:捂裆派
2.函数式编程:峨美眉妹妹派
3.面向对象编程:少林蛋黄派
二 编程进化论
1.编程最开始就是无组织无结构,从简单控制流中按步写指令
2.从上述的指令中提取重复的代码块或逻辑,组织到一起(比方说,你定义了一个函数),便实现了代码重用,且代码由无结构走向了结构化,创建程序的过程变得更具逻辑性
3.我们定义函数都是独立于函数外定义变量,然后作为参数传递给函数,这意味着:数据与动作是分离的
4.如果我们把数据和动作内嵌到一个结构(函数或类)里面,那么我们就有了一个‘对象系统’(对象就是数据与函数整合到一起的产物)。
假设你是一条狗,我们用结构化的数据来描述你
1:数据与动作分离
2:数据与动作结合
导向:
1.面向对象设计
2.什么是类什么是对象
三 面向对象设计与面向对象编程
正本清源二:有人说,只有class定义类这才是面向对象,def定义函数就是函数相关的,跟面向对象没关系--->大傻逼
面向对象设计(Object oriented design):将一类具体事物的数据和动作整合到一起,即面向对象设计
面向对象设计(OOD)不会特别要求面向对象编程语言。事实上,OOD 可以由纯结构化语言来实现(比如 C)。但如果想要构造具备对象性质和特点的数据类型,就需要在程序上作更多的努力。
我们现在想用程序表述一台提款机,可以用面向过程,和面向对象两种方式设计(作为练习作业,你的智商,暂时看不懂,先看狗的例子吧)

#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
#为了方便大家理解,这里我们先用面向过程思想去实现
bank_database={
'12345':{'name':'alex','passwd':'123','money':100},
'12335':{'name':'linhaifeng','passwd':'123','money':100},
'22235':{'name':'wupeiqi','passwd':'123','money':100},
'14567':{'name':'yuanhao','passwd':'123','money':100},
}
current_user={'account_id':None,'status':None}
def auth_login(func):
def wrapper(account):
if not current_user['status']:
account_id=account['account_id']
if account_id not in bank_database:
print('账号不存在')
return
password=input('输入密码: ')
if password == bank_database[account_id]['passwd']:
current_user['account_id']=account_id
current_user['status']=True
res=func(account)
else:
res=func(account)
return res
return wrapper
@auth_login
def get_money(account):
account_id=account['account_id']
money=int(input('\033[0;45m穷逼,取多少:\033[0m '))
if money > bank_database[account_id]['money']:
print('\033[0;41m余额不足了,穷逼\033[0m')
return
bank_database[account_id]['money']-=money
print('\033[0;42m取款成功,余额为[%s]\033[0m' %bank_database[account_id]['money'])
@auth_login
def save_money(account):
account_id=account['account_id']
money=int(input('\033[0;43m穷逼,存多少:\033[0m '))
bank_database[account_id]['money']+=money
print('\033[0;43m存钱成功,余额为[%s]\033[0m' %bank_database[account_id]['money'])
@auth_login
def check_balance(account):
account_id=account['account_id']
print('\033[0;45m余额为[%s]\033[0m' %bank_database[account_id]['money'])
if __name__ == '__main__':
msg='''
1 取款
2 存款
3 查询
'''
msg_dic={
'1':get_money,
'2':save_money,
'3':check_balance,
}
account=input('请输入银行卡号: ')
acount_dic={'account_id':account}
while True:
print(msg)
choice=input('请输入操作>>: ').strip()
if not choice:continue
if choice == 'quit':break
msg_dic[choice](acount_dic)
__author__ = 'Linhaifeng'
#这里我们完全基于结构化的语言来实现面向对象设计
bank_database={
'12345':{'name':'alex','passwd':'123','money':100},
'12335':{'name':'linhaifeng','passwd':'123','money':100},
'22235':{'name':'wupeiqi','passwd':'123','money':100},
'14567':{'name':'yuanhao','passwd':'123','money':100},
}
def atm(account_id):
def init(account_id):
account={
'status':False,
'account_id':account_id,
'get_money':get_money,
'save_money':save_money,
'check_balance':check_balance,
}
return account
def auth_login(func):
def wrapper(account):
if not account['status']:
account_id=account['account_id']
if account_id not in bank_database:
print('账号不存在')
return
password=input('输入密码: ')
if password == bank_database[account_id]['passwd']:
account['status']=True
res=func(account)
else:
res=func(account)
return res
return wrapper
@auth_login
def get_money(account):
account_id=account['account_id']
money=int(input('\033[0;45m穷逼,取多少:\033[0m '))
if money > bank_database[account_id]['money']:
print('\033[0;41m余额不足了,穷逼\033[0m')
return
bank_database[account_id]['money']-=money
print('\033[0;42m取款成功,余额为[%s]\033[0m' %bank_database[account_id]['money'])
@auth_login
def save_money(account):
account_id=account['account_id']
money=int(input('\033[0;43m穷逼,存多少:\033[0m '))
bank_database[account_id]['money']+=money
print('\033[0;43m存钱成功,余额为[%s]\033[0m' %bank_database[account_id]['money'])
@auth_login
def check_balance(account):
account_id=account['account_id']
print('\033[0;45m余额为[%s]\033[0m' %bank_database[account_id]['money'])
return init(account_id)
if __name__ == '__main__':
account_id=input('银行号码: ')
alex=atm(account_id)
print(alex)
alex['get_money'](alex)
print(alex)
print('='*33)
alex['save_money'](alex)
print(alex)
print(bank_database)
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
dog1={
'name':'alex',
'gender':'female',
'type':'京巴'
}
dog2={
'name':'wupeiqi',
'gender':'female',
'type':'腊肠'
}
dog3={
'name':'yuanhao',
'gender':'female',
'type':'藏獒'
}
def bark(dog):
print('一条名字为[%s]的[%s],狂吠不止' %(dog['name'],dog['type']))
def yao_ren(dog):
