
交通流的数据分析,需求是对于海量的城市交通数据,需要使用MapReduce清洗后导入到HBase中存储,然后使用Hive外部表关联HBase,对HBase中数据进行查询、统计分析,将分析结果保存在一张Hive表中,最后使用Sqoop将该表中数据导入到MySQL中。整个流程大概如下:
一、HBase数据库表
下面我主要介绍Hive关联HBase表——Sqoop导出Hive表到MySQL这些流程,原始数据集收集、MapReduce清洗及WEB界面展示此处不介绍。

创建一个名叫“transtable”的HBase表,列族是:“jtxx”。HBase中的部分数据如下:
- hbase(main):003:0> list
- TABLE
- transtable
- 1 row(s) in 0.0250 seconds
- => ["transtable"]
- hbase(main):004:0> describe 'transtable'
- DESCRIPTION ENABLED
- 'transtable', {NAME => 'jtxx', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VER true
- SIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS => 'false', BLO
- CKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
- 1 row(s) in 0.0480 seconds
- hbase(main):008:0> get 'transtable','32108417000000013220140317000701'
- COLUMN CELL
- jtxx:cdbh timestamp=1429597736296, value=03
- jtxx:clbj timestamp=1429597736296, value=0
- jtxx:cllb timestamp=1429597736296, value=0
- jtxx:cllx timestamp=1429597736296, value=3
- jtxx:clsd timestamp=1429597736296, value=127.00
- jtxx:hphm timestamp=1429597736296, value=\xE8\x8B\x8FKYV152
- jtxx:wflx timestamp=1429597736296, value=0
- jtxx:xsfx timestamp=1429597736296, value=03
- 8 row(s) in 0.1550 seconds
二、创建Hive外部表关联HBase表
- create external table transJtxx_Hbase
- (
- clxxbh string,
- xsfx string,
- cdbh string,
- hphm string,
- clsd string,
- cllx string,
- clbj string,
- cllb string,
- wflx string
- )
- stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
- with serdeproperties ("hbase.columns.mapping" =":key,jtxx:xsfx,jtxx:cdbh,jtxx:hphm,jtxx:clsd,jtxx:cllx,jtxx:clbj,jtxx:cllb,jtxx:wflx") TBLPROPERTIES ("hbase.table.name" = "transtable");
hbase.columns.mapping要对应hbase数据库transtable表中列族下的列限定符。此处一定要是外部表
查看是否关联成功,如何执行一条语句能够查询出HBase表中数据,则关联成功。
- hive> select * from transjtxx_hbase where clxxbh like '321084170000000132%';
- Total jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks is set to 0 since there's no reduce operator
- Starting Job = job_1428394594787_0007, Tracking URL = http://secondmgt:8088/proxy/application_1428394594787_0007/
- Kill Command = /home/hadoopUser/cloud/hadoop/programs/hadoop-2.2.0/bin/hadoop job -kill job_1428394594787_0007
- Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
- 2015-04-21 17:27:18,136 Stage-1 map = 0%, reduce = 0%
- 2015-04-21 17:27:35,029 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 12.31 sec
- MapReduce Total cumulative CPU time: 12 seconds 310 msec
- Ended Job = job_1428394594787_0007
- MapReduce Jobs Launched:
- Job 0: Map: 1 Cumulative CPU: 12.31 sec HDFS Read: 256 HDFS Write: 636 SUCCESS
- Total MapReduce CPU Time Spent: 12 seconds 310 msec
- OK
- 32108417000000013220140317000701 03 03 苏KYV152 127.00 3 0 0 0
- 32108417000000013220140317000705 02 03 苏KRU593 127.00 2 0 0 0
- 32108417000000013220140317000857 03 02 苏KYL920 28.00 4 0 0 0
- 32108417000000013220140317001145 02 02 苏K19V75 136.00 6 0 0 0
- 32108417000000013220140317001157 02 02 鲁QV0897 150.00 4 0 0 0
- 32108417000000013220140317001726 02 02 苏KL2938 23.00 1 0 0 0
- 32108417000000013220140317001836 02 02 苏J5S373 142.00 4 0 0 0
- 32108417000000013220140317001844 02 02 苏KK8332 158.00 3 0 0 0
- 32108417000000013220140317002039 03 02 苏KK8820 17.00 0 0 0 0
- 32108417000000013220140317002206 03 03 苏KK8902 32.00 4 0 0 0
- Time taken: 36.018 seconds, Fetched: 10 row(s)
