


MySQL学习目录
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
如果查询语句不包含最左边的索引字段,则不会命中该索引,即该索引失效(这里是全部失效)。
如果查询条件中跳过了某一列而选取后边索引列,索引将部分失效(后面的字段索引会失效,失效部分将做那部分的全部数据遍历)。
追其原因,是因为在创建索引时,根据索引列的位置,逐次添加索引,并遵循B+Tree的排序规则。
查询条件中,各个索引字段的位置可以不一致,即前后位置随意,查询条件中存在索引字段即可。
索引失效的情况
1.范围查询
联合索引中,出现范围查询(<,>),范围查询右侧的列索引失效。但是如果是>=或者<=的话,右侧索引仍有效。
2.索引列运算
不再在索引列上进行运算操作,否则索引将失效。


3.字符串类型的索引查询条件不加引号
字符串类型字段的索引在使用时,不加引号,索引将失效

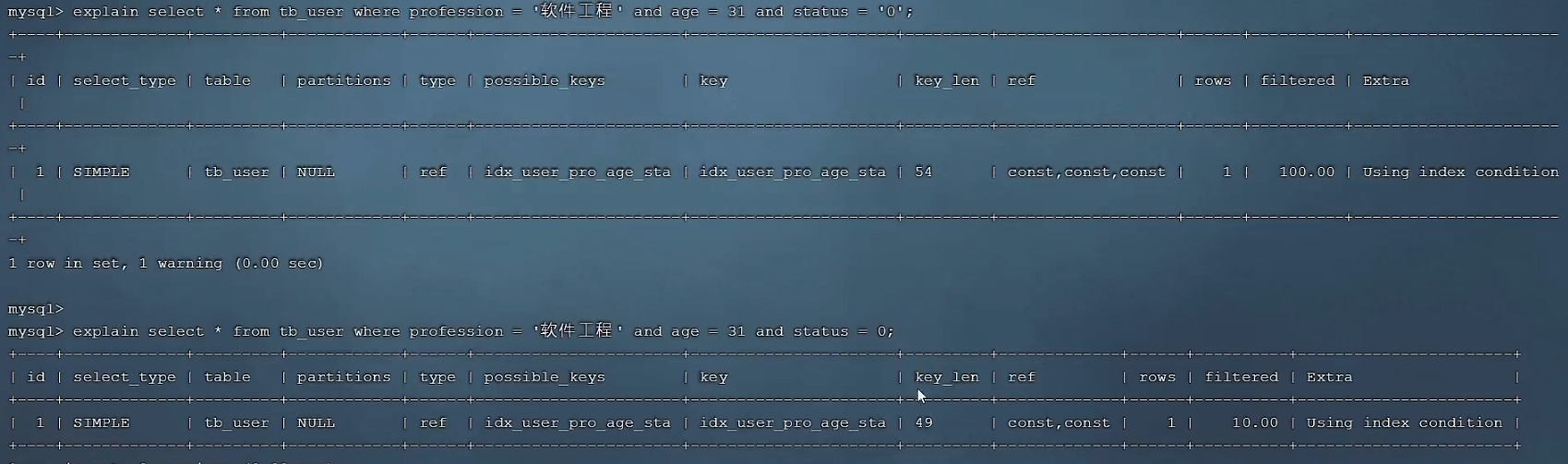
4.模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。

5. OR连接的查询条件
用OR分割开的条件,如果OR前的条件中列有索引,而后边的列中没有索引,那么涉及的索引都不会被用到。
只有OR前后的两个查询条件都有索引时,索引才会生效。这其中说的有索引是会命中的索引,比如联合查询中只有非最左的那种不算。
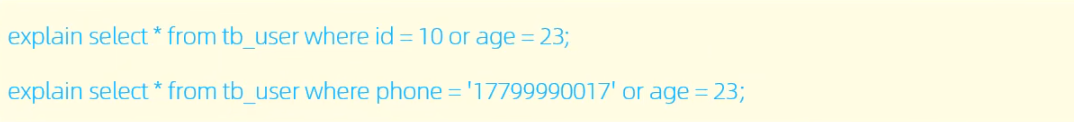
由于age没有索引,所以即使id,phone有索引,索引页会失效。所以需要针对于age也要建立索引。
6.数据分布影响
如果MySQL评估使用索引比全表扫描更慢,则不使用索引。
假如某种条件下,筛选出的结果大多数都满足条件时,MySQL会自动放弃索引,直接全表扫描。索引使用原则:
SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句种加入一些人为的提示,来达到优化操作的目的。
1.use index:
explain select* from tb_user use index(idx_user_pro) where profession='软件工程';
2.ignore index:
explain select * from tb_user ignore index(idx_user_pro) where profession='软件工程';
3.force index:
explain select * from tb_user force index(idx_user_pro) where profession='软件工程';




覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引种已经全部能够找到),减少select *。
这里说的情况是,在实际场景中确实不需要其他非索引字段的时候,也就是说,索引中的字段返回了足够业务来使用。也就是说能够在二级索引中自己搞定的事儿,尽量别回表到主键索引中在查一次了。
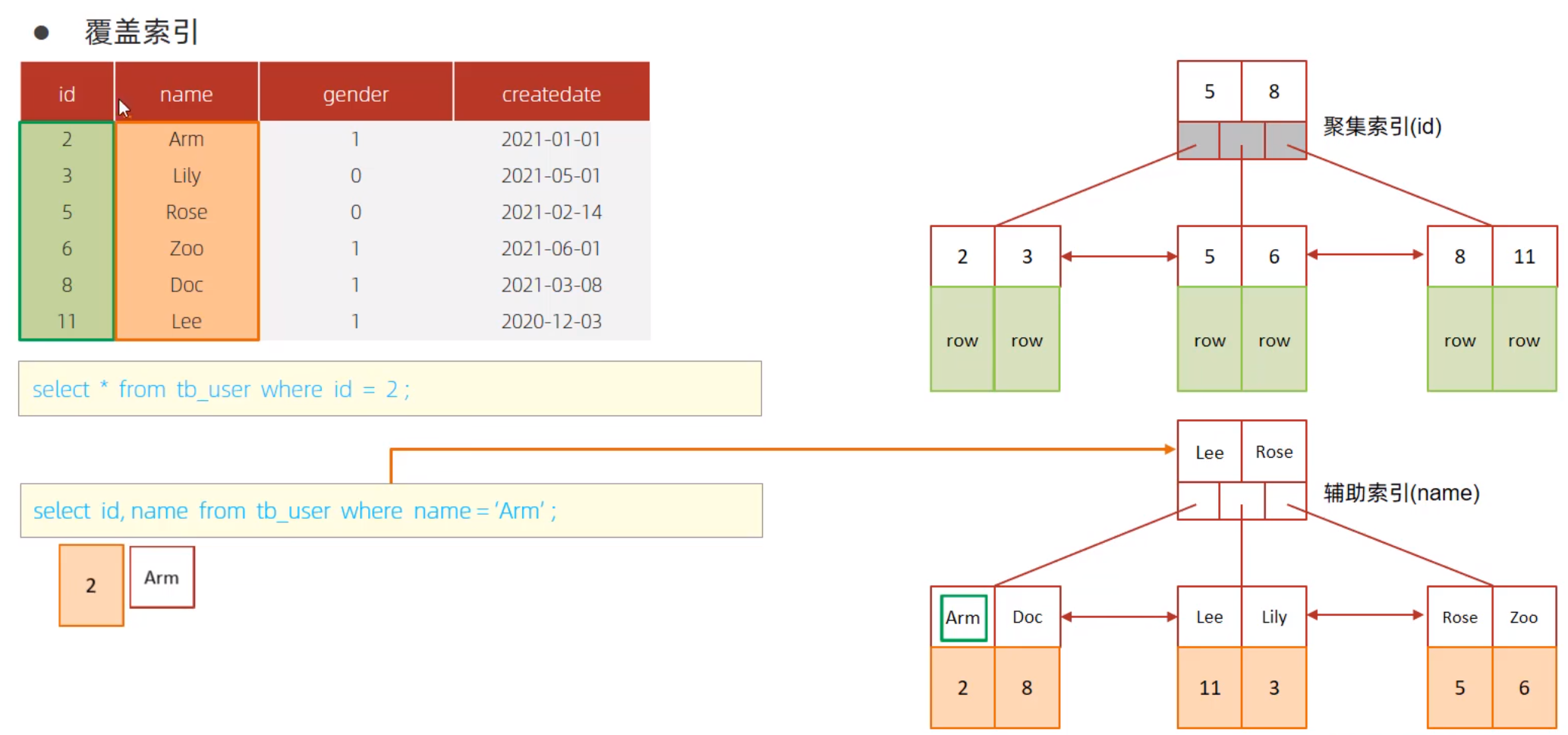
Extra 列中如果出现using index condition:查找使用了索引,但是需要回表查询数据
Extra 列中如果出现using where;using index;查询使用了索引,但是需要的数据都在索引列中能找到,所以不需要徽标查询数据。