print('[%s]正在咬人' %(dog['name']))
def chi_shi(dog):
print('[%s]正在吃屎' %(dog['type']))
bark(dog1)
yao_ren(dog2)
chi_shi(dog3)
#上面的例子就是基于面向对象设计的思想实现的
#我们用结构化的数据去实现了三个具体的对象,即dog1,dog2,dog3
#然后我们并没有实现数据与动作的融合
person={
'name':'犀利哥',
'gender':'male',
'type':'person',
}
bark(person) #狗的对象没有跟自己的方法绑定,导致人也能用狗的方法
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
def Dog(name,gender,type):
def init(name,gender,type):
dog={
'name':name,
'gender':gender,
'type':type,
'bark':bark,
'yao_ren':yao_ren,
'chi_shi':chi_shi,
}
return dog
def bark(dog):
print('一条名字为[%s]的[%s],狂吠不止' %(dog['name'],dog['type']))
def yao_ren(dog):
print('[%s]正在咬人' %(dog['name']))
def chi_shi(dog):
print('[%s]正在吃屎' %(dog['type']))
return init(name,gender,type)
dog1=Dog('alex','female','京巴')
dog2=Dog('wupeiqi','female','腊肠')
dog3=Dog('yuanhao','female','藏獒')
dog1['bark'](dog1)
dog2['yao_ren'](dog2)
dog3['chi_shi'](dog3)
面向对象编程(object-oriented programming):用定义类+实例/对象的方式去实现面向对象的设计
#用面向对象编程独有的语法class去实现面向对象设计
class Dog:
def __init__(self,name,gender,type):
self.name=name
self.gender=gender
self.type=type
def bark(self):
print('一条名字为[%s]的[%s],狂吠不止' %(self.name,self.type))
def yao_ren(self):
print('[%s]正在咬人' %(self.name))
def chi_shi(self):
print('[%s]正在吃屎' %(self.type))
dog1=Dog('alex','female','京巴')
dog2=Dog('wupeiqi','female','腊肠')
dog3=Dog('yuanhao','female','藏獒')
dog1.bark()
dog2.yao_ren()
dog3.chi_shi()
四 小结
一门面向对象的语言不一定会强制你写 OO 方面的程序。例如 C++可以被认为“更好 的 C”;而 Java,则要求万物皆类,此外还规定,一个源文件对应一个类定义。
然而,在 Python 中, 类和 OOP 都不是日常编程所必需的。尽管它从一开始设计就是面向对象的,并且结构上支持 OOP,但 Python 没有限定或要求你在你的应用中写 OO 的代码
用面向对象语言写程序,和一个程序的设计是面向对象的,两者是八杆子打不着的两码事。
纯C写的linux kernel事实上比c++/java之类语言搞出来的大多数项目更加面向对象——只是绝大部分人都自以为自己到处瞎写class的面条代码才是面向对象的正统、而死脑筋的linus搞的泛文件抽象不过是过程式思维搞出来的老古董。
五 类和对象
1.什么叫类:类是一种数据结构,就好比一个模型,该模型用来表述一类事物(事物即数据和动作的结合体),用它来生产真实的物体(实例)。
2.什么叫对象:睁开眼,你看到的一切的事物都是一个个的对象,你可以把对象理解为一个具体的事物(事物即数据和动作的结合体)
(铅笔是对象,人是对象,房子是对象,狗是对象,alex是对象,配齐是对象,元昊是对象)
3.类与对象的关系:对象都是由类产生的,上帝造人,上帝首先有一个造人的模板,这个模板即人的类,然后上帝根据类的定义来生产一个个的人
4.什么叫实例化:由类生产对象的过程叫实例化,类实例化的结果就是一个对象,或者叫做一个实例(实例=对象)
5.1 类相关知识
5.1.1 初识类
在python中声明函数与声明类很相似
声明函数
1 def functionName(args):
2 '函数文档字符串'
3 函数体
声明类
1 '''
2 class 类名:
3 '类的文档字符串'
4 类体
5 '''
6
7 #我们创建一个类
8 class Data:
9 pass
10
11 #用类Data实例化出一个对象d1
12 d1=Data()
经典类与新式类
1 大前提:
2 1.只有在python2中才分新式类和经典类,python3中统一都是新式类
3 2.新式类和经典类声明的最大不同在于,所有新式类必须继承至少一个父类
4 3.所有类甭管是否显式声明父类,都有一个默认继承object父类(讲继承时会讲,先记住)
5 在python2中的区分
6 经典类:
7 class 类名:
8 pass
9
10 经典类:
11 class 类名(父类):
12 pass
13
14 在python3中,上述两种定义方式全都是新式类
5.1.2 属性
类是用来描述一类事物,类的对象指的是这一类事物中的一个个体
是事物就要有属性,属性分为
1:数据属性:就是变量
2:函数属性:就是函数,在面向对象里通常称为方法
注意:类和对象均用点来访问自己的属性
5.1.3 类的属性
峰式理论:数据属性即变量,类的定义与函数又极其类似,其实可以用函数的作用域来理解类的属性调用
类的数据属性
1 #定义一个中文人的类,然后在类中定义一个类的属性,政府是***,这样,只要是中文人他们的党永远都是***
2 #类属性又称为静态变量,或者是静态数据。这些数据是与它们所属的类对象绑定的,不依赖于任何类实例。
3 #如果你是一位Java或C++程序员,这种类型的数据相当于在一个变量声明前加上static关键字。
4
5 class ChinesePeople:
6 government='***'
7
8 print(ChinesePeople.government)
类的函数属性(又称为方法)
1 class ChinesePeople:
2 government='***'
3 def sui_di_tu_tan():
4 print('90%的中国人都喜欢随地吐痰')
5
6 def cha_dui(self):
7 print('一个中国人-->%s<--插到了前面' %self)
8
9 ChinesePeople.sui_di_tu_tan()
10
11 person1_obj='alex'
12 ChinesePeople.cha_dui(person1_obj) #带参函数,所以调用时需要传入参数,将'alex'传给self
查看类属性
我们定义的类的属性到底存到哪里了?有两种方式查看 dir(类名):查出的是一个名字列表
类名.__dict__:查出的是一个字典,key为属性名,value为属性值
1 class ChinesePeople:
2 government='***'
3 def sui_di_tu_tan():
4 print('90%的中国人都喜欢随地吐痰')
5
6 def cha_dui(self):
7 print('一个中国人-->%s<--插到了前面' %self)
8
9
10 print(dir(ChinesePeople)) #显示结果是一个列表,包含类(包含内建属性在内的)所有的属性名
11 print(ChinesePeople.__dict__) #显示结果是一个字典,包含类的所有属性:属性值
特殊的类属性
1 class ChinesePeople:
2 '我们都是中国人,我们骄傲的活着,我们不服任何事和物'
3 government='***'
4 def sui_di_tu_tan():
5 print('90%的中国人都喜欢随地吐痰')
6
7 def cha_dui(self):
8 print('一个中国人-->%s<--插到了前面' %self)
9
10 print(ChinesePeople.__name__)# 类C的名字(字符串)
11 print(ChinesePeople.__doc__)# 类C的文档字符串
12 print(ChinesePeople.__base__)# 类C的第一个父类(在讲继承时会讲)
13 print(ChinesePeople.__bases__)# 类C的所有父类构成的元组(在讲继承时会讲)
14 print(ChinesePeople.__dict__)# 类C的属性
15 print(ChinesePeople.__module__)# 类C定义所在的模块
16 print(ChinesePeople.__class__)# 实例C对应的类(仅新式类中)
5.2 对象相关知识
对象是由类实例化而来,类实例化的结果称为一个实例或者称作一个对象
5.2.1 实例化
1 class ChinesePeople:
2 '我们都是中国人,我们骄傲的活着,我们不服任何事和物'
3 government='***'
4 def sui_di_tu_tan():
5 print('90%的中国人都喜欢随地吐痰')
6
7 def cha_dui(self):
8 print('一个中国人-->%s<--插到了前面' %self)
9
10 person1=ChinesePeople() #类名加上括号就是实例化(可以理解为函数的运行,返回值就是一个实例)
11
12 #这就是实例化,只不过你得到的person1实例,没有做任何事情
5.2.2 构造函数
上述的实例化过程,没有做任何事情,啥意思?
