
MapReduce全排序的方法1:
每个map任务对自己的输入数据进行排序,但是无法做到全局排序,需要将数据传递到reduce,然后通过reduce进行一次总的排序,但是这样做的要求是只能有一个reduce任务来完成。
并行程度不高,无法发挥分布式计算的特点。
MapReduce全排序的方法2:
针对方法1的问题,现在介绍方法2来进行改进;
使用多个partition对map的结果进行分区,且分区后的结果是有区间的,将多个分区结果拼接起来,就是一个连续的全局排序文件。
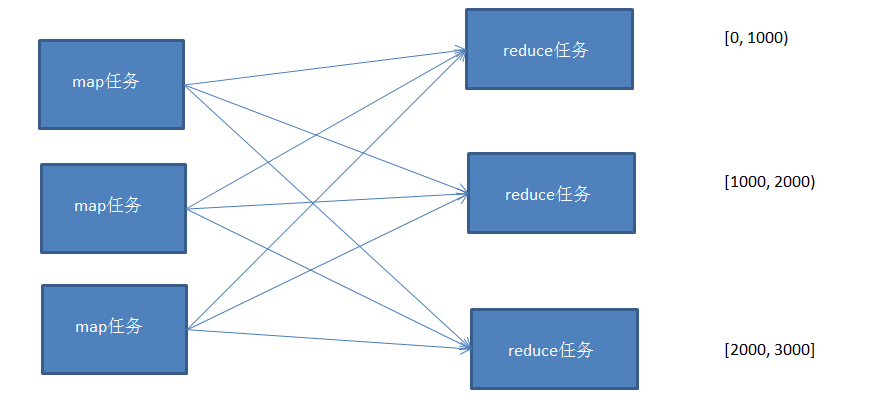
Hadoop自带的Partitioner的实现有两种,一种为HashPartitioner, 默认的分区方式,计算公式 hash(key)%reducernum,另一种为TotalOrderPartitioner, 为排序作业创建分区,分区中数据的范围需要通过分区文件来指定。
分区文件可以人为创建,如采用等距区间,如果数据分布不均匀导致作业完成时间受限于个别reduce任务完成时间的影响。
也可以通过抽样器,先对数据进行抽样,根据数据分布生成分区文件,避免数据倾斜。
这里实现一个通过随机抽样来生成分区文件,然后对数据进行全排序,根据分区文件的范围分配到不同的reducer中。
示例代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.InputSampler; import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner; import java.io.IOException; /** * Created by Edward on 2016/10/4. */ public class TotalSort { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //access hdfs's user System.setProperty("HADOOP_USER_NAME","root"); Configuration conf = new Configuration(); conf.set("mapred.jar", "D:\\MyDemo\\MapReduce\\Sort\\out\\artifacts\\TotalSort\\TotalSort.jar"); FileSystem fs = FileSystem.get(conf); /*RandomSampler 参数说明 * @param freq Probability with which a key will be chosen. * @param numSamples Total number of samples to obtain from all selected splits. * @param maxSplitsSampled The maximum number of splits to examine. */ InputSampler.RandomSampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.1, 10, 10); //设置分区文件, TotalOrderPartitioner必须指定分区文件 Path partitionFile = new Path( "_partitions"); TotalOrderPartitioner.setPartitionFile(conf, partitionFile); Job job = Job.getInstance(conf); job.setJarByClass(TotalSort.class); job.setInputFormatClass(KeyValueTextInputFormat.class); //数据文件默认以\t分割 job.setMapperClass(Mapper.class); job.setReducerClass(Reducer.class); job.setNumReduceTasks(4); //设置reduce任务个数,分区文件以reduce个数为基准,拆分成n段 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setPartitionerClass(TotalOrderPartitioner.class); FileInputFormat.addInputPath(job, new Path("/test/sort")); Path path = new Path("/test/wc/output"); if(fs.exists(path))//如果目录存在,则删除目录 { fs.delete(path,true); } FileOutputFormat.setOutputPath(job, path); //将随机抽样数据写入分区文件 InputSampler.writePartitionFile(job, sampler); boolean b = job.waitForCompletion(true); if(b) { System.out.println("OK"); } } }
测试数据:
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 2
11 2
12 2
13 2
14 2
15 2
16 2
17 2
18 2
19 2
20 2
...
5999 4
6000 4
6001 4
6002 4
6003 4
6004 4
6005 4
6006 4
6007 4
6008 4
6009 4
6010 4
抽样生成的分区文件为:
# hadoop fs -text /user/root/_partitions
2673 (null)
4441 (null)
5546 (null)
生成的抽样文件为sequence file通过 -text打开查看
生成的排序结果文件:

文件内容:
hadoop fs -cat /test/wc/output/part-r-00000
... 2668 4 2669 4 267 3 2670 4 2671 4 2672 4
hadoop fs -cat /test/wc/output/part-r-00001
... 4431 4 4432 4 4433 4 4434 4 4435 4 4436 4 4437 4 4438 4 4439 4 444 3 4440 4
hadoop fs -cat /test/wc/output/part-r-00002
...
554 3 5540 4 5541 4 5542 4 5543 4 5544 4 5545 4
hadoop fs -cat /test/wc/output/part-r-00003
...
99 2 990 3 991 3 992 3 993 3 994 3 995 3 996 3 997 3 998 3 999 3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号