
基本关键字
1、msg(对匹配到的规则的说明,第一部分约定用大写字母表示,msg始终是签名的第一个关键字)
注意:msg中必须转义以下字符: ; \ "
msg :“ATTACK-RESPONSES 403 Forbidden” ; msg :“ET EXPLOIT SMB-DS DCERPC PnP绑定尝试” ;
2、Sid(对此规则的一个编号,以数字表示)
sid:123;
3、rev(Rev代表签名的版本,规则每改变一次,rev加一次1,与msg向对,rev总是签名的最后一个关键字)
rev :123 ;
4、gid(gid表示这条规则所属的组,如果不指定默认为1,通常情况下它会被改变,改变它没有技术含义。您只能在警报中注意到它)
[1:2010935:2] 其中1位置表示sid,2010935位置表示sid,2位置表示rev
5、Classtype(提供有关规则和警报分类的信息)
这个定义一般是在classification.conf文件中指定,定义格式依次是短类型名,简短描述,匹配优先级

在匹配规则中定义的是短类型名,而在匹配到的日志文件中显示的这是分类的简短描述
匹配规则中 classtype:misc-attack
匹配日志文件中 [Classification: Misc Attack] [Priority: 2]
6、Reference(字段表明这条规则相关信息所在url,规则的出处)
请注意,不能在url之前使用http
reference: url, www.info.nl
另外一种不同的表示方法(其中的2013-2135为参数,引用的url就是http://cve.mitre.org/cgi-bin/cvename.cgi?name=2015-0235)
reference:cve,2013-2135
定义引用的地方则是在reference.config配置文件中

7、Priority(priority字段表示此条规则或class的匹配优先级,即使在classification.config文件中指定了每个class的priority,还是可以在规则中重新制定priority字段进行覆盖)
priority:1;
该字段的值范围从1-255,在suricata中数字越小表示优先级越高,也就是说如果两条规则都能匹配,则优先匹配priority字段小的规则。
8、metadata(主要原因是当suricata遇到metadata字段便会忽略这个字段的值,还能在规则中使用是为了兼容之前的snort规则)
metadata:......;
有效字段匹配关键字(Payload)
1、content(content关键字在suricata规则中非常重要,大部分规则都要使用这个关键字来匹配数据包中的内容,可以在签名中使用多个内容)
content: ”............”;
content中的内容是按字节匹配的,能匹配ASCII码从0-255的字节,可打印字符比如a-z可以直接写,而某些特殊符号或是不可打印的字符则需要使用十六进制来表示
|0a|和|0A| 表示空格,十六进制表示时不区分大小写 |61| 表示字母a |21| 表示! b 表示字母b B 表示字母B(直接写a-z的字符则区分大小写) |61|b 表示字母ab,十六进制描述可以和字符混着写
有些字符不能在内容中使用,因为它们在签名中已经很重要。为了匹配这些字符,你应该使用十六进制符号(用大写字符编写十进制符号是一种惯例)
“| 22 | ; | 3B | :| 3A | | | 7C |
2、Nocase(nocase关键字是用来修饰content字段的,在content字段后加上nocase表示content中的内容不区分大小写)

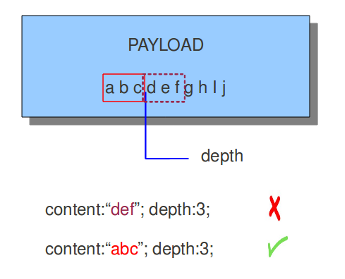
3、Depth(depth也是修饰content的关键字,表示从payload开始多少个字节与content中的内容进行匹配,格式如下表示的是匹配’abc’)
4、Offset(与depth不同的是offset是从payload开头先偏移指定字节再对content进行匹配,下图表示的是从开头偏移3字节,从第四字节开始匹配字符串”def”)

5、distance(distance表示从上一个content匹配的末尾偏移指定数量字符再进行本次的content匹配。如下所示,第一次匹配”abc”之后的位置在字符’d’处,distance为0表示不偏移,直接从’d’开始匹配’def’)

6、within(within也是一个修饰content的关键字,他表示从上一个content匹配位置之后的指定字节内对当前的content进行匹配,within的值不能为0。下面这个例子比较清楚的描述了within的用法,匹配完”abc”之后位置在’d’处,从’d’开始的3字节内对”def”进行匹配,而”fgh”明显已经超出了3字节的偏移)

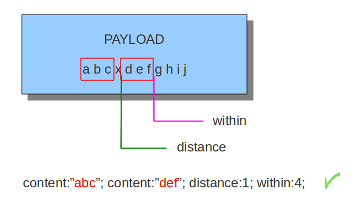
同样,within也可以和distance一起使用,如下所示匹配完”abc”,distance:1向后移动1字节从’d’开始的4个字节以内匹配’def’:
7、isdataat(isdataat关键字是用来判断指定偏移处的字符是否是数据。下面是两个例子,第一个表示从payload开头偏移512个字节的地方是否为数据,第二个则表示从上一次匹配完成之后偏移50字节的地方是否为数据)
isdataat:512; isdataat:50, relative;
8、dsize(dsize是用来检测数据包中的payload长度是否在符合要求的范围内,这样可以有效的组织一些缓冲区溢出的攻击。格式如下)
dsize:min<>max; dsize:[<|>]<number>;
来看两个例子,第一个表示payload的长度在200-400字节之间,第二个表示不能超过300字节
dsize:200<>400; dsize:<300;
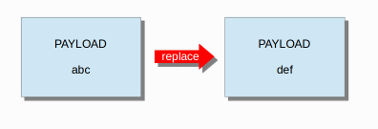
9、replace(replace关键字是用来替换匹配到的content中的字符,下面这个表示将匹配到的”abc”替换成”def”)
10、pcre(pcre关键字使用PCRE来匹配payload中的内容,用法一般是首先使用content匹配到指定字符串,然后根据pcre对相应的payload进行正则匹配)
pcre:”/[0-9]{6}/”;
11、fast_pattern(suricata对只有一个content关键字的规则使用多模匹配,而对于多个content的规则就对最长对复杂的一个进行多模匹配,而fast_pattern则可以改变这个状况,如果在较短较简单的content字段后加上fast_pattern关键字则会优先匹配这个content,有时这种方法可以有效提升效率。下面这个例子就是这种情况,如果第二个content没有fast_parttern关键字的话便会先去匹配”User-Agent:”,而这个在数据包中的出现频率是远远高于”Badness”的,这样就会导致大量的多余时间浪费到无用的匹配上,使用了fast_pattern之后便大大提高了匹配的效率)
content:”User-Agent|3A|”; content:”Badness”; distance:0; fast_pattern;
不仅如此,fast_parttern还支持部分content多模匹配,比如下面这个例子,表示从content的第8字节开始之后的4字节进行多摸匹配以提高效率:
content: “aaaaaaaaabc”; fast_pattern:8,4;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号