

| 课程 | 软件工程1916|W(福州大学) |
| 作业要求 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对博客 | 221600426 221600401 |
| Github基础需求项目地址 | 221600426 221600401 |
| Github进阶需求项目地址 | 221600426 221600401 |
| 作业目标 | 实现一个能够对文本文件中的单词的词频进行统计的控制台程序,并能在基本需求实现的基础上,通过爬取CVPR2018官网并进行顶会热词统计 |
| 具体分工 | 221600426负责主要代码的编写,221600401负责学习爬虫和博客的撰写 |
Github的代码签入记录:


PSP表格
|||
-------- | ---|----|-----
PSP2.1|Personal Software Process Stages|预估耗时(分钟)|实际耗时(分钟)
Planning|计划|2400|2650
Estimate|估计这个任务需要多少时间|2400|2650
Development|开发|720|900
Analysis|需求分析 (包括学习新技术)|100|150
Design Spec|生成设计文档|60|70
Design Review|设计复审|60|80
Coding Standard|代码规范 (为目前的开发制定合适的规范)|30|20
Design|具体设计|180|220
Coding|具体编码|770|850
Code Review|代码复审|120|100
Test|测试(自我测试,修改代码,提交修改)|120|70
Reporting|报告|60|70
Test Repor|测试报告|30|40
Size Measurement|计算工作量|30|25
Postmortem & Process Improvement Plan|事后总结, 并提出过程改进计划|120|55
|合计|2400|2650
解题思路描述:即刚开始拿到题目后,如何思考,如何找资料的过程
首先是语言的选择,由于221600426较常做LeetCode题,以及较常使用.net,所以开头是打算使用C++来开发的,后来较详细的分析了需求后发现对于此题,我们可能会需要用到大量的正则表达式以及爬虫,java有大量的类库以及前人的经验,所以最终选择用java来实现。然后是爬虫框架的选择,goole了一下,搜到较多的jsoup实现爬虫的相关信息,因此我们就选择了学习jsoup;分析程序要实现的基本功能,后确认至少需要有三个接口(字符计数,行计数,单词计数),将其封装成一个类不妨称为WordsHandler,最后针对每一个功能进行编码的实现,以及进行模块测试,确保独立模块稳定,再进行拼接以及整体测试。基本功能实现后就可以考虑进阶需求,先在jsoup Cookbook(中文版)学习jsoup,然后边学边写爬虫,最后在基础功能之上通过小修改即可实现进阶需求。
