【论文解析】关于YOLO系列的通俗概括
前言
目标检测是计算机视觉中的一个比较中间层面的任务,检测的步骤包括两部分:目标定位和目标检测,定位是为了找到物体在图像中的位置,而检测是为了将这个物体是什么返回出来,这就是两个阶段的检测,俗称two-stage,也就是两阶段检测。
可以自己想一想,如果让你来设计一个方式,给一个图片自动找出目标物体,你会怎么设计?请保持这个疑问继续往下看。
DPM
Deformable Part-based Model
在深度学习流行之前,它是计算机视觉中物体检测的重要技术之一
使用一个滑窗(sliding window)在整张图像上均匀滑动,用SVM分类器评估是否有物体。
R-CNN
Region-based Convolutional Neural Network
提出来候选区的方法:region proposals
什么意思呢?就是先从图像中找到一些可能存在对象的候选区potential bounding box,这个过程叫做\(selective-serach\),在实际利用模型的时候大概有2000个左右,然后用分类器来评估这些boxes,接着通过post-processing来改善bounding boxes,消除重复的检测目标,并基于整个场景中的其他物体重新对boxes进行打分。整个流程执行下来很慢,而且因为这些环节都是分开训练的,检测性能很难进行优化。
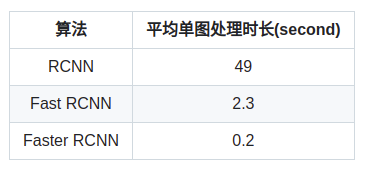
Fast R-CNN ->Faster R-CNN
这些就是将R-CNN的性能进行提升
YOLOv1
You Only Look Once
想象为什么叫这个名字。人们在看到一张图片的时候只需要看一眼,就能大致知道物体的位置和种类信息,那么就是这个一眼,被迁移到了这个算法中进行实现了。
是将物体检测当做回归任务,直接将整张图像所有像素都输入得到bopunding box的坐标,box中几包含物体的置信度和class probilities。实现了端到端。
YOLO将候选区和目标检测合二为一。
首先
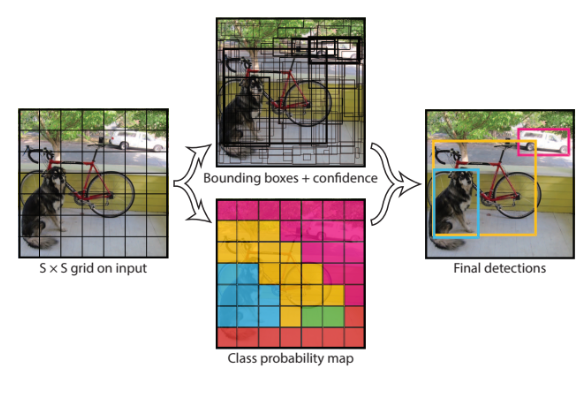
作者将原始图像分割成了\(S\times S\)个网格,使用这种预定义的类似候选区的预测区域方式取代了R-CNN的候选区,论文中S等于7,也就是49个网格(下文要用到,敲黑板)

网络结构
先按下不表怎么实现的,我们先来看看这个网络是什么样子的。

一张\(448\times448\times3\)的图片输入,最终输出一个\(7\times7\times30\)的张量。还记得前面的网格吗?没错,每一个网格都被拓展为\(1\times1\times30\)的向量了,一共49个,所以输出是:\(7\times7\times30\)。
那么这时候有人就会有疑问了?
那么如果存在跨网格的对象是不是就难以识别呢,其实不然,经过卷积神经网络的复杂提取和变换,网格周围的信息其实也被编码到这个30维向量中了。
这30维向量其实长这个样子。
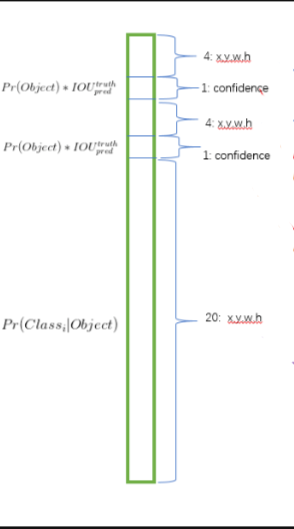
前20个代表着设计之初的20种目标在该位置的概率,\(P(C_i|Object)\)表示若该网格存在一个目标,它是\(C_i\)的概率出现。
最后8个值表示两个bounding box的位置,每个bounding box需要四个值来表示,分别为\((center_x,center_y,width,height)\)
以及置信度confidence,表示每个bounding box的置信度。
上式含义为bounding box的置信度等于该bounding box内存在目标的概率和该bounding box与实际bounding box的IOU乘积。
这是针对训练而言的,也就是用于计算预测准确程度的损失函数的一部分,实际使用训练好的YOLO算法是没有实际的bounding box进行参考的,因而没有IOU。简单说来,bounding box的置信度表示它是否包含目标且位置准确的程度。
上式第一行表示边框中心位置误差((cx,cy)误差),第二行表示边框宽度和高度误差,第三行表示边框内有目标的置信度误差,第四行表示边框内无目标的置信度误差,最后一行表示目标分类误差。总的来说,就是网络输出与真实标签的各项内容的误差平方和作为最后的输出误差,上述五项和30维输出是对应的。\(\lambda_{\text {coord}}\)用于调整bbox误差的权重,YOLO设置为5。

