


redis是什么:
Redis is an open source, BSD licensed, advanced key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
redis是开源,BSD许可,高级的key-value存储系统.
可以用来存储字符串,哈希结构,链表,集合,因此,常用来提供数据结构服务.
redis和memcached相比,的独特之处:
1: redis可以用来做存储(storge), 而memccached是用来做缓存(cache)
这个特点主要因为其有”持久化”的功能(把内存中的数据同步到硬盘,光盘等).
2: 存储的数据有”结构”,对于memcached来说,存储的数据,只有1种类型--”字符串”,
而redis则可以存储字符串,链表,哈希结构,集合,有序集合.
Redis下载安装
1:官方站点: redis.io 下载最新版或者最新stable版
2:解压源码并进入目录
tar xzvf …
cd redis-2.6.16
3: 不用configure
4: 直接make
(如果是32位机器 make 32bit)
注:易碰到的问题,时间错误.
原因: 源码是官方configure过的,但官方configure时,生成的文件有时间戳信息,
Make只能发生在configure之后,
如果你的虚拟机的时间不对,比如说是2012年
解决: date -s ‘yyyy-mm-dd hh:mm:ss’ 重写时间
再 clock -w 写入cmos
5: 可选步骤: make test 测试编译情况
(可能出现: need tcl >8.4这种情况, yum install tcl)
6: 安装到指定的目录,比如 /usr/local/redis
make PREFIX=/usr/local/redis install
注: PREFIX要大写
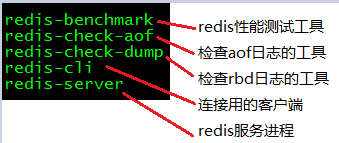
7: make install之后,得到如下几个文件
redis-benchmark 性能测试工具
redis-check-aof 日志文件检测工(比如断电造成日志损坏,可以检测并修复)
redis-check-dump 快照文件检测工具,效果类上
redis-cli 客户端
redis-server 服务端
redis是什么:
Redis is an open source, BSD licensed, advanced key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
redis是开源,BSD许可,高级的key-value存储系统.
可以用来存储字符串,哈希结构,链表,集合,因此,常用来提供数据结构服务.
redis和memcached相比,的独特之处:
1: redis可以用来做存储(storge), 而memccached是用来做缓存(cache)
这个特点主要因为其有”持久化”的功能(把内存中的数据同步到硬盘,光盘等).
2: 存储的数据有”结构”,对于memcached来说,存储的数据,只有1种类型--”字符串”,
而redis则可以存储字符串,链表,哈希结构,集合,有序集合.
Redis下载安装
1:官方站点: redis.io 下载最新版或者最新stable版
2:解压源码并进入目录
tar xzvf …
cd redis-2.6.16
3: 不用configure
4: 直接make
(如果是32位机器 make 32bit)
注:易碰到的问题,时间错误.
原因: 源码是官方configure过的,但官方configure时,生成的文件有时间戳信息,
Make只能发生在configure之后,
如果你的虚拟机的时间不对,比如说是2012年
解决: date -s ‘yyyy-mm-dd hh:mm:ss’ 重写时间
再 clock -w 写入cmos
5: 可选步骤: make test 测试编译情况
(可能出现: need tcl >8.4这种情况, yum install tcl)
6: 安装到指定的目录,比如 /usr/local/redis
make PREFIX=/usr/local/redis install
注: PREFIX要大写
7: make install之后,得到如下几个文件
redis-benchmark 性能测试工具
redis-check-aof 日志文件检测工(比如断电造成日志损坏,可以检测并修复)
redis-check-dump 快照文件检测工具,效果类上
redis-cli 客户端
redis-server 服务端
8: 复制配置文件
从源代码目录复制一份配置文件,复制到redis的安装根目录

9: 启动与连接
/path/to/redis/bin/redis-server ./path/to/conf-file
例:

连接: 用redis-cli
#/path/to/redis/bin/redis-cli [-h localhost -p 6379 ]

10: 让redis以后台进程的形式运行
编辑conf配置文件,修改如下内容;
daemonize yes

Redis对于key的操作命令
del key1 key2 ... Keyn
作用: 删除1个或多个键
返回值: 不存在的key忽略掉,返回真正删除的key的数量
rename key newkey
作用: 给key赋一个新的key名
注:如果newkey已存在,则newkey的原值被覆盖
renamenx key newkey
作用: 把key改名为newkey
返回: 发生修改返回1,未发生修改返回0
注: nx--> not exists, 即, newkey不存在时,作改名动作,newkey存在则不做修改
move key db
redis 127.0.0.1:6379[1]> select 2 //选择1号数据库,相当于mysql中的use database命令
OK
redis 127.0.0.1:6379[2]> keys *
(empty list or set)
redis 127.0.0.1:6379[2]> select 0 //选择0号数据库
OK
redis 127.0.0.1:6379> keys *
1) "name"
2) "cc"
3) "a"
4) "b"
redis 127.0.0.1:6379> move cc 2 //把key=cc的数据一道2号数据库中
(integer) 1
redis 127.0.0.1:6379> select 2 //选择2号数据库
OK
redis 127.0.0.1:6379[2]> keys * //可以查询到cc
1) "cc"
redis 127.0.0.1:6379[2]> get cc
"3"
(注意: 一个redis进程,打开了不止一个数据库, 默认打开16个数据库,从0到15编号,
如果想打开更多数据库,可以从配置文件修改) 默认使用第0个数据库

keys pattern 查询相应的key
在redis里,允许模糊查询key
有3个通配符 *, ? ,[]
*: 通配任意多个字符
?: 通配单个字符
[]: 通配括号内的某1个字符
redis 127.0.0.1:6379> flushdb
OK
redis 127.0.0.1:6379> keys *
(empty list or set)
redis 127.0.0.1:6379> mset one 1 two 2 three 3 four 4
OK
redis 127.0.0.1:6379> keys o*
1) "one"
redis 127.0.0.1:6379> key *o
(error) ERR unknown command 'key'
redis 127.0.0.1:6379> keys *o
1) "two"
redis 127.0.0.1:6379> keys ???
1) "one"
2) "two"
redis 127.0.0.1:6379> keys on?
1) "one"
redis 127.0.0.1:6379> set ons yes
OK
redis 127.0.0.1:6379> keys on[eaw]
1) "one"
randomkey 返回随机key
exists key
判断key是否存在,返回1/0
type key
返回key存储的值的类型
有string,link,set,order set, hash
ttl key
作用: 查询key的生命周期
返回: 秒数
注:对于不存在的key或已过期的key/不过期的key,都返回-1
Redis2.8中,对于不存在的key,返回-2
expire key 整型值
作用: 设置key的生命周期,以秒为单位
同理:
pexpire key 毫秒数, 设置生命周期
pttl key, 以毫秒返回生命周期
persist key
作用: 把指定key置为永久有效
Redis字符串类型的操作
之前讲解用的都是set命令,其实set命令设置的值就是字符串
set key value [ex 秒数] / [px 毫秒数] [nx] /[xx]
如: set a 1 ex 10 , 10秒有效
Set a 1 px 9000 , 9秒有效
注: 如果ex,px同时写,以后面的有效期为准
如 set a 1 ex 100 px 9000, 实际有效期是9000毫秒
nx: 表示key不存在时,执行操作
xx: 表示key存在时,执行操作(相当于对存在的key进行更改)
mset multi set , 一次性设置多个键值
例: mset key1 v1 key2 v2 ....
get key
作用:获取key的值
mget key1 key2 ..keyn
作用:获取多个key的值
setrange key offset value
作用:把字符串的offset偏移字节,改成value
redis 127.0.0.1:6379> set greet hello
OK
redis 127.0.0.1:6379> setrange greet 2 x
(integer) 5
redis 127.0.0.1:6379> get greet
"hexlo"
注意: 如果偏移量>字符长度, 该字符自动补0x00
redis 127.0.0.1:6379> setrange greet 6 !
(integer) 7
redis 127.0.0.1:6379> get greet
"heyyo\x00!"
append key value
作用: 把value追加到key的原值上
getrange key start stop
作用: 是获取字符串中 [start, stop]范围的值
注意: 对于字符串的下标,左数从0开始,右数从-1开始
redis 127.0.0.1:6379> set title 'chinese'
OK
redis 127.0.0.1:6379> getrange title 0 3
"chin"
redis 127.0.0.1:6379> getrange title 1 -2
"hines"
注意:
1: start>=length, 则返回空字符串
2: stop>=length,则截取至字符结尾
3: 如果start 所处位置在stop右边, 返回空字符串
getset key newvalue
作用: 获取并返回旧值,设置新值
redis 127.0.0.1:6379> set cnt 0
OK
redis 127.0.0.1:6379> getset cnt 1
"0"
redis 127.0.0.1:6379> getset cnt 2
"1"
incr key (秒杀?)
作用: 指定的key的值加1,并返回加1后的值
注意:
1:不存在的key当成0,再incr操作
2: 范围为64有符号
incrby key number
redis 127.0.0.1:6379> incrby age 90
(integer) 92
incrbyfloat key floatnumber
redis 127.0.0.1:6379> incrbyfloat age 3.5
"95.5"
decr key
redis 127.0.0.1:6379> set age 20
OK
redis 127.0.0.1:6379> decr age
(integer) 19
decrby key number
redis 127.0.0.1:6379> decrby age 3
(integer) 16
getbit key offset
作用:获取值的二进制表示,对应位上的值(从左,从0编号)
redis 127.0.0.1:6379> set char A
OK
redis 127.0.0.1:6379> getbit char 1
(integer) 1
redis 127.0.0.1:6379> getbit char 2
(integer) 0
redis 127.0.0.1:6379> getbit char 7
(integer) 1
setbit key offset value
设置offset对应二进制位上的值
返回: 该位上的旧值
注意:
1:如果offset过大,则会在中间填充0,
2: offset最大大到多少
3:offset最大2^32-1,可推出最大的的字符串为512M

