为什么单线程Redis能那么快?
“一直很好奇redis是如何这么快的,怎么还能把它的数据存储在内存之中,难道不怕掉吗?以及内存这么宝贵的东西,redis是怎么利用它的。这些东西都促使着自己去了解redis的底层实现原理。所以在阅读了大量文章后。大概总结了redis的一些底层实现原理。”
1. redis快,一方面,这是因为它是内存数据库,所有操作都在内存上完成,内存的访问速度本身就很快。另一方面,这要归功于它的高效的数据结构。
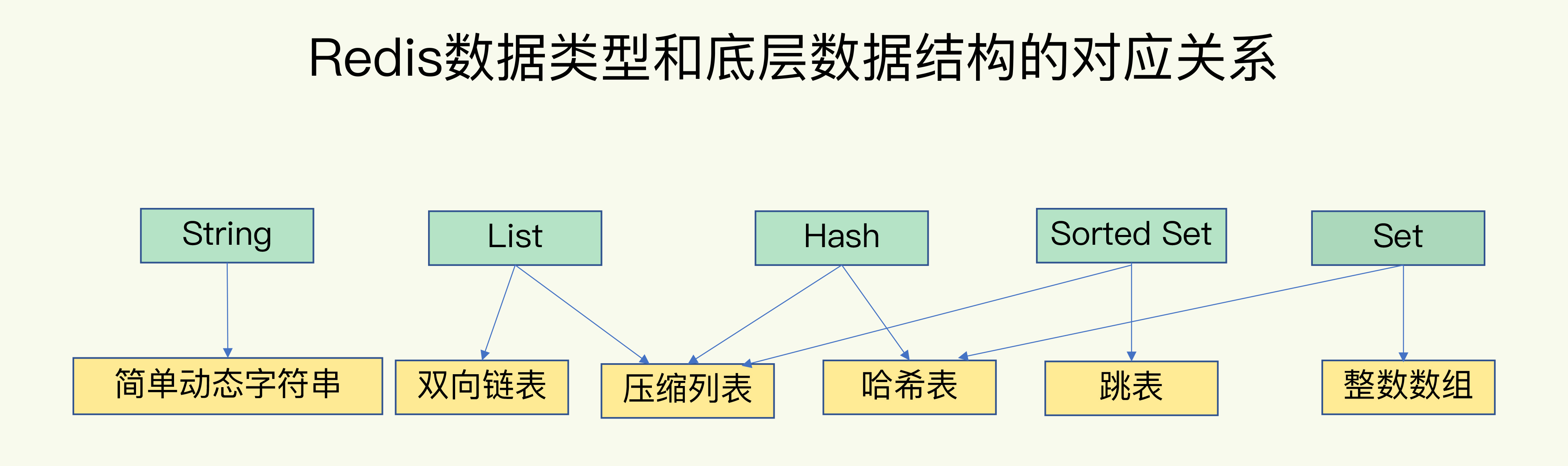
整个redis都由一个全局哈希表来实现查找。对于string类型,它存储的是单个元素,所以只要查询一次就能找到,也就是哈希表的时间复杂度O(1)
而对于另外四种集合类型,底层是由五种数据结构实现。整数数组、双向链表、哈希表、压缩列表和跳表。
其中set和hash底层数据结构都用了哈希表,所以查询速度还是挺快的。
而sorted set是使用了跳表,跳表是在普通链表的基础上使用了多级索引,所以速度也挺快,但对于范围查询往往时间复杂度为O(n)