类是数据属性和函数属性的结合,描述的是一类事物
这类事物的一个具体表现就是一个实例/对象,比方说中国人是一个类,而你就是这个类的一个实例
你除了有中国人这个数据属性外,还应该有名字,年龄,性别等数据属性
如何为实例定制数据属性,可以使用类的一个内置方法__init__()该方法,在类()实例化是会自动执行
class ChinesePeople:
'我们都是中国人,我们骄傲的活着,我们不服任何事和物'
government='***'
def __init__(self,name,age,gender): #实例化的过程可以简单理解为执行该函数的过程,实例本身会当作参数传递给self(这是默认的步骤)
self.name=name
self.age=age
self.gender=gender
def sui_di_tu_tan():
print('90%的中国人都喜欢随地吐痰')
def cha_dui(self):
print('一个中国人-->%s<--插到了前面' %self)
# person1=ChinesePeople() #会报错
#自动执行__init__方法,而这个方法需要参数,
# 这些参数应该写在类名后面的括号里,然后由类传
#给__init__函数,也就说,传给类的参数就是传给__init__的参数
person1=ChinesePeople('alex',1000,'female')
person2=ChinesePeople('wupeiqi',10000,'female')
person3=ChinesePeople('yuanhao',9000,'female')
print(person1.__dict__)
注意:在说实例化的时候说过,执行类()会自动返回一值,这个值就是实例,而类()会自动执行__init__,所以一定不要在该函数内定义返回值,会冲突(不怕死可以自己测试)
5.2.3 实例属性
峰式理论:
1.实例只有数据属性(实例的函数属性严格来说是类的函数属性)
2.del 实例/对象,只是回收了实例的数据属性,函数属性是属于类的,是不会回收。
正本清源三:有人说,类有数据属性和函数属性,实例/对象是由类产生的,所以实例也有数据属性和函数属性了--->大大傻逼
实例化的过程实际就是执行__init__的过程,这个函数内部只是为实例本身即self设定了一堆数据(变量),所以实例只有数据属性
1 class ChinesePeople:
2 '我们都是中国人,我们骄傲的活着,我们不服任何事和物'
3 government='***'
4 def __init__(self,name,age,gender):
5 self.name=name
6 self.age=age
7 self.gender=gender
8
9 def sui_di_tu_tan():
10 print('90%的中国人都喜欢随地吐痰')
11
12 def cha_dui(self):
13 print('一个中国人-->%s<--插到了前面' %self)
14
15
16 person1=ChinesePeople('alex',1000,'female')
17 print(person1.__dict__) #查看实例的属性,发现里面确实只有数据属性
18 print(person1.name,person1.age,person1.gender) #访问实例的数据属性
那么我们想访问实例的函数属性(其实是类的函数属性),如何实现
1 class ChinesePeople:
2 '我们都是中国人,我们骄傲的活着,我们不服任何事和物'
3 government='***'
4 def __init__(self,name,age,gender):
5 self.name=name
6 self.age=age
7 self.gender=gender
8
9 def sui_di_tu_tan():
10 print('90%的中国人都喜欢随地吐痰')
11
12 def cha_dui(self):
13 print('一个中国人-->%s<--插到了前面' %self)
14
15
16 person1=ChinesePeople('alex',1000,'female')
17 print(person1.__dict__) #查看实例的属性,发现里面确实只有数据属性
18 print(ChinesePeople.__dict__)#函数属性只存在于类中
19 ChinesePeople.cha_dui(person1)#我们只能通过类去调用类的函数属性,然后把实例当做变量传递给self
一个小小的改进,就大不一样了
1 class ChinesePeople:
2 '我们都是中国人,我们骄傲的活着,我们不服任何事和物'
3 government='***'
4 def __init__(self,name,age,gender):
5 self.name=name
6 self.age=age
7 self.gender=gender
8
9 def sui_di_tu_tan():
10 print('90%的中国人都喜欢随地吐痰')
11
12 # def cha_dui(self):
13 # print('一个中国人-->%s<--插到了前面' %self)
14
15 def cha_dui(self):
16 print('一个中国人-->姓名:%s 年龄:%s 性别:%s<--插到了前面' %(self.name,self.age,self.gender))
17
18 def eat_food(self,food):
19 print('%s 正在吃 %s' %(self.name,food))
20
21 person1=ChinesePeople('alex',1000,'female')
22 print(person1.__dict__) #查看实例的属性,发现里面确实只有数据属性
23 print(ChinesePeople.__dict__)#函数属性只存在于类中
24 ChinesePeople.cha_dui(person1)#我们只能通过类去调用类的函数属性,然后把实例当做变量传递给self
25 ChinesePeople.eat_food(person1,'韭菜馅饼')
26
27
28 person1.cha_dui()#其实就是ChinesePeople.cha_dui(person1)
29 person1.eat_food('飞禽走兽') #本质就是ChinesePeople.eat_food(person1,'飞禽走兽')
5.2.4 查看实例属性
同样是dir和内置__dict__两种方式
5.2.5 特殊实例属性
__class__
__dict__
class ChinesePeople:
'我们都是中国人,我们骄傲的活着,我们不服任何事和物'
government='***'
def __init__(self,name,age,gender):
self.name=name
self.age=age
self.gender=gender
def sui_di_tu_tan():
print('90%的中国人都喜欢随地吐痰')
# def cha_dui(self):
# print('一个中国人-->%s<--插到了前面' %self)
def cha_dui(self):