训练
YOLO现在ImageNet数据集上训练前20层卷积网络,让网络获得一部分图像特征提取能力,然后在Pascal VOC数据集上进行目标检测的训练。除了最后一层使用线性激活函数,其他层均使用Leaky Relu,同时采用Dropout和Data Augmention来控制过拟合的发生。
预测
训练完的YOLO网络就可以进行目标预测了,在此之前需要明确下面几个点。原论文的YOLO结构最多识别49个目标;通过调整网络结构可以识别更多的对象;YOLO中的预定义bounding box和Faster RCNN中的Anchor不一样,并没有设定bounding box的位置和大小,只是表示对一个目标预测两个bounding box,选择可能性较大的那个,仅此而已。
训练完成的YOLO网络就可以进行目标检测了,不过它的输出是49个30维向量,表示网格包含的对象类别以及该对象的可能两个bounding box位置和对应的置信度。
NMS(Non-maximal suppression)
为了向量中提取最有可能的目标及其位置,YOLO采用NMS(Non-maximal suppression,非极大值抑制算法)来实现。
NMS算法并不复杂,其核心思想非常简单:选择score最高的作为输出,与其重叠的删除,反复迭代直到处理完所有备选。在YOLO中定义score如下式,表示每个网格中目标\(C_i\)存在于第\(j\)个bounding box的概率。
总结
YOLO提出时由于one-stage特性,速度很快,FPS可以达到45,总体精度低于FastRCNN
YOLOv2
YOLO9000:better,faster,stronger
原作者将目标类别增加到了9000种,因此又称为YOLO9000

YOLOv3
相交前面的,这个地方反而创新性的改进较少。
可以先来了解下什么是FPN
FPN
Feature Pyramid Networks
主要解决物体检测中的多尺度的问题,通过网络改变,提高小物体检测的性能。
划重点:小物体
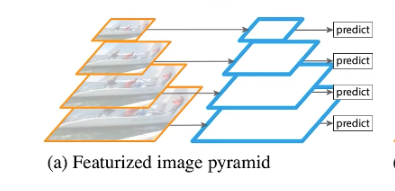
上图为特征图像金字塔结构,要检测不同尺度目标时会将图片进行缩放,针对每个尺度的图片都依次通过进行预测。
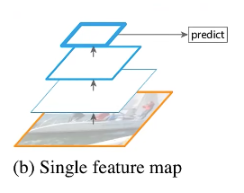
上图为单一特征图结构,将图片通过backbone得到最终特征图,在最终特征图上进行预测。