对于复杂度较高的 List 类型,它的两种底层实现结构:双向链表和压缩列表的操作复杂度都是 O(N)。因因地制宜地使用 List 类型。例如,既然它的 POP/PUSH 效率很高,那么就将它主要用于 FIFO 队列场景,而不是作为一个可以随机读写的集合。
2.Redis 使用了单线程,并且使用了多路复用技术的eppll来监听客户端的连接请求。
redis的单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的。多线程编程模式面临共享资源的并发访问控制问题。需要精细控制并发问题,如果控制不好,会降低系统吞吐率。使用单线程没有堵塞的原因是因为使用了多路复用技术。
3.Redis的两大持久化技术,一是AOF日志,二是RDB快照。
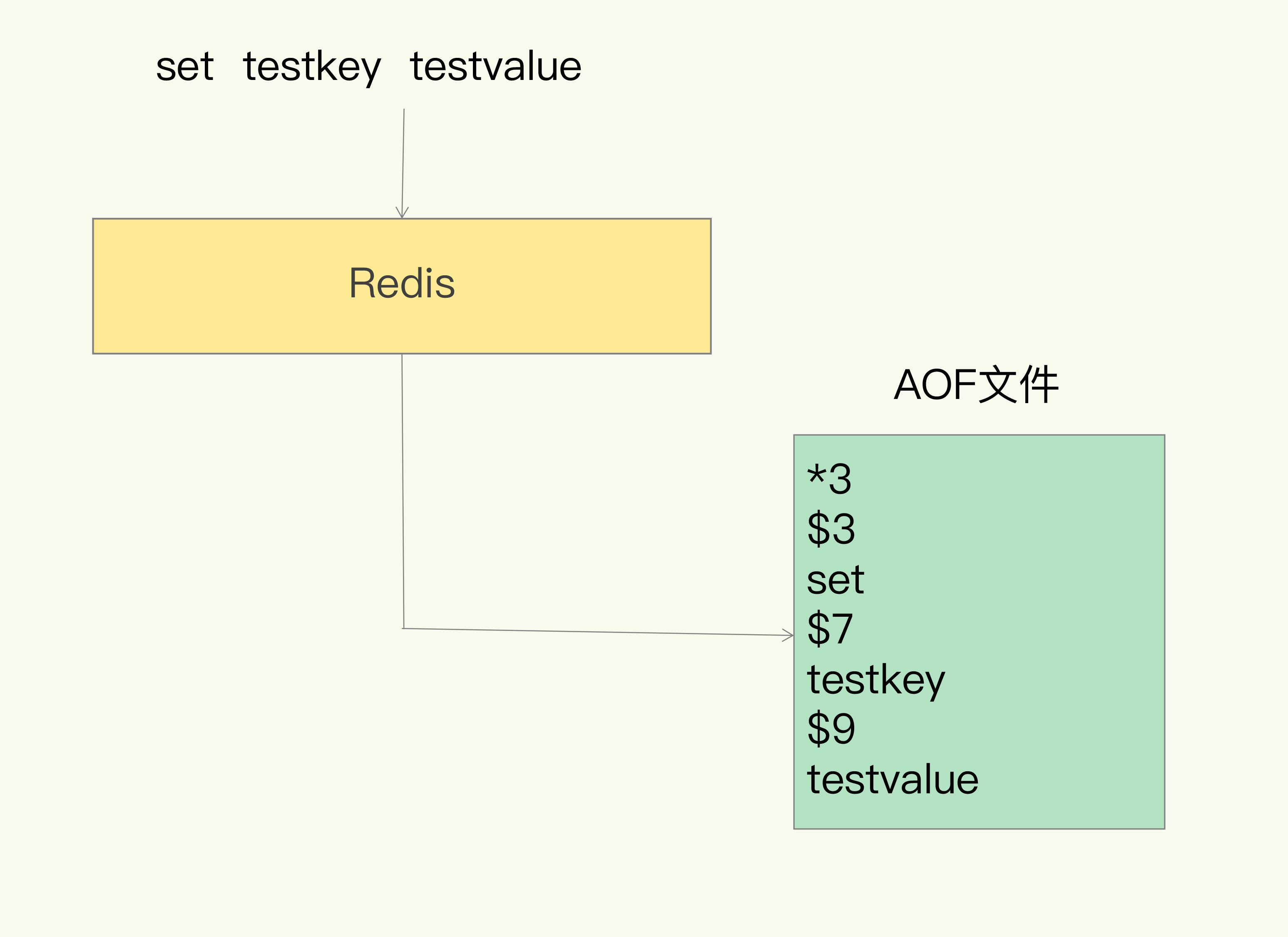
AOF的过程是先执行Redis命令,然后再进行写日志。它的日志记录的是每一条命令,而不是数据,这些命令以文本的形式进行保存。执行写后记录是为了,保证所有记录的日志都是正确的命令,还有一点是先写这样不会阻塞当前的写操作。
