
MySQL分区表
原创沐雨聼風 最后发布于2018-03-07 16:43:49 阅读数 5898 收藏
展开
分区不是在引擎层实现的,所以常见的引擎都支持,至少MyISAM和InnoDB是支持的。就访问数据库的程序而言,从逻辑上将,只有一个表或一个索引,但在物理上这个表或者索引可能由数十个物理分区组成。每个分区都是独立的对象,可以单独处理,也可以作为一个更大对象的一部分处理。
MySQL支持水平分区,即按行分区,不支持垂直分区。MySQL数据库的分区是局部分区索引,一个分区既存放数据也存放索引。
可通过如下命令查看当前数据库是否启用了分区功能。
show variables like '%partition%';
或者
show pulgins;
MySQL支持如下几种类型的分区
RANGE分区:行数据基于一个给定连续范围分区。不好理解,看例子吧。5.5开始支持RANGE COLUMNS分区。
LIST分区:同RANGE,区别在于给定的不是连续范围,是离散的值。5.5开始支持LIST COLUMNS分区。
HASH分区:根据用户自定义的表达式的返回值进行分区,返回值不能是负数。
KEY分区:根据MySQL内部提供的哈希函数进行分区。
COLUMNS分区:5.5开始支持,可以直接使用非整形的数据进行分区,分区根据类型直接比较而得,不需要转换为整形。看例子吧。
无论创建何种类型的分区,如果表中存在主键或唯一索引的列,则分区列必须是主键或唯一索引的一部分。索引列可以是null值。在没有主键和唯一索引的表中可以指定任意列为索引列。表中只能最多有一个唯一索引,即primary key 和unique key不能同时存在,primary key包含在unique key中时除外。下面是例子
有唯一索引,分区列必须是唯一索引的一部分,索引列也可以是null
create table t1(
col1 int(11),
col2 int(11),
col3 int(11) null,
unique key (col2, col3)
) partition by hash(col3) partitions 4;
没有唯一索引,可以指定任何列
create table t2(
col1 int(11),
col2 int(11),
col3 int(11)
) partition by hash(col1) partitions 4;
主键和唯一索引都存在,主键包含在唯一索引中,只能以主键进行分区
create table t100(
col1 int(11),
col2 int(11) null,
primary key(col1),
unique key (col2,col1)
) partition by hash(col1) partitions 2;
主键和唯一索引存在,主键没有包含在唯一索引中,不能创建,下面是错误的例子
create table t101(
col1 int(11),
col2 int(11) null,
primary key(col1),
unique key (col2)
) partition by hash(col1) partitions 2;
[Err] 1503 - A UNIQUE INDEX must include all columns in the table's partitioning function
create table t101(
col1 int(11),
col2 int(11) null,
primary key(col1),
unique key (col2)
) partition by hash(col2) partitions 2;
[Err] 1503 - A PRIMARY KEY must include all columns in the table's partitioning function
两个唯一索引列也不能创建分区
create table t102(
col1 int(11),
col2 int(11) null,
unique key(col1),
unique key (col2)
) partition by hash(col2) partitions 2;
[Err] 1503 - A UNIQUE INDEX must include all columns in the table's partitioning function
(这么多的限制,感觉这分区真没法用)
RANGE分区,直接看例子
create table t(
id int(11)
)engine=innodb
partition by range(id)(
partition p0 values less than(10),
partition p1 values less than(20)
);
查看表在磁盘上的物理文件,启用分区之后,表不再由一个ibd文件组成了,而是由建立分区时各个分区的ibd文件组成,如下图所示的,t#p#p0.ibd,t#p#p1.ibd。
插入数据
insert into t values(9),(10);
则9会被插入到p0分区,10会被插入的到p1分区。通过information_schema.PARTITIONS表查看每个分区的具体信息
