
每日学习记录20230323_Bert视频学习
20230323:Bert视频学习
B站视频
RNN
这个东西不能并行运算,所以翻译的时候需要用Transformer,这样输出结果是同时被计算出来的.并且Transformer有注意力机制进行并行计算
Transformer
输入如何编码?
输出结果是什么?
Attention的目的?
怎样组合在一起?
Transformer最核心的机制是Self-attention,也就是让计算机关注到有价值的信息.
比如下面两句话:
这里面的it是有不同的指代的,所以这是注意力机制就需要根据上下文来决定it来自哪些词的概率,上图用热图表示.
self-attention如何计算


一共是三个矩阵,实际的含义如上图.
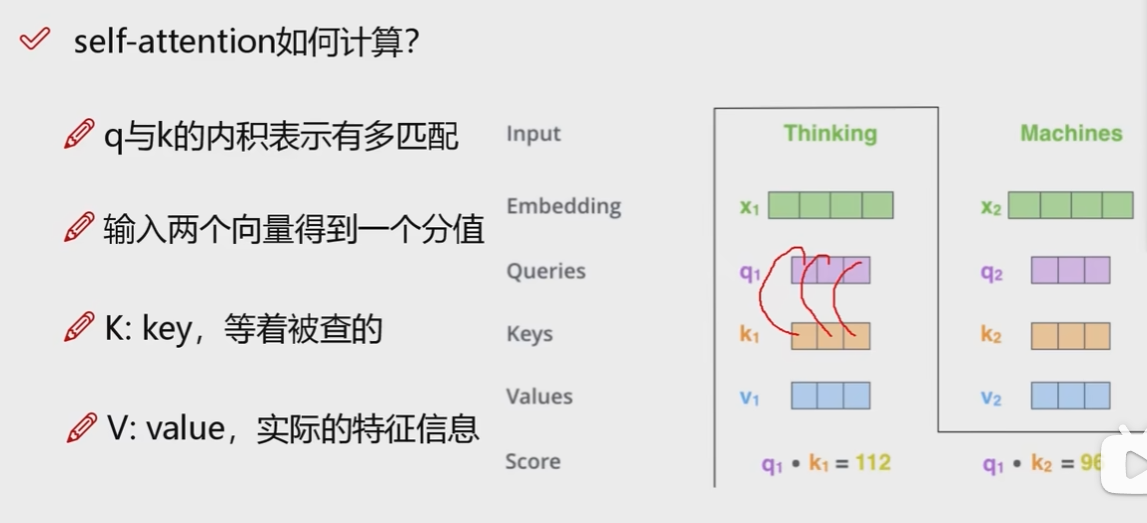
得到每个词的四个矩阵之后,就可以举例一下,比如我想计算第一个词与第一个词和第二个词的关系,就需要计算上图最下面的两个式子的结果,也就是向量之间的内积.内积越大说明向量越相似,越趋于零说明向量越垂直.(内积是上图红线的两个数相乘,再求和).这样就算出来每个词与其他词的相关程度.

上图的下面是softmax的计算过程,假设有三个词的值,然后就要先求\(e^x\),也就是一个转化.再用得到的每一个词的结果除所有结果的和.就变成了百分比.