三种写回策略
其实,对于这个问题,AOF 机制给我们提供了三个选择,也就是 AOF 配置项 appendfsync 的三个可选值。
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
AOF以追加的方式逐一对新增的写命令进行记录,这样AOF日志文件会越来越大。如果宕机后,需要对日志文件进行执行操作恢复数据,如果日志文件太大,这样的话会很费时。所以引入了AOF重写机制。
AOF重写机制的原理,就是针对那些对同一个数据操作多次的记录,变为只记录最后一次数据命令操作的记录,这样的记录一直保持数据最新状态就行了。这个重写是子线程完成的。
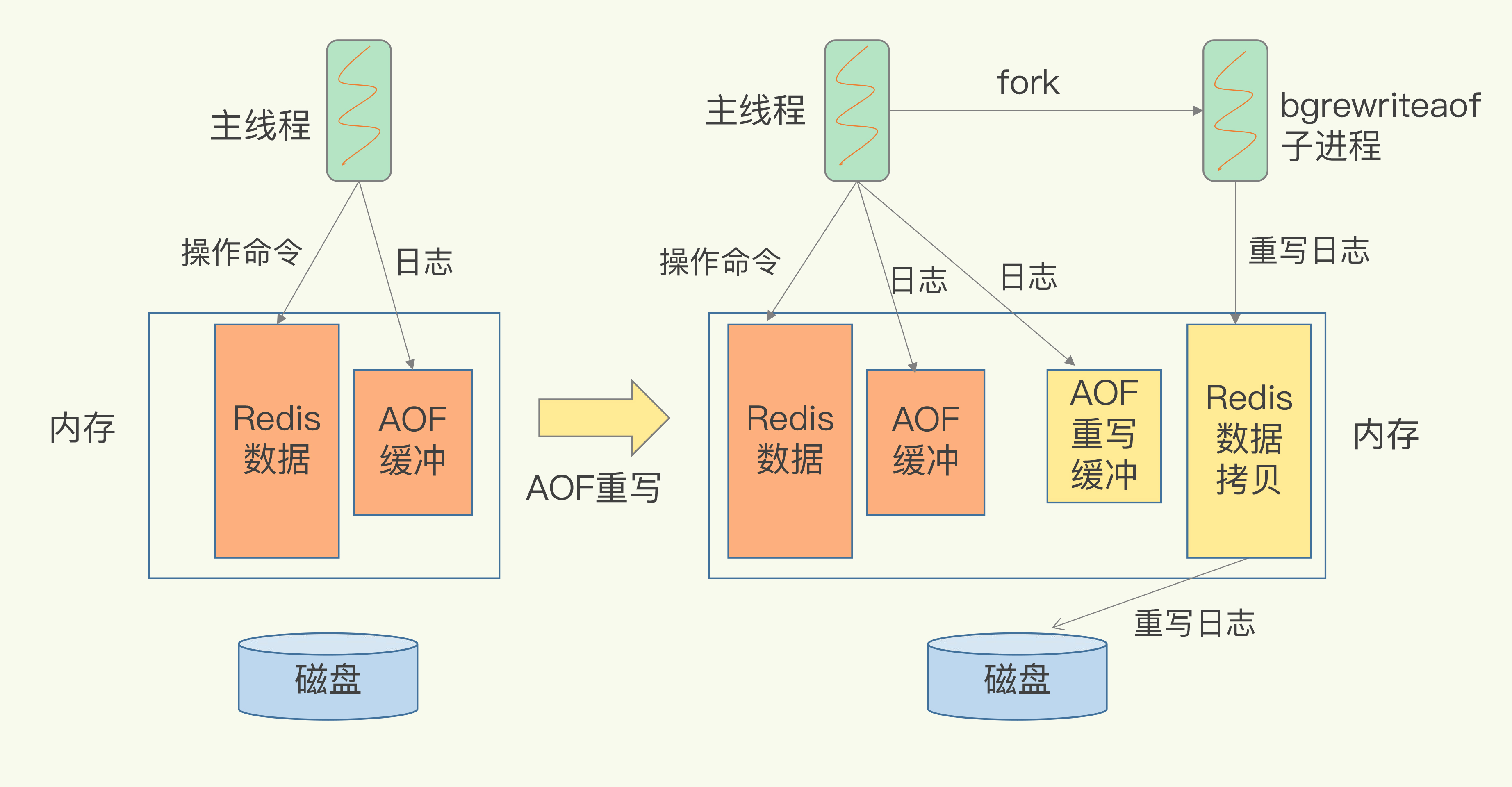
所以会出现两个日志,一个主线程里的AOF日志,一个子线程里的AOF重写日志。最终是把AOF重写日志里文件写入磁盘。
4.RDB快照实现持久化是一种比AOF恢复数据更快的方法。
RDB通过执行bgsave来创建一个子线程来执行全量快照