select * from information_schema.PARTITIONS where table_schema=database() and table_name='t';
部分截图如下,其中分区PARTITION_METHOD表示分区类型,TABLE_ROWS反应每个分区的记录数量(图中未展示)
当插入不在分区中定义的值时,MySQL会报错,如插入30
insert into t select 30;
[Err] 1526 - Table has no partition for value 30
对于上述问题,我们可以创建一个MAXVALUES分区,MAXVALUES 可以理解为正无穷大,所有大于等于20的值就会插入到该分区,如下
create table t(
id int(11)
)engine=innodb
partition by range(id)(
partition p0 values less than(10),
partition p1 values less than(20),
partition p2 values less than(MAXVALUE)
);
RANGE分区主要用于日期列的分区,如销售类的表,可以根据年份来分区存放销售记录
create table sales(
money int(11) unsigned,
date datetime
)engine=innodb
partition by range (year(date))(
partition p2017 values less than(2018),
partition p2018 values less than(2019),
partition p2019 values less than(2020)
);
如果需要删除2018年的数据,不需要删除 delete from sales where date>='2018-01-01' and date<'2019-01-01',只需要删除2018分区就行了
alter table sales drop partition p2018;
可以加快某些查询操作,如查询2018年的销售记录
explain partition select * from sales where date<='2018-12-31' and date>='2018-01-01;
这样查询优化器只会搜索p2018这个分区,而不是搜索所有分区。下面这条语句则会搜索p2018和p2019这两个分区
explain partition select * from sales where date<'2019-01-01' and date>='2018-01-01;
对于sales这张表,如果按照每年每月来进行分区,有人这样设计表
create table sales(
money int(11) unsigned,
date datetime
)engine=innodb
partition by range (year(date)*100+month(date)(
partition p201801 values less than(201802),
partition p201802 values less than(201803),
partition p201803 values less than(201804)
);
但是在执行下面的sql语句时并不会进行查询优化,会搜索所有分区
explain partition select * from sales where date<='2018-03-31' and date>='2018-03-01';
产生这个问题的主要原是,对于 RANGE 分区的查询,优化器只能对 YEAR(), TO_DAYS(), TO_SECONDS(), UNIX_TIMESTAMP()这类函数进行优化。对于上面的要求,可以使用TO_DAYS()进行修改,如下
create table sales(
money int(11) unsigned,
date datetime
)engine=innodb
partition by range (to_days(date))(
partition p201801 values less than(to_days('2018-02-01'),
partition p201802 values less than(to_days('2018-03-01'),
partition p201803 values less than(to_days('2018-04-01')
);
LIST分区
LIST分区和RANGE分区非常相似,只是LIST分区的值是离散的。与RANGE分区的 VALUES LESS THAN 不同,LIST分区使用 VALUES IN,所以每个分区的值是离散的,只能是定义的值。如
create table t(
a int(11),
b int(11)
)engine=innodb
partition by list(b)(
partition p0 values in(1,3,5,7,9),
partition p1 values in(2,4,6,8,10)
);
同样,如果插入的值不在分区定义中,会报错
insert into t select 11;
[Err] 1526 - Table has no partition for value 11
