
Sqoop安装配置及hive导入
官网地址:http://sqoop.apache.org/
一、安装配置
1.下载
最新版本1.4.6,下载http://mirrors.cnnic.cn/apache/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
解压:tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6.bin
2.环境变量配置
vi ~/.bash_profile
export SQOOP_HOME=/home/hadoop/sqoop-1.4.6export PATH=$SQOOP_HOME/bin:$PATH
使其生效source .bash_profile
3.配置Sqoop参数
复制conf/sqoop-env-template.sh 为:conf/sqoop-env.sh
- # Hadoop
- export HADOOP_PREFIX=/home/hadoop/hadoop-2.6.0
- export HADOOP_HOME=${HADOOP_PREFIX}
- export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
- export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
- export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
- export HADOOP_YARN_HOME=${HADOOP_PREFIX}
- # Native Path
- export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
- export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib/native"
- # Hadoop end
- #Hive
- export HIVE_HOME=/home/hadoop/hive-1.2.1
- export PATH=$HIVE_HOME/bin:$PATH
- #HBase
- export HBASE_HOME=/home/hadoop/hbase-1.1.2
- export PATH=$HBASE/bin:$PATH
将mysql的驱动jar(mysql-connector-java-5.1.34.jar)复制到lib目录下
二、hive导入测试
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password 123456 ##连接mysql的密码
--table test ##从mysql导出的表名称
--query ##查询语句
--columns ##指定列
--where ##条件
--hive-import ##指定为hive导入
--hive-table ##指定hive表,可以使用--target-dir //user/hive/warehouse/table_name 替换
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
以上的命令中后面的##部分是注释,执行的时候需要删掉;另外,命令的所有内容不能换行,只能一行才能执行。以下操作类似。
准备数据
- CREATE TABLE `t_user` (
- `id` varchar(40) COLLATE utf8_bin NOT NULL,
- `name` varchar(40) COLLATE utf8_bin NOT NULL,
- `age` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`)
- );
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
- INSERT t_user VALUES(uuid_short(), CONCAT('姓名',ROUND(RAND()*50)), ROUND(RAND()*100));
sqoop import --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --table t_user
命令会启动一个job mapreduce 程序导入数据
验证导入到hdfs上的数据:
hdfs dfs -ls /user/hadoop/t_user
hdfs dfs -cat /user/hadoop/t_user/part-m-0000*
注:
1)默认设置下导入到hdfs上的路径是: /user/{user.name}/tablename/(files),比如我的当前用户是hadoop,那么实际路径即: /user/hadoop/t_user/(files)。
如果要自定义路径需要增加参数:--warehouse-dir 比如:
sqoop import --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --table t_user --warehouse-dir /user/test/sqoop
2)若表是无主键表的导入需要增加参数 --split-by xxx 或者 -m 1
Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中.每个map中再处理数据库中获取的一行一行的值,写入到HDFS中.同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。
sqoop import --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --table t_user --split-by 字段名
2.导入数据到Hive
增加参数 –hive-import
sqoop import --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --table t_user --warehouse-dir /user/sqoop --hive-import --create-hive-table
验证导入到hive上的数据:
hive>show tables;
hive>select * from t_user;
3.把数据从hdfs导出到mysql中
复制表结构:create table t_user1 select * from t_user where 1=2;
sqoop export --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --table t_user1 --export-dir '/user/hadoop/t_user/part-m-00000' --fields-terminated-by ','
4.列出mysql数据库中的所有数据库
sqoop list-databases --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456
5.连接mysql并列出数据库中的表
sqoop list-tables --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456
6.将关系型数据的表结构复制到hive中,只是复制表的结构,表中的内容没有复制
sqoop create-hive-table --connect jdbc:mysql://192.168.1.93/test --username hive --password 123456 --hive-table t_user1 --fields-terminated-by "\t" --lines-terminated-by "\n";
参数说明:
--fields-terminated-by "\0001" 是设置每列之间的分隔符,"\0001"是ASCII码中的1,它也是hive的默认行内分隔符, 而sqoop的默认行内分隔符为","
--lines-terminated-by "\n" 设置的是每行之间的分隔符,此处为换行符,也是默认的分隔符;
7.将数据从关系数据库导入文件到hive表中,--query 语句使用
--query 查询语句 如 "select * from t_user"
8.将数据从关系数据库导入文件到hive表中,--columns --where 语句使用
--columns 列名 如:"id,age,name"
--where 条件 如:"age > 40"
参考文章:
(sqoop-1.4.5 on hadoop 1.0.4)
1.什么是Sqoop
Sqoop即 SQL to Hadoop ,是一款方便的在传统型数据库与Hadoop之间进行数据迁移的工具,充分利用MapReduce并行特点以批处理的方式加快数据传输,发展至今主要演化了二大版本,Sqoop1和Sqoop2。
Sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive、hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入。
那么为什么选择Sqoop呢?