2^32=4294967296
bitop operation destkey key1 [key2 ...]
对key1,key2..keyN作operation,并将结果保存到 destkey 上。
operation 可以是 AND 、 OR 、 NOT 、 XOR
redis 127.0.0.1:6379> setbit lower 7 0
(integer) 0
redis 127.0.0.1:6379> setbit lower 2 1
(integer) 0
redis 127.0.0.1:6379> get lower
" "
redis 127.0.0.1:6379> set char Q
OK
redis 127.0.0.1:6379> get char
"Q"
redis 127.0.0.1:6379> bitop or char char lower
(integer) 1
redis 127.0.0.1:6379> get char
"q"
注意: 对于NOT操作, key不能多个
link 链表结构
lpush key value
作用: 把值插入到链接头部
rpop key
作用: 返回并删除链表尾元素
rpush,lpop: 不解释
如果链表本来为空lpush rpush没区别
lrange key start stop
作用: 返回链表中[start ,stop]中的元素
规律: 左数从0开始,右数从-1开始
查看链表所有元素

lrem key count value
作用: 从key链表中删除 value值
注: 删除count的绝对值个value后结束
Count>0 从表头删除
Count<0 从表尾删除
ltrim key start stop
作用: 剪切key对应的链接,切[start,stop]一段,并把该段重新赋给key
lindex key index
作用: 返回index索引上的值,
如 lindex key 2
llen key
作用:计算链接表的元素个数
redis 127.0.0.1:6379> llen task
(integer) 3
redis 127.0.0.1:6379>
linsert key after|before search value
作用: 在key链表中寻找’search’,并在search值之前|之后,.插入value
注: 一旦找到一个search后,命令就结束了,因此不会插入多个value
rpoplpush source dest
作用: 把source的尾部拿出,放在dest的头部,
并返回 该单元值
场景: task + bak 双链表完成安全队列
Task列表 bak列表
|
|
|
|
|
|
|
|
业务逻辑:
1:Rpoplpush task bak
2:接收返回值,并做业务处理
3:如果成功,rpop bak 清除任务. 如不成功,下次从bak表里取任务
注:意思是这样的,Task列表中,存放着系统待处理的任务,我依次的使用rpop,从列表中弹出任务,来进行处理。此时如果要是任务失败了,但是我们的数据又从Task列表中pop出来了。我们就不好处理了。所以这条命令就体现出所用了。我们每处理一条任务的时候,先pop,然后再push进bak列表,如果任务成功了,我们再把这个任务从bak列表中删除。如果没成功,那么就存在bak列表中。这样bak列表最后存储的不都是任务失败的记录了吗。或者失败之后我们再次执行任务就直接从bak列表中取任务(rpop)不就可以了吗。
brpop ,blpop key timeout
作用:等待弹出key的尾/头元素,
Timeout为等待超时时间
如果timeout为0,则一直等待
场景: 长轮询Ajax,在线聊天时,能够用到
注:把说的话都push进这个链表,如果没有话说,我就一直等着,如果有内容push进来,我就pop出去
在客户端1中执行rpop命令

我在客户端2中,push进来一个e字符

在客户端1中,立刻就被pop出来了。

Setbit 的实际应用
场景: 1亿个用户, 每个用户 登陆/做任意操作 ,记为 今天活跃,否则记为不活跃
每周评出: 有奖活跃用户: 连续7天活动
每月评,等等...
思路:
Userid dt active
1 2013-07-27 1
1 2013-0726 1
如果是放在表中, 1:表急剧增大,2:要用group ,sum运算,计算较慢
用: 位图法 bit-map
Log0721: ‘011001...............0’
......
log0726 : ‘011001...............0’
Log0727 : ‘0110000.............1’
1: 记录用户登陆:
每天按日期生成一个位图, 用户登陆后,把user_id位上的bit值置为1
2: 把1周的位图 and 计算,
位上为1的,即是连续登陆的用户
redis 127.0.0.1:6379> setbit mon 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit mon 3 1
(integer) 0
redis 127.0.0.1:6379> setbit mon 5 1
(integer) 0
redis 127.0.0.1:6379> setbit mon 7 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit thur 3 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 5 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 8 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit wen 3 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 4 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 6 1
(integer) 0
redis 127.0.0.1:6379> bitop and res mon feb wen
(integer) 12500001
如上例,优点:
1: 节约空间, 1亿人每天的登陆情况,用1亿bit,约1200WByte,约10M 的字符就能表示
2: 计算方便
集合 set 相关命令
集合的性质: 唯一性,无序性,确定性(确定性指的是能够描述)
注: 在string和link的命令中,可以通过range 来访问string中的某几个字符或某几个元素
但,因为集合的无序性,无法通过下标或范围来访问部分元素.
因此想看元素,要么随机选一个,要么全选
sadd key value1 value2
作用: 往集合key中增加元素(一次可以增加多个元素,返回值为实际加入到集合中的个数)
srem key value1 value2
作用: 删除集合中值为 value1 value2的元素
返回值: 忽略不存在的元素后,真正删除掉的元素的个数
spop key
作用: 返回并删除集合中key中1个随机元素
随机--体现了无序性
srandmember key
作用: 返回集合key中,随机的1个元素.
sismember key value
作用: 判断value是否在key集合中
是返回1,否返回0
smembers key
作用: 返回集中中所有的元素
scard key
作用: 返回集合中元素的个数
smove source dest value
作用:把source中的value删除,并添加到dest集合中
sinter key1 key2 key3
作用: 求出key1 key2 key3 三个集合中的交集,并返回
redis 127.0.0.1:6379> sadd s1 0 2 4 6
(integer) 4
redis 127.0.0.1:6379> sadd s2 1 2 3 4
(integer) 4
redis 127.0.0.1:6379> sadd s3 4 8 9 12
(integer) 4
redis 127.0.0.1:6379> sinter s1 s2 s3
1) "4"
redis 127.0.0.1:6379> sinter s3 s1 s2
1) "4"
sinterstore dest key1 key2 key3
作用: 求出key1 key2 key3 三个集合中的交集,并赋给dest
suion key1 key2.. Keyn
作用: 求出key1 key2 keyn的并集,并返回
sdiff key1 key2 key3
作用: 求出key1与key2 key3的差集
即key1-key2-key3
order set 有序集合
zadd key score1 value1 score2 value2 ..
添加元素
redis 127.0.0.1:6379> zadd stu 18 lily 19 hmm 20 lilei 21 lilei
(integer) 3
score:排序所用的权重
zrem key value1 value2 ..
作用: 删除集合中的元素
zremrangebyscore key min max
作用: 按照socre来删除元素,删除score在[min,max]之间的
redis 127.0.0.1:6379> zremrangebyscore stu 4 10
(integer) 2
redis 127.0.0.1:6379> zrange stu 0 -1
1) "f"
zremrangebyrank key start end
作用: 按排名删除元素,删除名次在[start,end]之间的
redis 127.0.0.1:6379> zremrangebyrank stu 0 1
(integer) 2
redis 127.0.0.1:6379> zrange stu 0 -1
1) "c"
2) "e"
3) "f"
4) "g"
zrank key member
查询member的排名(升续 0名开始)
zrevrank key memeber
查询 member的排名(降续 0名开始)
ZRANGE key start stop [WITHSCORES]
把集合排序后,返回名次[start,stop]的元素
默认是升续排列
Withscores 是把score也打印出来
zrevrange key start stop
作用:把集合降序排列,取名字[start,stop]之间的元素
zrangebyscore key min max [withscores] limit offset N
作用: 集合(升续)排序后,取score在[min,max]内的元素,
并跳过 offset个, 取出N个
redis 127.0.0.1:6379> zadd stu 1 a 3 b 4 c 9 e 12 f 15 g
(integer) 6
redis 127.0.0.1:6379> zrangebyscore stu 3 12 limit 1 2 withscores
1) "c"
2) "4"
3) "e"
4) "9"
zcard key
返回元素个数
zcount key min max
返回权重在[min,max] 区间内元素的数量
zinterstore destination numkeys key1 [key2 ...]
[WEIGHTS weight [weight ...]]
[AGGREGATE SUM|MIN|MAX]
求key1,key2的交集,key1,key2的权重分别是 weight1,weight2
聚合方法用: sum |min|max
聚合的结果,保存在dest集合内
注意: weights ,aggregate如何理解?
答: 如果有交集, 交集元素又有socre,score怎么处理?
Aggregate sum->score相加 , min 求最小score, max 最大score
另: 可以通过weigth设置不同key的权重, 交集时,socre * weights
详见下例
redis 127.0.0.1:6379> zadd z1 2 a 3 b 4 c
(integer) 3
redis 127.0.0.1:6379> zadd z2 2.5 a 1 b 8 d
(integer) 3
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1
1) "b"
2) "a"
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "4"
3) "a"
4) "4.5"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 aggregate sum
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "4"
3) "a"
4) "4.5"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 aggregate min
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "1"
3) "a"
4) "2"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 weights 1 2
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "5"
3) "a"
4) "7"
Hash 哈希数据类型相关命令
hset key field value
作用: 把key中 filed域的值设为value
注:如果没有field域,直接添加,如果有,则覆盖原field域的值
hmset key field1 value1 [field2 value2 field3 value3 ......fieldn valuen]
作用: 设置field1->N 个域, 对应的值是value1->N
(对应PHP理解为 $key = array(file1=>value1, field2=>value2 ....fieldN=>valueN))
hget key field
作用: 返回key中field域的值
hmget key field1 field2 fieldN
作用: 返回key中field1 field2 fieldN域的值
hgetall key
作用:返回key中,所有域与其值
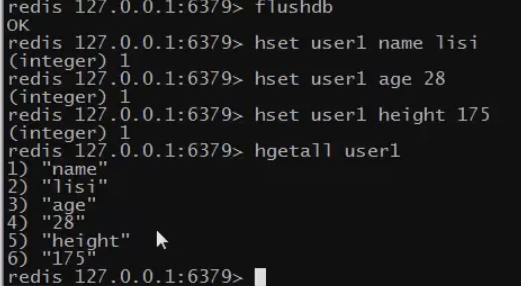
hdel key field
作用: 删除key中 field域
hlen key
作用: 返回key中元素的数量
hexists key field
作用: 判断key中有没有field域 (无返回0,有返回1)
hinrby key field value
作用: 是把key中的field域的值增长整型值value(返回增长后的值)