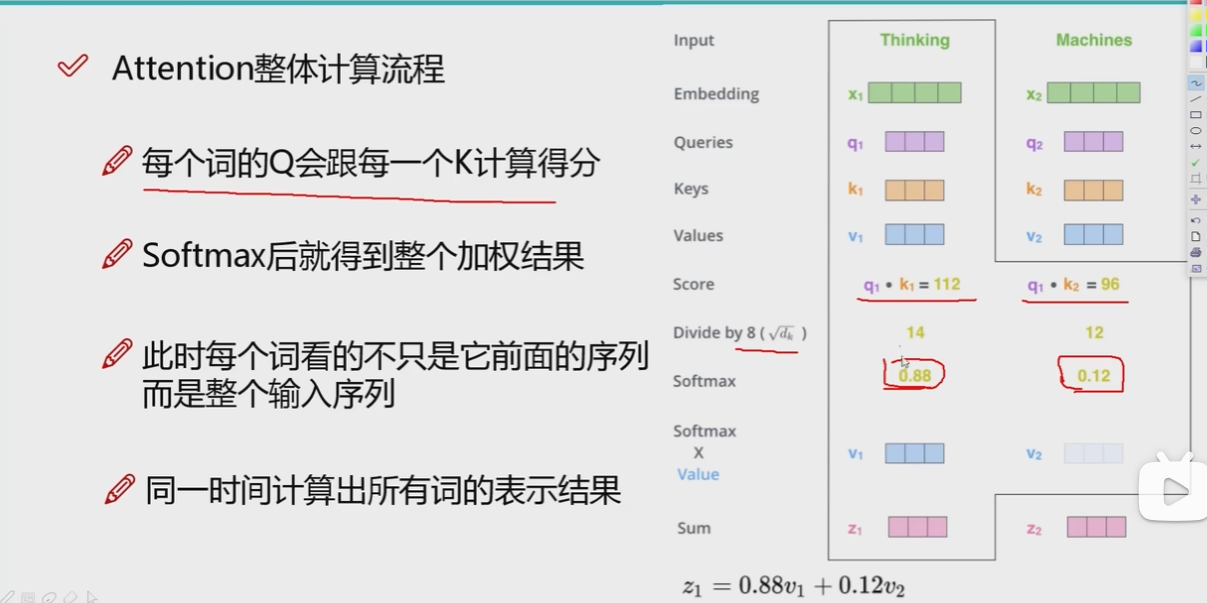
综上所述,上图就是attention计算的过程.
多头机制(multi-headed)
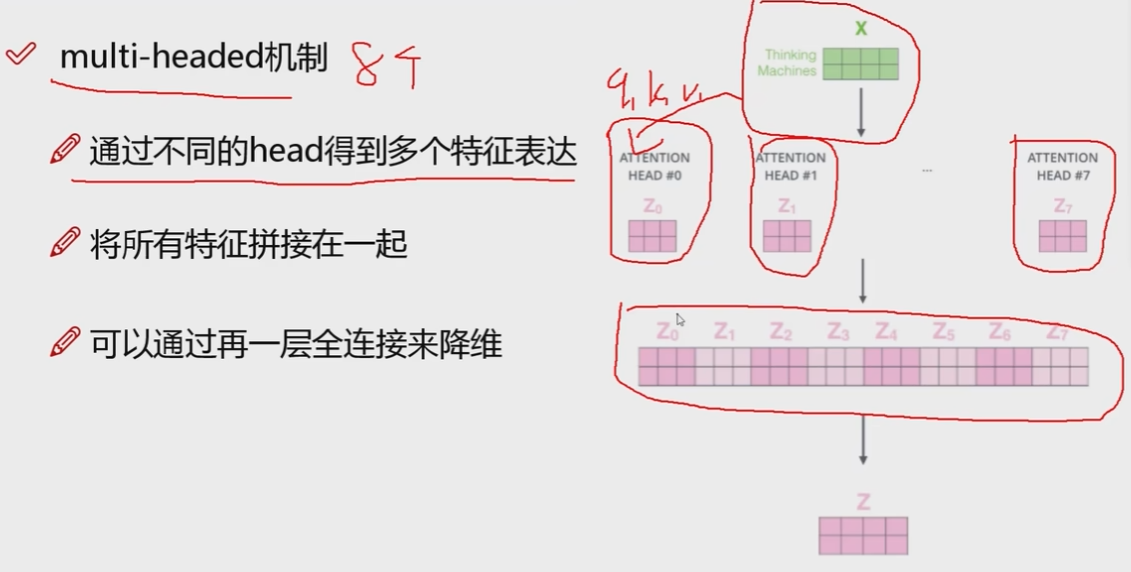
所谓多头机制就是一个x用多组q k v表示, 得到多种特征表达,最后把所有特征拼接在一起,在弄一层全连接 把升高的维度降下来.