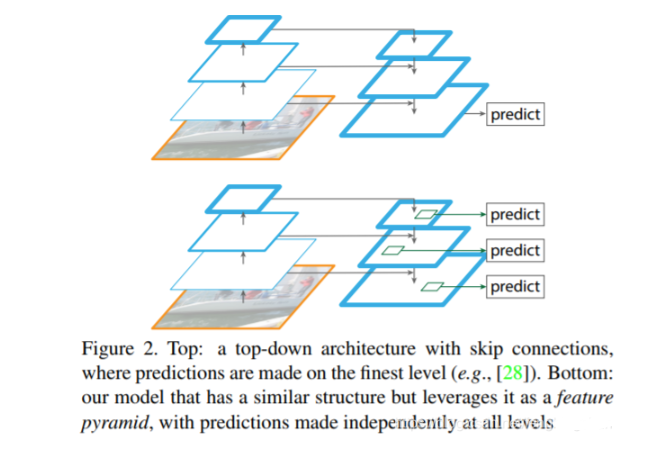
为金字塔特征层次结构,将图片输入backbone,在backbone正向传播过程中得到的不同的特征图上分别进行预测。(小目标容易被错分)
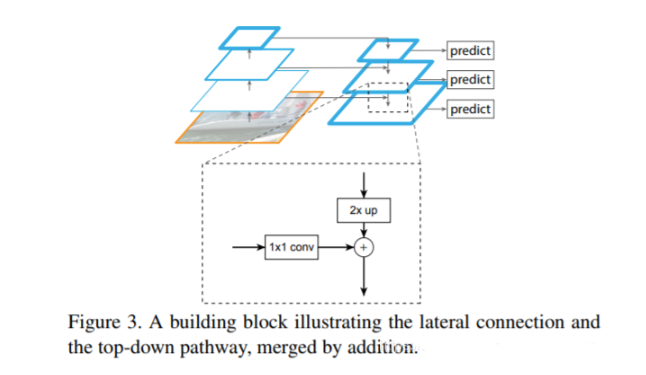
对backbone的网络作用1X1的卷积,用来匹配通道数(这点大家应该都能理解),然后对高层的特征图进行2倍的上采样,上两步处理后,最高层与中间层的特征图的shape完全相同,最后两个相加。重复这个动作。
一、up sampling 这里笔者科普一下什么是上采样和下采样:
1、上采样又名放大图像、图像插值,主要目的是放大原始图像,从而可以显示在更高分辨率的显示设备上。上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling);图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
2、当然还有下采样,又名降采样、缩小图像;主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图;其实下采样就是池化;(doge)
二、笔者再来科普一下什么是backbone:
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。所以将这一部分网络结构称为backbone十分形象,仿佛是一个人站起来的支柱。
参考这篇
FPN的结构:
这里以RESNET50为backbone为例
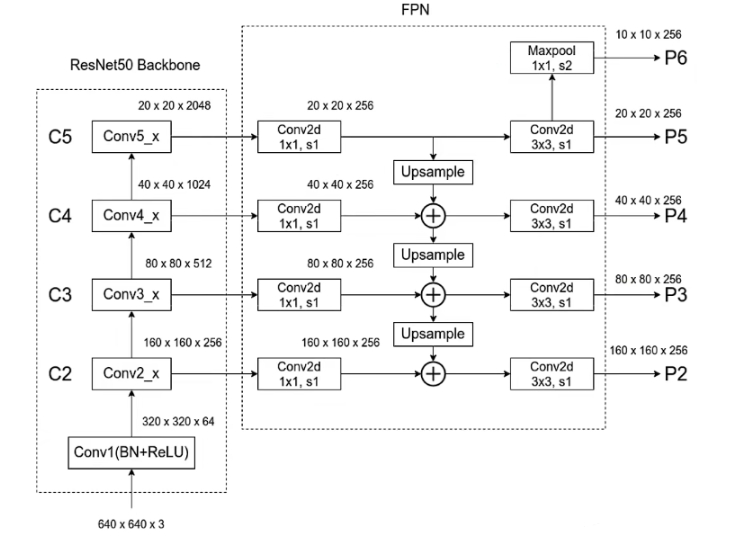
通过上面这些图,也就知道为啥叫多尺度融合了。图像放大、缩小、局部特征、全局特征,我全都能知道,这个识别厉害吧?
那这些和YOLOv3有什么关系呢?
YOLOv3的改进中,不光改进了网络结构,借鉴了RESNET的做法,设计了新版本的DARKNET。此外,还有一点比较大的创新是融合了多尺度融合。因为这一点当时还比较火,通过下采样和上采样联合的操作,对几个尺度的特征图进行融合(concatenation),以获取不同的感受野信息,通过三种尺度的特征融合分别获得了小、中、大目标的检测能力,这是对YOLO2中passthrough层的进一步拓展。也是拓展,是的算法对于各种大小的目标有了更强的检测能力。
同时激活函数由softmax转化为Logistic函数回归来支持多标签的分类。
总而言之
相比于YOLO2,YOLO3没有什么太突破的成果,参照ResNet加深了网络结构,使用比较流行的多尺度融合提升了小目标检测效果。如果只考虑推理时间,在同等精度的情况下,YOLO3的速度是其他算法的3倍以上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号