用insert插入多个行数据的过程中如果遇到分区未定义的值时,MyISAM和InnoDB存储引擎的处理完全不同。MyISAM会将之前的行数据都插入,之后的行数据不会插入。InnoDB则会将其视为一个事务,不会插入任何行。
HASH分区
要使用HASH分区分割一个表,要在CREATE TABLE 语句上加一个 PARTITION BY HASH(expr)子句,其中expr是一个返回整数的表达式,如果没有PARTITIONS num子句,则默认的分区数量是1(没啥意义啊)。
看例子
create table t(
id int(11),
date datetime
)engine=innodb
partition by hash(year(date))
partitions 4;
如果插入日期为2018-03-07,保存该记录的分区如下
mod(year('2018-03-01'))=2
所以该记录会存放到分区 2 中。
MySQL数据库还支持一种LINEAR HASH的分区,他使用一个更复杂的算法来确定新行插入的分区。语法为 linear hash(expr),只是将关键字 HASH 换成了 LINEAR HASH。
对于LINEAR HASH分区类型的表,如果插入日期为2018-03-07,确定保存该记录的分区如下
(1)取大于分区数量4的下一个2的幂值V:V=power(2, celing(log(2, num)))=4;(num是分区数量partitions,本例中是4)
(2)分区N=year(date)&(V-1)
LINEAR HASH分区的优点是:增加、删除、合并和拆分分区变得更加快捷,这有利于处理含有大量数据的表。
缺点:与HASH分区相比,数据分布可能不大均匀。
(这个优缺点我也不懂)
KEY分区
KEY分区和HASH分区相似。KEY分区支持除text和BLOB之外的所有数据类型的分区,而HASH分区只支持数字分区,KEY分区不允许使用用户自定义的表达式进行分区,KEY分区使用系统提供的HASH函数进行分区。
在KEY 分区中使用LINEAR 和在HASH分区中一样,分区的编号是通过2的幂(powers-of-two)算法得到的,而不是取模算法。(看不懂)
原文链接:https://blog.csdn.net/u010320108/article/details/79460748
https://www.cnblogs.com/wy123/p/9778590.html
分区的作用
分区是将一个表的数据按照某种方式,比如按照时间上的月份,分成多个较小的,更容易管理的部分,但是逻辑上仍是一个表。
个人理解起来,分区跟性能没有必然关系,分区更多的是从管理的角度出发的。
MySQL分区表对分区字段的限制
分区的字段,必须是表上所有的唯一索引(或者主键索引)包含的字段的子集
换句话说就是:(所有的)字段必须出现在(所有的)唯一索引或者主键索引的字段中,
或者更通俗讲就是,一个表上有一个或者多个唯一索引的情况下,分区的字段必须被包含在所有的主键或者唯一索引字段中。
关于这个限制,笔者是根据官方文档中的示例,理解了好久,以下参考官方的示例。
示例1(如下语句报错,无法创建分区表):

CREATE TABLE t1 ( col1 INT NOT NULL, col2 DATE NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, UNIQUE KEY (col1, col2) ) PARTITION BY HASH(col3) PARTITIONS 4;
分区字段是col3, 主键是(col1, col2),col3没有出现在主键字段中,因此不满足“分区的字段,必须是唯一索引字段的子集”,无法创建分区表
如果要想按照col3分区,可以把col3加入到unique key中。
示例2(如下语句报错,无法创建分区表):
CREATE TABLE t2 ( col1 INT NOT NULL, col2 DATE NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, PRIMARY KEY (col1), UNIQUE KEY (col3) ) PARTITION BY HASH(col1 + col3) PARTITIONS 4;
分区字段是col1 + col3, 两个unique key分别是col1和col3,分区字段没有出现在任何一个unique(primary) key中,因此无法按照(col1 + col3)分区
如果要想按照ccol1 + col3,分区,创建一个col1 + col3的unique key(唯一索引),如果是col1+col3的唯一索引,那只能有一个了,不能两个unique key的字段完全一致。
因此分区字段是 “所有的(如果有多个)” “索引唯一索引(或者主键索引)”的中字段的子集(或者全集)。
示例3(如下语句报错,无法创建分区表):
如下情况下,无法为t4表分区,因为有两个唯一索引,且唯一索引的字段没有交集,
那么任何情况下,都不符合:分区字段是 “所有的(如果有多个)” “索引唯一索引(或者主键索引)”的子集(或者全集)