print('一个中国人-->姓名:%s 年龄:%s 性别:%s<--插到了前面' %(self.name,self.age,self.gender))
def eat_food(self,food):
print('%s 正在吃 %s' %(self.name,food))
person1=ChinesePeople('alex',1000,'female')
print(person1.__class__)
print(ChinesePeople)
person2=person1.__class__('xiaobai',900,'male')
print(person2.name,person2.age,person2.gender)
警告:类和对象虽然调用__dict__返回的是一个字典结构,但是千万不要直接修改该字典,会导致你的oop不稳定
5.3 类属性与对象(实例)属性
正本清源四:有人说,实例是类产生的,所以实例肯定能访问到类属性,然后就没有说为什么--->大大大傻逼
#类属性又称为静态变量,或者是静态数据。这些数据是与它们所属的类对象绑定的,不依赖于任何类实例。
#如果你是一位Java或C++程序员,这种类型的数据相当于在一个变量声明前加上static关键字。
class ChinesePeople:
country='China'
def __init__(self,name):
self.name=name
def play_ball(self,ball):
print('%s 正在打 %s' %(self.name))
def say_word(self,word):
print('%s 说 %s' %(self.name,word))
#查看类属性
print(ChinesePeople.country)
#修改类属性
ChinesePeople.country='CHINA'
print(ChinesePeople.country)
#删除类属性
del ChinesePeople.country
#增加类属性
ChinesePeople.Country='China'
ChinesePeople.location='Asia'
print(ChinesePeople.__dict__)
#类的数据属性增删改查与函数属性是一样的
ChinesePeople.say_word=say_word
print(ChinesePeople.__dict__)
alex_obj=ChinesePeople('alex')
ChinesePeople.say_word(alex_obj,'我是一只来自北方的狼狗')
class ChinesePeople:
country='China'
def __init__(self,name):
self.name=name
def play_ball(self,ball):
print('%s 正在打 %s' %(self.name,ball))
p1=ChinesePeople('alex')
print(p1.__dict__)
#查看实例属性
print(p1.name)
# print(p1.age)#不存在于p1的属性字典中,会报错
print(p1.country)#country也不存在于p1的属性字典中,为何可以取到呢?
#删除
# del p1.country #报错,因为p1的属性字典里根本就没有country属性
del p1.name
print(p1.__dict__)
#增加
p1.gender='man'
print(p1.__dict__)
#修改
p1.gender='woman'
print(p1.__dict__)
1.其实你会发现,实例化就是 类名(),然后返回的结果是一个对象,加上括号是不是跟函数运行很像,函数运行完了有返回值,是不是很像,没错,就是一样的。
2.函数又作用域的概念,其实类也有作用域的概念,二者一样
3.你可以把class当做最外层的函数,是一个作用域
1 #定义一个类,只当一个作用域去用,类似于c语言中的结构体
2 class MyData:
3 pass
4
5 x=10
6 y=20
7 MyData.x=1
8 MyData.y=2
9
10 print(x,y)
11 print(MyData.x,MyData.y)
12 print(MyData.x+MyData.y)
4.实例化会自动触发init函数的运行,最后返回一个值即实例,我们要找的实例属性就存放在init函数的局部作用域里
5.类有类的属性字典,就是类的作用域,实例有实例的属性字典,即实例的作用域
6.综上,一个点代表一层作用域,obj.x先从自己的作用域找,自己找不到去外层的类的字典中找,都找不到,就会报错
7.在类中没有使用点的调用,代表调用全局变量啊,这还tm用说,对,你就是不知道
age=1000
class ChinesePeople:
country='China'
age=10
def __init__(self,name):
self.name=name
print('初始化函数中调用age',age) #不加点调用就跟类没关系了,找的就是全局的
print('初始化函数中调用self.age',self.age)
def play_ball(self,ball):
print('%s 正在打 %s' %(self.name,ball))
def say_word(self,word):
print('%s 说 %s' %(self.name,word))
p1=ChinesePeople('alex')
print(p1.age)
#这属于在自己的作用域定义了一个age,类的age并不会变
p1.age=100000000
print(p1.age)
print(ChinesePeople.age)
#不是说实例无函数属性吗,他都是调用的类的,那么我们就为实例添加一个函数属性好了
p1.haha=say_word
print(p1.__dict__)
p1.haha(p1,'英语')#我擦嘞,怎么会这么玩
age=10000000000
class ChinesePeople:
country='China'
age=10
def __init__(self,name):
self.name=name
def play_ball(self,ball):
print('%s 正在打 %s' %(self.name,ball))
p1=ChinesePeople('alex')
p2=ChinesePeople('wupeiqi')
p3=ChinesePeople('yuanhao')
p1.age=1000
p2.age=10000
p3.age=9000
print(p1.age,p2.age,p3.age)
print('全局变量',age)
print('类数据属性',ChinesePeople.age)
#开始玩你了
age=10000000000
class ChinesePeople:
country='China'
age=10
l=[]
def __init__(self,name):
self.name=name
def play_ball(self,ball):
print('%s 正在打 %s' %(self.name,ball))
p1=ChinesePeople('alex')
p2=ChinesePeople('wupeiqi')
