
MySQL学习目录
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。

索引的优点:
1.提高数据检索的效率,降低数据库的IO成本
2.通过索引列对数据进行排序,降低数据排序的成本呢,降低CPU的消耗
索引的缺点:
1.索引列也是要占用空间的(实际生成时,这个可以忽略,磁盘成本较低)
2.索引大大提高了查询效率,同时却也降低了更新表的速度,如对表进行INSERT,UPDATE,DELETE时,效率降低
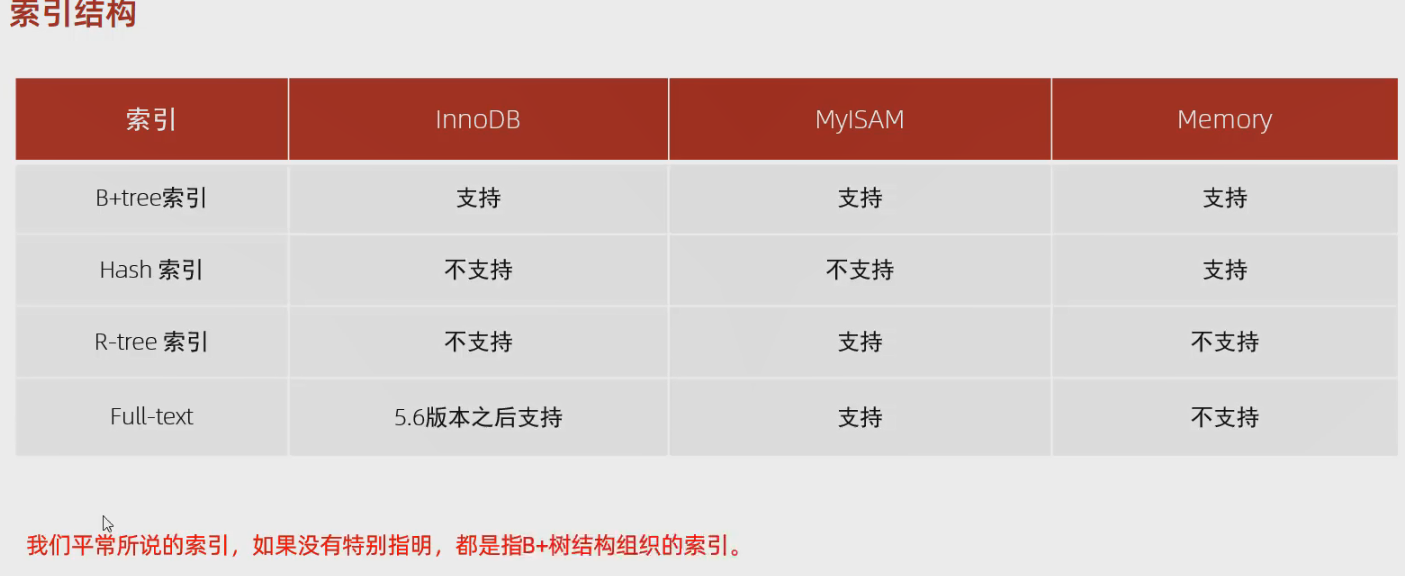