基础需求设计实现过程:
-
代码如何组织 :
共需两个类,一个程序入口Main,一个文本处理WordsHandler。Main实例化一个WordsHandler,该实例在调用其接口charCnt,lineCnt,wordCnt进行字符,有效行数,单词数统计,最后调用printInfo进行输出。 -
单元测试的设计 :
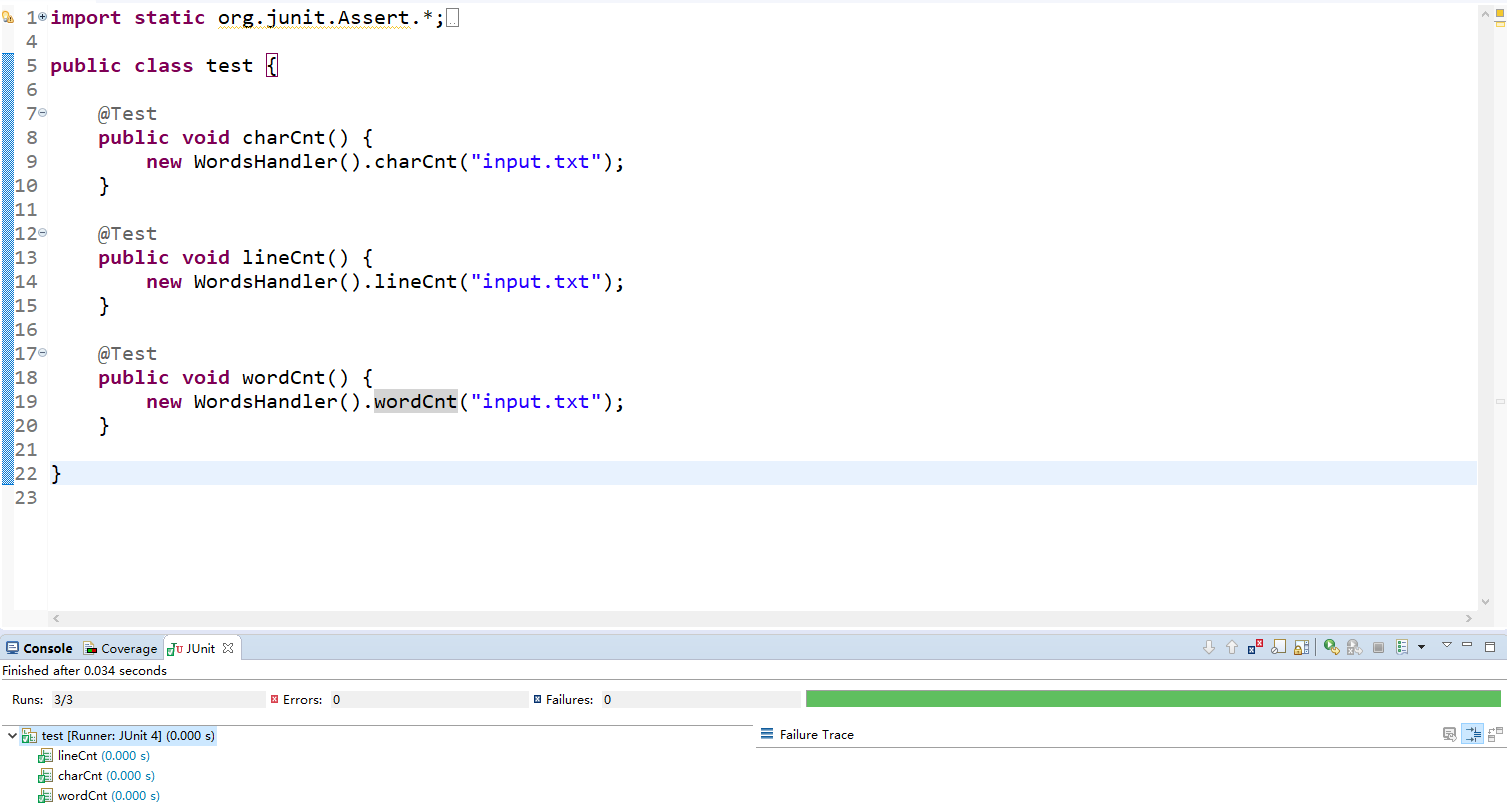
-
代码组织与内部实现设计(类图) :

-
算法的关键与关键实现部分流程图 :
基础需求较为简单,硬要找到算稍微难点的,应该是wordCnt的实现。该接口接收一行字符串,首先用正则表达式"[^a-zA-Z0-9]"匹配非字母数字符号的位置,分割出所有的可能单词(存在不符合题目定义"必须4个字母开头"),然后把所有单词转为小写,并遍历单词数组,如果该词匹配正则"[a-z]{4}[a-zA-Z0-9]*"则它就是题目定义的单词,那么就把单词总数+1,并判断单词map中是否存在以该单词为key的二元组,若不存在则将单词作为key,并用1作为value存入map,否则在对应key的位置将其value+1。
//单词数统计
public void wordCnt(String line) {
String arr[]=line.split("[^a-zA-Z0-9]"); //分割出潜在的单词
tolowerCase(arr);
for(int i=0;i<arr.length;++i) {
//System.out.println(arr[i]);
if(arr[i].matches("[a-z]{4}[a-z0-9]*")) {//判断是否是单词
wordCnt++;
if(!wordCntMap.containsKey(arr[i])) {
wordCntMap.put(arr[i], 1);
}else {
wordCntMap.put(arr[i], wordCntMap.get(arr[i])+1);
}
}
}
}

进阶需求设计实现过程:
-
代码如何组织 :
wordCount进阶设计了三个类,分别是Main,WordsHandler,Option。Main是程序的入口,实例化一个Option对象,调用该对象的getOption接口获取操作参数;然后实例化一个WordsHandler对象,调用该对象的readFile读取文件,并在每读取一行后调用charCnt,lineCnt,wordCnt进行字符,有效行数,单词总数统计,若m>1则调用worsCnt进行词组统计。最后调用writeFile进行输出。爬虫采用两个类,分别是Main,Handler。Main实例化一个Handler,在获取到目标所有链接后,筛选出具有”content_cvpr_2018/html/“头部的链接,并使用线程池调用Handle对象的同步方法writeFile进行论文爬取并输出。 -