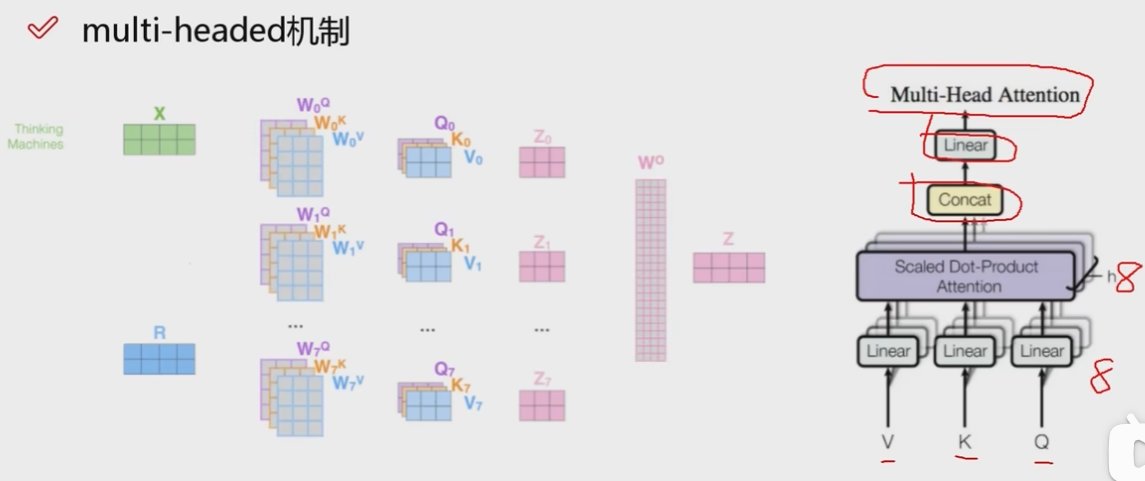
上图就是多头机制的表示:多个q k v矩阵输入到attention机制,导致attention也有8个,然后进行concat(拼接),再进入全连接层(Linear),这就是整个的多头机制.
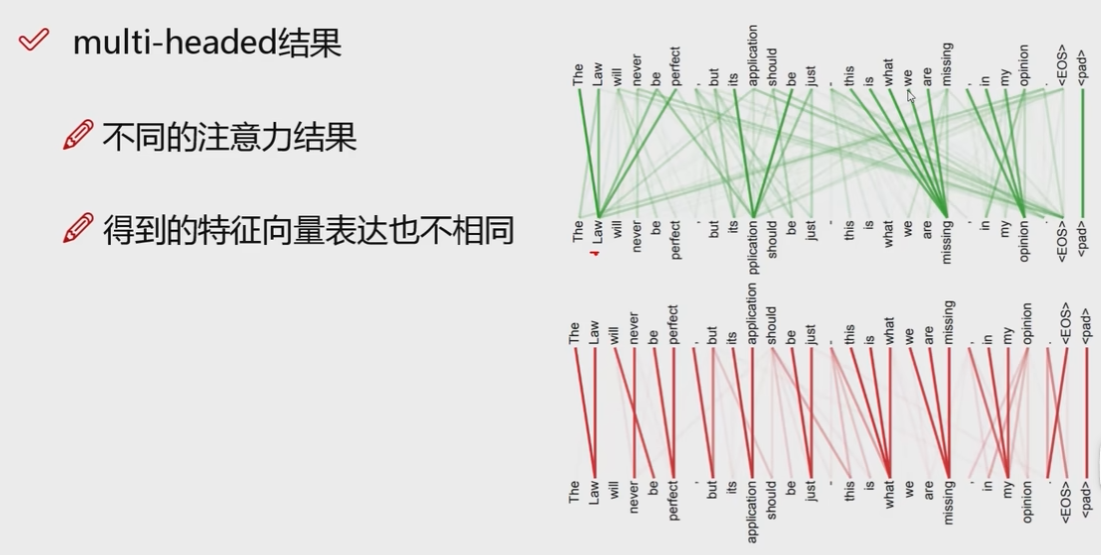
上图就是使用多头机制得到的结果,红线是一个头,绿线是一个头.使用同样的输入,不同的头得到的结果是不一样的.看单个单词,一般跟自己距离近,跟自己附近的词也会相关性很大.