p3=ChinesePeople('yuanhao')
p1.l.append('p1')
p2.l.append('p2')
p3.l.append('p3')
print(ChinesePeople.l)
print(p1.l,p2.l,p3.l)
峰式理论 :类的作用域即函数作用域
六 静态属性、类方法、静态方法
class Room:
def __init__(self,name,owner,width,length):
self.name=name
self.owner=owner
self.width=width
self.length=length
@property
def cal_area(self):
return self.width * self.length
r1=Room('厕所','alex',1000,100)
print(r1.cal_area)
r1.cal_area=10 #无法设置,会报错
'''
staticmethod静态方法只是名义上的归属类管理,不能使用类变量和实例变量,是类的工具包
'''
class Room:
def __init__(self,name,owner,width,length):
self.name=name
self.owner=owner
self.width=width
self.length=length
@property
def cal_area(self):
return self.width * self.length
@staticmethod
def wash_body():
print('洗刷刷,洗刷刷')
def test():
print('这可不是静态方法,用类调用没问题,你用一个实例调用看看')
Room.wash_body()
r1=Room('厕所','alex',10,10)
r1.wash_body()
#------
Room.test()
r1.test() #会报错,因为如果test不是静态方法,那么r1会吧自己传给test的第一个参数self,test无参所以报错
'''
classmethod类方法只是给类使用(不管是否存在实例),只能访问实例变量
'''
class Room:
style='欧式豪宅'
def __init__(self,name,owner,width,length):
self.name=name
self.owner=owner
self.width=width
self.length=length
@property
def cal_area(self):
return self.width * self.length
@staticmethod
def wash_body():
print('洗刷刷,洗刷刷')
def test():
print('这可不是静态方法,用类调用没问题,你用一个实例调用看看')
@classmethod
def tell_style(cls):
# print('%s的房间风格是%s' %(self.name,cls.style)) #不能访问实例
print('房间风格是[%s]' %(cls.style)) #不能访问实例
Room.tell_style() #类方法的定义应该只是为了类去调用
r1=Room('卧室','alex',10,10)
r1.tell_style() #但其实你非要让实例去调用,也是可以的,不过却违反了我们的初衷:类方法就是专门为类使用
七 组合
定义一个人的类,人有头,驱赶,手,脚等数据属性,这几个属性又可以是通过一个类实例化的对象,这就是组合
用途:
1:做关联
2:小的组成大的
class School:
def __init__(self,name,addr):
self.name=name
self.addr=addr
def tell_info(self):
print('School(%s,%s)' %(self.name,self.addr))
class Course:
def __init__(self,name,price,period):
self.name=name
self.price=price
self.period=period
self.school=School('oldboy','沙河')
c1=Course('python',15000,'5month')
print(c1.name)
c1.school.tell_info()
八 面向对象编程三大特性
8.1 继承
一 什么是类的继承?
类的继承跟现实生活中的父、子、孙子、重孙子、继承关系一样,父类又称为基类。
python中类的继承分为:单继承和多继承
1 class ParentClass1:
2 pass
3
4 class ParentClass2:
5 pass
6
7 class SubClass(ParentClass1): #单继承
8 pass
9
10 class SubClass(ParentClass1,ParentClass2): #多继承
11 pass
二 子继承到底继承了父类的什么属性?
正本清源五:有人说,子类继承了父类的所有属性,子类自定义的属性如果跟父类重名了,那就覆盖了父类的--->大大大傻逼
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class Dad:
'我是爸爸类啊'
money=10000
def __init__(self,name):
print('爸爸类的初始化方法-->')
self.name=name
def hit_son(self):
print('调用者是%s 我是爸爸吧的方法啊' %self.name)
class Son(Dad):
'我是儿子类吭'
pass
s1=Son('小白龙')
print('继承的爸爸的遗产',s1.money)
s1.hit_son() #继承了爸爸打儿子的方法
#上述表现貌似证明了儿子类,继承了父类所有的属性(类的数据属性和函数属性)
print(Dad.__dict__)
print(Son.__dict__)
#打印的结果发现,儿子类的属性字典中没有任何关于父类的属性
#注意了
#注意了
#注意了
#注意了
#注意了
#注意了
#继承的本质是父类把自己类的属性引用传递给了儿子,儿子类可以调用父类的属性,但其实它们是不属于儿子的
#因此,在子类中定义的任何数据属性和函数属性都存在于儿子类的属性字典中,调用时优先从自己的属性字典里面查
class Dad:
'我是爸爸类啊'
money=10000
def __init__(self,name):
print('爸爸类的初始化方法-->')
self.name=name
def hit_son(self):
print('调用者是%s 我是爸爸吧的方法啊' %self.name)
class Son(Dad):
'我是儿子类吭'
def __init__(self,name,age):
self.name=name
self.age=age
def hit_son(self):
print('我们做儿子的,哪能忍心下手再打儿子')
s1=Son('小白龙',18)
print(s1.name,s1.age)
s1.hit_son()
print(Dad.__dict__)
print(Son.__dict__)
做儿子的哪能打儿子
三 什么时候用继承?