RDB通过写时复制技术来解决执行快照时,有写命令的情况,就如同我们拍照时,不希望有人动,希望大家都保持不要动准备拍照。如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么子线程把这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
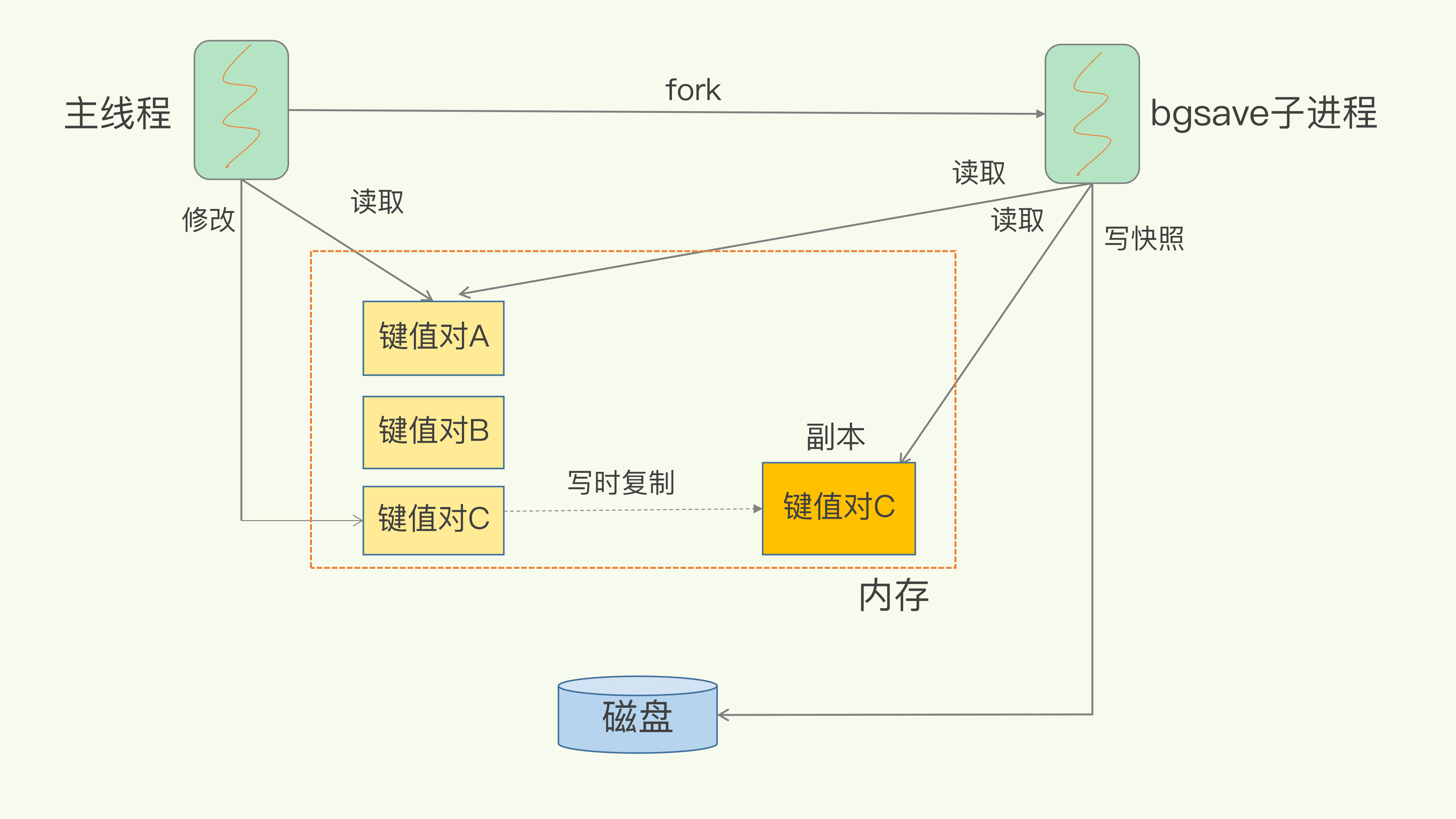
执行RDB快照有一个频率问题,是每秒执行还是每分钟执行,执行多快频率好。如果频率高则频繁 fork 出 bgsave 子进程,这就会频繁阻塞主线程了,太慢又不能很好应对宕机情况。
此时我们可以使用增量快照,所谓增量快照,就是指,做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。但是频率高也同样会会增加很多额外内存开销。
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号