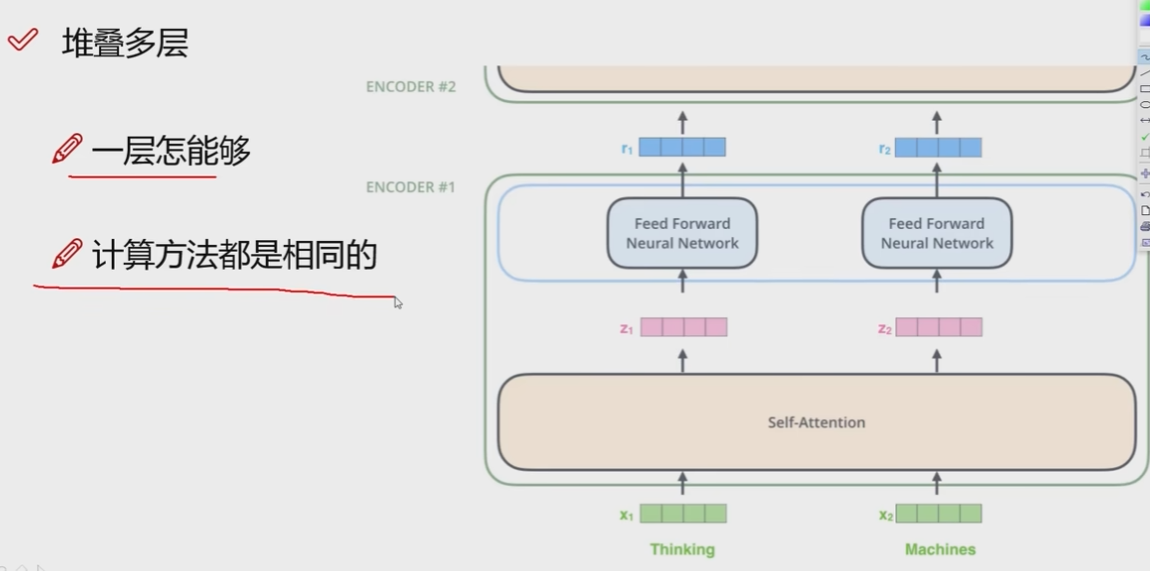
上图是堆叠多层,就是ENCODER重复多次.

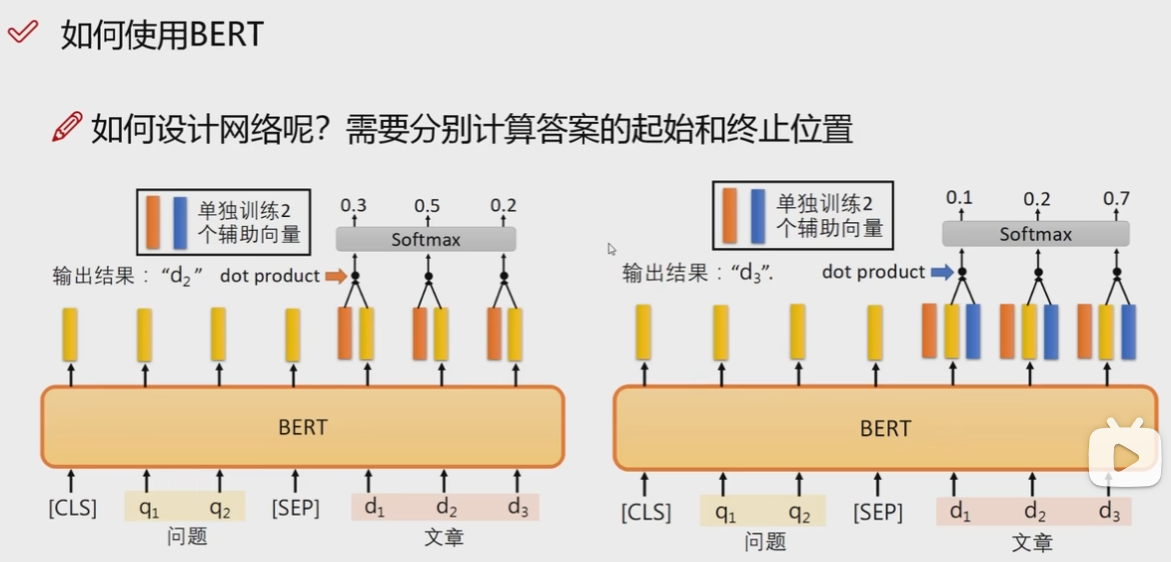
上面两个图片是:使用Bert进行阅读理解的计算的过程,输入文章和问题到Bert,然后需要额外训练两个辅助向量,分别表示答案在文章的起始位置和终止位置.因为在训练的过程中,答案是已知的文本,只是需要转化一下变成向量,这样在实际计算的时候就有评判标准了.有了标准,这样再对起始位置单词和文章中的每一个单词做点积,计算相似度得分,对终止位置也做同样的操作,最后得到起始到终止的所有单词,这就是最终的答案.
