
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
用例说明:

注:基于物品的协同过滤算法,是目前商用最广泛的推荐算法。
刚开始看这个用例,感觉还是基于用户进行的推荐,用户A,B,C都喜欢物品a,并且用户A,B喜欢物品c,然后就将物品c推荐给用户C。
再回过头来看看基于物品的协同过滤的概念:给用户推荐和他之前喜欢的物品相似的物品。按我的理解和其他用户的喜好并没有什么直接关系;比如用户C喜欢帽子a,再给他推荐个类似的商品帽子b就可以了。
比如:物品a为啤酒,物品c为尿布,符合图例,则向用户C推荐的物品为尿布,因为物品a和物品c相似?,所以就向用户C推荐了此商品。显然这里的相似并不是决对的相同种类或类型的物品。
那物品的相似是怎么计算出来的哪?
Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。
这样解释就可以很好的说明上面的疑问了。
当然也可以直接针对不同物品建立相似性关系。计算出不同物品的相似度。
相似度
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的 CF 和基于物品的 CF。这两种方法都需要计算相似度。
关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用户 - 物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。
上一篇文章中基于用户的协同过滤,建立的用户相似矩阵,此篇文章是建立的物品相似度的矩阵。
同现矩阵(Co-occurrence Matrix): 反应物品关联度的矩阵
生成同现矩阵
数据:user,item,grade
1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.0 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0
用户1的三个item 101,102,103形成9种组合,相应位置加1.
[101] [102] [103]
[101] 1 1 1
[102] 1 1 1
[103] 1 1 1
最终结果: [101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
下面内容摘自一论坛:
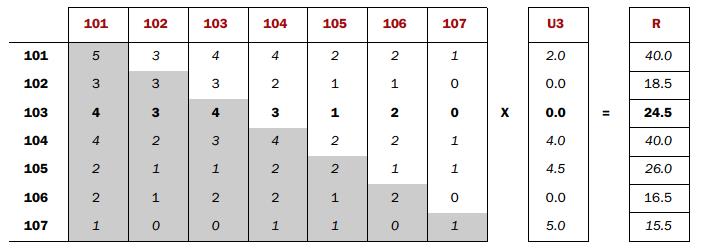
再谈谈Co-occurrence Matrix(同显矩阵)和User Preference Vector(用户评分向量)相乘得到的这个Recommended Vector(推荐向量)的意义
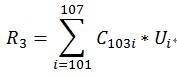

 浙公网安备 33010602011771号
浙公网安备 33010602011771号