hinrby float key field value
作用: 是把key中的field域的值增长浮点值value

hkeys key
作用: 返回key中所有的field

hvals key
作用: 返回key中所有的value

Redis 中的事务
Redis支持简单的事务
Redis与 mysql事务的对比
|
|
Mysql |
Redis |
|
开启 |
start transaction |
muitl |
|
语句 |
普通sql |
普通命令 |
|
失败 |
rollback 回滚 |
discard 取消 |
|
成功 |
commit |
exec |
注: rollback与discard 的区别
如果已经成功执行了2条语句, 第3条语句出错.
Rollback后,前2条的语句影响消失.
Discard只是结束本次事务,前2条语句造成的影响仍然还在
注:
在mutil后面的语句中, 语句出错可能有2种情况
1: 语法就有问题,
这种,exec时,报错, 所有语句得不到执行
2: 语法本身没错,但适用对象有问题. 比如 zadd 操作list对象
Exec之后,会执行正确的语句,并跳过有不适当的语句.
(如果zadd操作list这种事怎么避免? 这一点,由程序员负责)
思考:
我正在买票
Ticket -1 , money -100
而票只有1张, 如果在我multi之后,和exec之前, 票被别人买了---即ticket变成0了.
我该如何观察这种情景,并不再提交
悲观的想法:
世界充满危险,肯定有人和我抢, 给 ticket上锁, 只有我能操作. [悲观锁]
乐观的想法:
没有那么人和我抢,因此,我只需要注意,
--有没有人更改ticket的值就可以了 [乐观锁]
Redis的事务中,启用的是乐观锁,只负责监测key没有被改动.
具体的命令---- watch命令
例:
redis 127.0.0.1:6379> watch ticket
OK
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> decr ticket
QUEUED
redis 127.0.0.1:6379> decrby money 100
QUEUED
redis 127.0.0.1:6379> exec
(nil) // 返回nil,说明监视的ticket已经改变了,事务就取消了.
redis 127.0.0.1:6379> get ticket
"0"
redis 127.0.0.1:6379> get money
"200"
watch key1 key2 ... keyN
作用:监听key1 key2..keyN有没有变化,如果有变, 则事务取消
unwatch
作用: 取消所有watch监听
消息订阅
使用办法:
订阅端: Subscribe 频道名称
发布端: publish 频道名称 发布内容
客户端例子:
redis 127.0.0.1:6379> subscribe news
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news"
3) (integer) 1
1) "message"
2) "news"
3) "good good study"
1) "message"
2) "news"
3) "day day up"
服务端例子:
redis 127.0.0.1:6379> publish news 'good good study'
(integer) 1
redis 127.0.0.1:6379> publish news 'day day up'
(integer) 1