因为此处我是模拟环境,所以我创建一个和hive关联表transjtxx_hbase一样字段类型的表,用于存放查询结果,如下:
- hive> create table temptrans
- > (clxxbh string,
- > xsfx string,
- > cdbh string,
- > hphm string,
- > clsd string,
- > cllx string,
- > clbj string,
- > cllb string,
- > wflx string
- > ) ;
- OK
- Time taken: 0.112 seconds
四、通过查询结果向Hive表中插入数据
使用Hive表四种数据导入方式之一——通过SQL查询语句向Hive表中插入数据。(详细介绍可以查看我的另外一篇博文:Hive表中四种不同数据导出方式以及如何自定义导出列分隔符)此处我以查询某个路口过往车辆为例。因为,clxxbh是由路口编号+日期组成,此处不使用overwrite,是因为后续会循环执行,之前导入的数据需要保留,所以必须使用into,如下:
- hive> insert into table temptrans select * from transjtxx_hbase where clxxbh like '321084170000000133%';
- Total jobs = 3
- Launching Job 1 out of 3
- Number of reduce tasks is set to 0 since there's no reduce operator
- Starting Job = job_1428394594787_0009, Tracking URL = http://secondmgt:8088/proxy/application_1428394594787_0009/
- Kill Command = /home/hadoopUser/cloud/hadoop/programs/hadoop-2.2.0/bin/hadoop job -kill job_1428394594787_0009
- Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
- 2015-04-21 19:05:03,398 Stage-1 map = 0%, reduce = 0%
- 2015-04-21 19:05:24,091 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 12.71 sec
- MapReduce Total cumulative CPU time: 12 seconds 710 msec
- Ended Job = job_1428394594787_0009
- Stage-4 is selected by condition resolver.
- Stage-3 is filtered out by condition resolver.
- Stage-5 is filtered out by condition resolver.
- Moving data to: hdfs://secondmgt:8020/hive/scratchdir/hive_2015-04-21_19-04-48_325_2835499611469580351-1/-ext-10000
- Loading data to table hive.temptrans
- Table hive.temptrans stats: [numFiles=2, numRows=12, totalSize=1380, rawDataSize=732]
- MapReduce Jobs Launched:
- Job 0: Map: 1 Cumulative CPU: 12.71 sec HDFS Read: 256 HDFS Write: 815 SUCCESS
- Total MapReduce CPU Time Spent: 12 seconds 710 msec
- OK
- Time taken: 37.229 seconds
- hive> select * from tempTrans;
- OK
- 32108417000000013220140317000701 03 03 苏KYV152 127.00 3 0 0 0
- 32108417000000013220140317000705 02 03 苏KRU593 127.00 2 0 0 0
- 32108417000000013220140317000857 03 02 苏KYL920 28.00 4 0 0 0
- 32108417000000013220140317001145 02 02 苏K19V75 136.00 6 0 0 0
- 32108417000000013220140317001157 02 02 鲁QV0897 150.00 4 0 0 0
- 32108417000000013220140317001726 02 02 苏KL2938 23.00 1 0 0 0
- 32108417000000013220140317001836 02 02 苏J5S373 142.00 4 0 0 0
- 32108417000000013220140317001844 02 02 苏KK8332 158.00 3 0 0 0
- 32108417000000013220140317002039 03 02 苏KK8820 17.00 0 0 0 0
- 32108417000000013220140317002206 03 03 苏KK8902 32.00 4 0 0 0
- 32108417000000013320140317000120 02 02 苏KRW076 0.00 7 0 0 0
- 32108417000000013320140317000206 00 02 苏AHF730 0.00 4 0 0 0
- 32108417000000013320140317000207 02 02 苏KYJ792 0.00 6 0 0 0
- 32108417000000013320140317000530 00 01 苏K53T85 0.00 1 0 0 0
- 32108417000000013320140317000548 03 01 苏KR0737 0.00 7 0 0 0
- 32108417000000013320140317000605 03 02 苏KYU203 0.00 1 0 0 0
- 32108417000000013320140317000659 01 02 苏K3R762 0.00 4 0 0 0
- 32108417000000013320140317001042 02 03 苏KYK578 0.00 6 0 0 0
- 32108417000000013320140317001222 02 03 苏KK8385 0.00 2 0 0 0
- 32108417000000013320140317001418 02 03 苏K26F89 0.00 7 0 0 0
- 32108417000000013320140317001538 02 03 苏KK8987 0.00 5 0 0 0
- 32108417000000013320140317001732 01 01 苏KYB127 0.00 7 0 0 0
- Time taken: 0.055 seconds, Fetched: 22 row(s)
