
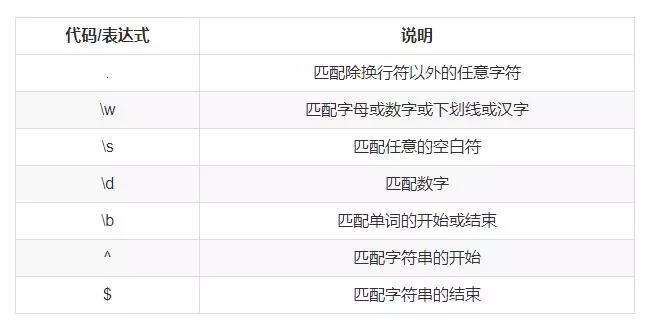
1、元字符
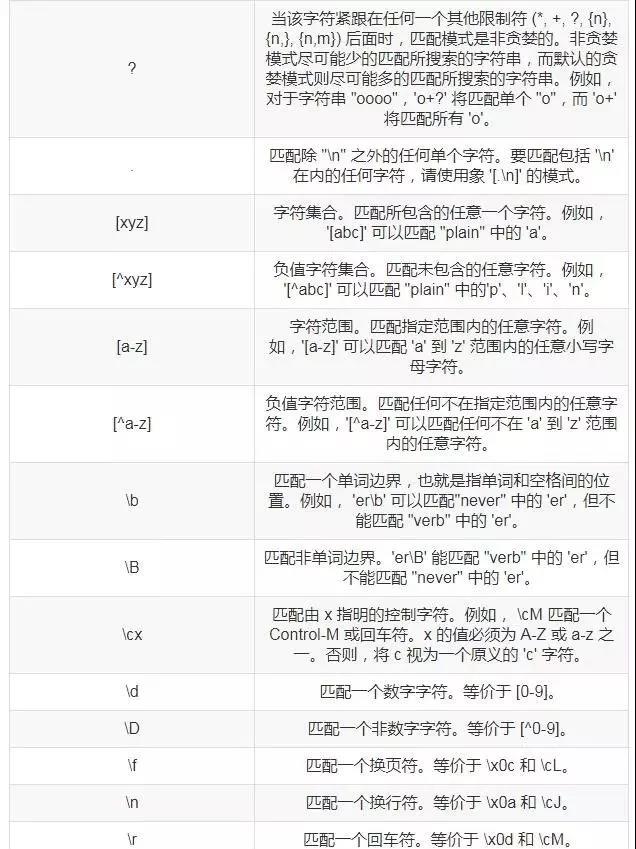
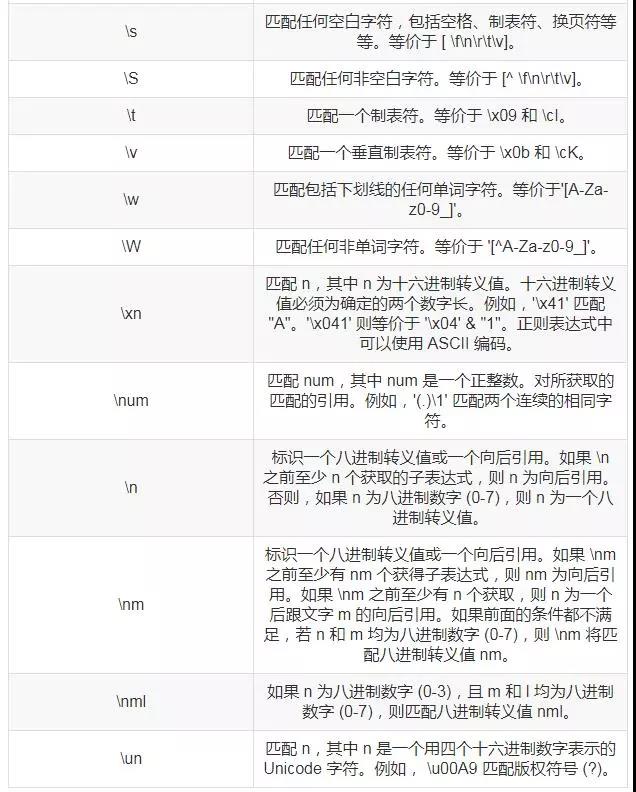
常用的元字符
2、字符转义
如你要查找<code>.</code>,或者<code>*</code>,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用<code>\.</code>和<code> \* </code>。当然,要查找<code> \ </code>本身,你也得用<code>\\ </code>。
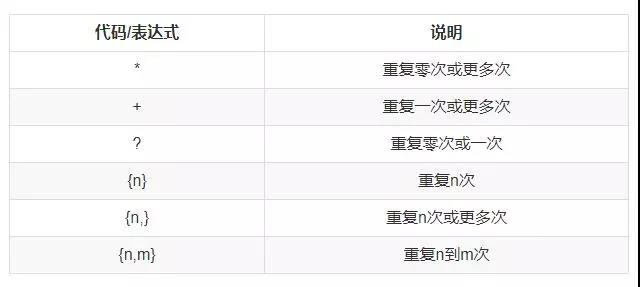
3、重复
常用的限定符

4、字符类
[“your set”]:如[aeiou],则匹配<code>a</code>,<code>e</code>,<code>i</code>,<code>o</code>和<code>u</code>中的任意一个,同理[.?!]匹配标点符号(<code>.</code>或<code>?</code>或<code>!</code>)。
[0-9]:与<code>\d</code>就是完全一致,表示一位数字。
[a-zA-Z]:表示一个字母,[a-z0-9A-Z]等同于<code>\w</code>(当然值考虑英文的话)。
例4-1:\(?0\d{2}[)-]?\d{8}
【分析】
这个表达式可以匹配几种格式的电话号码,像(010)88886666,或022-22334455,或02912345678等。
我们对它进行一些分析吧。
首先是一个转义字符<code>\(</code>,它能出现0次或1次<code>?</code>,然后是一个0,后面跟着2个数字<code>\d{2}</code>,然后是)或-或空格中的一个,它出现1次或不出现<code>?</code>,最后是8个数字<code>\d{8}</code>。
5、分枝条件
如果你认真去看例4-1,发现那个表达式也能匹配010)12345678或(022-87654321这样的“不正确”的格式。要解决这个问题,我们需要用到分枝条件。
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用<code>|</code>(竖线)把不同的规则分隔开
例5-1:0\d{2}-\d{8}|0\d{3}-\d{7}
【分析】
这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如:010-12345678),一种是4位区号,7位本地号(如:0376-2233445),<code>0\d{2}-\d{8}</code>表示“0”加两数字加“-”加8个数字,<code>0\d{3}-\d{7}</code>表示“0”加三数字加“-”加7个数字,<code>|</code>可理解为“或”。就是查找与前者相匹配或者与后者相匹配的内容。
【注意】
使用分枝条件时,要注意各个条件的顺序。因为匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。如:<code>\d{5}-\d{4}|\d{5}</code>和<code>\d{5}|\d{5}-\d{4}</code>是不同的。
6、分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了。
例6-1:(\d{1,3}.){3}\d{1,3}