CREATE TABLE t4 ( col1 INT NOT NULL, col2 INT NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, UNIQUE KEY (col1, col3), UNIQUE KEY (col2, col4)、 );
MySQL是局部分区,意思是一个分区中,包含分区的数据和其对应的索引,而不是索引是一个索引统一存放在一个地方,仅分区数据这种方式。
想一下,为什么MySQL的分区表会有这个么一个奇怪的要求:一个表上有一个或者多个唯一索引的情况下,分区的字段必须被包含在所有的主键或者唯一索引字段中?
分区类型
range分区,分区字段必须是整型或者转换为整型
按照字段的区间划分数据的归属,典型的就是按照时间维度的月份分区
CREATE TABLE test_range_partition(
id INT auto_increment,
createdate DATETIME,
primary key (id,createdate)
)
PARTITION BY RANGE (TO_DAYS(createdate) ) (
PARTITION p201801 VALUES LESS THAN ( TO_DAYS('20180201') ),
PARTITION p201802 VALUES LESS THAN ( TO_DAYS('20180301') ),
PARTITION p201803 VALUES LESS THAN ( TO_DAYS('20180401') ),
PARTITION p201804 VALUES LESS THAN ( TO_DAYS('20180501') ),
PARTITION p201805 VALUES LESS THAN ( TO_DAYS('20180601') ),
PARTITION p201806 VALUES LESS THAN ( TO_DAYS('20180701') ),
PARTITION p201807 VALUES LESS THAN ( TO_DAYS('20180801') ),
PARTITION p201808 VALUES LESS THAN ( TO_DAYS('20180901') ),
PARTITION p201809 VALUES LESS THAN ( TO_DAYS('20181001') ),
PARTITION p201810 VALUES LESS THAN ( TO_DAYS('20181101') ),
PARTITION p201811 VALUES LESS THAN ( TO_DAYS('20181201') ),
PARTITION p201812 VALUES LESS THAN ( TO_DAYS('20190101') )
);
insert into test_range_partition (createdate) values ('20180105');
insert into test_range_partition (createdate) values ('20180205');
insert into test_range_partition (createdate) values ('20180206');
insert into test_range_partition (createdate) values ('20180305');
insert into test_range_partition (createdate) values ('20180405');
insert into test_range_partition (createdate) values ('20180505');
insert into test_range_partition (createdate) values ('20180605');
insert into test_range_partition (createdate) values ('20180705');
insert into test_range_partition (createdate) values ('20180805');
insert into test_range_partition (createdate) values ('20180905');
insert into test_range_partition (createdate) values ('20181005');
insert into test_range_partition (createdate) values ('20181105');
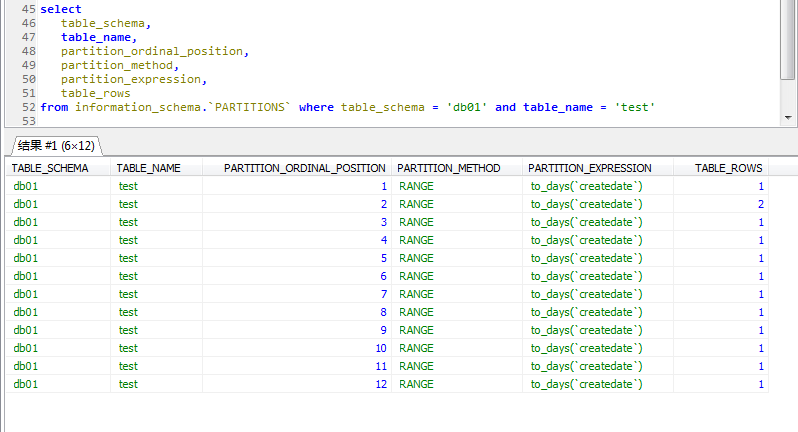
select
table_schema,
table_name,
partition_name,
partition_ordinal_position,
partition_method,
partition_expression,
table_rows
from information_schema.`PARTITIONS` where table_schema = 'db01' and table_name = 'test_range_partition';
对应的物理文件
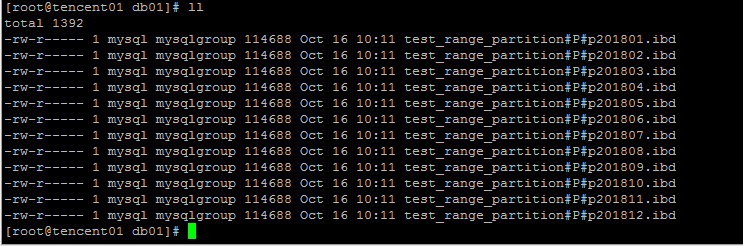
查看每个分区的信息