单元测试的设计 :
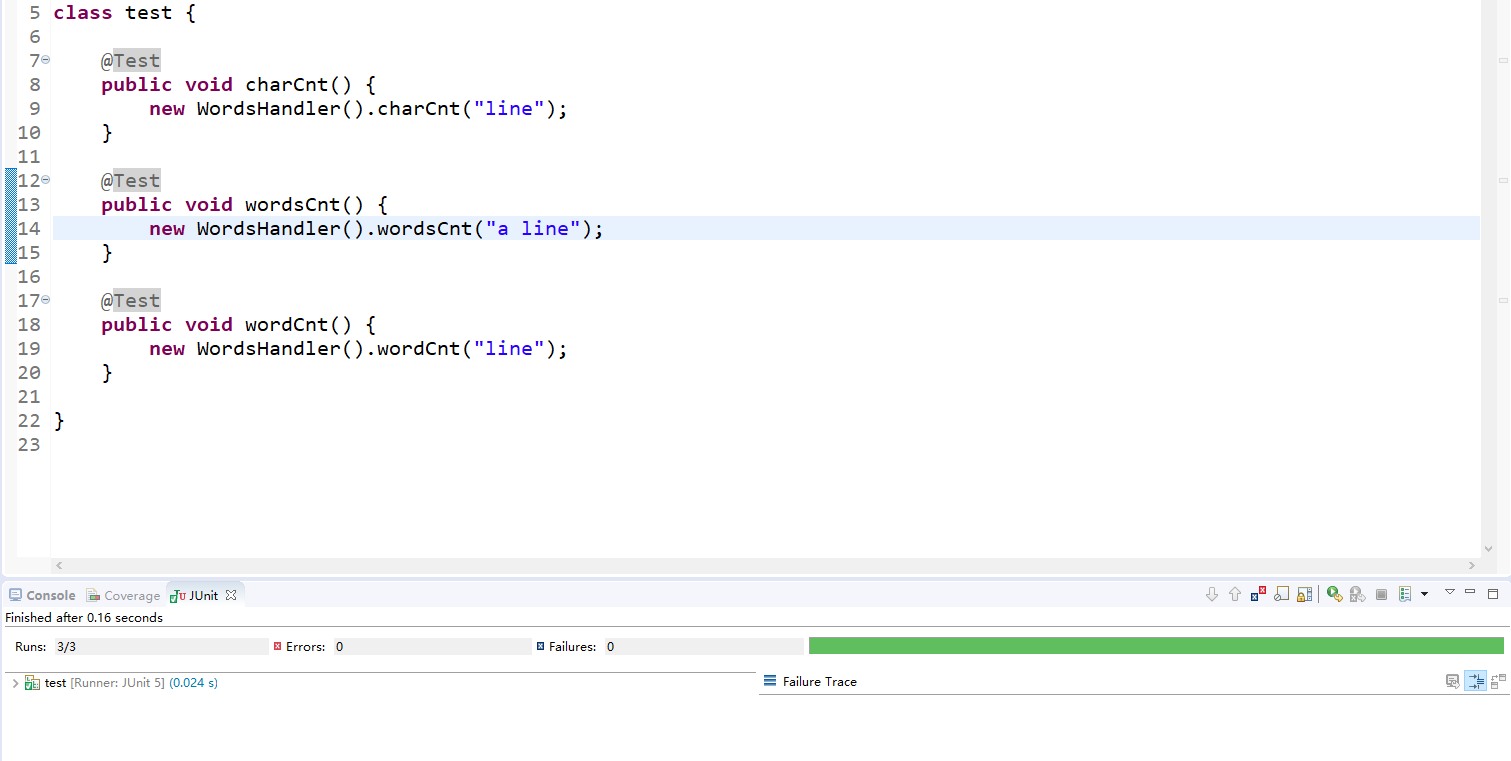
-
代码组织与内部实现设计(类图) :
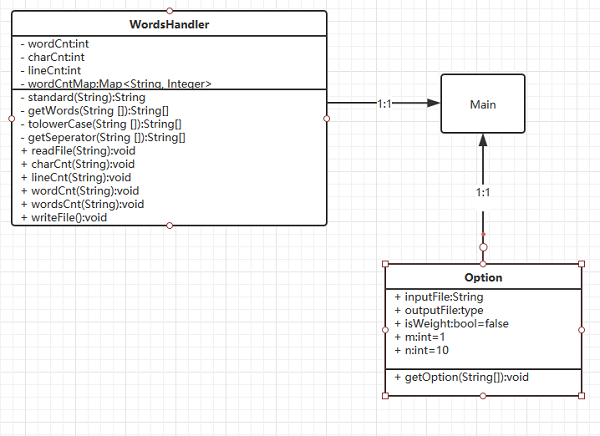
-
算法的关键与关键实现部分流程图 :
进阶需求较难的地方是单词词组的统计,以及爬虫的效率和同步代码块的设计。(由于Option.isWeight仅仅是权值的不同,以下仅解释当启用权值的情况)wordsCnt接收一行字符串,调用getWords分割出所有的可能单词(存在不符合题目定义"必须4个字母开头",正则表达式为"[^a-zA-Z0-9]"),调用getSeperator分割出所有的分隔符(正则表达式为“[a-zA-Z0-9]+”);然后遍历单词数组i=0->letters.length-m查找连续的m个单词,首先置find为true,然后从i位置连续遍历m此单词数组,若存在一个位置不符合题目单词的定义则置find=false,二层循环结束后判断find是否为true,若为true则表示存在连续的m个单词,那么从位置i开始拼接单词和其原本的分隔符,并根据该串是在title行还是在abstract行分别进行map的存取。
//单词组计数
public void wordsCnt(String line) {
if(Option.isWeight) {//启用权值
String letters[]=getWords(line); //分割出潜在的单词
String separators[]=getSeperator(line);//分割出分隔符
for(int i=0;i<letters.length-Option.m+1;i++) {
boolean find=true;
for(int j=i,cnt=0;cnt<Option.m;++j,cnt++) {
if(!letters[j].matches("[a-z]{4}[a-z0-9]*")) {//判断是否是单词
find=false;
}
}
if(find) {//找到连续的m个单词
String str=letters[i];
for(int j=i+1,cnt=0;cnt<Option.m-1;++j,cnt++) {
str+=separators[j-1]+letters[j];
}