【分析】
这是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:<code>\d{1,3}</code>匹配1到3位的数字,<code>(\d{1,3}.)</code> <code>{3}</code>匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字<code>\d{1,3}</code>。
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
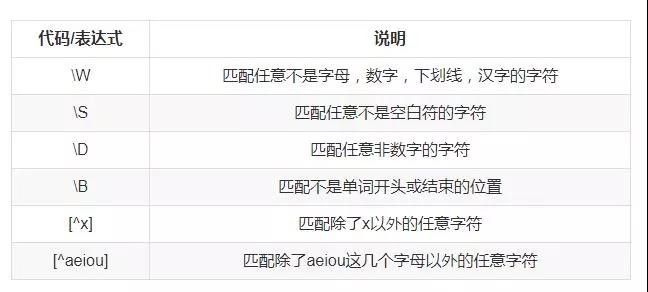
7、反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义。
常用的反义代码
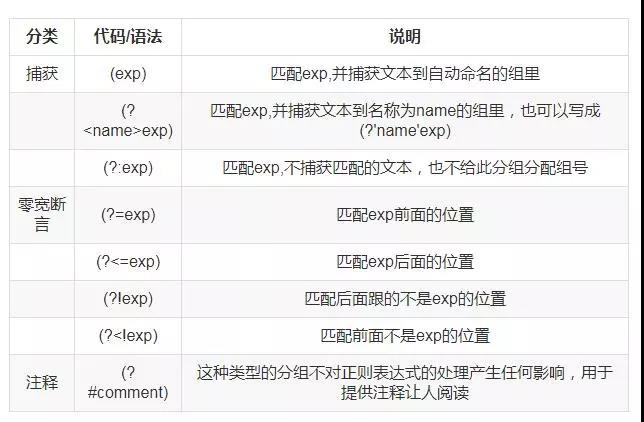
8、反向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本。例如,<code>\1</code>代表分组1匹配的文本。
例8-1:\b(\w+)\b\s+\1\b
【分析】
可以匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字<code>\b(\w+)\b</code>,这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符<code>\s+</code>,最后是分组1中捕获的内容(也就是前面匹配的那个单词)<code>\1</code>。
常用分组语法
9、贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
【注意】最先开始的匹配拥有最高的优先权。
懒惰限定符

附表

<code>(pattern)</code> 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '(' 或 ')'。
<code>(?:pattern)</code> 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符“|”来组合一个模式的各个部分是很有用。
例如,“industr(?:y|ies)”就是一个比 “industry|industries” 更简略的表达式。
<code>(?=pattern)</code> 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
<code>(?!pattern)</code> 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
<code>x|y</code>匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
<code>用户名</code>:^[a-z0-9_-]{3,16}$
<code>密码</code>:^[a-z0-9_-]{6,18}$
<code>十六进制值</code>:^#?([a-f0-9]{6}|[a-f0-9]{3})$
<code>电子邮箱</code>:^([a-z0-9_.-]+)@([\da-z.-]+).([a-z.]{2,6})$
<code>URL</code>:^(https?://)?([\da-z.-]+).([a-z.]{2,6})([/\w .-]*)*/?$