红色的2代表的是把消息发送给了几个粉丝,也就是发送给了几个客户端(谁订阅发送给谁)
psubscribe new* 凡是以new开头的频道,我通通都监听
p代表pattern,表示可以使用通配符来进行广播的收听
Redis持久化配置
Redis的持久化有2种方式 1快照 2是日志
Rdb快照
rdb快照的意思就是,把你的内存拍张照片(形象化的说法),原模原样弄到磁盘上去
rdb是把内存的映像直接放到硬盘中,是一个二进制整块,所以恢复的时候直接把整块扔内存里,恢复速度非常快
Rdb快照原理
redis-server监控rdb的dump条件(save 900 1,save ….),一旦条件满足,调用dump子进程,把快照写到磁盘。
Rdb快照的配置选项
save 900 1 // 900内,有1条写入,则产生快照
save 300 1000 // 如果300秒内有1000次写入,则产生快照
save 60 10000 // 如果60秒内有10000次写入,则产生快照
(这3个选项都屏蔽,则rdb禁用)
注:这三个数据应该从下往上看,先看1分钟修改数量是否达到10000,如果达到,则产生快照,否则不产生快照。如果没有达到,然后再查看,300s内,是否有超过10个变化,如果有,则产生快照,否则不产生快照。就这样一层层往上看。
stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入?
rdbcompression yes // 导出的rdb文件是否压缩
Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性
dbfilename dump.rdb //导出来的rdb文件名
dir ./ //rdb的放置路径
stop-writes-on-basave-error yes详解:以前老版本的redis的持久化是这样做的。后台有一个redis-server进程,负责客户端的请求,并且同时进行导出rdb,导出rdb是比较非时间的。这就导致了一个问题,在导出rdb的过程中,客户端的请求在一段时间内得不到响应。而现在的redis呢,导出rdb是单独用一个子进程来完成的,这样在我打出rdb的过程中,依然可以处理客户端的请求,也就是客户端可以往内存里面写数据。但是这样也产生了一个问题,如果说我在导出rdb的时候,导出进程出错了,比如磁盘满了。而客户端又在不停的往内存中写数据。这样就会导致数据不一致。这在持久化中是一个非常严重的问题。所以就出现了这样一个选项,是否在导出进程出错的时候,禁止客户端写数据。
rdbcheckwum yes:如果真的出现断电等的意外情况,重启后,我们需要把导出的rdb快照文件导入到内存中,该选项的意思是在导入之前是否检测rdb快照文件被损坏过,版本是否兼容等等,是否符合我的要求
我们来模拟一下rdb的缺陷
1.修改一下配置文件,save 60 10000改为save 60 3000
2.set一个数据, set site www.baidu.com
3.使用redis-benchmark 执行10000条命令
redis-benchmark命令详解
4.执行完成后,查看目录,发现已经生成了dump.rdb文件(因为10000条命令已经达到了出发rdb的dump条件)
5.此时再set一个数据, set main www.google.com
6.使用 pkill -9 redis 模拟断电操作。
7.重启redis,get site 可以得到www.baidu
get main 得不到数据(短点的时候,main已经写入到内存中,但是没有触发dump的条件,故数据丢失)
aof日志备份
aof日志:把你干的事我都给你记录下来
aof原理
Aof 的配置
appendonly no # 是否打开 aof日志功能
appendfsync always # 每1个命令,都立即同步到aof. 安全,速度慢
appendfsync everysec # 折衷方案,每秒写1次
appendfsync no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快,
no-appendfsync-on-rewrite yes: # 正在导出rdb快照的过程中,要不要停止同步aof
注:导出rdb快照的时候是很耗费io的,内存中好几个G的内容全部同步磁盘上,需要一定的时间,得几十秒,所以为了节省io,在rdb导出的时候,暂时不同步aof。
auto-aof-rewrite-percentage 100 #aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb #aof文件,至少超过64M时,重写
注:上述两个配置是配合在一起使用的。如果只利用第一个auto-aof-rewrite-percentage 100,那么会产生一种情况,就是在初始阶段,最开始aof文件很小,那么很快就会触发重写,0到1,1到2,2到4,这写都会触发重写,所以重写的频率很高。所以就有了第二个配置auto-aof-rewrite-min-size 64mb,当着两条配置同时满足的时候,我们才触发重写。也就会说,文件大小比上次重写时的大小,增长率为100%,且文件大小达到了64M,我们才触发重写。
appendfilename:设置aof文件位置
注: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
注: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里.
以解决 aof日志过大的问题.
注:这个功能的作用是这样的,我们举一个列子,我set一个值,set a 1; 然后我不停的incr,incr次,那么此时我们的aof文件,会记录100次的incr操作。但是在一个时刻,我们的a的值只有一个,我们记录他变化的过程没有意义。当我们拿这个aof来恢复的时候,他会按照你执行的过程,也一次次的incr,把这100条incr命令都执行一遍。
当我们对一个key操作很多次的时候,aof文件会记录这个key所对应的值的变化过程,这样会使得aof文件变得非常大,我们的aof重写,就是解决这种情况的。把内存中的key和value你话成相关的命令。比如说set age 1,
然后incr100次,所以重写的就是 set age 100。
问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof
问: 2种是否可以同时用?
答: 可以,而且推荐这么做
问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
aof文件,举例查看
执行如下命令
查看产生的aof文件,可以看到里面记录了你的所有操作
立刻杀掉redis,再重启,get name依然可以得到name。如果要是rdb,可能就得不到这个值了,因为我在插入值之后,立刻杀掉了redis,此时由于rdb没有达到dump条件,所以不会把内存中的数据导出。故再次重启的时候,这些数据就丢失了。而aof,我们设置的是1S钟就向aof中写一次,所以数据丢失最多也就丢失一秒。
测试aof重写。
- 修改配置文件,把配置文件改成
auto-aof-rewrite-min-size 32mb
- 使用redis-benchmark –n 80000
- 我们可以看到aof文件在不停的变大,当大到32M的时候,触发了重写。因为最开始我们的文件大小为0,达到32M的时候,肯定是达到100%的增长条件了,而且aof文件又达到了32M,所以会触发重写。重写之后,可以看到文件甚至能达到几十K。
redis 服务器端命令
redis 127.0.0.1:6380> time ,显示服务器时间 , 时间戳(秒), 微秒数
1) "1375270361"
2) "504511"
redis 127.0.0.1:6380> dbsize // 当前数据库的key的数量
(integer) 2
redis 127.0.0.1:6380> select 2
OK
redis 127.0.0.1:6380[2]> dbsize
(integer) 0
redis 127.0.0.1:6380[2]>
BGREWRITEAOF 后台进程重写AOF
BGSAVE 后台保存rdb快照
SAVE 保存rdb快照
LASTSAVE 上次保存时间
Slaveof master-Host port , 把当前实例设为master的slave
Flushall 清空所有库所有键
Flushdb 清空当前库所有键
Showdown [save/nosave]
注: 如果不小心运行了flushall, 立即 shutdown nosave ,关闭服务器
然后 手工编辑aof文件, 去掉文件中的 “flushall ”相关行, 然后开启服务器,就可以导入回原来数据.
如果,flushall之后,系统恰好bgrewriteaof了,那么aof就清空了,数据丢失.
Slowlog 显示慢查询
注:多慢才叫慢?
答: 由slowlog-log-slower-than 10000 ,来指定,(单位是微秒)
服务器储存多少条慢查询的记录?
答: 由 slowlog-max-len 128 ,来做限制
Info [Replication/CPU/Memory..]
查看redis服务器的信息
Config get 配置项
Config set 配置项 值 (特殊的选项,不允许用此命令设置,如slave-of, 需要用单独的slaveof命令来设置)
Redis运维时需要注意的参数
1: 内存
# Memory
used_memory:859192 数据结构的空间
used_memory_rss:7634944 实占空间
mem_fragmentation_ratio:8.89 前2者的比例,1.N为佳,如果此值过大,说明redis的内存的碎片化严重,可以导出再导入一次.
2: 主从复制
# Replication
role:slave
master_host:192.168.1.128
master_port:6379
master_link_status:up
3:持久化
# Persistence
rdb_changes_since_last_save:0
rdb_last_save_time:1375224063
4: fork耗时
#Status
latest_fork_usec:936 上次导出rdb快照,持久化花费微秒
注意: 如果某实例有10G内容,导出需要2分钟,
每分钟写入10000次,导致不断的rdb导出,磁盘始处于高IO状态.
5: 慢日志
config get/set slowlog-log-slower-than
CONFIG get/SET slowlog-max-len
slowlog get N 获取慢日志
运行时更改master-slave
修改一台slave(设为A)为new master
1) 命令该服务不做其他redis服务的slave
命令: slaveof no one
2) 修改其readonly为yes
其他的slave再指向new master A
1) 命令该服务为new master A的slave
命令格式 slaveof IP port
监控工具 sentinel
Sentinel不断与master通信,获取master的slave信息.
监听master与slave的状态
如果某slave失效,直接通知master去除该slave.
如果master失效,,是按照slave优先级(可配置), 选取1个slave做 new master
,把其他slave--> new master
疑问: sentinel与master通信,如果某次因为master IO操作频繁,导致超时,
此时,认为master失效,很武断.
解决: sentnel允许多个实例看守1个master, 当N台(N可设置)sentinel都认为master失效,才正式失效.
Sentinel选项配置
port 26379 # 端口
sentinel monitor mymaster 127.0.0.1 6379 2 ,
给主机起的名字(不重即可),
当2个sentinel实例都认为master失效时,正式失效
sentinel down-after-milliseconds mymaster 30000 多少毫秒后连接不到master认为断开
sentinel can-failover mymaster yes #是否允许sentinel修改slave->master. 如为no,则只能监控,无权修改./
sentinel parallel-syncs mymaster 1 , 一次性修改几个slave指向新的new master.
sentinel client-reconfig-script mymaster
/var/redis/reconfig.sh ,# 在重新配置new master,new slave过程,可以触发的脚本
redis 与关系型数据库的适合场景
书签系统
create table book (
bookid int,
title char(20)
)engine myisam charset utf8;
insert into book values
(5 , 'PHP圣经'),
(6 , 'ruby实战'),
(7 , 'mysql运维')
(8, 'ruby服务端编程');
create table tags (
tid int,
bookid int,
content char(20)
)engine myisam charset utf8;
insert into tags values
(10 , 5 , 'PHP'),
(11 , 5 , 'WEB'),
(12 , 6 , 'WEB'),
(13 , 6 , 'ruby'),
(14 , 7 , 'database'),
(15 , 8 , 'ruby'),
(16 , 8 , 'server');
# 既有web标签,又有PHP,同时还标签的书,要用连接查询
select * from tags inner join tags as t on tags.bookid=t.bookid
where tags.content='PHP' and t.content='WEB';
换成key-value存储
用kv 来存储
set book:5:title 'PHP圣经'
set book:6:title 'ruby实战'
set book:7:title 'mysql运难'
set book:8:title ‘ruby server’
sadd tag:PHP 5
sadd tag:WEB 5 6
sadd tag:database 7
sadd tag:ruby 6 8
sadd tag:SERVER 8
查: 既有PHP,又有WEB的书
Sinter tag:PHP tag:WEB #查集合的交集
查: 有PHP或有WEB标签的书
Sunin tag:PHP tag:WEB
查:含有ruby,不含WEB标签的书
Sdiff tag:ruby tag:WEB #求差集
Redis key 设计技巧
1: 把表名转换为key前缀 如, tag:
2: 第2段放置用于区分区key的字段--对应mysql中的主键的列名,如userid
3: 第3段放置主键值,如2,3,4...., a , b ,c
4: 第4段,写要存储的列名
|
用户表 user , 转换为key-value存储 |
|||
|
userid |
username |
passworde |
|
|
9 |
Lisi |
1111111 |
lisi@163.com |
set user:userid:9:username lisi
set user:userid:9:password 111111
set user:userid:9:email lisi@163.com
keys user:userid:9*
2 注意:
在关系型数据中,除主键外,还有可能其他列也步骤查询,
如上表中, username 也是极频繁查询的,往往这种列也是加了索引的.
转换到k-v数据中,则也要相应的生成一条按照该列为主的key-value
Set user:username:lisi:uid 9
这样,我们可以根据username:lisi:uid ,查出userid=9,
再查user:9:password/email ...
完成了根据用户名来查询用户信息
php-redis扩展编译
1: 到pecl.php.net 搜索redis
2: 下载stable版(稳定版)扩展
3: 解压,
4: 执行/php/path/bin/phpize (作用是检测PHP的内核版本,并为扩展生成相应的编译配置)
5: configure --with-php-config=/php/path/bin/php-config
6: make && make install
引入编译出的redis.so插件
1: 编辑php.ini
2: 添加
redis插件的使用
// get instance
$redis = new Redis();
// connect to redis server
$redis->open('localhost',6380);
$redis->set('user:userid:9:username','wangwu');
var_dump($redis->get('user:userid:9:username'));
微博项目的key设计
全局相关的key:
|
表名 |
global |
|
|
列名 |
操作 |
备注 |
|
Global:userid |
incr |
产生全局的userid |
|
Global:postid |
Incr |
产生全局的postid |
用户相关的key(表)
|
表名 |
user |
||
|
Userid |
Username |
Password |
Authsecret |
|
3 |
Test3 |
1111111 |
#U*Q(%_ |
在redis中,变成以下几个key
|
Key前缀 |
user |
||
|
User:Userid:* |
User:userid:*Username |
User:userid:*Password |
User:userid:*:Authsecret |
|
User:userid:3 |
User:userid:3:Test3 |
User:userid:3:1111111 |
User:userid:3:#U*Q(%_ |
微博相关的表设计
|
表名 |
post |
|
|
|
|
Postid |
Userid |
Username |
Time |
Content |
|
4 |
2 |
Lisi |
1370987654f |
测试内容 |
微博在redis中,与表设计对应的key设计
|
Key前缀 |
post |
|
|
|
|
Post:Postid:* |
Post:postid:*Userid |
Post:postid:*:Username |
Post:postid:*:Time |
Post:postid:*:Content |
|
4 |
2 |
Lisi |
1370987654f |
测试内容 |
|
set |
关注表: following
Following:$userid -->
|
set |
粉丝表
Follower:$userid --->
推送表:revicepost
|
Recivepost:$userid |
|
3 |
4 |
7 |
|
|
|
=================拉模型,改进=====================
拉取表
|
Pull:$userid: |
|
3 |
4 |
7 |
|
|
|
问: 上次我拉取了 A->5,67,三条微博, 下次刷新home.php, 从>7的微博开始拉取
解决: 拉取时,设定一个lastpull时间点, 下次拉取时,取>lastpull的微博
问: 有很多关注人,如何取?
解决: 循环自己的关注列表,逐个取他们的新微博
问: 取出来之后放在哪儿?
答: pull:$userid的链接里
问: 如果个人中心,只有前1000条
答: ltrim,只取前1000条
问: 如果我关注 A,B两人, 从2人中,各取3条最新信息
,这3+3条信息, 从时间上,是交错的, 如何按时间排序?
答: 我们发布时, 是发布的hash结构, 不能按时间来排序.
解决: 同步时,取微博后,记录本次取的微博的最大id,
下次同步时,只取比最大id更大的微博
Time taken for tests: 32.690 seconds
Complete requests: 20000
Failed requests: 0
Write errors: 0
Non-2xx responses: 20000
Total transferred: 13520000 bytes
Total POSTed: 5340000
HTML transferred: 9300000 bytes
Requests per second: 611.80 [#/sec] (mean)
Time per request: 81.726 [ms] (mean)
Time per request: 1.635 [ms] (mean, across all concurrent requests)
Transfer rate: 403.88 [Kbytes/sec] received
159.52 kb/s sent
563.41 kb/s total
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.9 0 19
Processing: 14 82 8.4 81 153
Waiting: 4 82 8.4 80 153
Total: 20 82 8.2 81 153
Percentage of the requests served within a certain time (ms)
50% 81
66% 84
75% 86
80% 88
90% 93
95% 96
98% 100
99% 103
100% 153 (longest request)
测试结果:
50个并发, 20000次请求, 虚拟下,未做特殊优化
每次请求redis写操作6次.
30+秒左右完成.
平均每秒发布700条微博, 4000次redis写入.
后台定时任务,回归冷数据入mysql
Redis配置文件
daemonize yes # redis是否以后台进程运行
Requirepass 密码 # 配置redis连接的密码
注:配置密码后,客户端连上服务器,需要先执行授权命令
# auth 密码
8: 复制配置文件
从源代码目录复制一份配置文件,复制到redis的安装根目录
9: 启动与连接
/path/to/redis/bin/redis-server ./path/to/conf-file
例:
连接: 用redis-cli
#/path/to/redis/bin/redis-cli [-h localhost -p 6379 ]
10: 让redis以后台进程的形式运行
编辑conf配置文件,修改如下内容;
daemonize yes
Redis对于key的操作命令
del key1 key2 ... Keyn
作用: 删除1个或多个键
返回值: 不存在的key忽略掉,返回真正删除的key的数量
rename key newkey
作用: 给key赋一个新的key名
注:如果newkey已存在,则newkey的原值被覆盖
renamenx key newkey
作用: 把key改名为newkey
返回: 发生修改返回1,未发生修改返回0
注: nx--> not exists, 即, newkey不存在时,作改名动作,newkey存在则不做修改
move key db
redis 127.0.0.1:6379[1]> select 2 //选择1号数据库,相当于mysql中的use database命令
OK
redis 127.0.0.1:6379[2]> keys *
(empty list or set)
redis 127.0.0.1:6379[2]> select 0 //选择0号数据库
OK
redis 127.0.0.1:6379> keys *
1) "name"
2) "cc"
3) "a"
4) "b"
redis 127.0.0.1:6379> move cc 2 //把key=cc的数据一道2号数据库中
(integer) 1
redis 127.0.0.1:6379> select 2 //选择2号数据库
OK
redis 127.0.0.1:6379[2]> keys * //可以查询到cc
1) "cc"
redis 127.0.0.1:6379[2]> get cc
"3"
(注意: 一个redis进程,打开了不止一个数据库, 默认打开16个数据库,从0到15编号,
如果想打开更多数据库,可以从配置文件修改) 默认使用第0个数据库
keys pattern 查询相应的key
