
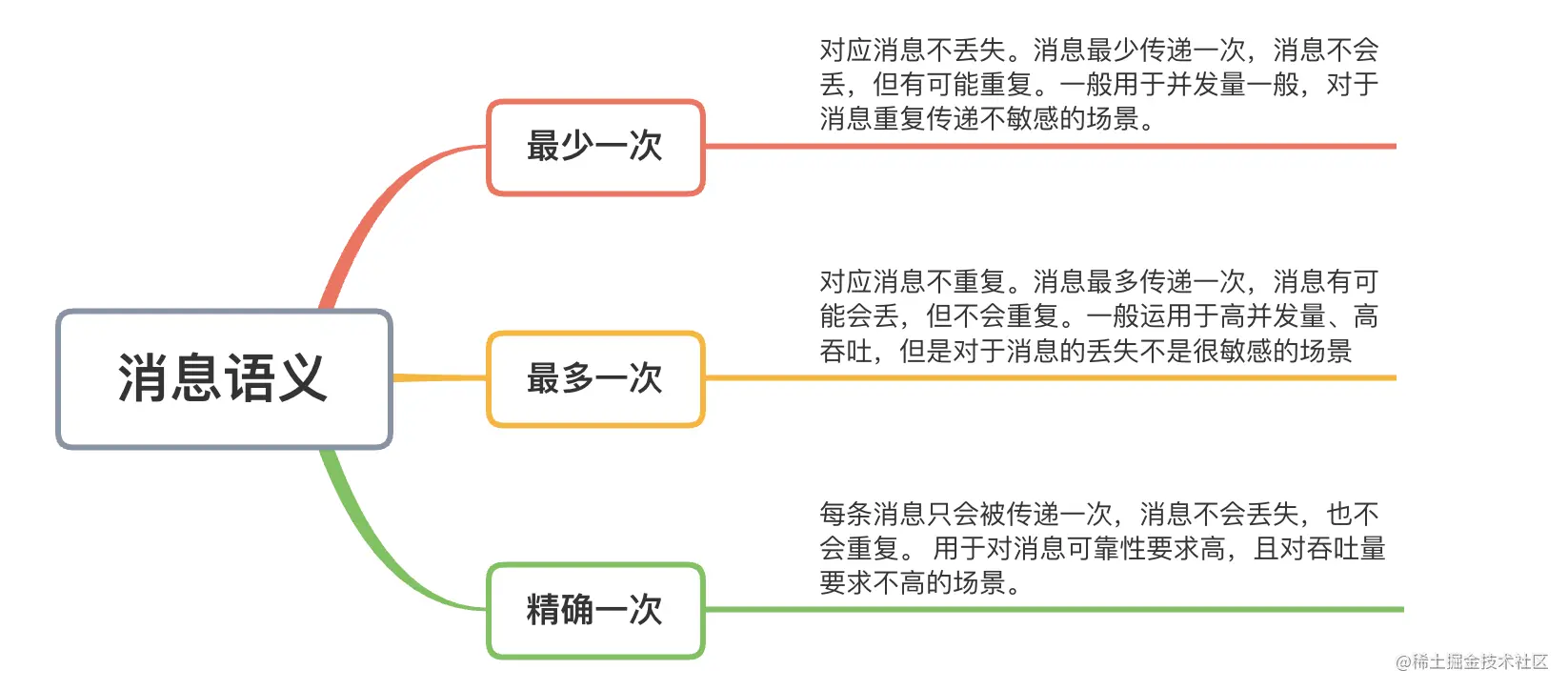
三种消息语义及场景
kafka如何做到消息不丢失?
