
Spark简介
官网地址:http://spark.apache.org/
Apache Spark is a fast and general engine for large-scale data processing.
Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing.
Ease of Use
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, or on Apache Mesos. Access data in HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source.
官方文档地址:http://spark.apache.org/docs/1.6.0/
安装
下载:
Spark runs on Java 7+, Python 2.6+ and R 3.1+. For the Scala API, Spark 1.6.0 uses Scala 2.10. You will need to use a compatible Scala version (2.10.x).
spark版本:spark-1.6.0-bin-hadoop2.6.tgz
scala版本:scala-2.10.4.tgz
spark监控端口 :8080
安装集群:
tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz -C /usr/
修改解压后的配置文件 /conf/spark-env.sh
export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=1024m export SPARK_LOCAL_DIRS=/data/spark/dataDir export HADOOP_CONF_DIR=/usr/hadoop-2.5.1/etc/hadoop
修改slaves文件
node2
node3
集群管理器类型有
Standalone
Apache Mesos
Hadoop Yarn
这里介绍两种方式 Standalone 和 Yarn
配置文件中的 HADOOP_CONF_DIR就是为了使用Yarn配置的
Standalone
启动spark自身的管理器
spark/sbin/start-all.sh
运行测试脚本
standalone client模式
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --executor-memory 512m --total-executor-cores 1 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
standalone cluster模式
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
查询结果http://node1:8080 client模式通过8080查询不到结果,在脚本执行结束后在终端就能看到结果。
Yarn
启动hadoop集群, 由于使用Yarn不需要启动spark
start-all.sh
运行测试脚本:
Yarn client模式
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512M --num-executors 1 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
Yarn cluster模式
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 1 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
查询执行结果 http://node1:8088 client模式通过8088查询不到结果,在脚本执行结束后在终端就能看到结果。
Yarn应用场景,集群中同时运行hadoop和spark建议使用yarn,共用相同的资源调度器。
Standalone针对只跑spark应用的集群。
集群模式
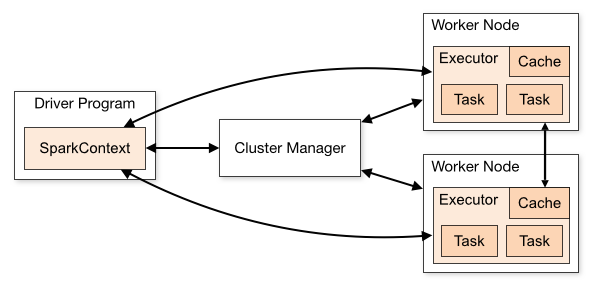
The following table summarizes terms you’ll see used to refer to cluster concepts:
| Term | Meaning |
|---|---|
| Application | User program built on Spark. Consists of a driver program and executors on the cluster. |
| Application jar | A jar containing the user's Spark application. In some cases users will want to create an "uber jar" containing their application along with its dependencies. The user's jar should never include Hadoop or Spark libraries, however, these will be added at runtime. |
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Cluster manager | An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
| Deploy mode | Distinguishes where the driver process runs. In "cluster" mode, the framework launches the driver inside of the cluster. In "client" mode, the submitter launches the driver outside of the cluster. |
| Worker node | Any node that can run application code in the cluster |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Task | A unit of work that will be sent to one executor |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs. |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号