
一、mongodb主从复制配置
主从复制是mongodb最常用的复制方式,也是一个简单的数据库同步备份的集群技术,这种方式很灵活.可用于备份,故障恢复,读扩展等.
最基本的设置方式就是建立一个主节点和一个或多个从节点,每个从节点要知道主节点的地址.
结构图:
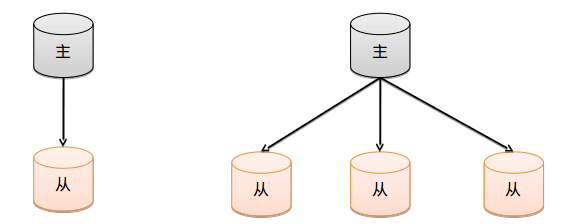
配置主从复制的注意点:
- 在数据库集群中要明确的知道谁是主服务器,主服务器只有一台.
- 从服务器要知道自己的数据源也就是对应的主服务是谁.
- –master用来确定主服务器,–slave 和 –source 来控制从服务器
这里在本机上用一主一从实现mongodb的复制:
master.conf:
dbpath = /home/wang/mongodbDATA/master #主数据库地址
port = 8888 #主数据库端口号
bind_ip = 127.0.0.1 #主数据库所在服务器
master = true #确定我是主服务器slave.conf:
dbpath = /home/wang/mongodbDATA/slave #从数据库地址
port = 7777 #从数据库端口号
bind_ip = 127.0.0.1 #从数据库所在服务器
source = 127.0.0.1:8888 #确定主数据库端口
slave = true #确定自己是从服务器分别启动两台服务器:
mongod --config master.conf
mongod --config slave.conf启动两个shell客户端:
mongo 127.0.0.1:8888
mongo 127.0.0.1:7777我们给主服务器添加数据:
>use master_slave
> function add(){
... var i = 0;
... for(;i<50;i++){
... db.persons.insert({"name":"wang"+i})
... }
... }
> add()
>db.persons.find()
.....一批数据如上的操作比较简单,此处不在多说。现在主服务器添加了50条数据后,我们打开从服务器,会惊奇的发现,从服务器中也存在如上的50条数据。
此时,我们得到一个结论:
当配置完主从服务器后,一但主服务器上的数据发生变化,从服务器也会发生变化
主从复制的原理–oplog
在主从结构中,主节点的操作记录成为oplog(operation log)。oplog存储在一个系统数据库local的集合oplog.$main中,这个集合的每个文档都代表主节点上执行的一个操作。
从服务器会定期从主服务器中获取oplog记录,然后在本机上执行!对于存储oplog的集合,MongoDB采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!
主从复制的其他设置项
–only 从节点指定复制某个数据库,默认是复制全部数据库
–slavedelay 从节点设置主数据库同步数据的延迟(单位是秒)
–fastsync 从节点以主数据库的节点快照为节点启动从数据库
–autoresync 从节点如果不同步则从新同步数据库(即选择当通过热添加了一台从服务器之后,从服务器选择是否更新主服务器之间的数据)
–oplogSize 主节点设置oplog的大小(主节点操作记录存储到local的oplog中)
利用shell动态的添加或删除从节点:
我们在我们上面的从节点的local数据库中,存在一个集合sources。这个集合就保存了我这个服务器的主服务器是谁。
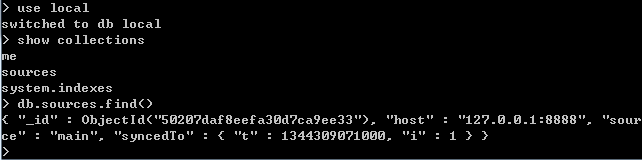
不难看出从服务器中关于主服务器的信息全部存到local的sources的集合中
我们只要对集合进行操作就可以动态操作主从关系
挂接主服务器:操作之前只留下从数据库服务
db.sources.insert({“host”:”127.0.0.1:8888”})
删除已经挂接的主节点:操作之前只留下从数据库服务
db.sources.remove({“host”:”127.0.0.1:8888”})
二,MongoDB的副本集:
1.副本集的概念:
副本集有点类似主从复制,不过跟真正的主从复制还是有两点区别的。
该集群没有特定的主数据库。
如果哪个主数据库宕机了,集群中就会推选出一个从属数据库作为主数据库顶上,这就具备了自动故障恢复功能.