索引结构

基础结构-二叉树
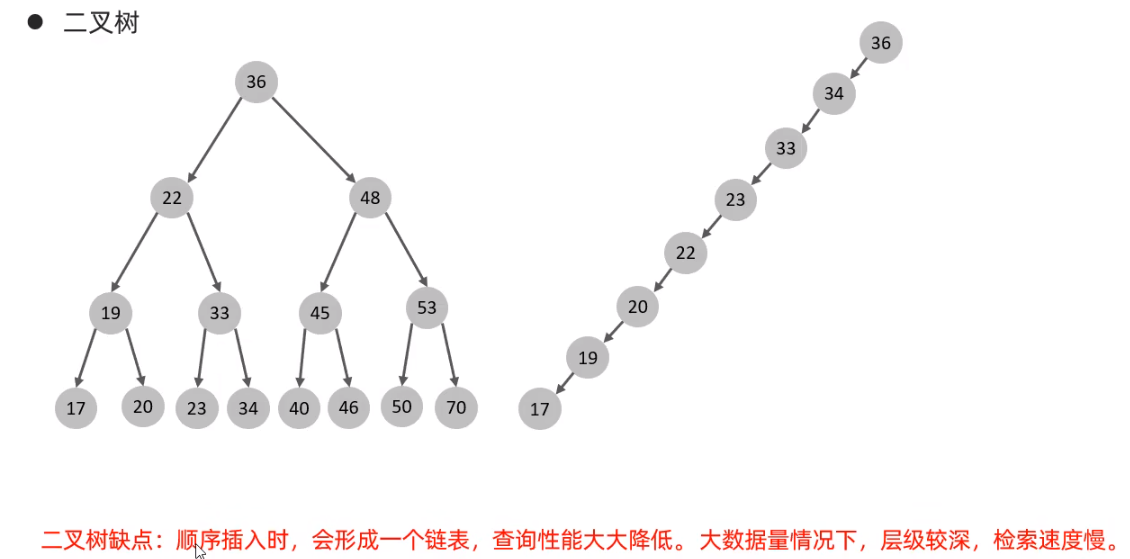
解决二叉树顺序插入形成链表的问题,引入了红黑树(自平衡二叉树),但是红黑树并没有解决数据量大时,层级较深,检索速度慢的问题。
为了解决层级较深(即树高)的问题,引入了B-Tree的概念。
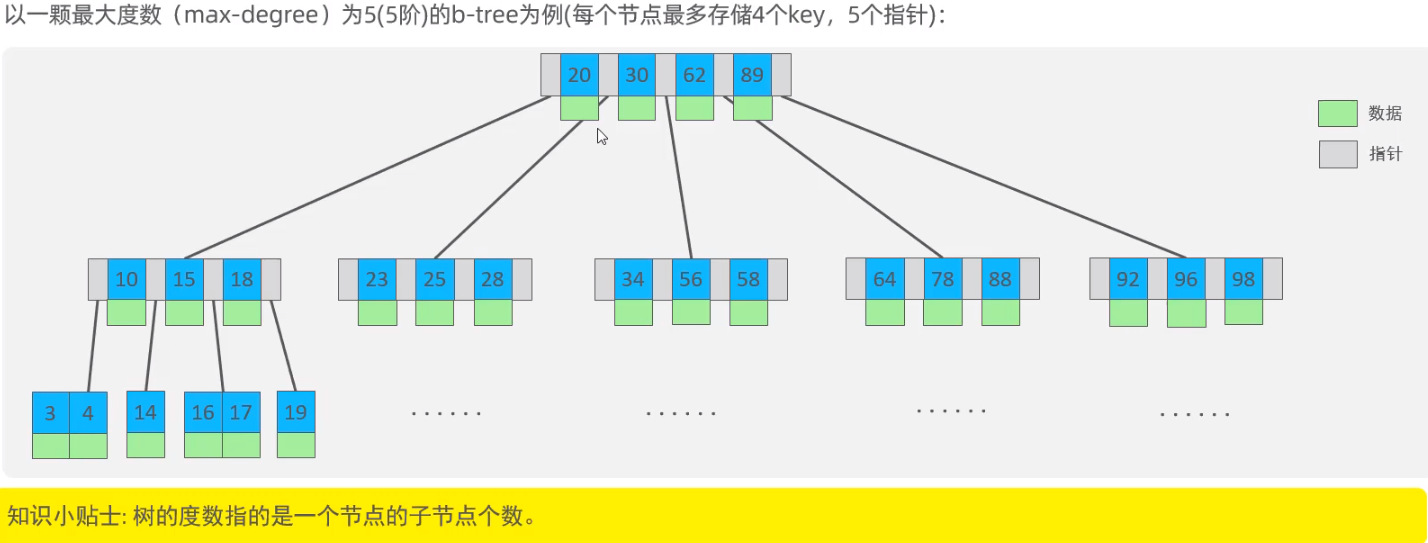
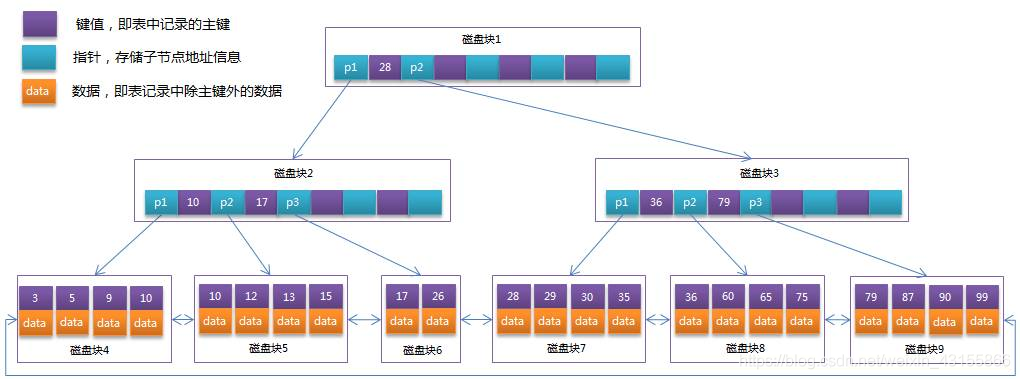
B-Tree (多路平衡查找树)【其中多路指的是一个节点多个key,对应的分支也是多个】