在redis里,允许模糊查询key
有3个通配符 *, ? ,[]
*: 通配任意多个字符
?: 通配单个字符
[]: 通配括号内的某1个字符
redis 127.0.0.1:6379> flushdb
OK
redis 127.0.0.1:6379> keys *
(empty list or set)
redis 127.0.0.1:6379> mset one 1 two 2 three 3 four 4
OK
redis 127.0.0.1:6379> keys o*
1) "one"
redis 127.0.0.1:6379> key *o
(error) ERR unknown command 'key'
redis 127.0.0.1:6379> keys *o
1) "two"
redis 127.0.0.1:6379> keys ???
1) "one"
2) "two"
redis 127.0.0.1:6379> keys on?
1) "one"
redis 127.0.0.1:6379> set ons yes
OK
redis 127.0.0.1:6379> keys on[eaw]
1) "one"
randomkey 返回随机key
exists key
判断key是否存在,返回1/0
type key
返回key存储的值的类型
有string,link,set,order set, hash
ttl key
作用: 查询key的生命周期
返回: 秒数
注:对于不存在的key或已过期的key/不过期的key,都返回-1
Redis2.8中,对于不存在的key,返回-2
expire key 整型值
作用: 设置key的生命周期,以秒为单位
同理:
pexpire key 毫秒数, 设置生命周期
pttl key, 以毫秒返回生命周期
persist key
作用: 把指定key置为永久有效
Redis字符串类型的操作
之前讲解用的都是set命令,其实set命令设置的值就是字符串
set key value [ex 秒数] / [px 毫秒数] [nx] /[xx]
如: set a 1 ex 10 , 10秒有效
Set a 1 px 9000 , 9秒有效
注: 如果ex,px同时写,以后面的有效期为准
如 set a 1 ex 100 px 9000, 实际有效期是9000毫秒
nx: 表示key不存在时,执行操作
xx: 表示key存在时,执行操作(相当于对存在的key进行更改)
mset multi set , 一次性设置多个键值
例: mset key1 v1 key2 v2 ....
get key
作用:获取key的值
mget key1 key2 ..keyn
作用:获取多个key的值
setrange key offset value
作用:把字符串的offset偏移字节,改成value
redis 127.0.0.1:6379> set greet hello
OK
redis 127.0.0.1:6379> setrange greet 2 x
(integer) 5
redis 127.0.0.1:6379> get greet
"hexlo"
注意: 如果偏移量>字符长度, 该字符自动补0x00
redis 127.0.0.1:6379> setrange greet 6 !
(integer) 7
redis 127.0.0.1:6379> get greet
"heyyo\x00!"
append key value
作用: 把value追加到key的原值上
getrange key start stop
作用: 是获取字符串中 [start, stop]范围的值
注意: 对于字符串的下标,左数从0开始,右数从-1开始
redis 127.0.0.1:6379> set title 'chinese'
OK
redis 127.0.0.1:6379> getrange title 0 3
"chin"
redis 127.0.0.1:6379> getrange title 1 -2
"hines"
注意:
1: start>=length, 则返回空字符串
2: stop>=length,则截取至字符结尾
3: 如果start 所处位置在stop右边, 返回空字符串
getset key newvalue
作用: 获取并返回旧值,设置新值
redis 127.0.0.1:6379> set cnt 0
OK
redis 127.0.0.1:6379> getset cnt 1
"0"
redis 127.0.0.1:6379> getset cnt 2
"1"
incr key (秒杀?)
作用: 指定的key的值加1,并返回加1后的值
注意:
1:不存在的key当成0,再incr操作
2: 范围为64有符号
incrby key number
redis 127.0.0.1:6379> incrby age 90
(integer) 92
incrbyfloat key floatnumber
redis 127.0.0.1:6379> incrbyfloat age 3.5
"95.5"
decr key
redis 127.0.0.1:6379> set age 20
OK
redis 127.0.0.1:6379> decr age
(integer) 19
decrby key number
redis 127.0.0.1:6379> decrby age 3
(integer) 16
getbit key offset
作用:获取值的二进制表示,对应位上的值(从左,从0编号)
redis 127.0.0.1:6379> set char A
OK
redis 127.0.0.1:6379> getbit char 1
(integer) 1
redis 127.0.0.1:6379> getbit char 2
(integer) 0
redis 127.0.0.1:6379> getbit char 7
(integer) 1
setbit key offset value
设置offset对应二进制位上的值
返回: 该位上的旧值
注意:
1:如果offset过大,则会在中间填充0,
2: offset最大大到多少
3:offset最大2^32-1,可推出最大的的字符串为512M
2^32=4294967296
bitop operation destkey key1 [key2 ...]
对key1,key2..keyN作operation,并将结果保存到 destkey 上。
operation 可以是 AND 、 OR 、 NOT 、 XOR
redis 127.0.0.1:6379> setbit lower 7 0
(integer) 0
redis 127.0.0.1:6379> setbit lower 2 1
(integer) 0
redis 127.0.0.1:6379> get lower
" "
redis 127.0.0.1:6379> set char Q
OK
redis 127.0.0.1:6379> get char
"Q"
redis 127.0.0.1:6379> bitop or char char lower
(integer) 1
redis 127.0.0.1:6379> get char
"q"
注意: 对于NOT操作, key不能多个
link 链表结构
lpush key value
作用: 把值插入到链接头部
rpop key
作用: 返回并删除链表尾元素
rpush,lpop: 不解释
如果链表本来为空lpush rpush没区别
lrange key start stop
作用: 返回链表中[start ,stop]中的元素
规律: 左数从0开始,右数从-1开始
查看链表所有元素
lrem key count value
作用: 从key链表中删除 value值
注: 删除count的绝对值个value后结束
Count>0 从表头删除
Count<0 从表尾删除
ltrim key start stop
作用: 剪切key对应的链接,切[start,stop]一段,并把该段重新赋给key
lindex key index
作用: 返回index索引上的值,
如 lindex key 2
llen key
作用:计算链接表的元素个数
redis 127.0.0.1:6379> llen task
(integer) 3
redis 127.0.0.1:6379>
linsert key after|before search value
作用: 在key链表中寻找’search’,并在search值之前|之后,.插入value
注: 一旦找到一个search后,命令就结束了,因此不会插入多个value
rpoplpush source dest
作用: 把source的尾部拿出,放在dest的头部,
并返回 该单元值
场景: task + bak 双链表完成安全队列
Task列表 bak列表
|
|
|
|
|
|
|
|
业务逻辑:
1:Rpoplpush task bak
2:接收返回值,并做业务处理
3:如果成功,rpop bak 清除任务. 如不成功,下次从bak表里取任务
注:意思是这样的,Task列表中,存放着系统待处理的任务,我依次的使用rpop,从列表中弹出任务,来进行处理。此时如果要是任务失败了,但是我们的数据又从Task列表中pop出来了。我们就不好处理了。所以这条命令就体现出所用了。我们每处理一条任务的时候,先pop,然后再push进bak列表,如果任务成功了,我们再把这个任务从bak列表中删除。如果没成功,那么就存在bak列表中。这样bak列表最后存储的不都是任务失败的记录了吗。或者失败之后我们再次执行任务就直接从bak列表中取任务(rpop)不就可以了吗。
brpop ,blpop key timeout
作用:等待弹出key的尾/头元素,
Timeout为等待超时时间
如果timeout为0,则一直等待
场景: 长轮询Ajax,在线聊天时,能够用到
注:把说的话都push进这个链表,如果没有话说,我就一直等着,如果有内容push进来,我就pop出去
在客户端1中执行rpop命令
我在客户端2中,push进来一个e字符
在客户端1中,立刻就被pop出来了。
Setbit 的实际应用
场景: 1亿个用户, 每个用户 登陆/做任意操作 ,记为 今天活跃,否则记为不活跃
每周评出: 有奖活跃用户: 连续7天活动
每月评,等等...
思路:
Userid dt active
1 2013-07-27 1
1 2013-0726 1
如果是放在表中, 1:表急剧增大,2:要用group ,sum运算,计算较慢
用: 位图法 bit-map
Log0721: ‘011001...............0’
......
log0726 : ‘011001...............0’
Log0727 : ‘0110000.............1’
1: 记录用户登陆:
每天按日期生成一个位图, 用户登陆后,把user_id位上的bit值置为1
2: 把1周的位图 and 计算,
位上为1的,即是连续登陆的用户
redis 127.0.0.1:6379> setbit mon 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit mon 3 1
(integer) 0
redis 127.0.0.1:6379> setbit mon 5 1
(integer) 0
redis 127.0.0.1:6379> setbit mon 7 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit thur 3 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 5 1
(integer) 0
redis 127.0.0.1:6379> setbit thur 8 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 100000000 0
(integer) 0
redis 127.0.0.1:6379> setbit wen 3 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 4 1
(integer) 0
redis 127.0.0.1:6379> setbit wen 6 1
(integer) 0
redis 127.0.0.1:6379> bitop and res mon feb wen
(integer) 12500001
如上例,优点:
1: 节约空间, 1亿人每天的登陆情况,用1亿bit,约1200WByte,约10M 的字符就能表示
2: 计算方便
集合 set 相关命令
集合的性质: 唯一性,无序性,确定性(确定性指的是能够描述)
注: 在string和link的命令中,可以通过range 来访问string中的某几个字符或某几个元素
但,因为集合的无序性,无法通过下标或范围来访问部分元素.
因此想看元素,要么随机选一个,要么全选
sadd key value1 value2
作用: 往集合key中增加元素(一次可以增加多个元素,返回值为实际加入到集合中的个数)
srem key value1 value2
作用: 删除集合中值为 value1 value2的元素
返回值: 忽略不存在的元素后,真正删除掉的元素的个数
spop key
作用: 返回并删除集合中key中1个随机元素
随机--体现了无序性
srandmember key
作用: 返回集合key中,随机的1个元素.
sismember key value
作用: 判断value是否在key集合中
是返回1,否返回0
smembers key
作用: 返回集中中所有的元素
scard key
作用: 返回集合中元素的个数
smove source dest value
作用:把source中的value删除,并添加到dest集合中
sinter key1 key2 key3
作用: 求出key1 key2 key3 三个集合中的交集,并返回
redis 127.0.0.1:6379> sadd s1 0 2 4 6
(integer) 4
redis 127.0.0.1:6379> sadd s2 1 2 3 4
(integer) 4
redis 127.0.0.1:6379> sadd s3 4 8 9 12
(integer) 4
redis 127.0.0.1:6379> sinter s1 s2 s3
1) "4"
redis 127.0.0.1:6379> sinter s3 s1 s2
1) "4"
sinterstore dest key1 key2 key3
作用: 求出key1 key2 key3 三个集合中的交集,并赋给dest
suion key1 key2.. Keyn
作用: 求出key1 key2 keyn的并集,并返回
sdiff key1 key2 key3
作用: 求出key1与key2 key3的差集
即key1-key2-key3
order set 有序集合
zadd key score1 value1 score2 value2 ..
添加元素
redis 127.0.0.1:6379> zadd stu 18 lily 19 hmm 20 lilei 21 lilei
(integer) 3
score:排序所用的权重
zrem key value1 value2 ..
作用: 删除集合中的元素
zremrangebyscore key min max
作用: 按照socre来删除元素,删除score在[min,max]之间的
redis 127.0.0.1:6379> zremrangebyscore stu 4 10
(integer) 2
redis 127.0.0.1:6379> zrange stu 0 -1
1) "f"
zremrangebyrank key start end
作用: 按排名删除元素,删除名次在[start,end]之间的
redis 127.0.0.1:6379> zremrangebyrank stu 0 1
(integer) 2
redis 127.0.0.1:6379> zrange stu 0 -1
1) "c"
2) "e"
3) "f"
4) "g"
zrank key member
查询member的排名(升续 0名开始)
zrevrank key memeber
查询 member的排名(降续 0名开始)
ZRANGE key start stop [WITHSCORES]
把集合排序后,返回名次[start,stop]的元素
默认是升续排列
Withscores 是把score也打印出来
zrevrange key start stop
作用:把集合降序排列,取名字[start,stop]之间的元素
zrangebyscore key min max [withscores] limit offset N
作用: 集合(升续)排序后,取score在[min,max]内的元素,
并跳过 offset个, 取出N个
redis 127.0.0.1:6379> zadd stu 1 a 3 b 4 c 9 e 12 f 15 g
(integer) 6
redis 127.0.0.1:6379> zrangebyscore stu 3 12 limit 1 2 withscores
1) "c"
2) "4"
3) "e"
4) "9"
zcard key
返回元素个数
zcount key min max
返回权重在[min,max] 区间内元素的数量
zinterstore destination numkeys key1 [key2 ...]
[WEIGHTS weight [weight ...]]
[AGGREGATE SUM|MIN|MAX]
求key1,key2的交集,key1,key2的权重分别是 weight1,weight2
聚合方法用: sum |min|max
聚合的结果,保存在dest集合内
注意: weights ,aggregate如何理解?
答: 如果有交集, 交集元素又有socre,score怎么处理?
Aggregate sum->score相加 , min 求最小score, max 最大score
另: 可以通过weigth设置不同key的权重, 交集时,socre * weights
详见下例
redis 127.0.0.1:6379> zadd z1 2 a 3 b 4 c
(integer) 3
redis 127.0.0.1:6379> zadd z2 2.5 a 1 b 8 d
(integer) 3
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1
1) "b"
2) "a"
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "4"
3) "a"
4) "4.5"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 aggregate sum
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "4"
3) "a"
4) "4.5"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 aggregate min
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "1"
3) "a"
4) "2"
redis 127.0.0.1:6379> zinterstore tmp 2 z1 z2 weights 1 2
(integer) 2
redis 127.0.0.1:6379> zrange tmp 0 -1 withscores
1) "b"
2) "5"
3) "a"
4) "7"
Hash 哈希数据类型相关命令
hset key field value
作用: 把key中 filed域的值设为value
注:如果没有field域,直接添加,如果有,则覆盖原field域的值
hmset key field1 value1 [field2 value2 field3 value3 ......fieldn valuen]
作用: 设置field1->N 个域, 对应的值是value1->N
(对应PHP理解为 $key = array(file1=>value1, field2=>value2 ....fieldN=>valueN))
hget key field
作用: 返回key中field域的值
hmget key field1 field2 fieldN
作用: 返回key中field1 field2 fieldN域的值
hgetall key
作用:返回key中,所有域与其值
hdel key field
作用: 删除key中 field域
hlen key
作用: 返回key中元素的数量
hexists key field
作用: 判断key中有没有field域 (无返回0,有返回1)
hinrby key field value
作用: 是把key中的field域的值增长整型值value(返回增长后的值)
hinrby float key field value
作用: 是把key中的field域的值增长浮点值value
hkeys key
作用: 返回key中所有的field
hvals key
作用: 返回key中所有的value
Redis 中的事务
Redis支持简单的事务
Redis与 mysql事务的对比
|
|
Mysql |
Redis |
|
开启 |
start transaction |
muitl |
|
语句 |
普通sql |
普通命令 |
|
失败 |
rollback 回滚 |
discard 取消 |
|
成功 |
commit |
exec |
注: rollback与discard 的区别
如果已经成功执行了2条语句, 第3条语句出错.
Rollback后,前2条的语句影响消失.
Discard只是结束本次事务,前2条语句造成的影响仍然还在
注:
在mutil后面的语句中, 语句出错可能有2种情况
1: 语法就有问题,
这种,exec时,报错, 所有语句得不到执行
2: 语法本身没错,但适用对象有问题. 比如 zadd 操作list对象
Exec之后,会执行正确的语句,并跳过有不适当的语句.
(如果zadd操作list这种事怎么避免? 这一点,由程序员负责)
思考:
我正在买票
Ticket -1 , money -100
而票只有1张, 如果在我multi之后,和exec之前, 票被别人买了---即ticket变成0了.
我该如何观察这种情景,并不再提交
悲观的想法:
世界充满危险,肯定有人和我抢, 给 ticket上锁, 只有我能操作. [悲观锁]
乐观的想法:
没有那么人和我抢,因此,我只需要注意,
--有没有人更改ticket的值就可以了 [乐观锁]
Redis的事务中,启用的是乐观锁,只负责监测key没有被改动.
具体的命令---- watch命令
例:
redis 127.0.0.1:6379> watch ticket
OK
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> decr ticket
QUEUED
redis 127.0.0.1:6379> decrby money 100
QUEUED
redis 127.0.0.1:6379> exec
(nil) // 返回nil,说明监视的ticket已经改变了,事务就取消了.
redis 127.0.0.1:6379> get ticket
"0"
redis 127.0.0.1:6379> get money
"200"
watch key1 key2 ... keyN
作用:监听key1 key2..keyN有没有变化,如果有变, 则事务取消
unwatch
作用: 取消所有watch监听
消息订阅
使用办法:
订阅端: Subscribe 频道名称
发布端: publish 频道名称 发布内容
客户端例子:
redis 127.0.0.1:6379> subscribe news
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news"
3) (integer) 1
1) "message"
2) "news"
3) "good good study"
1) "message"
2) "news"
3) "day day up"
服务端例子:
redis 127.0.0.1:6379> publish news 'good good study'
(integer) 1
redis 127.0.0.1:6379> publish news 'day day up'
(integer) 1