if(line.contains("Title: ")) {
if(!wordCntMap.containsKey(str)) {
wordCntMap.put(str, 10);
}else {
wordCntMap.put(str, wordCntMap.get(str)+10);
}
}
if(line.contains("Abstract: ")) {
if(!wordCntMap.containsKey(str)) {
wordCntMap.put(str, 1);
}else {
wordCntMap.put(str, wordCntMap.get(str)+1);
}
}
}
}
}
else {//不启用权值
String letters[]=getWords(line); //分割出潜在的单词
String separators[]=getSeperator(line);//分割出分隔符
for(int i=0;i<letters.length-Option.m+1;i++) {
boolean find=true;
for(int j=i,cnt=0;cnt<Option.m;++j,cnt++) {
if(!letters[j].matches("[a-z]{4}[a-z0-9]*")) {//判断是否是单词
find=false;
}
}
if(find) {//找到连续的m个单词
String str=letters[i];
for(int j=i+1,cnt=0;cnt<Option.m-1;++j,cnt++)
str+=separators[j-1]+letters[j];
if(!wordCntMap.containsKey(str)) {
wordCntMap.put(str, 1);
}else {
wordCntMap.put(str, wordCntMap.get(str)+1);
}
}
}
}
}
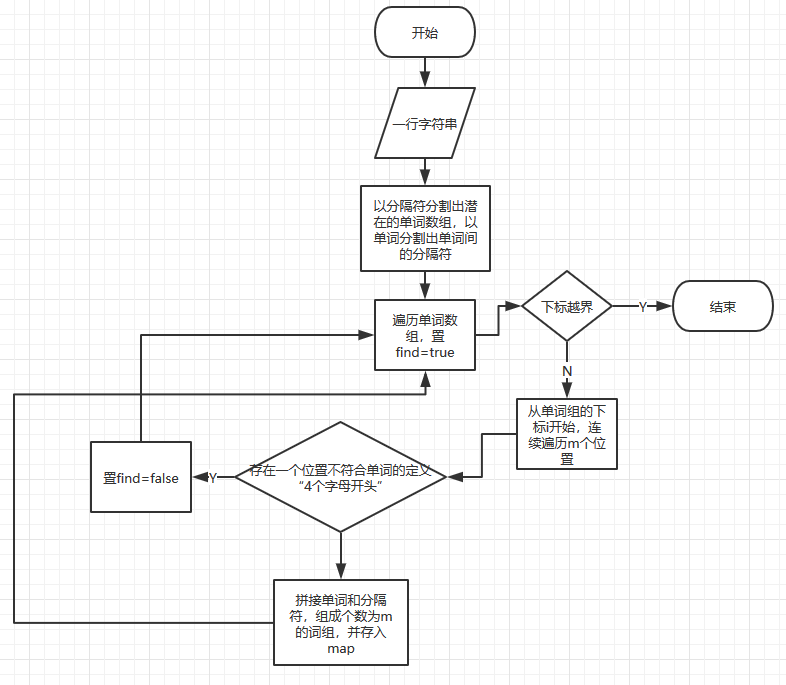
爬虫部分的实现采用jsoup,首先爬取http://openaccess.thecvf.com/CVPR2018.py官网的所有a标签,然后遍历所有a标签数组,若该a标签的href包含“content_cvpr_2018/html/”则它就是具有论文html的页面,将其完全限定路径取出并使用线程池开启一个线程去爬取论文。线程会调用Handler的同步方法writeFile(该方法共享cnt变量(论文数量),以及文件指针)对目标论文进行按要求爬取。
//Main函数部分代码
try {
System.out.println("开始链接");