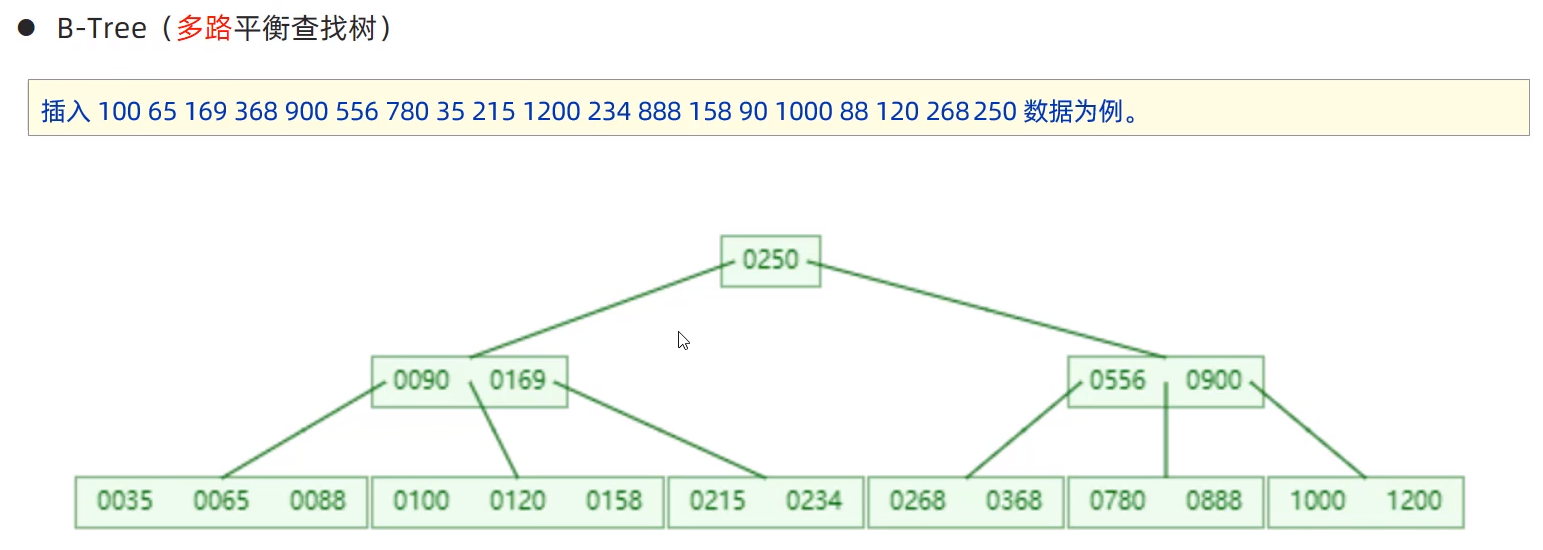
B-Tree 每个节点都挂在数据。
中间元素向上分裂。向上分裂时,如果上一层的节点树不够度数,就加到上一层对应的节点上,如果够就要进行再次分裂。
B+Tree
特点:
1.所有的元素都会出现再叶子节点,即叶子节点包含所有的索引值。非叶子节点只起到索引的作用。非叶子节点不存放数据。
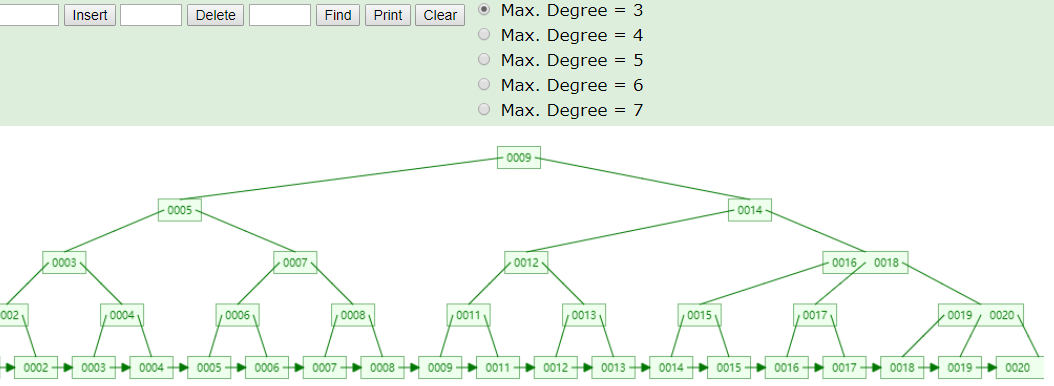