具体需要Producer端,Broker端,Consumer都做一些工作才能保证消息一定被消费,即,
- 生产者不少生产消息;
- 服务端不丢失消息;
- 消费者也不能少消费消息。
生产者不少生产消息
使用带回调的发送消息的方法。
如果消息没有发送成功,那么Producer会按照配置的重试规则进行重试,如果重试次数用光后,还是消息发送失败,那么kafka会将异常信息通过回调的形式带给我们,这时,我们可以将没有发送成功的消息进行持久化,做后续的补偿处理。
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
// todo 处理发送失败的消息
}
}
});
-
复制代码
-
配置可靠性参数
2.1 配置
acks = -1- acks=0,表示生产者不等待任何服务器节点的响应,只要发送消息就认为成功。
- acks=1,表示生产者收到 leader 分区的响应就认为发送成功。
- acks=-1,表示只有当 ISR 中的副本全部收到消息时,生产者才会认为消息生产成功了。这种配置是最安全的,因为如果 leader 副本挂了,当 follower 副本被选为 leader 副本时,消息也不会丢失。但是系统吞吐量会降低,因为生产者要等待所有副本都收到消息后才能再次发送消息。
2.2 配置
retries = 3参数
retries表示生产者生产消息的重试次数,这里的3属于一个建议值,如果重试次数超过3次后,消息还是没有发送成功,可以根据自己的业务场景对发送失败的消息进行额外处理,比如持久化到磁盘,等待服务正常后进行补偿。 2.3 配置retry.backoff.ms=300参数
retry.backoff.ms表示重试的时间间隔,单位是毫秒,300ms是一个建议值,如果配置的时间间隔太短,服务可能仍然处于不可用状态。
服务端不丢失消息
-
配置
replication.factor > 1参数
replication.factor表示在服务端的分区副本数,配置> 1后,即使分区的leader挂掉,其他follower被选中为leader也会正常处理消息。 -
配置
min.insync.replicas > 1min.insync.replicas指的是 ISR 最少的副本数量,原理同上,也需要大于 1 的副本数量来保证消息不丢失。
简单介绍下 ISR。ISR 是一个分区副本的集合,每个分区都有自己的一个 ISR 集合。但不是所有的副本都会在这个集合里,首先 leader 副本是在 ISR 集合里的,如果一个 follower 副本的消息没落后 leader 副本太长时间,这个 follower 副本也在 ISR 集合里;可是如果有一个 follower 副本落后 leader 副本太长时间,就会从 ISR 集合里被淘汰出去。也就是说,ISR 里的副本数量是小于或等于分区的副本数量的.
-
确保 replication.factor > min.insync.replicas。
如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
-
配置
unclean.leader.election.enable = falseunclean.leader.election.enable指是否能把非 ISR 集合中的副本选举为 leader 副本。unclean.leader.election.enable = true,也就是说允许非 ISR 集合中的 follower 副本成为 leader 副本。因为非ISR集合中的副本消息可能已经落后leader消息很长时间,数据不完整,如果被选中作为leader副本,可能导致消息丢失。
消费者不少消费消息
-
手动提交消息
1.1 配置
enable.auto.commit=falseenable.auto.commit这个参数表示是否自动提交,设置成false后,将消息提交的权利交给开发人员。因为设置自动提交后,消费端可能由于消息消费失败,但是却自动提交,导致消息丢失问题。 1.2 手动提交消息的正确方式 先处理消息,后提交offset,代码如下:
kafkaConsumer.subscribe(Collections.singleton("foo"));
-
new Thread(() -> {
-
while (true) {
-
ConsumerRecords<String, Object> records = kafkaConsumer.poll(Duration.ofMillis(100));
-
handlerRecord(records);
-
kafkaConsumer.commitSync();
-
}
-
}).start();
-
} catch (Exception e) {
-
errHandler(e);
-
}复制代码
但是这种情况可能会导致消息已经消费成功,但是提交offset的时候,consumer突然宕机,导致消息提交失败,等到consumer重启后,可能还会收到已经成功处理过的消息,消费了重复的消息,所以手动提交消息需要做一些幂等性的措施。
-
由于网络原因,Producer端对消息进行了重试,但是,Broker端可能之前已经收到了消息,这样就导致broker端收到了重复的消息。
kafka在0.11.0 版本后,给每个Producer端分配了一个唯一的ID,每条消息中也会携带一个序列号,这样服务端便可以对消息进行去重,但是如果是两个Producer生产了两条相同的消息,那么kafka无法对消息进行去重,所以我们可以在消息头中自定义一个唯一的消息ID然后在consumer端对消息进行手动去重。
由于为了保证不少消费消息,配置了手动提交,由于处理消息期间,其他consumer的加入,进行了重平衡,或者consumer提交消息失败,进而导致接收到了重复的消息。
我们可以通过自定义唯一消息ID对消息进行过滤去重重复的消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号