



k-近邻算法(KNN)是一种基本的分类与回归方法。
算法介绍:
给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最邻近的K个实例。如果这K个实例多数属于某个类别,则把该输入实例分为这个类。简单来说,KNN算法的思想就是“近朱者赤,近墨者黑”。
算法描述:

总结:从以上算法描述我们可以看出,K邻近算法的3个关键问题是:距离度量、K值选择和分类决策规则。
Python实例:
说明:本实例来自于《机器学习实战》一书,代码有我标记的大量注释,后面我会附上具体的数据样本。
1、首先我们需要关注的就是KNN算法的具体实现,即classify0()方法:
1 """ 2 使用K-近邻算法改进约会网站的配对效果 3 """ 4 5 from numpy import * 6 import matplotlib.pyplot as plt 7 import operator # 运算符模块 8 import matplotlib as mpl 9 # 解决图表中文乱码的问题 10 mpl.rcParams['font.sans-serif'] = [u'SimHei'] 11 12 13 def classify0(inX, dataSet,labels,k): 14 """ 15 采用KNN算法分类 16 :param inX: 测试样本 17 :param dataSet: 训练样本数据集 18 :param labels: 标签向量 19 :param k: 最近邻居的数目 20 :return: 21 """ 22 23 # 计算测试样本和训练样本间的距离 24 dataSetSize = dataSet.shape[0] # 数据集大小 25 # 可以用tile()函数 或者用numpy的广播规则 26 # diffMat2 = inX - dataSet # numpy的广播规则 27 diffMat = tile(inX,(dataSetSize,1)) - dataSet # tile()函数相当于将inX向量在列方向上重复了dataSetSize次,行方向上重复1次 28 sqDiffMat = diffMat ** 2 # 矩阵的乘方 29 sqDistance = sqDiffMat.sum(axis=1) # 按行相加 30 distance = sqDistance ** 0.5 # 取平方根32 33 # 将计算的距离从小到大排列,找出其中最小的K个 34 sortedDistIndicies = distance.argsort() # argsort()返回的是排序后的索引 35 # 采用的决策规则为“投票规则”,用字典的方式存储 36 classCount = {} 37 for i in range(k): 38 voteIlabel = labels[sortedDistIndicies[i]] 39 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # dict.get(key, default=None) key -- 字典中要查找的键。default -- 如果指定键的值不存在时,返回该默认值 40 41 # 排序距离最小的K个训练样本的分类个数 42 # Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。 43 44 # sorted函数 45 # reverse = True 降序 或者 reverse = False 升序,有默认值。 46 # key=operator.itemgetter(1) 表示用元组的第二个属性比较 47 48 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) 49 50 # sortedClassCount 获得的是经过排序的由元组构成的数组(降序) 51 return sortedClassCount[0][0]
总结:以上KNN算法的三个关键问题就是:距离度量采用了“欧式距离”,不熟悉的童鞋可以上网查查。另外,决策规则采用的是“投票规则”,K值取为3。
2、在搞清楚KNN算法的的具体实现流程以后,我们就可以用数据来测试算法的性能了。我们知道,分类算法的测试评估方法有很多,通常采用的是通过“错误率”来评估分类器的好坏。以下代码就是KNN分类器的测试代码:
2.1 首先是测试数据的处理,这里由于数据是存储在文本文件中,因此首先需要读取文本文档的数据:
1 def file2matrix(filename): 2 """ 3 获取文本文件的数据 4 :param filename: 5 :return: 6 """ 7 fr = open(filename) 8 arrayOLines = fr.readlines() # 读取文件内容 9 numberOfLines = len(arrayOLines) # 获取文件行数 10 returnMat = zeros((numberOfLines,3)) # 创建要返回的矩阵 11 classLabelVector = [] # 类标签向量 12 index = 0 13 14 # 解析文件 15 for line in arrayOLines: 16 # 用strip截取掉所有的回车字符 17 line = line.strip() # strip()方法用于移除字符串头尾指定的字符(默认为空格)。 18 listFromLine = line.split('\t') # 用分割制表符获取数据 19 returnMat[index,:] = listFromLine[0:3] 20 classLabelVector.append(int(listFromLine[-1])) 21 index += 1 22 return returnMat, classLabelVector