1.当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
例如:描述一个机器人类,机器人这个大类是由很多互不相关的小类组成,如机械胳膊类、腿类、身体类、电池类
2.当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好
例如
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别为猫和狗创建一个类,那么就需要为 猫 和 狗 实现他们所有的功能,如下所示:
class 猫:
def 喵喵叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
class 狗:
def 汪汪叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
上述代码不难看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现:
动物:吃、喝、拉、撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
class 动物:
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 猫(动物):
def 喵喵叫(self):
print '喵喵叫'
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 狗(动物):
def 汪汪叫(self):
print '喵喵叫'
伪代码
class Animal:
def eat(self):
print("%s 吃 " %self.name)
def drink(self):
print ("%s 喝 " %self.name)
def shit(self):
print ("%s 拉 " %self.name)
def pee(self):
print ("%s 撒 " %self.name)
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '猫'
def cry(self):
print('喵喵叫')
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed='狗'
def cry(self):
print('汪汪叫')
# ######### 执行 #########
c1 = Cat('小白家的小黑猫')
c1.eat()
c2 = Cat('小黑的小白猫')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()
四 继承同时具有两种含义
含义一.继承基类的方法,并且做出自己的改变或者扩展(代码重用)
含义二.声明某个子类兼容于某基类,定义一个接口类,子类继承接口类,并且实现接口中定义的方法
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
#一切皆文件
import abc
class All_file(metaclass=abc.ABCMeta):
@abc.abstractmethod
def read(self):
'子类必须实现读功能'
pass
@abc.abstractmethod
def write(self):
'子类必须实现写功能'
pass
# class Txt(All_file):
# pass
#
# t1=Txt() #报错,子类必须实现父类的方法
class Txt(All_file):
def read(self):
print('文本数据的读取方法')
def write(self):
print('文本数据的读取方法')
class Sata(All_file):
def read(self):
print('硬盘数据的读取方法')
def write(self):
print('硬盘数据的读取方法')
class Process(All_file):
def read(self):
print('进程数据的读取方法')
def write(self):
print('进程数据的读取方法')
wenbenwenjian=Txt()
yingpanwenjian=Sata()
jinchengwenjian=Process()
#这样大家都是被归一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read()
实践中,继承的第一种含义意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
继承的第二种含义非常重要。它又叫“接口继承”。 接口继承实质上是要求“做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象”——这在程序设计上,叫做归一化。
归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合——就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备”和“块设备”,然后做出针对性的设计:细致到什么程度,视需求而定)。
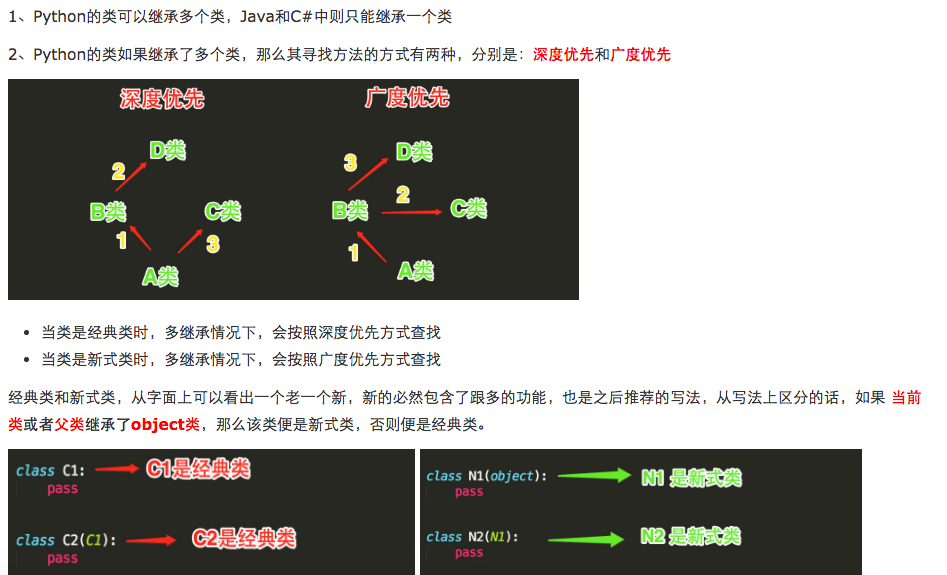
五 继承顺序
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class A:
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D,E):
# def test(self):
# print('from F')
pass
f1=F()
f1.test()
print(F.__mro__) #python2中没有这个属性
#新式类继承顺序:F->D->B->E->C->A
#经典类继承顺序:F->D->B->A->E->C
#python3中统一都是新式类
#pyhon2中才分新式类与经典类
终极解密:python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则: 1.子类会先于父类被检查 2.多个父类会根据它们在列表中的顺序被检查 3.如果对下一个类存在两个合法的选择,选择第一个父类
六 子类中调用父类方法
子类继承了父类的方法,然后想进行修改,注意了是基于原有的基础上修改,那么就需要在子类中调用父类的方法
方法一:父类名.父类方法()
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class Vehicle: #定义交通工具类
Country='China'
def __init__(self,name,speed,load,power):
self.name=name
self.speed=speed
self.load=load
self.power=power
def run(self):
print('开动啦...')
class Subway(Vehicle): #地铁
def __init__(self,name,speed,load,power,line):
Vehicle.__init__(self,name,speed,load,power)
self.line=line
def run(self):
print('地铁%s号线欢迎您' %self.line)
Vehicle.run(self)
line13=Subway('中国地铁','180m/s','1000人/箱','电',13)
line13.run()
方法二:super()
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class Vehicle: #定义交通工具类
Country='China'
def __init__(self,name,speed,load,power):
self.name=name
self.speed=speed
self.load=load
self.power=power
def run(self):
print('开动啦...')
class Subway(Vehicle): #地铁
def __init__(self,name,speed,load,power,line):
#super(Subway,self) 就相当于实例本身
super(Subway,self).__init__(name,speed,load,power)
self.line=line
def run(self):
print('地铁%s号线欢迎您' %self.line)
super(Subway,self).run()
class Mobike(Vehicle):#摩拜单车
pass
line13=Subway('中国地铁','180m/s','1000人/箱','电',13)
line13.run()
不用super引发的惨案
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
#每个类中都继承了且重写了父类的方法
class A:
def __init__(self):
print('A的构造方法')
class B(A):
def __init__(self):
print('B的构造方法')
A.__init__(self)
class C(A):
def __init__(self):
print('C的构造方法')
A.__init__(self)
