
ByteBuf是Netty整个结构里面最为底层的模块,主要负责把数据从底层I/O读到ByteBuf,然后传递给应用程序,应用程序处理完成之后再把数据封装成ByteBuf写回I/O。所以,ByteBuf是直接与底层打交道的一层抽象。相对于Netty其他模块来说,这部分内容是非常复杂的。
ByteBuf有三个非常重要的指针,分别是readerIndex(记录读指针的开始位置)、writerIndex(记录写指针的开始位置)和capacity(缓冲区的总长度),三者的关系是readerIndex<=writerIndex<=capacity。从0到readerIndex为discardable bytes,表示是无效的;从readerIndex到writerIndex为readable bytes,表示可读数据区;从writerIndex到capacity为writablebytes,表示这段区间空闲,可以往里面写数据。除了这三个指针,ByteBuf里面其实还有一个指针maxCapacity,它相当于ByteBuf扩容的最大阈值。
在Netty中,ByteBuf的大部分功能是在AbstractByteBuf中实现,最重要的几个属性readerIndex、writerIndex、markedReaderIndex、markedWriterIndex、maxCapacity被定义在AbstractByteBuf抽象类中。
AbstractByteBuf有众多子类,大概类别分别如下。
● Pooled:池化内存,就是从预先分配好的内存空间中提取一段连续内存封装成一个ByteBuf,分给应用程序使用。
● Unsafe:是JDK底层的一个负责I/O操作的对象,可以直接获得对象的内存地址,基于内存地址进行读写操作。
● Direct:堆外内存,直接调用JDK的底层API进行物理内存分配,不在JVM的堆内存中,需要手动释放。
Pooled(池化内存)和Unpooled(非池化内存);Unsafe和非Unsafe;Heap(堆内内存)和Direct(堆外内存)
Netty中内存分配有一个顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf类型的内存。ByteBufAllocator的基本实现类是AbstractByteBufAllocator,在newHeapBuffer()方法和newDirectBuffer()方法中,分配内存判断PlatformDependent是否支持Unsafe,如果支持则创建Unsafe类型的Buffer,否则创建非Unsafe类型的Buffer,由Netty自动判断。
1.非池化内存分配
1.1堆内内存分配
通过调用PlatformDependent.hasUnsafe()方法来判断操作系统是否支持Unsafe,如果支持Unsafe则创建UnpooledUnsafeHeapByteBuf类,否则创建UnpooledHeapByteBuf类。
1 public Class Unpooledheapbytebuf extends Abstractreferencecountedbytebuf f 2 3 private final Bytebufallocator alloc;bytel array 4 5 private Bytebuffer tmpniobuf; 6 7 protected Unpooledheapbytebuf( Bytebufallocator alloc, int initialcapacity, int maxcapacity) 8 9 this(alloc, new byte linitialcapacity], 0, 0, maxcapacity); 10 11 protected Unpooledheapbytebuf(Bytebufallocator alloc, byte[] initialarray, int maxcapacity) 12 13 this(alloc, initialarray, 0, initialarray. length, maxcapacity); 14 15 private Unpooled Heapbytebuf( 16 17 Bytebufallocator alloc, byte[] initialarray, int readerindex, int writerindex, int 18 19 maxcapacity) t 20 21 super(maxcapacity); 22 23 this alloc= allocsetarray(initialarray); 24 25 setindex(readerindex, writerindex);