红色的2代表的是把消息发送给了几个粉丝,也就是发送给了几个客户端(谁订阅发送给谁)
psubscribe new* 凡是以new开头的频道,我通通都监听
p代表pattern,表示可以使用通配符来进行广播的收听
Redis持久化配置
Redis的持久化有2种方式 1快照 2是日志
Rdb快照
rdb快照的意思就是,把你的内存拍张照片(形象化的说法),原模原样弄到磁盘上去
rdb是把内存的映像直接放到硬盘中,是一个二进制整块,所以恢复的时候直接把整块扔内存里,恢复速度非常快
Rdb快照原理
redis-server监控rdb的dump条件(save 900 1,save ….),一旦条件满足,调用dump子进程,把快照写到磁盘。

Rdb快照的配置选项
save 900 1 // 900内,有1条写入,则产生快照
save 300 1000 // 如果300秒内有1000次写入,则产生快照
save 60 10000 // 如果60秒内有10000次写入,则产生快照
(这3个选项都屏蔽,则rdb禁用)
注:这三个数据应该从下往上看,先看1分钟修改数量是否达到10000,如果达到,则产生快照,否则不产生快照。如果没有达到,然后再查看,300s内,是否有超过10个变化,如果有,则产生快照,否则不产生快照。就这样一层层往上看。
stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入?
rdbcompression yes // 导出的rdb文件是否压缩
Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性
dbfilename dump.rdb //导出来的rdb文件名
dir ./ //rdb的放置路径