2.叶子形成了一个单向链表。(但实际上MySQL InnoDB 实现B+Tree的时候,是一个双向链表)可查看引申知识1
MySQL索引数据结构对经典的B+Tree进行了优化,增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
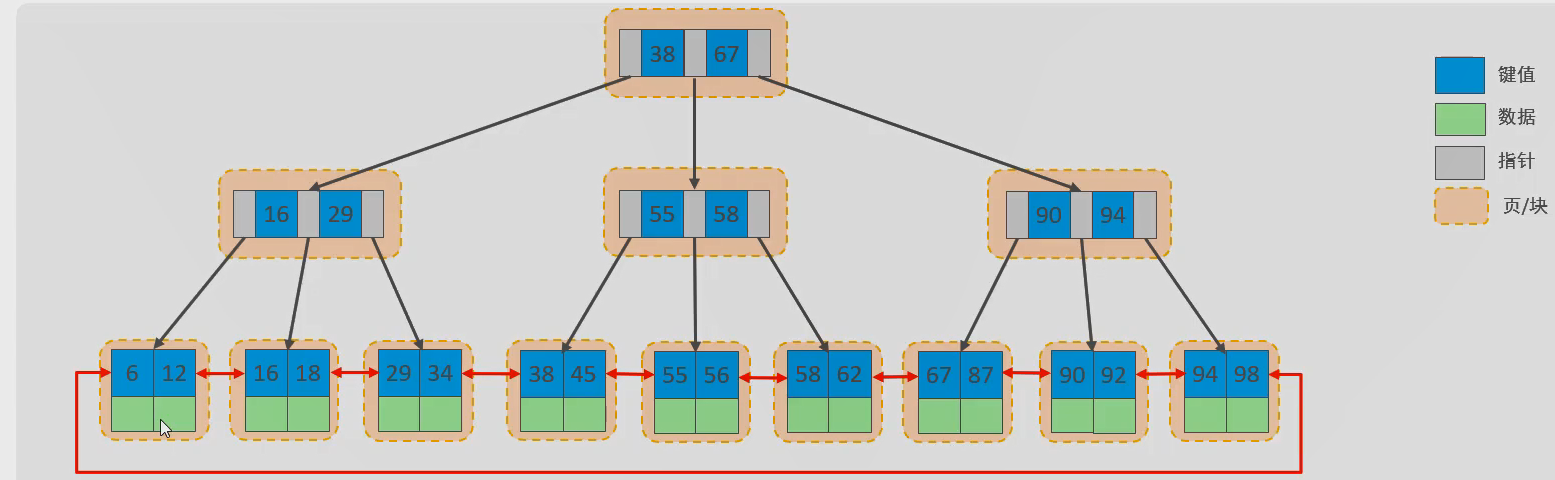
Hash索引
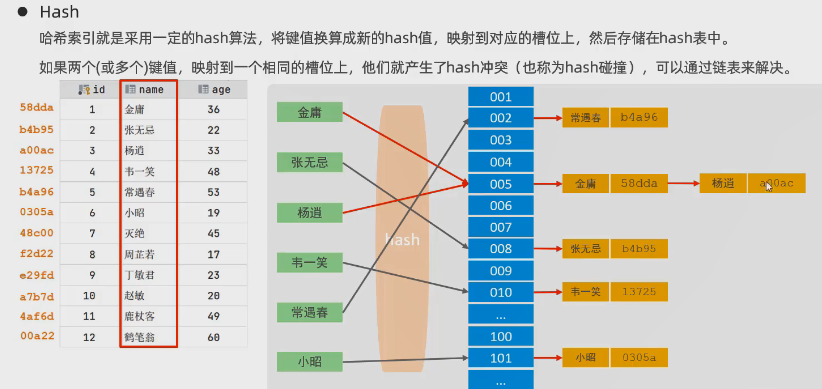
Hash索引的特点:
1.Hash索引只能用于对等比较(=,in),不支持范围查找(between,>,<....)