其中调用了一个关键方法就是setArray()方法。这个方法的功能非常简单,就是把默认分配的数组new byte[initialCapacity]赋值给全局变量initialArray数组
Unsafe和不Unsafe根本区别在于I/O的读写,他们的getByte()方法,非Unsafe直接根据index索引从数组中取值,Unsafe则调用PlatformDependent工具类取值。
1.2堆外内存的分配
UnpooledByteBufAllocator的newDirectBuffer()方法实现堆外内存的分配,同样有Unsafe之分,Unsafe调用PlatformDependent.directBufferAddress()方法获取Buffer真实的内存地址,并保存到memoryAddress变量中,并调用了Unsafe的getLong()方法,这是一个native方法。它直接通过Buffer的内存地址加上一个偏移量去取数据。
不管是堆外还是堆上,非Unsafe通过数组的下标取数据,Unsafe直接操作内存地址,相对于非Unsafe来说效率当然要更高。
2.池化内存分配
AbstractByteBufAllocator的子类PooledByteBufAllocator实现分配内存的两个方法:newDirectBuffer()方法和newHeapBuffer()方法。
以newDirectBuffer()方法为例,简单地分析一下。首先,通过threadCache.get()方法获得一个类型为PoolThreadCache的cache对象;然后,通过cache获得directArena对象;最后,调用directArena.allocate()方法分配ByteBuf。详细分析一下,threadCache对象其实是PoolThreadLocalCache类型的变量。从名字来看,PoolThreadLocalCache的initialValue()方法就是用来初始化PoolThreadLocalCache的。首先调用leastUsedArena()方法分别获得类型为PoolArena的heapArena和directArena对象。然后把heapArena和directArena对象作为参数传递到PoolThreadCache的构造器中。那么heapArena和directArena对象是在哪里初始化的呢?经过查找,发现在PooledByteBufAllocator的构造方法中调用newArenaArray()方法给heapArenas和directArenas进行了赋值。
1 public Pooledbytebufallocator(boolean preferdirect, int nheaparena, int ndirectarena, intpagesize, int maxorder 2 3 int tinycachesize, int small Cachesize, int normalcachesize) { 4 if (nheaparena >0) { 5 6 heaparenas =newarenaarray(nheaparena); 7 8 } else { 9 10 heaparenas = null 11 12 heaparenametrics =Collections. emptylist() 13 14 if (ndirectarena > 0){ 15 16 directarenas =newarenaarray(ndirectarena); 17 } 18 }
newAreanArray()其实就是创建了一个固定大小的PoolArena数组,数组大小由传入的参数nHeapArena和nDirectArena决定
nHeapArena和nDirectArena的默认值就是CPU核数×2,也就是把defaultMinNumArena的值赋给nHeapArena和nDirectArena。对于CPU核数×2,EventLoopGroup分配线程时,默认线程数也是CPU核数×2。主要目的就是保证Netty中的每一个任务线程都可以有一个独享的Arena,保证在每个线程分配内存的时候不用加锁,实现了线程的绑定,基于上面的分析,我们知道Arena有heapArena和directArena,这里统称为Arena。假设有四个线程,那么对应会分配四个Arena。在创建ByteBuf的时候,首先通过PoolThreadCache获取Arena对象并赋值给其成员变量,然后每个线程通过PoolThreadCache调用get()方法的时候会获得它底层的Arena,也就是说通过EventLoop1获得Arena1,通过EventLoop2获得Arena2,以此类推...
