以下操作基于该网站进行演示:https://www.yahoo.com/
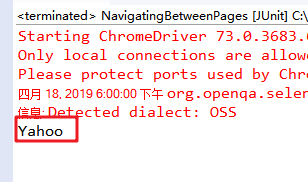
一、driver.getTitle()---获取当前页面的title

1 package basicweb; 2 3 import static org.junit.jupiter.api.Assertions.fail; 4 5 import java.util.concurrent.TimeUnit; 6 7 import org.junit.jupiter.api.AfterAll; 8 import org.junit.jupiter.api.AfterEach; 9 import org.junit.jupiter.api.BeforeAll; 10 import org.junit.jupiter.api.BeforeEach; 11 import org.junit.jupiter.api.Test; 12 import org.openqa.selenium.WebDriver; 13 import org.openqa.selenium.chrome.ChromeDriver; 14 15 class NavigatingBetweenPages { 16 // 声明了一个webdriver类型的变量名,对象名为“driver” 17 WebDriver driver; 18 // 定义一个String类型的字符串,用于存放我们需要打开的url 19 String baseUrl; 20 21 @BeforeEach 22 void setUpBeforeClass() throws Exception { 23 // 将这个变量名对象的引用指向ChromeDriver,表示我们需要用谷歌浏览器来进行自动化操作 24 driver = new ChromeDriver(); 25 // 指定我们需要打开的网站 26 baseUrl = "https://www.yahoo.com/"; 27 // 隐式等待 28 // .implicitlyWait(时长, 时间单位);下面设置时间为“10秒” 29 // TimeUnit.SECONDS表示秒 30 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); 31 // 浏览器窗口最大化 32 driver.manage().window().maximize(); 33 } 34 35 @Test 36 void test() { 37 driver.get(baseUrl); 38 // 获取当前页面的title,用String类型的变量来接收 39 String title = driver.getTitle(); 40 // 打印title 41 System.out.println(title); 42 } 43 44 @AfterEach 45 void tearDownAfterClass() throws Exception { 46 driver.quit(); 47 } }
运行打印结果:
二、driver.getCurrentUrl()--获取当前页面的url
package basicweb; import java.util.concurrent.TimeUnit; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.chrome.ChromeOptions; class NavigatingBetweenPages { // 声明了一个webdriver类型的变量名,对象名为“driver” WebDriver driver; // 定义一个String类型的字符串,用于存放我们需要打开的url String baseUrl; @BeforeEach void setUpBeforeClass() throws Exception { // 将这个变量名对象的引用指向ChromeDriver,表示我们需要用谷歌浏览器来进行自动化操作 // ChromeOptions options = new ChromeOptions(); // options.addArguments("--start-maximized", "allow-running-insecure-content", "--test-type"); driver = new ChromeDriver(); // 指定我们需要打开的网站 baseUrl = "https://www.baidu.com/"; // 隐式等待 // .implicitlyWait(时长, 时间单位);下面设置时间为“10秒” // TimeUnit.SECONDS表示秒 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); // 浏览器窗口最大化 driver.manage().window().maximize(); // 打开网址 driver.get(baseUrl); } @Test void test() { // 获取当前页面的url String url = driver.getCurrentUrl(); // 打印url System.out.println("当前页面的url为:"+url); } @AfterEach void tearDownAfterClass() throws Exception { // 关闭浏览器 driver.quit(); } }
运行结果为:

三、driver.navigate().to(urlToNavigate)--在未点击登录按钮的情况下进入指定页面
driver.navigate().back():返回上一页
driver.navigate().forward():跳转到下一页
1 package basicweb; 2 3 import java.util.concurrent.TimeUnit; 4 5 import org.junit.jupiter.api.AfterEach; 6 import org.junit.jupiter.api.BeforeEach; 7 import org.junit.jupiter.api.Test; 8 import org.openqa.selenium.WebDriver; 9 import org.openqa.selenium.chrome.ChromeDriver; 10 import org.openqa.selenium.chrome.ChromeOptions; 11 12 class NavigatingBetweenPages { 13 // 声明了一个webdriver类型的变量名,对象名为“driver” 14 WebDriver driver; 15 // 定义一个String类型的字符串,用于存放我们需要打开的url 16 String baseUrl; 17 18 @BeforeEach 19 void setUpBeforeClass() throws Exception { 20 // 将这个变量名对象的引用指向ChromeDriver,表示我们需要用谷歌浏览器来进行自动化操作 21 // ChromeOptions options = new ChromeOptions(); 22 // options.addArguments("--start-maximized", "allow-running-insecure-content", "--test-type"); 23 driver = new ChromeDriver(); 24 // 指定我们需要打开的网站 25 baseUrl = "https://www.yahoo.com/"; 26 // 隐式等待 27 // .implicitlyWait(时长, 时间单位);下面设置时间为“10秒” 28 // TimeUnit.SECONDS表示秒 29 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); 30 // 浏览器窗口最大化 31 driver.manage().window().maximize(); 32 // 打开网址 33 driver.get(baseUrl); 34 } 35 36 @Test 37 void test() throws InterruptedException { 38 // 获取当前页面的title,用String类型的变量来接收 39 String title = driver.getTitle(); 40 // 打印title 41 System.out.println("页面标题为:"+title); 42 43 // 获取当前页面的url 44 String url = driver.getCurrentUrl(); 45 // 打印url 46 System.out.println("第一次进入页面时的url:"+url); 47 48 // 新建一个String的变量用于存储“登录”页面的url 49 String urlToNavigate = "https://login.yahoo.com/config/login?.src=fpctx&.intl=us&.lang=en-US&.done=https%3A%2F%2Fwww.yahoo.com"; 50 // 跳转到登录页面 51 driver.navigate().to(urlToNavigate); 52 url = driver.getCurrentUrl(); 53 System.out.println("第一次跳转后的url:"+url); 54 55 // 强制等待2秒(需要抛出异常) 56 Thread.sleep(2000); 57 // 返回上一次打开的url 58 driver.navigate().back(); 59 url = driver.getCurrentUrl(); 60 System.out.println("返回到跳转前页面的url(返回上一页):"+url); 61 62 // 强制等待2秒(需要抛出异常) 63 Thread.sleep(2000); 64 // 跳转到下一页 65 driver.navigate().forward(); 66 url = driver.getCurrentUrl(); 67 System.out.println("返回到跳转前页面的url(跳转到下一页):"+url); 68 69 } 70 71 @AfterEach 72 void tearDownAfterClass() throws Exception { 73 // 退出浏览器 74 driver.quit(); 75 } 76 }
运行结果为:

四、刷新页面
方法一:driver.navigate().refresh();
方法二:driver.get(url);将通过driver.getCurrentUrl();方法获取到的url重新通过“.get”方法打开,也相当于重新加载刷新页面
package basicweb; import java.util.concurrent.TimeUnit; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.chrome.ChromeOptions; class NavigatingBetweenPages { // 声明了一个webdriver类型的变量名,对象名为“driver” WebDriver driver; // 定义一个String类型的字符串,用于存放我们需要打开的url String baseUrl; @BeforeEach void setUpBeforeClass() throws Exception { // 将这个变量名对象的引用指向ChromeDriver,表示我们需要用谷歌浏览器来进行自动化操作 // ChromeOptions options = new ChromeOptions(); // options.addArguments("--start-maximized", "allow-running-insecure-content", "--test-type"); driver = new ChromeDriver(); // 指定我们需要打开的网站 baseUrl = "https://www.yahoo.com/"; // 隐式等待 // .implicitlyWait(时长, 时间单位);下面设置时间为“10秒” // TimeUnit.SECONDS表示秒 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); // 浏览器窗口最大化 driver.manage().window().maximize(); // 打开网址 driver.get(baseUrl); } @Test void test() throws InterruptedException { // 获取当前页面的title,用String类型的变量来接收 String title = driver.getTitle(); // 打印title System.out.println("页面标题为:"+title); // 获取当前页面的url String url = driver.getCurrentUrl(); // 打印url System.out.println("第一次进入页面时的url:"+url); // 新建一个String的变量用于存储“登录”页面的url String urlToNavigate = "https://login.yahoo.com/config/login?.src=fpctx&.intl=us&.lang=en-US&.done=https%3A%2F%2Fwww.yahoo.com"; // 跳转到登录页面 driver.navigate().to(urlToNavigate); url = driver.getCurrentUrl(); System.out.println("第一次跳转后的url:"+url); // 强制等待2秒(需要抛出异常) Thread.sleep(2000); // 返回上一次打开的url driver.navigate().back(); url = driver.getCurrentUrl(); System.out.println("返回到跳转前页面的url(返回上一页):"+url); // 强制等待2秒(需要抛出异常) Thread.sleep(2000); // 跳转到下一页 driver.navigate().forward(); url = driver.getCurrentUrl(); System.out.println("返回到跳转前页面的url(跳转到下一页):"+url); Thread.sleep(2000); // 刷新页面:方法一 driver.navigate().refresh(); // 刷新页面:方法二 // driver.get(url); } @AfterEach void tearDownAfterClass() throws Exception { // 退出浏览器 driver.quit(); } }
五、driver.getPageSource()--获取当前页面的“页面源代码
1 package basicweb; 2 3 import java.util.concurrent.TimeUnit; 4 5 import org.junit.jupiter.api.AfterEach; 6 import org.junit.jupiter.api.BeforeEach; 7 import org.junit.jupiter.api.Test; 8 import org.openqa.selenium.WebDriver; 9 import org.openqa.selenium.chrome.ChromeDriver; 10 import org.openqa.selenium.chrome.ChromeOptions; 11 12 class NavigatingBetweenPages { 13 // 声明了一个webdriver类型的变量名,对象名为“driver” 14 WebDriver driver; 15 // 定义一个String类型的字符串,用于存放我们需要打开的url 16 String baseUrl; 17 18 @BeforeEach 19 void setUpBeforeClass() throws Exception { 20 // 将这个变量名对象的引用指向ChromeDriver,表示我们需要用谷歌浏览器来进行自动化操作 21 // ChromeOptions options = new ChromeOptions(); 22 // options.addArguments("--start-maximized", "allow-running-insecure-content", "--test-type"); 23 driver = new ChromeDriver(); 24 // 指定我们需要打开的网站 25 baseUrl = "https://www.yahoo.com/"; 26 // 隐式等待 27 // .implicitlyWait(时长, 时间单位);下面设置时间为“10秒” 28 // TimeUnit.SECONDS表示秒 29 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); 30 // 浏览器窗口最大化 31 driver.manage().window().maximize(); 32 // 打开网址 33 driver.get(baseUrl); 34 } 35 36 @Test 37 void test() throws InterruptedException { 38 // 获取当前页面源代码 39 String pageSource = driver.getPageSource(); 40 System.out.println(pageSource); 41 42 } 43 44 @AfterEach 45 void tearDownAfterClass() throws Exception { 46 // 退出浏览器 47 driver.quit(); 48 } 49 }
运行结果:
我们也可以在浏览器中直接获取当前浏览页面源代码:点击鼠标右击---》查看网页源代码