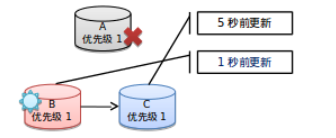
结构图:
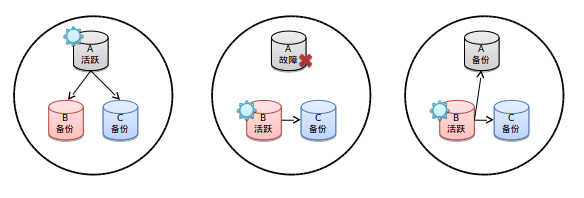
- 第一张图表明A是活跃的B和C是用于备份的
- 第二张图当A出现了故障,这时候集群根据权重算法推选出B为活跃的数据库
- 第三张图当A恢复后他自动又会变为备份数据库
如上三台机器的conf配置文件为:
A.conf
dbpath = /home/wang/mongodbDATA/A
port = 1111 #端口
bind_ip = 127.0.0.1 #服务地址
replSet = child/127.0.0.1:2222 #设定同伴 child为集群名称B.conf
dbpath = /home/wang/mongodbDATA/B
port = 2222
bind_ip = 127.0.0.1
replSet = child/127.0.0.1:3333C.conf
dbpath = /home/wang/mongodbDATA/C
port = 3333
bind_ip = 127.0.0.1
replSet = child/127.0.0.1:1111如上可以看出,ABC三台服务器之间形成一个闭环。
启动如上三台服务器。
2,初始化副本集
我们随意链接上面三个服务的一个shell客户端。
执行如下命令:
config = {_id: 'child', members: [{
"_id":1,
"host":"127.0.0.1:1111"
},{
"_id":2,
"host":"127.0.0.1:2222"
},{
"_id":3,
"host":"127.0.0.1:3333"
}]
}
rs.initiate(config); 在以前的2.0系统中是这样执行的:
use admin #必须进admin
db.runCommand({"replSetInitiate":
{
"_id":'child',
"members":[{
"_id":1,
"host":"127.0.0.1:1111"
},{
"_id":2,
"host":"127.0.0.1:2222"
},{
"_id":3,
"host":"127.0.0.1:3333"
}]
}
}) 此时你会发现你当前的shell客户端的前缀变了。
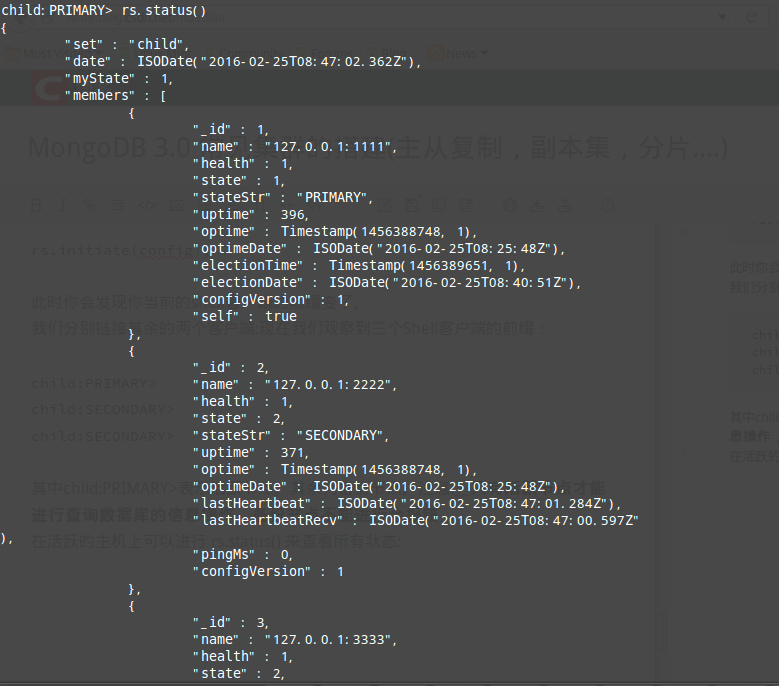
我们分别链接其余的两个客户端:现在我们观察到三个Shell客户端的前缀:
child:PRIMARY>
child:SECONDARY>
child:SECONDARY> 其中child:PRIMARY>表示活跃节点。其余为备份节点。注意:只有活跃节点才能进行查询数据库的信息操作,备份节点不能进行会报错
在活跃的主机上可以进行 rs.status() 来查看所有状态:
4.搭建完毕,来进行验证
主从服务器数据是否同步,从服务器没有读写权限
- a:向主服务器写入数据 ok 后台自动同步到从服务器,从服务器有数据
- b:向从服务器写入数据 false 从服务器不能写
- c:主服务器读取数据 ok
- d:从服务器读取数据 false 从服务器不能读
关闭主服务器,从服务器是否能顶替
此时你关掉活跃节点的服务。此时你会发现剩余的两台机器有一台变为活跃节点了。
5.配置副本集的其他配置参数:
节点和初始化高级参数
- standard 常规节点:参与投票有可能成为活跃节点
- passive 副本节点:参与投票,但是不能成为活跃节点
- arbiter 仲裁节点:只是参与投票不复制节点也不能成为活跃节点
高级参数
- Priority 0到1000之间 ,0代表是副本节点 ,1到1000是常规节点
- arbiterOnly : true 仲裁节点
用法
members":[{
"_id":1,
"host":"127.0.0.1:1111“,
arbiterOnly : true
}]” 优先级相同时候仲裁组建的规则
三,分片
分片技术,跟关系数据库的表分区类似,我们知道当数据量达到T级别的时候,我们的磁盘,内存就吃不消了,或者单个的mongoDB服务器已经不能满足大量的插入操作,针对这样的场景我们该如何应对。mongoDB提供的分片技术来应对这种瓶颈。
当然分片除了解决空间不足的问题之外,还极大的提升的查询速度。
1.分片的概念
mongodb采用将集合进行拆分,然后将拆分的数据均摊到几个片上的一种解决方案。
结构图:
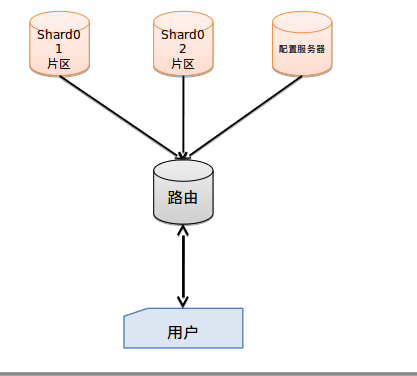
用户:代表客户端,客户端肯定说,你数据库分片不分片跟我没关系,我叫你干啥就干啥,没什么好商量的。