创建username,password的联合索引。
前缀索引
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
前缀长度:
可以根据所以的选择性来决定,而选择性时值不重复的索引值(基数)和数据表的记录总数的壁纸,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
创建索引时,如果索引值太长,可以截取索引值的一部分作为索引,语法实例如下:
create index idx_email_5 on tb_user(email(5)); // 意思就是给tb_user表的email字段创建截图前5个字符作为索引

在使用前缀索引的时候,查询参数的值可以比索引的值长,MySQL会自动去处理。
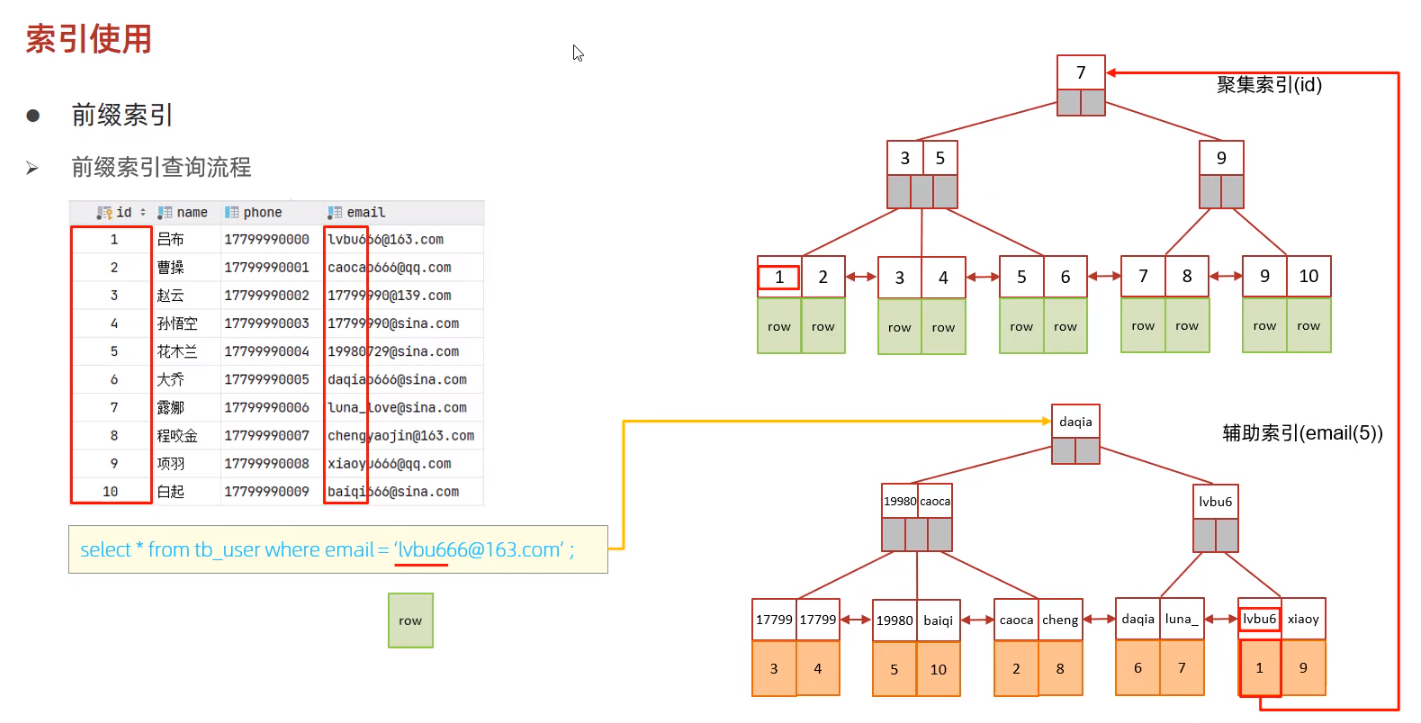
前缀索引查找顺序解释:
首先根据传入的参数,截取前五位作为二级索引的索引值去查询相关数据,经过B+Tree的比值获取到相关索引值对应的id,然后根据id回表查询出相应的行数据,
之后根据返回的行,再次比对传入的参数(email这个参数的全部值,不再是截取值),如果比对结果为符合,则返回数据,比对结果不符合,那么就是无结果。
