
在python2列表中,有时候,想打印一个列表,会出现如下显示:

这个是由于:
print一个对象,是输出其“为了给人(最终用户)阅读”而设计的输出形式,那么字符串中的转义字符需要转出来,而且 也不要带标识字符串边界的引号。
因此,单独打印列表中的某一项,譬如:list[0],他可以很好的转义出中文字符。而一个list对象,本身就是个数据结构,如果要把它显示给最终用户看,它不会对里面的数据进行润色。
解决办法参考:https://www.zhihu.com/question/20413029
由此进一步思考:
1、我们在定义字符串的时候,u"中文"的u是什么意思?
string = u"中文"
string.decode('utf8')
可以看到会出异常:
---------------------------------------------------------------------------
UnicodeEncodeError Traceback (most recent call last)
<ipython-input-41-b3abdaf47d60> in <module>()
1 string = u"中文"
----> 2 string.decode('utf8')
C:\ProgramData\Anaconda2\lib\encodings\utf_8.pyc in decode(input, errors)
14
15 def decode(input, errors='strict'):
---> 16 return codecs.utf_8_decode(input, errors, True)
17
18 class IncrementalEncoder(codecs.IncrementalEncoder):
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
这说明,string的编码方式并不是utf-8。
我之前一直以为是指的是utf-8的编码方式,其实不然。
2、# -*- coding: utf-8 -*- 和 sys.setdefaultencoding("utf-8")的区别是什么?
# -*- coding: utf-8 -*- :作用于源代码,如果没有定义,源码不能包含中文字符。https://www.python.org/dev/peps/pep-0263/
sys.setdefaultencoding("utf-8") :设置默认的string编码方式
3、decode\encode指定编码解码方式
# -*- coding: utf-8 -*-
import sys
#Python2.5 初始化后删除了 sys.setdefaultencoding 方法,我们需要重新载入
reload(sys)
sys.setdefaultencoding('utf-8')
string = "中文"
print repr(string.decode('utf-8'))
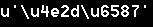
4、unicode编码
字符串通常包含str、unicode两种类型,通常str指字符串编码方式。在Python程序内部,通常使用的字符串为unicode编码,这样的字符串字符是一种内存编码格式,如果将这些数据存储到文件或是记录日志的时候,就需要将unicode编码的字符串转换为特定字符集的存储编码格式,比如:UTF-8、GBK等。
unicode编码:编码表的编号从0一直算到了100多万(三个字节)。每一个区间都对应着一种语言的编码。目前几乎收纳了全世界大部分的字符。所有的字符都有唯一的编号,事实上是一种字符集。但是,unicode把大家都归纳进来,却没有为编码的二进制传输和二进制解码做出规定。于是,就出现了如下解决方案:uft-8,utf-16,utf-32这些编码方案,主要还是为了解决一个信息传输效率的问题,因为如果直接根据字符集进行传输的话,三个字节的表示就会比较低效了。
str 转 unicode
string = "asdf"
string.decode("utf-8")
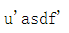
所以,u就是unicode
unicode转 str
string = u"asdf"
string.encode("utf-8")

5、unicode-escape
在将unicode存储到文本的过程中,还有一种存储方式,不需要将unicode转换为实际的文本存储字符集,而是将unicode的内存编码值进行存储,读取文件的时候再反向转换回来,是采用:unicode-escape的转换方式。
unicode到unicode-escape
string = "中文" # 或 u"中文",不影响,因为最终都是unicode的内存编码
string.encode("unicode-escape")
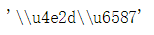
unicode-escape到unicode
string = "中文"
string.decode("unicode-escape")
>> u'\xe4\xb8\xad\xe6\x96\x87
6、string-escape
对于utf-8编码的字符串,在存储的时候,通常是直接存储,而实际上也还有一种存储utf-8编码值的方法,即:string-escape。
str(utf8)到string-escape
string = "中文"
string.encode("string-escape")
>> '\\xe4\\xb8\\xad\\xe6\\x96\\x87'
string-escape到str(utf8)
string = "中文"
string.decode("string-escape")
>>'\xe4\xb8\xad\xe6\x96\x87'
//-------------由上,进一步分析:
a = "中文"
print repr(a.decode("utf-8"))
a = "中文"
print repr(a.decode("unicode-escape"))
print repr(u"中文")
print repr(a)

可以看到,从str转unicode和从unicode-escape转unicode的差距。再比如:
string = '\u4e2d\u6587'
print repr(string.decode("unicode-escape"))
print repr(string.decode("utf8"))

更为清楚的看到,从unicode-escape转unicode,两者没有文本转化的过程,是一个内存转化的过程。而通过str转unicode,会有文本转化,譬如对转义字符的操作。
对于列表中中文编码的解释:
arr = [u"中文"]
print arr
print repr(arr)
pp = str(arr).decode("unicode-escape")#
print pp
print repr(pp)
tt = str(arr).decode("utf-8")
print tt
print repr(tt)
>>[u'\u4e2d\u6587']
>>[u'\u4e2d\u6587']
>>[u'中文']
>>u"[u'\u4e2d\u6587']"
>>[u'\u4e2d\u6587']
>>u"[u'\\u4e2d\\u6587']"
由此可见,想要打印list中的中文,思路是:
通过字符串化处理,将list转化为str(utf-8)文本编码的方式,同时要保留list里面的unicode,避免通过字符处理导致的转义操作,破坏掉中文的unicode,因此选择了unicode-escape
作者:禅在心中
出处:http://www.cnblogs.com/pinking/
本文版权归作者和博客园共有,欢迎批评指正及转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号