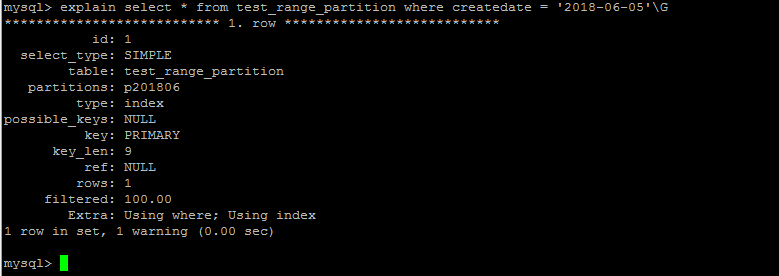
分区在查询中的优化体现
并不是说一个表只要分区了,对于任何查询都会实现查询优化,只有查询条件的数据分布在某一个分区的时候,查询引擎只会去某一个分区查询,而不是遍历整个表
在管理层面,如果需要删除某一个分区的数据,只需要删除对应的分区即可
增加与删除分区
ALTER TABLE test ADD PARTITION (PARTITION p201902 VALUES LESS THAN ( TO_DAYS('20190301') ));
ALTER TABLE test DROP PARTITION p20180201;
对于range分区,分区字段必须是整型或者转换为整型,如果分区字段是日期类型的字段,那么就必须将日期类型的字段转换成整型类型
对于日期类型的转换,优化器只支持year(),to_days,to_seconds,unix_timestamp()函数的转换,其他的并不支持,
也就是说,在按日期字段分区的时候,如果不是使用上述几个函数转换的,查询优化器将无法对相关查询进行优化。
List分区,分区字段必须是整型或者转换为整型
按照某个字段上的规则,不同的数据离散地分布在不同的区中。
create table test_list_partiotion
(
id int auto_increment,
data_type tinyint,
primary key(id,data_type)
)partition by list(data_type)
(
partition p0 values in (0,1,2,3,4,5,6),
partition p1 values in (7,8,9,10,11,12),
partition p2 values in (13,14,15,16,17)
);
对于List分区,分区字段必须是已知的,如果插入的字段不在分区时枚举值中,将无法插入
Hash分区,分区字段必须是整型或者转换为整型
Hash分区可以将数据均匀地分不到预先定义的分区中,使得各个分区的数据量分布基本上一致。同样,分区字段必须是整型或者转换为整型
drop table test_hash_partiotion;
create table test_hash_partiotion
(
id int auto_increment,
create_date datetime,
primary key(id,create_date)
)partition by hash(year(create_date)) partitions 10;
一个很明显的问题就是,如果分区字段本身的分布不匀均,那么hash分区之后存储的分区也是不均匀的,hash分区时对于hash的字段,需要慎重。
对于单个值的查询hash分区可以定位到某一个分区
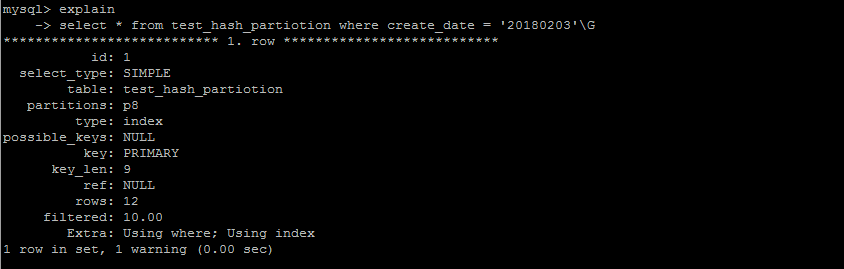
hash分区在查询优化方面,无法优化范围查询,因为无法确定一个某个字段经过hash计算之后究竟分布了在哪个分区之中。
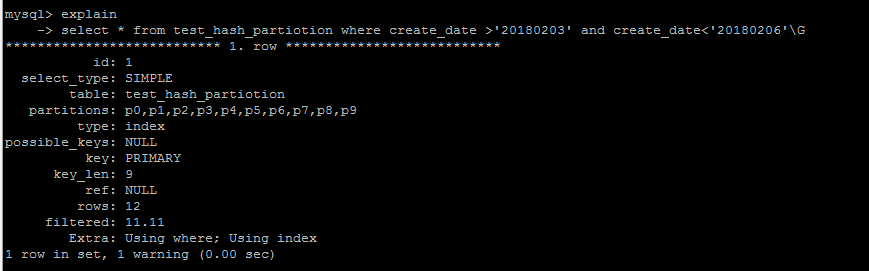
Key分区,分区字段必须是整型或者转换为整型
与hash分区不用的是,key分区使用MySQL自定义的库函数进行分区,不需要hash分区那样对字段整型进行转换,同样,分区字段必须是整型或者转换为整型
create table test_key_partiotion
(
id int auto_increment,
create_date datetime,
primary key(id,create_date)
)partition by key(create_date) partitions 10;
对于查询优化,Key分区的特点与Hash分区一致,对于单个字段可以
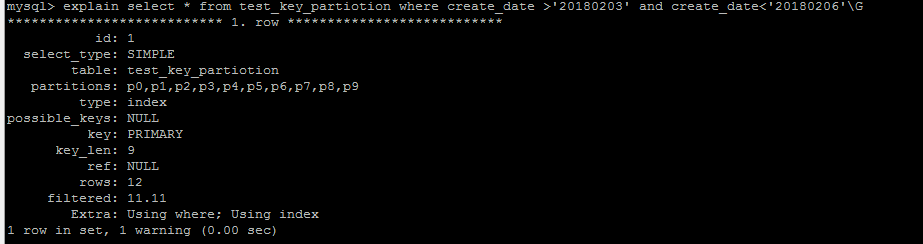
column 分区
解决了分区字段必须是整型或者必须转换为整型的限制,可以对整型,date或者datetime进行支持。
create table test_column_partiotion
(
id int auto_increment,
data_type datetime,
primary key(id,data_type)
)partition by range columns(data_type) (
partition p0 values less than ('20180101'),
partition p1 values less than ('20180201'),
partition p2 values less than ('20180301'),
partition p3 values less than ('20180401'),
partition p4 values less than ('20180501'),
partition p5 values less than ('20180601'),
partition p6 values less than ('20180701'),
partition p7 values less than ('20180801')
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号