
2022.02.10-学习记录
2022.02.10-学习记录
可以使用线性回归的原理进行差异基因的筛选
广义线性模型筛选差异基因,应该是通过回归系数和p值去筛选,这个明天看看
这篇文章要好好看看
数据建模流程
来自这里
- 划分训练集和测试集,
- 留出法 :caret包的createDataPartition函数,划分数据的80%为训练集,剩下的20%为测试集
- 交叉验证法: creatFolds函数,交叉验证法将原始数据分成K组(一般是均分),每次训练将其中一组作为训练集,另外K-1组作为测试集。
- Boostrap法:creatResample,当数据量比较少时,Boostrap抽样会成为你的救命稻草,它是一种从给定训练集中有放回的均匀抽样。也就是说,每当选中一个样本,它依然会被再次选中并被再次添加到训练集中。createResample函数中times参数用于设定生成几份随机样本,当times为3,意味着生成3份样本,不仅不同sample之间会有交叉,就连同一份sample中也会有重复的样本。
- 分割时间序列:createTimeSlices,可以把连续的时间的序列数据变成一段一段由重叠的连续数据,用于构建训练集和测试集
- 缺失值填补
- 中位数填补:preProcess(.,method='median')
- k近邻法:preProcess(.,method='knnImpute')基于欧氏距离用k近邻法得到k个与此样本相近的样本,使用这个k个数据对缺失值进行填补.K近邻法会自动利用训练集的均值标准差信息对数据进行标准化,所以最后得到的数据是标准化之后的,如果你想看原始值,那么还需要将其去标准化倒推回来。
- 删除近零方差:
利用caret包中的nearZeroVar函数,一行代码就能找出近零方差的变量.所谓近零方差的数据可以举例为:是否喜欢矮矬穷和对方是否喜欢矮矬穷这两个变量的方差为0,也就是所有人都这样,这样的数据可以直接删除了
- 删除共线性变量:
findCorrelation函数会自动找到高度共线性的变量,比如你的性别和相亲人的性别这样的高度相关的变量,并给出建议删除的变量。注意:此函数要求数据中不能有缺失值,所以在此之前需要先处理缺失值;2.只能包含数值型变量;
- 标准化:
preProcess(.,method= c('center','scale')),不同变量的量纲不同,进入线性模型时的权重也不同,所以这个时候需要标准化才可以学习各个变量的真实权重.注意:只能拿训练集的均值和标准差来对测试集进行标准化。
博文哥给的心梗项目的分析
Lasso:这个讲的很详细,可以理解Lasso和OLS的区别和相同点
CAR-T疗法
CAR-T介绍
CAR-T,全称Chimeric Antigen Receptor T-Cell Immunotherapy.它会把
一个癌细胞表面的抗原的抗体中的重链可变区和轻链可变区拿出来,合成成一条链.再把T细胞的CD3的胞内结构域拿出来.把两个合为一条链.
这个合成的蛋白有一个特征,胞外可以进行抗原抗体结合,胞内可以传到T细胞信号.这个抗体跟抗原结合就可以使T细胞发生活化
过程是:构建一个慢病毒,里面包裹着可以转录翻译成一个抗体的DNA,慢病毒感染T细胞后会让T细胞表达这个单链抗体,进而使T细胞可以识别抗原,将肿瘤杀死.
抗体结构
抗体分为两个部分,两个长(大)的 重链 ,以及两个短(小)的 轻链 。.而轻链和重链之间以双硫键连接
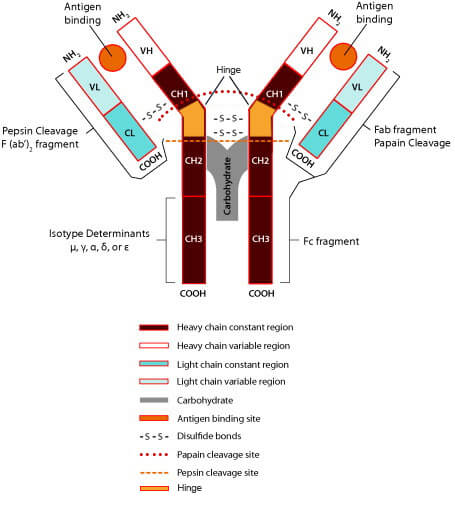
轻链:轻链包括可变区和恒定区,可变区约占轻链的1/2。
重链:重链包括可变区和恒定区。根据重链的不同,可以将抗体分为不同的种类,例如哺乳动物 Ig 的重链有α、δ、ε、γ和 μ 五种,相对应可以将哺乳动物Ig分为 IgA、IgD、IgE、IgG 和 IgM 五类。
抗体可以和具有三级结构的抗原结合
T细胞如果想在抗原的刺激下变成效应T细胞,需要经过激活分化增殖三个阶段,也需要三个信号通路:
1.MHC多肽复合物和TCR结合形成的CD4-T细胞
2.B7家族与CD28形成的第二信号
3.胞外的细胞因子

 浙公网安备 33010602011771号
浙公网安备 33010602011771号