- 高效可控的利用资源,任务并行度,超时时间。
- 数据类型映射与转化,可自动进行,用户也可自定义
- 支持多种主流数据库,MySQL,Oracle,SQL Server,DB2等等
2.Sqoop1和Sqoop2对比的异同之处
- 两个不同的版本,完全不兼容
- 版本号划分区别,Apache版本:1.4.x(Sqoop1); 1.99.x(Sqoop2) CDH版本 : Sqoop-1.4.3-cdh4(Sqoop1) ; Sqoop2-1.99.2-cdh4.5.0 (Sqoop2)
- Sqoop2比Sqoop1的改进
- 引入Sqoop server,集中化管理connector等
- 多种访问方式:CLI,Web UI,REST API
- 引入基于角色的安全机制
3.Sqoop1与Sqoop2的架构图
Sqoop架构图1

Sqoop架构图2

4.Sqoop1与Sqoop2的优缺点
|
比较 |
Sqoop1 |
Sqoop2 |
|
架构 |
仅仅使用一个Sqoop客户端 |
引入了Sqoop server集中化管理connector,以及rest api,web,UI,并引入权限安全机制 |
|
部署 |
部署简单,安装需要root权限,connector必须符合JDBC模型 |
架构稍复杂,配置部署更繁琐 |
|
使用 |
命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏 |
多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在Sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写 |
5.Sqoop的安装部署
5.0 安装环境
hadoop:hadoop-1.0.4
sqoop:sqoop-1.4.5.bin__hadoop-1.0.0
5.1 下载安装包及解压
tar -zxvf sqoop-1.4.5.bin__hadoop-1.0.0.tar.gz
ln -s ./package/sqoop-1.4.5.bin__hadoop-1.0.0/ sqoop
5.2 配置环境变量和配置文件
cd sqoop/conf/
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
在sqoop-env.sh中添加如下代码

#Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/home/hadoop/hadoop #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/home/hadoop/hadoop #set the path to where bin/hbase is available export HBASE_HOME=/home/hadoop/hbase #Set the path to where bin/hive is available export HIVE_HOME=/home/hadoop/hive #Set the path for where zookeper config dir is export ZOOCFGDIR=/home/hadoop/zookeeper
(如果数据读取不设计hbase和hive,那么相关hbase和hive的配置可以不加,如果集群有独立的zookeeper集群,那么配置zookeeper,反之,不用配置)。
5.3 copy需要的lib包到Sqoop/lib
所需的包:hadoop-core包、Oracle的jdbc包、mysql的jdbc包(由于我的项目只用到Oracle,因此只用了oracle的jar包:ojdbc6.jar)
cp ~/hadoop/hadoop-core-1.0.4.jar ~/sqoop/lib/
cp ojdbc6.jar ~/sqoop/lib/
5.4 添加环境变量
vi ~/.bash_profile
添加如下内容
#Sqoop export SQOOP_HOME=/home/hadoop/sqoop export PATH=$PATH:$SQOOP_HOME/bin
source ~/.bash_profile
5.5 测试oracle数据库的连接使用
①连接oracle数据库,列出所有的数据库
[hadoop@eb179 sqoop]$sqoop list-databases --connect jdbc:oracle:thin:@10.1.69.173:1521:ORCLBI --username huangq -P
或者sqoop list-databases --connect jdbc:oracle:thin:@10.1.69.173:1521:ORCLBI --username huangq --password 123456
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: $HADOOP_HOME is deprecated.