具体的池化思路就是
PoolThreadCache在Arena上进行内存分配,还可以在它底层维护的ByteBuf缓存列表进行分配。举个例子:我们通过PooledByteBufAllocator创建了一个1024字节的ByteBuf,当用完释放后,可能在其他地方会继续分配1024字节的ByteBuf。这时,其实不需要在Arena上进行内存分配,而是直接通过PoolThreadCache中维护的ByteBuf的缓存列表直接拿过来返回。在PooledByteBufAllocator中维护着三种规格大小的缓存列表,分别是三个值tinyCacheSize、smallCacheSize、normalCacheSize
/**附:这种思想在Tomcat里也有运用,比如Tomcat中的NioChannel属于频繁生成与消除的对象,因为每个客户端连接都需要一个通道与之相对应,频繁地生成和消除在性能的损耗上也不得不多加考虑,我们需要一种手段规避此处可能带来的性能问题。其思想就是:当某个客户端使用完NioChannel对象后,不对其进行回收,而是将它缓存起来,当新客户端访问到来时,只须替换其中的SocketChannel对象即可,NioChannel对象包含的其他属性只须做重置操作即可,如此一来就不必频繁生成与消除NioChannel对象。具体的做法是使用一个队列,比如ConcurrentLinkedQueue<NioChannel>,将关闭的通道对应的NioChannel对象放到队列中,而封装NioChannel对象时优先从队列里面取,取到该对象后,做相应的替换及重置操作,假如队列中获取不到NioChannel对象,再通过实例化创建新的NioChannel对象。这种优化方式很常见,尤其在频繁生成与消除对象的场景下。*/
在PooledByteBufAllocator的构造器中,分别赋值tinyCacheSize,smallCacheSize,normalCacheSize通过这种方式,Netty预创建了固定规格的内存池,大大提高了内存分配的性能。(Tomcat通重新为对象建立引用复用资源,Netty通过释放内存复用内存池而不是新开辟内存复用资源)
Arena分配内存的基本流程有三个步骤。
(1)优先从对象池里获得PooledByteBuf进行复用。
(2)然后在缓存中进行内存分配。
(3)最后考虑从内存堆里进行内存分配。
以directBuffer为例,首先来看从对象池里获得PooledByteBuf进行复用的情况,从PooledByteBufAllocator的newDirectBuffer()方法直接跟进PoolArena的allocate()方法,在该方法中调用newByteBuf()方法获得一个PooledByteBuf对象,然后通过allocate()方法在线程私有的PoolThreadCache中分配一块内存,再对buf里面的内存地址之类的值进行初始化。跟进newByteBuf()方法,选择DirectArena对象。然后通过RECYCLER(回收站对象)从不同规格的缓存列表获取对象。如果缓存列表的规格都不满足,就进行真实的内存分配。
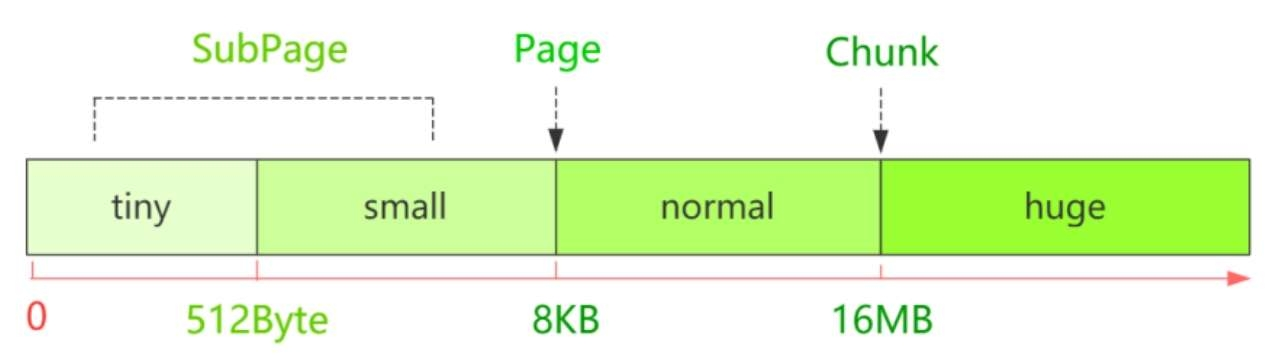
其实在Netty底层还有一个内存单位的封装,为了更高效地管理内存,避免内存浪费,把每一个区间的内存规格又做了细分。默认情况下,Netty将内存规格划分为四个部分。Netty中所有的内存申请是以Chunk为单位向系统申请的,每个Chunk大小为16MB,后续的所有内存分配都是在这个Chunk里的操作。一个Chunk会以Page为单位进行切分,8KB对应的是一个Page,而一个Chunk被划分为2048个Page。小于8KB的是SubPage。例如,我们申请的一段内存空间只有1KB,却给我们分配了一个Page,显然另外7KB就会被浪费,所以就继续把Page进行划分,以节省空间。内存规格大小如下图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号