路由: mongos.首先我们要了解”片键“的概念,也就是说拆分集合的依据是什么?按照什么键值进行拆分集合….好了,mongos就是一个路由服务器,它会根据管理员设置的“片键”将数据分摊到自己管理的mongod集群,数据和片的对应关系以及相应的配置信息保存在”config服务器”上。
配置服务器:mongod普通的数据库,一般是一组而图中我们只画了一个,由路由管理。它的作用是记录对数据分片的规则,存储所有数据库元信息(路由、分片)的配置
片区:具体的存储信息,根据路由配置的片键不同
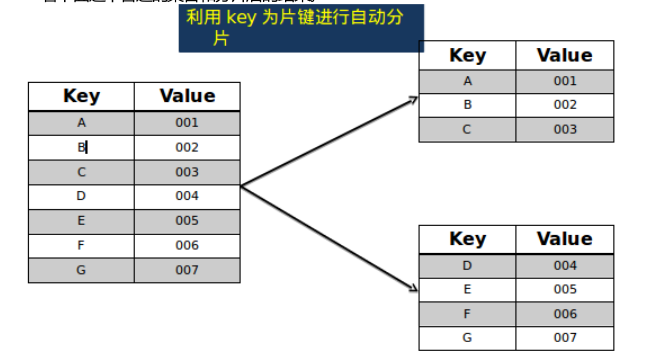
2.片键的概念和用处
看下面这个普通的集合和分片后的结果。
3.分片步骤
- 创建一个配置服务器
- 创建路由服务器,并且连接配置服务器
- 由器是调用mongos命令
- 添加2个分片数据库 端口为8081和8082
- 利用路由为集群添加分片(允许本地访问)
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true})
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true}) 切记之前不能使用任何数据库语句
- 打开数据分片功能,为数据库foobar打开分片功能
db.runCommand({"enablesharding":"foobar"})
- 对集合进行分片,制定片键
db.runCommand({"shardcollection":"foobar.bar","key":{"_id":1}})4.搭建分片:
分片数据库_01.conf:
dbpath = ~/mongodata/01
port = 8081
bind_ip = 127.0.0.1分片数据库_02.conf:
dbpath = ~/mongodata/02
port = 8082
bind_ip = 127.0.0.1配置服务器.conf:
dbpath = ~/mongodata/00
port = 2000
bind_ip = 127.0.0.1路由
mongos --port 1000 --configdb 127.0.0.1:2000启动上面所有的服务。
mongo 127.0.0.1:1000 (此时就通过路由链接到了配置服务器)
登录进路由之后为集群添加分片:
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true})
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true})切记之前不能使用任何数据库语句
打开数据分片功能,为数据库foobar打开分片功能
db.runCommand({"enablesharding":"foobar"})对集合进行分片
db.runCommand({"shardcollection":"foobar.bar","key":{"_id":1}})5.利用大数据量进行测试
function add(){
var i = 0;
for(;i<200000;i++){
db.bar.insert({"age":i+10,"name":"jim"})
}
}
function add2(){
var i = 0;
for(;i<200000;i++){
db.bar.insert({"age":12,"name":"tom"+i})
}
}
function add3(){
var i = 0;
for(;i<200000;i++){
db.bar.insert({"age":12,"name":"lili"+i})
}
} (给foobar插入800000条数据,然后会发现这800000条数据分批存放在分片上。)
查看配置库对于分片服务器的配置存储
db.printShardingStatus()查看集群对bar的自动分片机制配置信息
mongos> db.shards.find()
{ "_id" : "shard0000", "host" : "127.0.0.1:8081" }
{ "_id" : "shard0001", "host" : "127.0.0.1:8082" }如上就是MongoDB中常见的集群搭建。对于分片是最常用的,实际中的分片不可以像我们配置的这么简单,为了保险期间,实际中分片之间配置为副本集,配置服务器也不会是单单一台也常见的是一个副本集的集群。只有这样,才能让系统更加健壮。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号