- mysql> create database transport;
- Query OK, 1 row affected (0.00 sec)
- mysql> use transport;
- Database changed
- mysql> create table jtxx
- -> (
- -> clxxbh varchar(64) not null primary key,
- -> xsfx varchar(2),
- -> cdbh varchar(4),
- -> hphm varchar(32),
- -> clsd varchar(16),
- -> cllx varchar(2),
- -> clbj varchar(8),
- -> cllb varchar(8),
- -> wflx varchar(8)
- -> );
- Query OK, 0 rows affected (0.04 sec)
- mysql> show tables;
- +---------------------+
- | Tables_in_transport |
- +---------------------+
- | jtxx |
- +---------------------+
- 1 row in set (0.00 sec)
- mysql> select * from jtxx;
- Empty set (0.00 sec)
六、Sqoop将Hive表数据导入到MySQL中此处创建MySQL表的时候,一定要注意字段名称要和Hive表中对应
- [hadoopUser@secondmgt ~]$ sqoop-export --connect jdbc:mysql://secondmgt:3306/transport --username hive --password hive --table jtxx --export-dir /hive/warehouse/hive.db/temptrans
使用以上导出命令会报如下错误:
- 15/04/21 19:38:52 INFO mapreduce.Job: Task Id : attempt_1428394594787_0010_m_000001_0, Status : FAILED
- Error: java.io.IOException: Can't export data, please check task tracker logs
- at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)
- at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
- at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
- at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:763)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:339)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:162)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:157)
- Caused by: java.util.NoSuchElementException
- at java.util.ArrayList$Itr.next(ArrayList.java:834)
- at jtxx.__loadFromFields(jtxx.java:387)
- at jtxx.parse(jtxx.java:336)
- at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
- ... 10 more
这个错误的原因是指定Hive中表字段之间使用的分隔符错误,供Sqoop读取解析不正确。如果是由hive执行mapreduce操作汇总的结果,默认的分隔符是 '\001',否则如果是从HDFS文件导入的则分隔符则应该是'\t'。此处我是hive执行mapreduce分析汇总的结果,所以默认的分隔是'\001'。Sqoop命令修改如下,指定分隔符:
- [hadoopUser@secondmgt ~]$ sqoop-export --connect jdbc:mysql://secondmgt:3306/transport --username hive --password hive --table jtxx --export-dir /hive/warehouse/hive.db/temptrans --input-fields-terminated-by '\001'
此处的Sqoop导出命令,当MySQL数据库中对应表为空,无数据的时候可以成功执行,但是当里面有数据,即从Hive表中需要导出的数据字段中,和MySQL表中关键字有重复的记录时候,进程会死住,不再往下执行,查看Hadoop任务界面出现内存被大部分占用,队列被占100%占用情况,如下:
- [hadoopUser@secondmgt ~]$ sqoop-export --connect jdbc:mysql://secondmgt:3306/transport --username hive --password hive --table jtxx --export-dir /hive/warehouse/hive.db/temptrans --input-fields-terminated-by '\001'
- Warning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.
- Please set $HCAT_HOME to the root of your HCatalog installation.
- 15/04/21 20:08:28 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
- 15/04/21 20:08:28 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
- 15/04/21 20:08:28 INFO tool.CodeGenTool: Beginning code generation
- 15/04/21 20:08:29 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `jtxx` AS t LIMIT 1
- 15/04/21 20:08:29 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `jtxx` AS t LIMIT 1
- 15/04/21 20:08:29 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoopUser/cloud/hadoop/programs/hadoop-2.2.0
- Note: /tmp/sqoop-hadoopUser/compile/67173774b957b511b4d62bc4ebe56e23/jtxx.java uses or overrides a deprecated API.
- Note: Recompile with -Xlint:deprecation for details.