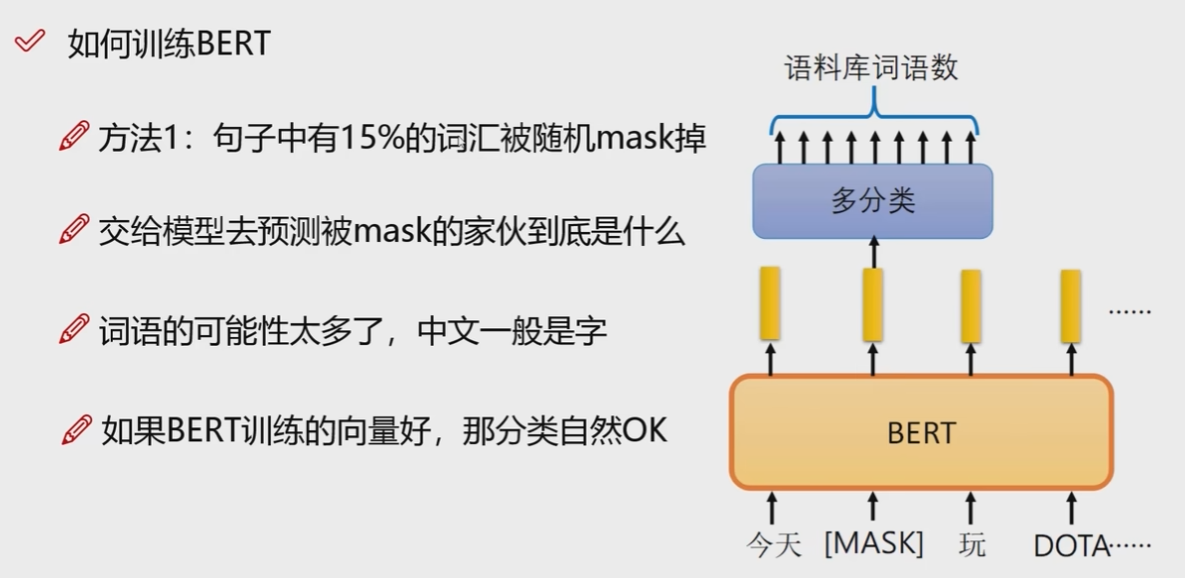
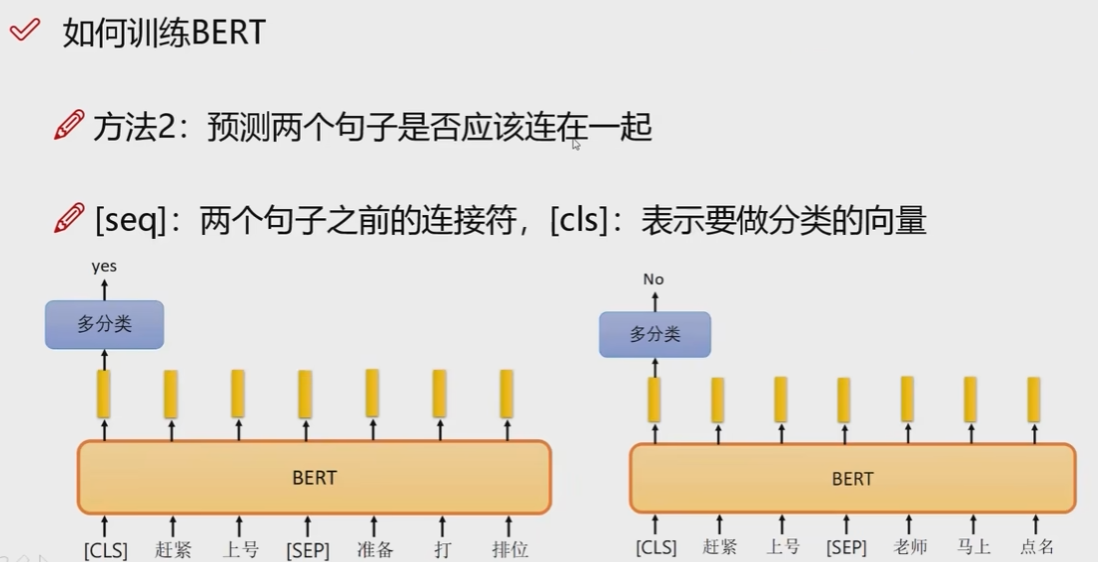
具体的训练过程有两种,第一是随机mask一些词,第二是判断是否两个句子是连在一起的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号