Document document=Jsoup.connect("http://openaccess.thecvf.com/CVPR2018.py").maxBodySize(0).timeout(1000*60).get();
System.out.println("开始爬取");
handler.writer=new BufferedWriter(new FileWriter("result.txt"));
//System.out.println(document.toString());
Elements links=document.getElementsByTag("a");
int cnt=0;
for(Element link:links) {
String href=link.attr("href");
//System.out.println(href);
if(href.contains("content_cvpr_2018/html/")) {//获取论文
cnt++;
cachedPool.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
try {
//Thread.sleep(100);
Document document=Jsoup.connect("http://openaccess.thecvf.com/"+href).maxBodySize(0).timeout(1000*60*5).get();
handler.writeFile(document);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
}
System.out.println(cnt);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
class Handler{
BufferedWriter writer;
int cnt=0;
synchronized void writeFile(Document document) {//目标内容爬取
try {
System.out.println(cnt+" "+document.getElementById("abstract").text());
String string=cnt+"\r\n";
string+="Title: "+document.getElementById("papertitle").text()+"\r\n";
string+="Abstract: "+document.getElementById("abstract").text()+"\r\n\r\n\r\n";
writer.write(string);
writer.flush();
cnt++;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
protected void finalize() throws Throwable {
// TODO Auto-generated method stub
super.finalize();
System.out.println("close");
writer.close();
}
}

改进的思路:
- 基础需求的改进:原本采用三模块子功能划分导致过度的IO,会使性能下降;改进措施是先对文件扫描一遍导入内存,三个子功能分别对内存中的文件镜像进行操作,这样减少了IO,在文件过大的情况下,可以有效提高性能。
- 进阶需求的改进:由于进阶是在基础之上,基础的改进同样适用,主要不同在于进阶需要进行词组统计,这里我们采用了2重循环,最坏情况下时间复杂度是O(mn),由于m<=100,所以可以认为最坏的时间复杂度是O(n),该出尚未想到更加的优化策略。爬虫方面的优化在于原本采用单线程去爬取(有978条数据)使用的时间超过5分钟,所以我们就采用了多线程技术,多线程碰到该怎么设计同步方法,该方法必须尽可能的短才能有效的优化效率,最后抽取出共享cnt变量(论文计数)和文件指针,方法体仅进行目标爬取。
项目测试:
-
基础需求的字符,单词,行数少量计数(有10个测试样例,这里只贴出2个)


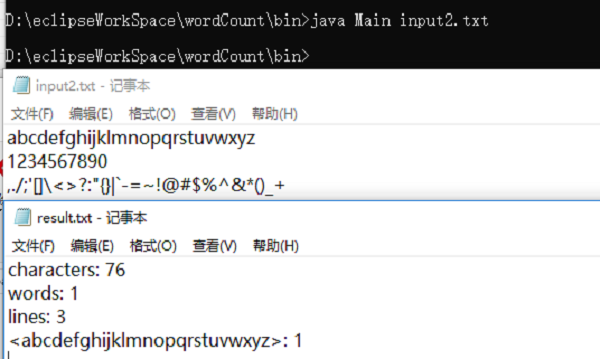
-
基础需求的压力测试
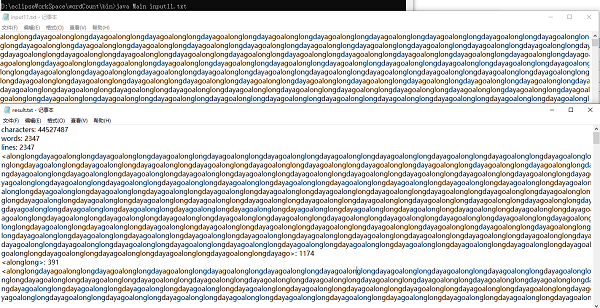
-
进阶需求的官网论文测试

遇到的困难和解决方法:
-
1.需求不明确,Edge Case模糊
解决方法 :在群里与同学,助教交流 -
2.初次使用java爬虫
解决方法 :上网找教程自学爬虫 -
3.结对成员上课时间冲突,未能深入讨论代码实现
解决方法 :在双方都没课时,约个时间讨论实现方案;用qq保持交流,实时分享编程进度 -
4.对于“统计文件的字符数”的功能中一些字符该如何统计未能很好的理解
解决方法:在微信群和博客中向助教和老师提问直到彻底理解需求,对程序根据助教提供的样例进行测试
评价队友
221600426
| 队友积极配合,细心,耐心,具有上进心,两次作业合作下来非常愉快。 |
221600401
| 我的队友代码能力超强!之前只是听说我的队友队友是个大佬,结对后才深刻体会到他编程的能力,记得今天才刚分好工,第二天就完成了基础的编程,作为一队有一种强烈的不能偷懒的想法。我的队友学习能力也超强,上次作业的墨刀和这次作业的爬虫,感觉很快就能学会并且自己开始做了,对我提出的问题也会认真讲解。我希望能学到队友那超强的编程能力和学习能力,在作业过程中能不拖累队友! |