- 15/04/21 20:08:30 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoopUser/compile/67173774b957b511b4d62bc4ebe56e23/jtxx.jar
- 15/04/21 20:08:30 INFO mapreduce.ExportJobBase: Beginning export of jtxx
- 15/04/21 20:08:30 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
- SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/home/hadoopUser/cloud/hadoop/programs/hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/home/hadoopUser/cloud/hbase/hbase-0.96.2-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
- SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
- 15/04/21 20:08:30 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
- 15/04/21 20:08:31 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
- 15/04/21 20:08:31 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
- 15/04/21 20:08:31 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
- 15/04/21 20:08:31 INFO client.RMProxy: Connecting to ResourceManager at secondmgt/192.168.2.133:8032
- 15/04/21 20:08:32 INFO input.FileInputFormat: Total input paths to process : 2
- 15/04/21 20:08:32 INFO input.FileInputFormat: Total input paths to process : 2
- 15/04/21 20:08:32 INFO mapreduce.JobSubmitter: number of splits:3
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.job.classpath.files is deprecated. Instead, use mapreduce.job.classpath.files
- 15/04/21 20:08:32 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.cache.files.filesizes is deprecated. Instead, use mapreduce.job.cache.files.filesizes
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.cache.files is deprecated. Instead, use mapreduce.job.cache.files
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.cache.files.timestamps is deprecated. Instead, use mapreduce.job.cache.files.timestamps
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.mapoutput.key.class is deprecated. Instead, use mapreduce.map.output.key.class
- 15/04/21 20:08:32 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
- 15/04/21 20:08:32 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1428394594787_0016
- 15/04/21 20:08:33 INFO impl.YarnClientImpl: Submitted application application_1428394594787_0016 to ResourceManager at secondmgt/192.168.2.133:8032
- 15/04/21 20:08:33 INFO mapreduce.Job: The url to track the job: http://secondmgt:8088/proxy/application_1428394594787_0016/
- 15/04/21 20:08:33 INFO mapreduce.Job: Running job: job_1428394594787_0016
sqoop任务无法提交,一直处于以上状态无法继续执行,查看Hadoop任务界面,出现如下情况,队列被100%占用:
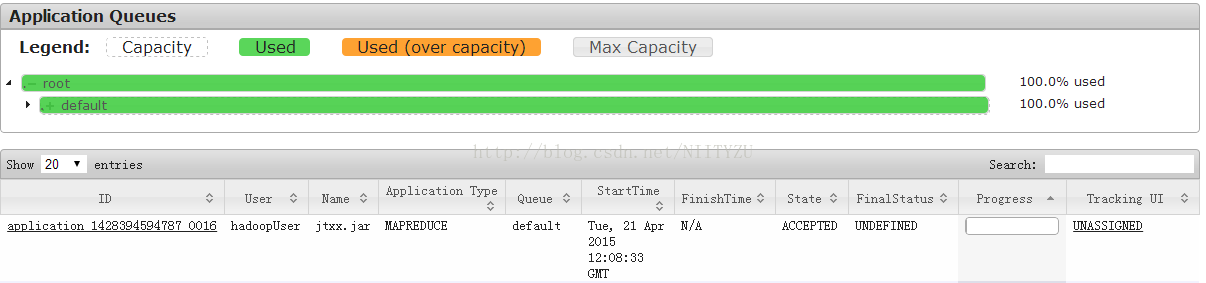
解决办法:
1、查看Hadoop正在运行的进程有哪些,hadoop job -list
2、杀死僵尸进程,hadoop job -kill [job-id]
3、修改Sqoop执行命令如下:
添加了两个参数:--update-key clxxbh --update-mode allowinsert,前面一个表示如果后期导入的数据关键字和MySQL数据库中数据存在相同的,则更新该行记录,后一个表示将目标数据库中原来不存在的数据也导入到数据库表中,即存在的数据保留,新的数据插入,它后接另一个选项是updateonly,即只更新数据,不插入新数据。详细介绍,查看另外一篇博文( Sqoop1.4.4将文件数据集从HDFS中导出到MySQL数据库表中)
- sqoop-export --connect jdbc:mysql://secondmgt:3306/transport --username hive --password hive --table jtxx --update-key clxxbh --
- update-mode allowinsert --export-dir /hive/warehouse/hive.db/temptrans --input-fields-terminated-by '\001'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号