单列索引和联合索引的选择
在实际业务场景中,如果存在多个查询条件,考虑针对查询字段建立索引时,建议建立联合索引,而非单列索引。
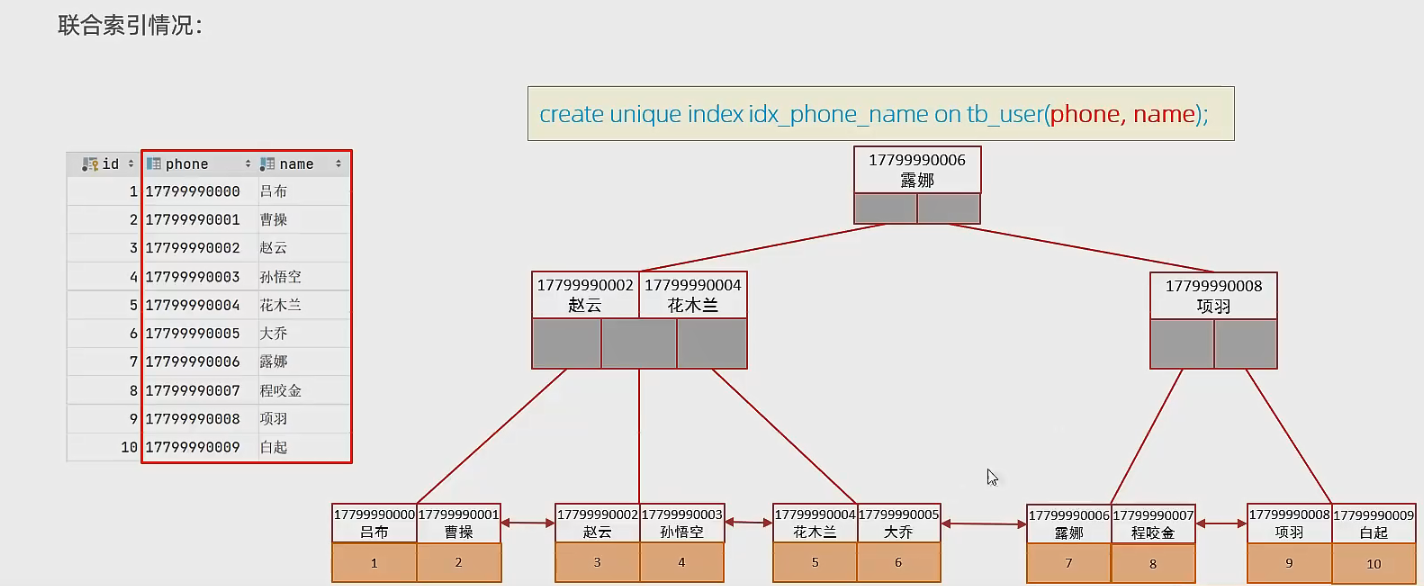
联合索引建立索引时,先根据第一个字段进行排序,如果第一字段值相同,那么在对第二个字段进行排序。
索引的设计原则:
1.针对于数据量较大,且查询比较频繁的表建立索引。
2.针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3.尽量选择却分度高的列作为索引,尽量建议唯一索引,区分度越高,使用索引 效率越高。
4.如果时字符串类型的字段,字段的长度较长,可以针对于字段的特点,使用前缀索引。
5.尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6.要控制索引的数量,索引并不是越多越好,索引越多,维护索引结构的代价就越大,会影响增删改的效率。
7.如果索引列不能存储Null值,在创建表时应该使用NOT NULL约束。当优化器知道每列是否包含NUll值时,它可以更好的确定哪个索引最有效的用于查询。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!