<code>IP 地址</code>:^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
<code>HTML 标签</code>:<([a-z]+)([<]+)*(?:>(.*)</\1>|\s+/>)$
<code>Unicode编码中的汉字范围</code>:^[u4e00-u9fa5],{0,}$
<code>匹配中文字符的正则表达式</code>: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
<code>匹配双字节字符</code>(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
<code>匹配空白行的正则表达式</code>:\n\s*\r
评注:可以用来删除空白行
<code>匹配HTML标记的正则表达式</code>:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
<code>匹配首尾空白字符的正则表达式</code>:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
<code>匹配Email地址的正则表达式</code>:\w+([-+.]\w+)*@\w+([-.]\w+)*.\w+([-.]\w+)*
评注:表单验证时很实用
<code>匹配网址URL的正则表达式</code>:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
<code>匹配帐号是否合法</code>(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
<code>匹配国内电话号码</code>:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
<code>匹配腾讯QQ号</code>:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
<code>匹配中国大陆邮政编码</code>:[1-9]\d{5}(?!\d)
评注:中国大陆邮政编码为6位数字
<code>匹配身份证</code>:\d{15}|\d{18}
评注:中国大陆的身份证为15位或18位
<code>匹配ip地址</code>:((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
评注:提取ip地址时有用
<code>匹配特定数字</code>:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*.\d*|0.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*.\d*|0.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0)$ //匹配浮点数
^[1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*.\d*|0.\d*[1-9]\d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
<code>匹配特定字符串</code>:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