stop-writes-on-basave-error yes详解:以前老版本的redis的持久化是这样做的。后台有一个redis-server进程,负责客户端的请求,并且同时进行导出rdb,导出rdb是比较非时间的。这就导致了一个问题,在导出rdb的过程中,客户端的请求在一段时间内得不到响应。而现在的redis呢,导出rdb是单独用一个子进程来完成的,这样在我打出rdb的过程中,依然可以处理客户端的请求,也就是客户端可以往内存里面写数据。但是这样也产生了一个问题,如果说我在导出rdb的时候,导出进程出错了,比如磁盘满了。而客户端又在不停的往内存中写数据。这样就会导致数据不一致。这在持久化中是一个非常严重的问题。所以就出现了这样一个选项,是否在导出进程出错的时候,禁止客户端写数据。
rdbcheckwum yes:如果真的出现断电等的意外情况,重启后,我们需要把导出的rdb快照文件导入到内存中,该选项的意思是在导入之前是否检测rdb快照文件被损坏过,版本是否兼容等等,是否符合我的要求

我们来模拟一下rdb的缺陷
1.修改一下配置文件,save 60 10000改为save 60 3000
2.set一个数据, set site www.baidu.com
3.使用redis-benchmark 执行10000条命令

redis-benchmark命令详解

4.执行完成后,查看目录,发现已经生成了dump.rdb文件(因为10000条命令已经达到了出发rdb的dump条件)
5.此时再set一个数据, set main www.google.com
6.使用 pkill -9 redis 模拟断电操作。
7.重启redis,get site 可以得到www.baidu
get main 得不到数据(短点的时候,main已经写入到内存中,但是没有触发dump的条件,故数据丢失)
aof日志备份
aof日志:把你干的事我都给你记录下来
aof原理
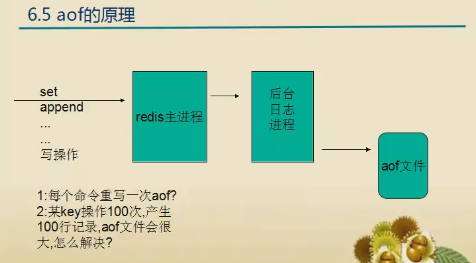
Aof 的配置
appendonly no # 是否打开 aof日志功能
appendfsync always # 每1个命令,都立即同步到aof. 安全,速度慢
appendfsync everysec # 折衷方案,每秒写1次
appendfsync no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快,
no-appendfsync-on-rewrite yes: # 正在导出rdb快照的过程中,要不要停止同步aof
注:导出rdb快照的时候是很耗费io的,内存中好几个G的内容全部同步磁盘上,需要一定的时间,得几十秒,所以为了节省io,在rdb导出的时候,暂时不同步aof。
auto-aof-rewrite-percentage 100 #aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb #aof文件,至少超过64M时,重写
注:上述两个配置是配合在一起使用的。如果只利用第一个auto-aof-rewrite-percentage 100,那么会产生一种情况,就是在初始阶段,最开始aof文件很小,那么很快就会触发重写,0到1,1到2,2到4,这写都会触发重写,所以重写的频率很高。所以就有了第二个配置auto-aof-rewrite-min-size 64mb,当着两条配置同时满足的时候,我们才触发重写。也就会说,文件大小比上次重写时的大小,增长率为100%,且文件大小达到了64M,我们才触发重写。
appendfilename:设置aof文件位置

注: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
注: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里.
以解决 aof日志过大的问题.
注:这个功能的作用是这样的,我们举一个列子,我set一个值,set a 1; 然后我不停的incr,incr次,那么此时我们的aof文件,会记录100次的incr操作。但是在一个时刻,我们的a的值只有一个,我们记录他变化的过程没有意义。当我们拿这个aof来恢复的时候,他会按照你执行的过程,也一次次的incr,把这100条incr命令都执行一遍。
当我们对一个key操作很多次的时候,aof文件会记录这个key所对应的值的变化过程,这样会使得aof文件变得非常大,我们的aof重写,就是解决这种情况的。把内存中的key和value你话成相关的命令。比如说set age 1,
然后incr100次,所以重写的就是 set age 100。
问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof


问: 2种是否可以同时用?
答: 可以,而且推荐这么做
问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
aof文件,举例查看
执行如下命令
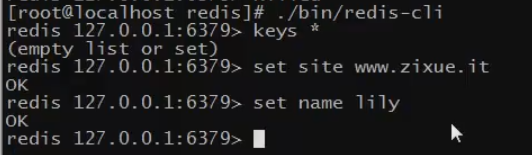
查看产生的aof文件,可以看到里面记录了你的所有操作
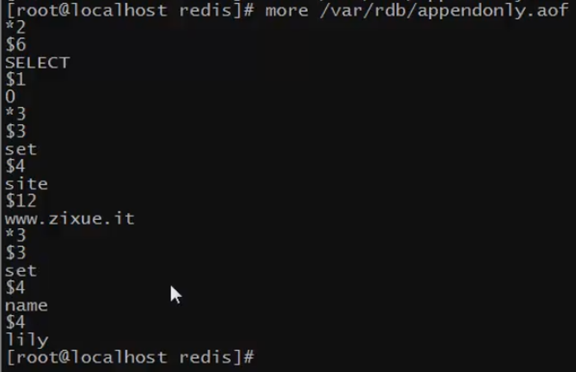
立刻杀掉redis,再重启,get name依然可以得到name。如果要是rdb,可能就得不到这个值了,因为我在插入值之后,立刻杀掉了redis,此时由于rdb没有达到dump条件,所以不会把内存中的数据导出。故再次重启的时候,这些数据就丢失了。而aof,我们设置的是1S钟就向aof中写一次,所以数据丢失最多也就丢失一秒。