2.无法利用索引完成排序操作
3.查询效率高,通常只需要一次检索就i可以查到对应数据(不发生hash碰撞的时候),效率通常要高于B+Tree索引
在MySQL中,支持Hash索引的是Memory引擎,而InnoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。(详细原理可查看引申知识2)
引申知识:
1.InnoDB的叶子节点到底是单向链表还是双向链表
页的概念
Mysql的innodb是以页为存储单位的,每个B+Tree的叶子节点都是一个页的大小的倍数,默认一页的大小是16K
页结构如下图所示
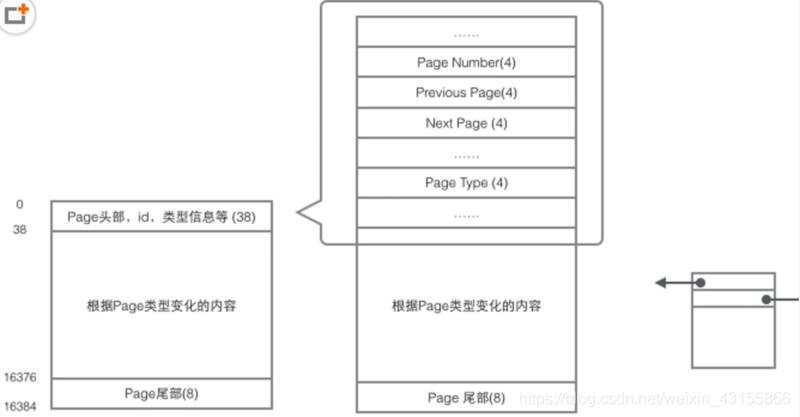
也就是每一个页都包含两个页指针,一个是previous page指针,指向上一个页,一个是next page指针,指向下一个页。
头部还有Page的类型信息和用来唯一标识Page的编号。根据这个指针分布可以想象到Page链接起来就是一个双向链表。
如下图所示
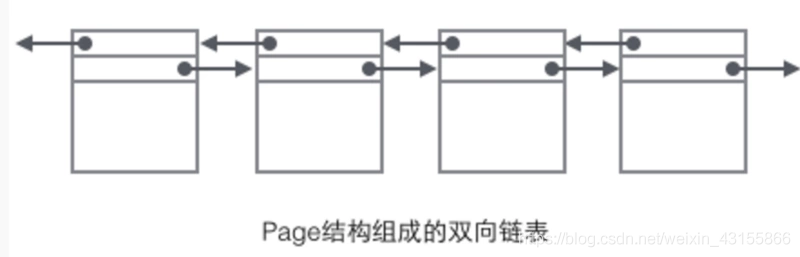
由于一个B+Tree的叶子节点是一个页,所以每个叶子节点之间是一个双向链表的结构。
———————————--------------------------分割线------------------------———————————————
2.自适应hash索引原理
1、原理过程
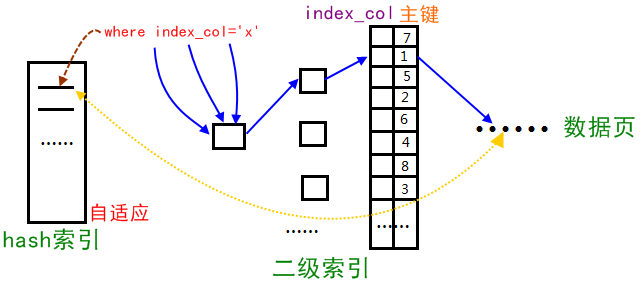
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升,则:
1、自适应hash索引功能被打开
mysql> show variables like '%ap%hash_index'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_adaptive_hash_index | ON | +----------------------------+-------+ 1 row in set (0.01 sec)
2、经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
2、特点
1、无序,没有树高
2、降低对二级索引树的频繁访问资源
索引树高<=4,访问索引:访问树、根节点、叶子节点
3、自适应
3、缺陷
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读。
三、监控与关闭
1、状态监控
mysql> show engine innodb status\G …… Hash table size 34673, node heap has 0 buffer(s) 0.00 hash searches/s, 0.00 non-hash searches/s
1、34673:字节为单位,占用内存空间总量
2、通过hash searches、non-hash searches计算自适应hash索引带来的收益以及付出,确定是否开启自适应hash索引
2、限制
1、只能用于等值比较,例如=, <=>,in
2、无法用于排序
3、有冲突可能
4、MySQL自动管理,人为无法干预。
3、自适应哈希索引的控制
由于innodb不支持hash索引,但是在某些情况下hash索引的效率很高,于是出现了adaptive hash index功能,但是通过上面的状态监控,可以计算其收益以及付出,控制该功能开启与否。
默认开启,建议关掉,意义不大。可以通过 set global innodb_adaptive_hash_index=off/on 关闭和打开该功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号