14/08/17 11:59:24 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
Enter password:
14/08/17 11:59:27 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
14/08/17 11:59:27 INFO manager.SqlManager: Using default fetchSize of 1000
14/08/17 11:59:51 INFO manager.OracleManager: Time zone has been set to GMT
MRDRP
MKFOW_QH
②Oracle数据库的表导入到HDFS
注意:
- 默认情况下会使用4个map任务,每个任务都会将其所导入的数据写到一个单独的文件中,4个文件位于同一目录,本例中 -m1表示只使用一个map任务
- 文本文件不能保存为二进制字段,并且不能区分null值和字符串值"null"
- 执行下面的命令后会生成一个ENTERPRISE.java文件,可以通过ls ENTERPRISE.java查看,代码生成是sqoop导入过程的必要部分,sqoop在将源数据库中的数据写到HDFS前,首先会用生成的代码将其进行反序列化
[hadoop@eb179 ~]$ sqoop import --connect jdbc:oracle:thin:@10.1.69.173:1521:ORCLBI --username huangq --password 123456 --table ORD_UV -m 1 --target-dir /user/sqoop/test --direct-split-size 67108864
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: $HADOOP_HOME is deprecated.
14/08/17 15:21:34 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/08/17 15:21:34 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
14/08/17 15:21:34 INFO oracle.OraOopManagerFactory: Data Connector for Oracle and Hadoop is disabled.
14/08/17 15:21:34 INFO manager.SqlManager: Using default fetchSize of 1000
14/08/17 15:21:34 INFO tool.CodeGenTool: Beginning code generation
14/08/17 15:21:46 INFO manager.OracleManager: Time zone has been set to GMT
14/08/17 15:21:46 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM ORD_UV t WHERE 1=0
14/08/17 15:21:46 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop
Note: /tmp/sqoop-hadoop/compile/328657d577512bd2c61e07d66aaa9bb7/ORD_UV.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
14/08/17 15:21:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/328657d577512bd2c61e07d66aaa9bb7/ORD_UV.jar
14/08/17 15:21:47 INFO manager.OracleManager: Time zone has been set to GMT
14/08/17 15:21:47 INFO manager.OracleManager: Time zone has been set to GMT
14/08/17 15:21:47 INFO mapreduce.ImportJobBase: Beginning import of ORD_UV
14/08/17 15:21:47 INFO manager.OracleManager: Time zone has been set to GMT
14/08/17 15:21:49 INFO db.DBInputFormat: Using read commited transaction isolation
14/08/17 15:21:49 INFO mapred.JobClient: Running job: job_201408151734_0027
14/08/17 15:21:50 INFO mapred.JobClient: map 0% reduce 0%
14/08/17 15:22:12 INFO mapred.JobClient: map 100% reduce 0%
14/08/17 15:22:17 INFO mapred.JobClient: Job complete: job_201408151734_0027
14/08/17 15:22:17 INFO mapred.JobClient: Counters: 18
14/08/17 15:22:17 INFO mapred.JobClient: Job Counters
14/08/17 15:22:17 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=15862
14/08/17 15:22:17 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
14/08/17 15:22:17 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