在经过以上步骤后,我们可以拿到由文本文件获取而来的样本实例矩阵returnMat以及类标记向量classLabelVector。那么在提出第二个步骤之前,我们先来看一个示例,假设我们要计算测试样本X=(0,20000,1.1)和训练样本Y=(67,32000,0.1)之间的距离,采用欧式距离的计算方法,有以下一对数据的计算公式:
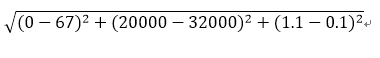
我们可以看到,样本的第二维特征的计算(20000-32000)的值要远远大于其他两个维的属性值的计算值,这在三个属性特征同等重要的前提下,显然是不符合实际的,因为如此巨大的数值差显然会影响其他两维特征对分类器的决策能力。于是为了解决这个问题,我们提出了“归一化数值”的方法。即将所有的数值的取值范围处理到0-1或者-1到1之间。即:
newValue = (oldValue - minValue) / (maxValue - minValue)
其中minValue和maxValue是数据集中的最小、最大特征值。
以下贴出“归一化数值“的代码:
2.2、数值归一化处理:
1 def autoNorm(dataSet): 2 """ 3 数据归一化处理,将数字的特征值转化到0-1区间 4 newValue = (OldValue-min) / (max - min) 5 :return: 6 """ 7 minVals = dataSet.min(0) # 返回每一列的最小值 8 maxVals = dataSet.max(0) # 返回每一列的最大值 9 ranges = maxVals - minVals 10 normDataSet = zeros(shape(dataSet)) 11 m = dataSet.shape[0] 12 normDataSet = dataSet -tile(minVals,(m,1)) # 将minVals在行方向上重复m次,列方向上重复1次 13 normDataSet = normDataSet/tile(ranges,(m,1)) # 具体特征值相除 14 return normDataSet,ranges,minVals
总结:以上数值归一化处理只需要注意一个问题,就是选取的是每一维的最大和最小特征值,而非整个样本矩阵的。另外对于tile函数的用法,如果不明白的话,可以去网上查,或者看我收藏的另外一篇帖子:http://www.cnblogs.com/ma-lijun/articles/7867243.html
3、KNN分类器测试代码:
1 def datingClassTest(): 2 """ 3 分类器测试代码,采用“错误率”来评估分类器的好坏 4 :return: 5 """ 6 hoRatio = 0.10 7 # 获取文本数据,将数据和分类标记分别开来 8 datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') 9 # 采用数据归一化处理,将所有数据化为0-1的数值范围 10 normMat,ranges,minVals = autoNorm(datingDataMat) 11 12 m = normMat.shape[0] # 获取归一化矩阵的行数,这里共有1000行数据 13 numTestVecs = int(m*hoRatio) # 需测试样本的行数 14 errorCount = 0.0 # 错误率 15 # 用前numTestVecs个样本测试分类器的准确率 16 for i in range(numTestVecs): 17 results = classify0(normMat[i,:],normMat[numTestVecs:,:],datingLabels[numTestVecs:],3) 18 print("分类器分为:%d,=========真实分类为:%d"%(results,datingLabels[i])) 19 if(results != datingLabels[i]): 20 errorCount += 1.0 21 print("最重测试分类器的错误率为:%f" %(errorCount/numTestVecs))
总结:这里测试代码选取了数据集的前10%作为测试样本,后90%作为训练样本。实际上,样本数据一共有1000个,所以这里用了前100个样本作为测试样本,后900个样本作为训练样本。通过计算分类“错误率”,来评估算法的好坏。测试结果为5%。
以上即是这篇帖子的全部内容,初次写这么长的帖子,有什么错误或者意见,欢迎指正。下面我贴上这期KNN算法的样本数据以及算法源码。
资源链接:http://pan.baidu.com/s/1eR5h7zW