class D(B,C):
def __init__(self):
print('D的构造方法')
B.__init__(self)
C.__init__(self)
pass
f1=D()
print(D.__mro__) #python2中没有这个属性
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
#每个类中都继承了且重写了父类的方法
class A:
def __init__(self):
print('A的构造方法')
class B(A):
def __init__(self):
print('B的构造方法')
super(B,self).__init__()
class C(A):
def __init__(self):
print('C的构造方法')
super(C,self).__init__()
class D(B,C):
def __init__(self):
print('D的构造方法')
super(D,self).__init__()
f1=D()
print(D.__mro__) #python2中没有这个属性
8.2 多态
什么是多态:
类的继承有两层意义:1.改变 2.扩展
多态就是类的这两层意义的一个具体的实现机制 即,调用不同的类实例化得对象下的相同的方法,实现的过程不一样
python中的标准类型就是多态概念的一个很好的示范如(str.__len__(),list.__len__(),tuple.__len__可以len(str),len(list),len(tuple))
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class H2O:
def __init__(self,name,temperature):
self.name=name
self.temperature=temperature
def turn_ice(self):
if self.temperature < 0:
print('[%s]温度太低结冰了' %self.name)
elif self.temperature > 0 and self.temperature < 100:
print('[%s]液化成水' %self.name)
elif self.temperature > 100:
print('[%s]温度太高变成了水蒸气' %self.name)
class Water(H2O):
pass
class Ice(H2O):
pass
class Steam(H2O):
pass
w1=Water('水',25)
i1=Ice('冰',-20)
s1=Steam('蒸汽',3000)
def func(obj):
obj.turn_ice()
func(w1)
func(i1)
func(s1)
w2=Water('水',101)
func(w2)
正本清源六:有人说,面向对象三大特性,封装,多态,继承--->小傻逼
可能是由于国人的命名习惯,总喜欢说三大特性,一个观点,三个_代表,八项纪律,九九归一,硬要把面向对象分成三大特性,小白们学的一知半解,然后去工作中用,注意了,用跟懂还是两个层次(有些人终其一生也无法走到技术的金字塔顶,就是因为只会用,不懂为什么),关键是大多数人用了以后,反过来拿着结果去验证自己的错误理解,结果就是建立了一套牢不可破的错误体系。
有一天一位朋友兴致勃勃的跑过来跟我说:你猜怎么着,蜘蛛是聋的,它所有的感知都在腿上。
我满脸疑惑,朋友接着说:你看哈,我把蜘蛛的腿都切掉,然后朝着它大声的啊啊啊啊啊啊啊啊啊啊啊啊,蜘蛛纹丝不动,没有跑
我。。。。。。
这确实就是身边很多搞技术的人喜欢的逻辑,你的出发点就是错的,你的理论体系看起来好像是完美的。
多态实际上是依附于继承的两种含义的:“改变”和“扩展”本身就意味着必须有机制去自动选用你改变/扩展过的版本,故无多态,则两种含义就不可能实现。
所以,多态实质上是继承的实现细节;那么让多态与封装、继承这两个概念并列,显然是不符合逻辑的
8.3 封装
封装是啥,抛开面向对象,你单去想什么是装,装就是拿来一个麻袋,把小猫,小狗,小王八,还有alex一起装进麻袋,什么是封,封就是把麻袋封上口子。
在面向对象中这个麻袋就是你的类或者对象,类或者对象这俩麻袋内部装了数据属性和函数属性,那么对于类和对象来说‘封’的概念从何而来,其实封的概念代表隐藏
在学完了面向对象的类和对象相关的知识后,大家都知道了如何把属性装进类或者对象中,那么如何完成封的效果呢?
第一个层面的封装:类就是麻袋,这本身就是一种封装
例:略
第二个层面的封装:类中定义私有的,只在类的内部使用,外部无法访问
python不依赖语言特性去实现第二层面的封装,而是通过遵循一定的数据属性和函数属性的命名约定来达到封的效果 约定一:任何以单下划线开头的名字都应该是内部的,私有的
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class People:
_star='earth'
def __init__(self,id,name,age,salary):
self.id=id
self.name=name
self._age=age
self._salary=salary
def _get_id(self):
print('我是私有方法啊,我找到的id是[%s]' %self.id)
#我们明明约定好了的,只要属性前加一个单下划线,那他就属于内部的属性,不能被外部调用了啊,为何还能调用???
print(People._star)
p1=People('3706861900121221212','alex',28,10)
print(p1._age,p1._salary)
p1._get_id()
瞬间你就蒙蔽了,私有的怎么还能被访问私有的怎么还能被访问,我上去就是一巴掌,这只是一种约定
python并不会真的阻止你访问私有的属性,模块也遵循这种约定,如果模块名以单下划线开头,那么from module import *时不能被导入,但是你from module import _private_module依然是可以导入的
其实很多时候你去调用一个模块的功能时会遇到单下划线开头的(socket._socket,sys._home,sys._clear_type_cache),这些都是私有的,原则上是供内部调用的,作为外部的你,一意孤行也是可以用的,只不过显得稍微傻逼一点点
约定二:双下划线开头的名字
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class People:
__star='earth'
def __init__(self,id,name,age,salary):
self.id=id
self.name=name
self.__age=age
self._salary=salary
def _get_id(self):
print('我是私有方法啊,我找到的id是[%s]' %self.id)
print(People.__dict__)#__star存到类的属性字典中被重命名为_People__star
p1=People('333333','alex',18,10)
print(p1.__dict__)#__age存到类的属性字典中被重命名为_People__age
print(People.star) #好像不能访问了喔!
print(p1.age)# 好像也不能访问了喔!
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class People:
__star='earth'
def __init__(self,id,name,age,salary):
self.id=id
self.name=name
self.__age=age
self._salary=salary
def _get_id(self):
print('我是私有方法啊,我找到的id是[%s]' %self.id)
print(People.__dict__)#__star存到类的属性字典中被重命名为_People__star
p1=People('333333','alex',18,10)
print(p1.__dict__)#__age存到类的属性字典中被重命名为_People__age
# print(People.star) #好像不能访问了喔!
# print(p1.age)# 好像也不能访问了喔!
print(People._People__star) #我曹,又能访问了why?
print(p1._People__age)#我曹,又能访问了why?
约定二到底有何卵用?-》双下滑线开头的属性在继承给子类时,子类是无法覆盖的(原理也是基于python自动做了双下滑线开头的名字的重命名工作)
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class People:
__star='earth'
def __init__(self,id,name,age,salary):
self.id=id
self.name=name
self.__age=age
self._salary=salary
def _get_id(self):
print('我是私有方法啊,我找到的id是[%s]' %self.id)
class Korean(People):
__star = '火星'
pass
print(People.__dict__)#__star存到类的属性字典中被重命名为_People__star
print(Korean.__dict__)