测试aof重写。
- 修改配置文件,把配置文件改成
auto-aof-rewrite-min-size 32mb
- 使用redis-benchmark –n 80000
- 我们可以看到aof文件在不停的变大,当大到32M的时候,触发了重写。因为最开始我们的文件大小为0,达到32M的时候,肯定是达到100%的增长条件了,而且aof文件又达到了32M,所以会触发重写。重写之后,可以看到文件甚至能达到几十K。


redis 服务器端命令
redis 127.0.0.1:6380> time ,显示服务器时间 , 时间戳(秒), 微秒数
1) "1375270361"
2) "504511"
redis 127.0.0.1:6380> dbsize // 当前数据库的key的数量
(integer) 2
redis 127.0.0.1:6380> select 2
OK
redis 127.0.0.1:6380[2]> dbsize
(integer) 0
redis 127.0.0.1:6380[2]>
BGREWRITEAOF 后台进程重写AOF
BGSAVE 后台保存rdb快照
SAVE 保存rdb快照
LASTSAVE 上次保存时间
Slaveof master-Host port , 把当前实例设为master的slave
Flushall 清空所有库所有键
Flushdb 清空当前库所有键
Showdown [save/nosave]
注: 如果不小心运行了flushall, 立即 shutdown nosave ,关闭服务器
然后 手工编辑aof文件, 去掉文件中的 “flushall ”相关行, 然后开启服务器,就可以导入回原来数据.
如果,flushall之后,系统恰好bgrewriteaof了,那么aof就清空了,数据丢失.
Slowlog 显示慢查询
注:多慢才叫慢?
答: 由slowlog-log-slower-than 10000 ,来指定,(单位是微秒)
服务器储存多少条慢查询的记录?
答: 由 slowlog-max-len 128 ,来做限制
Info [Replication/CPU/Memory..]
查看redis服务器的信息
Config get 配置项
Config set 配置项 值 (特殊的选项,不允许用此命令设置,如slave-of, 需要用单独的slaveof命令来设置)
Redis运维时需要注意的参数
1: 内存
# Memory
used_memory:859192 数据结构的空间
used_memory_rss:7634944 实占空间
mem_fragmentation_ratio:8.89 前2者的比例,1.N为佳,如果此值过大,说明redis的内存的碎片化严重,可以导出再导入一次.
2: 主从复制
# Replication
role:slave
master_host:192.168.1.128
master_port:6379
master_link_status:up
3:持久化
# Persistence
rdb_changes_since_last_save:0
rdb_last_save_time:1375224063
4: fork耗时
#Status
latest_fork_usec:936 上次导出rdb快照,持久化花费微秒
注意: 如果某实例有10G内容,导出需要2分钟,
每分钟写入10000次,导致不断的rdb导出,磁盘始处于高IO状态.
5: 慢日志
config get/set slowlog-log-slower-than
CONFIG get/SET slowlog-max-len
slowlog get N 获取慢日志
运行时更改master-slave
修改一台slave(设为A)为new master
1) 命令该服务不做其他redis服务的slave
命令: slaveof no one
2) 修改其readonly为yes
其他的slave再指向new master A
1) 命令该服务为new master A的slave
命令格式 slaveof IP port
监控工具 sentinel
Sentinel不断与master通信,获取master的slave信息.
监听master与slave的状态
如果某slave失效,直接通知master去除该slave.
如果master失效,,是按照slave优先级(可配置), 选取1个slave做 new master
,把其他slave--> new master
疑问: sentinel与master通信,如果某次因为master IO操作频繁,导致超时,
此时,认为master失效,很武断.
解决: sentnel允许多个实例看守1个master, 当N台(N可设置)sentinel都认为master失效,才正式失效.
Sentinel选项配置
port 26379 # 端口
sentinel monitor mymaster 127.0.0.1 6379 2 ,
给主机起的名字(不重即可),
当2个sentinel实例都认为master失效时,正式失效
sentinel down-after-milliseconds mymaster 30000 多少毫秒后连接不到master认为断开
sentinel can-failover mymaster yes #是否允许sentinel修改slave->master. 如为no,则只能监控,无权修改./
sentinel parallel-syncs mymaster 1 , 一次性修改几个slave指向新的new master.
sentinel client-reconfig-script mymaster
/var/redis/reconfig.sh ,# 在重新配置new master,new slave过程,可以触发的脚本
redis 与关系型数据库的适合场景
书签系统
create table book (
bookid int,
title char(20)
)engine myisam charset utf8;
insert into book values
(5 , 'PHP圣经'),
(6 , 'ruby实战'),
(7 , 'mysql运维')
(8, 'ruby服务端编程');
create table tags (
tid int,
bookid int,
content char(20)
)engine myisam charset utf8;
insert into tags values
(10 , 5 , 'PHP'),
(11 , 5 , 'WEB'),
(12 , 6 , 'WEB'),
(13 , 6 , 'ruby'),
(14 , 7 , 'database'),
(15 , 8 , 'ruby'),
(16 , 8 , 'server');
# 既有web标签,又有PHP,同时还标签的书,要用连接查询
select * from tags inner join tags as t on tags.bookid=t.bookid
where tags.content='PHP' and t.content='WEB';
换成key-value存储
用kv 来存储
set book:5:title 'PHP圣经'
set book:6:title 'ruby实战'
set book:7:title 'mysql运难'
set book:8:title ‘ruby server’
sadd tag:PHP 5
sadd tag:WEB 5 6
sadd tag:database 7
sadd tag:ruby 6 8
sadd tag:SERVER 8
查: 既有PHP,又有WEB的书
Sinter tag:PHP tag:WEB #查集合的交集
查: 有PHP或有WEB标签的书
Sunin tag:PHP tag:WEB
查:含有ruby,不含WEB标签的书
Sdiff tag:ruby tag:WEB #求差集
Redis key 设计技巧
1: 把表名转换为key前缀 如, tag:
2: 第2段放置用于区分区key的字段--对应mysql中的主键的列名,如userid
3: 第3段放置主键值,如2,3,4...., a , b ,c
4: 第4段,写要存储的列名
|
用户表 user , 转换为key-value存储 |
|||
|
userid |
username |
passworde |
|
|
9 |
Lisi |
1111111 |
lisi@163.com |
set user:userid:9:username lisi
set user:userid:9:password 111111
set user:userid:9:email lisi@163.com
keys user:userid:9*
2 注意:
在关系型数据中,除主键外,还有可能其他列也步骤查询,
如上表中, username 也是极频繁查询的,往往这种列也是加了索引的.
转换到k-v数据中,则也要相应的生成一条按照该列为主的key-value
Set user:username:lisi:uid 9
这样,我们可以根据username:lisi:uid ,查出userid=9,
再查user:9:password/email ...
完成了根据用户名来查询用户信息
php-redis扩展编译
1: 到pecl.php.net 搜索redis
2: 下载stable版(稳定版)扩展
3: 解压,
4: 执行/php/path/bin/phpize (作用是检测PHP的内核版本,并为扩展生成相应的编译配置)
5: configure --with-php-config=/php/path/bin/php-config
6: make && make install
引入编译出的redis.so插件
1: 编辑php.ini
2: 添加
redis插件的使用
// get instance
$redis = new Redis();
// connect to redis server
$redis->open('localhost',6380);
$redis->set('user:userid:9:username','wangwu');
var_dump($redis->get('user:userid:9:username'));
微博项目的key设计
全局相关的key:
|
表名 |
global |
|
|
列名 |
操作 |
备注 |
|
Global:userid |
incr |
产生全局的userid |
|
Global:postid |
Incr |
产生全局的postid |
用户相关的key(表)
|
表名 |
user |
||
|
Userid |
Username |
Password |
Authsecret |
|
3 |
Test3 |
1111111 |
#U*Q(%_ |
在redis中,变成以下几个key
|
Key前缀 |
user |
||
|
User:Userid:* |
User:userid:*Username |
User:userid:*Password |
User:userid:*:Authsecret |
|
User:userid:3 |
User:userid:3:Test3 |
User:userid:3:1111111 |
User:userid:3:#U*Q(%_ |
微博相关的表设计
|
表名 |
post |
|
|
|
|
Postid |
Userid |
Username |
Time |
Content |
|
4 |
2 |
Lisi |
1370987654f |
测试内容 |
微博在redis中,与表设计对应的key设计
|
Key前缀 |
post |
|
|
|
|
Post:Postid:* |
Post:postid:*Userid |
Post:postid:*:Username |
Post:postid:*:Time |
Post:postid:*:Content |
|
4 |
2 |
Lisi |
1370987654f |
测试内容 |
|
set |
关注表: following
Following:$userid -->
|
set |
粉丝表
Follower:$userid --->
推送表:revicepost
|
Recivepost:$userid |
|
3 |
4 |
7 |
|
|
|
=================拉模型,改进=====================
拉取表
|
Pull:$userid: |
|
3 |
4 |
7 |
|
|
|
问: 上次我拉取了 A->5,67,三条微博, 下次刷新home.php, 从>7的微博开始拉取
解决: 拉取时,设定一个lastpull时间点, 下次拉取时,取>lastpull的微博
问: 有很多关注人,如何取?
解决: 循环自己的关注列表,逐个取他们的新微博
问: 取出来之后放在哪儿?
答: pull:$userid的链接里
问: 如果个人中心,只有前1000条
答: ltrim,只取前1000条
问: 如果我关注 A,B两人, 从2人中,各取3条最新信息
,这3+3条信息, 从时间上,是交错的, 如何按时间排序?
答: 我们发布时, 是发布的hash结构, 不能按时间来排序.
解决: 同步时,取微博后,记录本次取的微博的最大id,
下次同步时,只取比最大id更大的微博
Time taken for tests: 32.690 seconds
Complete requests: 20000
Failed requests: 0
Write errors: 0
Non-2xx responses: 20000
Total transferred: 13520000 bytes
Total POSTed: 5340000
HTML transferred: 9300000 bytes
Requests per second: 611.80 [#/sec] (mean)
Time per request: 81.726 [ms] (mean)
Time per request: 1.635 [ms] (mean, across all concurrent requests)
Transfer rate: 403.88 [Kbytes/sec] received
159.52 kb/s sent
563.41 kb/s total
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.9 0 19
Processing: 14 82 8.4 81 153
Waiting: 4 82 8.4 80 153
Total: 20 82 8.2 81 153
Percentage of the requests served within a certain time (ms)
50% 81
66% 84
75% 86
80% 88
90% 93
95% 96
98% 100
99% 103
100% 153 (longest request)
测试结果:
50个并发, 20000次请求, 虚拟下,未做特殊优化
每次请求redis写操作6次.
30+秒左右完成.
平均每秒发布700条微博, 4000次redis写入.
后台定时任务,回归冷数据入mysql
Redis配置文件
daemonize yes # redis是否以后台进程运行
Requirepass 密码 # 配置redis连接的密码
注:配置密码后,客户端连上服务器,需要先执行授权命令
# auth 密码