14/08/17 15:22:17 INFO mapred.JobClient: Launched map tasks=1
14/08/17 15:22:17 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
14/08/17 15:22:17 INFO mapred.JobClient: File Output Format Counters
14/08/17 15:22:17 INFO mapred.JobClient: Bytes Written=1472
14/08/17 15:22:17 INFO mapred.JobClient: FileSystemCounters
14/08/17 15:22:17 INFO mapred.JobClient: HDFS_BYTES_READ=87
14/08/17 15:22:17 INFO mapred.JobClient: FILE_BYTES_WRITTEN=33755
14/08/17 15:22:17 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=1472
14/08/17 15:22:17 INFO mapred.JobClient: File Input Format Counters
14/08/17 15:22:17 INFO mapred.JobClient: Bytes Read=0
14/08/17 15:22:17 INFO mapred.JobClient: Map-Reduce Framework
14/08/17 15:22:17 INFO mapred.JobClient: Map input records=81
14/08/17 15:22:17 INFO mapred.JobClient: Physical memory (bytes) snapshot=192405504
14/08/17 15:22:17 INFO mapred.JobClient: Spilled Records=0
14/08/17 15:22:17 INFO mapred.JobClient: CPU time spent (ms)=1540
14/08/17 15:22:17 INFO mapred.JobClient: Total committed heap usage (bytes)=503775232
14/08/17 15:22:17 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2699571200
14/08/17 15:22:17 INFO mapred.JobClient: Map output records=81
14/08/17 15:22:17 INFO mapred.JobClient: SPLIT_RAW_BYTES=87
14/08/17 15:22:17 INFO mapreduce.ImportJobBase: Transferred 1.4375 KB in 29.3443 seconds (50.1631 bytes/sec)
14/08/17 15:22:17 INFO mapreduce.ImportJobBase: Retrieved 81 records.
③数据导出Oracle和HBase
- 使用export可将hdfs中数据导入到远程数据库中
export --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password=** -m1table VEHICLE--export-dir /user/root/VEHICLE
- 向Hbase导入数据
sqoop import --connect jdbc:oracle:thin:@192.168.**.**:**:**--username**--password=**--m 1 --table VEHICLE --hbase-create-table --hbase-table VEHICLE--hbase-row-key ID --column-family VEHICLEINFO --split-by ID
5.6 测试Mysql数据库的使用
前提:导入mysql jdbc的jar包
①测试数据库连接
sqoop list-databases –connect jdbc:mysql://192.168.10.63 –username root–password 123456
②Sqoop的使用
以下所有的命令每行之后都存在一个空格,不要忘记
(以下6中命令都没有进行过成功测试)
<1>mysql–>hdfs
sqoop export –connect
jdbc:mysql://192.168.10.63/ipj
–username root
–password 123456
–table ipj_flow_user
–export-dir hdfs://192.168.10.63:8020/user/flow/part-m-00000
前提:
(1)hdfs中目录/user/flow/part-m-00000必须存在
(2)如果集群设置了压缩方式lzo,那么本机必须得安装且配置成功lzo
(3)hadoop集群中每个节点都要有对mysql的操作权限
<2>hdfs–>mysql
sqoop import –connect
jdbc:mysql://192.168.10.63/ipj
–table ipj_flow_user
<3>mysql–>hbase
sqoop import –connect
jdbc:mysql://192.168.10.63/ipj
–table ipj_flow_user
–hbase-table ipj_statics_test
–hbase-create-table
–hbase-row-key id
–column-family imei
<4>hbase–>mysql
关于将Hbase的数据导入到mysql里,Sqoop并不是直接支持的,一般采用如下3种方法:
第一种:将Hbase数据扁平化成HDFS文件,然后再由Sqoop导入.