# print(Korean.__star)#傻逼,这么访问当然报错啦,__star被重命名了,忘记了?
print(Korean._Korean__star)
print(Korean._People__star)
第三个层面的封装:明确区分内外,内部的实现逻辑,外部无法知晓,并且为封装到内部的逻辑提供一个访问接口给外部使用(这才是真正的封装,具体实现,会在面向对象进阶中讲)
总结:
上面提到有两种不同的编码约定(单下划线和双下划线 )来命名私有属性,那么问 题就来了:到底哪种方式好呢?大多数而言,你应该让你的非公共名称以单下划线开 头。但是,如果你清楚你的代码会涉及到子类,并且有些内部属性应该在子类中隐藏 起来,那么才考虑使用双下划线方案。 但是无论哪种方案,其实python都没有从根本上限制你的访问。
然后你就懵逼了,你这不跟我扯犊子呢么,讲了半天得出的结论是:不可能完成真正的封。没错,这不是我的错,也不是龟叔的错
正本清源七:封装最简单了,装是定义属性,封是“把不想让别人看到、以后可能修改的东西用隐藏起来---》小傻逼
在其他语言中私有的属性在外部就是不能被访问的,在python中则相反
面向对象有封装,多态,继承三大特性没错,这只是面向对象所支持的特性,一些人错误的认为,面向对象编程兼备的三大特性,那一定就是好的,于是他们随意把属性定义成私有的,却又在需求变更时发现自己的定义不合理,又不得不通过某种方式把私有的属性公开,像这种(我们用python来模拟其他语言中滥用封装,发现不对劲后开始在类中到处挖洞)
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class People:
__star='earth'
def __init__(self,id,name,age,salary):
self.id=id
self.name=name
self.__age=age
self._salary=salary
def tell_star(self):
print('%s 来自于星球[%s]' %(self.name,self.__star))
p1=People('12','alex',18,12)
p1.tell_star()
上述的这种例子是,不动脑子就把一个属性做成了私有的属性,私有属性外部是无法被访问的,后来的某天你发现,这个属性其实是应该被放开的,于是你的解决方法是定义一个访问函数,在内部去调用私有属性,的方法完美的解决了这个问题,没错,访问函数确实是一种好东西,但是你这个问题的出在你滥用封装,后来利用访问函数去帮你填坑。
python并不严格限制外部对私有属性的访问,龟叔之所以这么设计,我估计一个重要原因就是见多了上面这种论调的人于是干脆把我们的python做成非严格意义的封装,以避免你滥用封装。
封装在于明确区分内外,使得类实现者可以修改封装内的东西而不影响外部调用者;而外部调用者也可以知道自己不可以碰哪里。这就提供一个良好的合作基础——或者说,只要接口这个基础约定不变,则代码改变不足为虑。
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class Room:
def __init__(self,name,owner,width,length,high):
self.name=name
self.owner=owner
self.__width=width
self.__length=length
self.__high=high
def tell_area(self): #此时我们想求的是面积
return self.__width * self.__length
r1=Room('卫生间','alex',100,100,10000)
area=r1.tell_area()
print(area)
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
class Room:
def __init__(self,name,owner,width,length,high):
self.name=name
self.owner=owner
self.__width=width
self.__length=length
self.__high=high
def tell_area(self): #此时我们想求的是体积,内部逻辑变了,而外部调用感知不到,仍然使用该方法
return self.__width * self.__length * self.__high
r1=Room('卫生间','alex',100,100,10000)
area=r1.tell_area()
print(area)
九 面向对象的优点
从编程进化论我们得知,面向对象是一种更高等级的结构化编程方式,它的好处就两点
1:通过封装明确了内外,你作为类的缔造者,你是上帝,上帝造物的逻辑你无需知道(你知道了你tm也成上帝了),上帝想让你知道的你才能知道,这样就明确了划分了等级,物就是调用者,上帝就是物的创造者
2:通过继承+多态在语言层面支持了归一化设计
注意:不用面向对象语言(即不用class),一样可以做归一化(如老掉牙的泛文件概念、游戏行业的一切皆精灵),一样可以封装(通过定义模块和接口),只是用面向对象语言可以直接用语言元素显式声明这些而已;而用了面向对象语言,满篇都是class,并不等于就有了归一化的设计。甚至,因为被这些花哨的东西迷惑,反而更加不知道什么才是设计。
十 python中关于OOP的常用术语
抽象/实现
抽象指对现实世界问题和实体的本质表现,行为和特征建模,建立一个相关的子集,可以用于 绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,还定义了这些数据的接口。
对某种抽象的实现就是对此数据及与之相关接口的现实化(realization)。现实化这个过程对于客户 程序应当是透明而且无关的。
封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口,与封装性都是背道而驰的,除非程序员允许这些操作。作为实现的 一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python中,所有的类属性都是公开的,但名字可能被“混淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数据属性。
注意:封装绝不是等于“把不想让别人看到、以后可能修改的东西用private隐藏起来”
真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”的接口,并使得内部细节可以对外透明
(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在)
合成
合成扩充了对类的 述,使得多个不同的类合成为一个大的类,来解决现实问题。合成 述了 一个异常复杂的系统,比如一个类由其它类组成,更小的组件也可能是其它的类,数据属性及行为, 所有这些合在一起,彼此是“有一个”的关系。
派生/继承/继承结构
派生描述了子类衍生出新的特性,新类保留已存类类型中所有需要的数据和行为,但允许修改或者其它的自定义操作,都不会修改原类的定义。 继承描述了子类属性从祖先类继承这样一种方式 继承结构表示多“代”派生,可以述成一个“族谱”,连续的子类,与祖先类都有关系。
泛化/特化
基于继承 泛化表示所有子类与其父类及祖先类有一样的特点。 特化描述所有子类的自定义,也就是,什么属性让它与其祖先类不同。
多态
多态的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需考虑他们具体的类。
多态表明了动态(又名,运行时)绑定的存在,允计重载及运行时类型确定和验证。
举例:
水是一个类
不同温度,水被实例化成了不同的状态:冰,水蒸气,雾(然而很多人就理解到这一步就任务此乃多态,错,fuck!,多态是运行时绑定的存在)
(多态体现在由同一个类实例化出的多个对象,这些对象执行相同的方法时,执行的过程和结果是不一样的)
冰,水蒸气,雾,有一个共同的方法就是变成云,但是冰.变云(),与水蒸气.变云()是截然不同的两个过程,虽然调用的方法都一样
自省/反射
自省也称作反射,这个性质展示了某对象是如何在运行期取得自身信息的。如果传一个对象给你,你可以查出它有什么能力,这是一项强大的特性。如果Python不支持某种形式的自省功能,dir和type内建函数,将很难正常工作。还有那些特殊属性,像__dict__,__name__及__doc__

 浙公网安备 33010602011771号
浙公网安备 33010602011771号