第二种:将Hbase数据导入Hive表中,然后再导入mysql。
第三种:直接使用Hbase的Java API读取表数据,直接向mysql导入
不需要使用Sqoop。
<5>mysql–>hive
sqoop import –connect
jdbc:mysql://192.168.10.63/ipj
–table hive_table_test
–hive-import
–hive-table hive_test_table 或–create-hive-table hive_test_table
<6>hive–>mysql
sqoop export –connect
jdbc:mysql://192.168.10.63/ipj
–username hive
–password 123456
–table target_table
–export-dir /user/hive/warehouse/uv/dt=mytable
前提:mysql中表必须存在
③Sqoop其他操作
<1>列出mysql中的所有数据库
sqoop list-databases –connect jdbc:mysql://192.168.10.63:3306/ –usernameroot –password 123456
<2>列出mysql中某个库下所有表
sqoop list-tables –connect jdbc:mysql://192.168.10.63:3306/ipj –usernameroot –password 123456
6 Sqoop1的性能
测试数据:
表名:tb_keywords
行数:11628209
数据文件大小:1.4G
测试结果:
|
|
HDFS--->DB |
HDFS<---DB |
|
Sqoop |
428s |
166s |
|
HDFS<->FILE<->DB |
209s |
105s |
从结果上来看,以FILE作为中转方式性能是要高于SQOOP的,原因如下:
- 本质上SQOOP使用的是JDBC,效率不会比MYSQL自带的导入\导出工具效率高
- 以导入数据到DB为例,SQOOP的设计思想是分阶段提交,也就是说假设一个表有1K行,那么它会先读出100行(默认值),然后插入,提交,再读取100行……如此往复
即便如此,SQOOP也是有优势的,比如说使用的便利性,任务执行的容错性等。在一些测试环境中如果需要的话可以考虑把它拿来作为一个工具使用。
其他参考资料:使用Sqoop将HDFS/Hive/HBase与MySQL/Oracle中的数据相互导入、导出
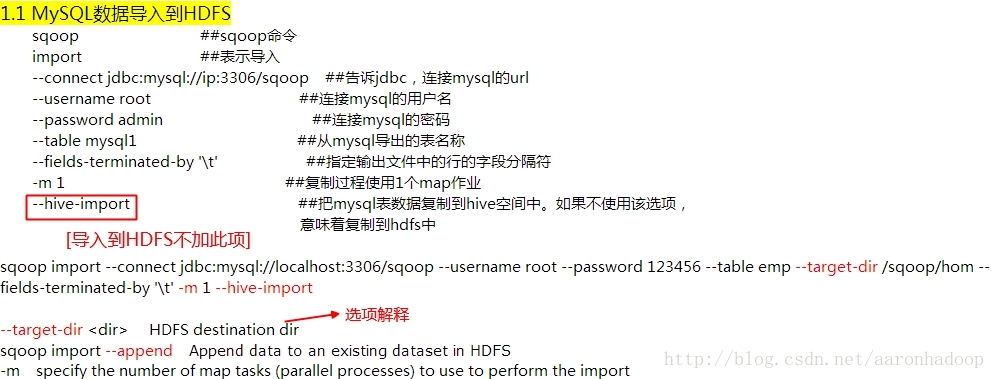
一、使用Sqoop将MySQL中的数据导入到HDFS/Hive/HBase


二、使用Sqoop将HDFS/Hive/HBase中的数据导出到MySQL


2.3 HBase中的数据导出到mysql
目前没有直接的命令将HBase中的数据导出到MySQL,但可以先将HBase中的数据导出到HDFS中,再将数据导出到MySQL。
三、使用Sqoop将Oracle中的数据导入到HDFS/Hive/HBase
下面只给出将Oracle中的数据导入HBase,其他情况下的命令行选项与MySQL的操作相似
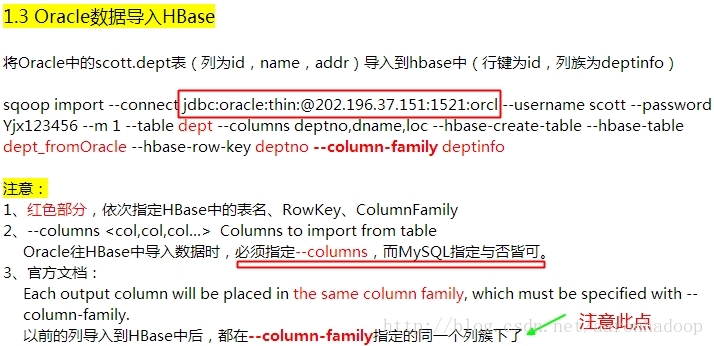
OK! 最好的文档尽在:http://sqoop.apache.org/docs/1.4.4/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号