
第一种方案数据库设计:
| 列名 | 数据类型 | 默认值 | 备注 |
| Id | int | 自增主键 | |
| Name | varchar(20) | 分类类别名称 | |
| ParentId | int | 0 | 父母分类Id |
| Depth | tinyint | 1 | 深度,从1递增 |
| Status | tinyint | 0 | 状态:0禁用,1启用 |
| Sort | int | 0 | 排序 |
此数据库设计方案一般通过递归来实现,不过由于此方案效率低效,所以下里面介绍的是通过php的引用来实现
代码实现:
header('Content-type:text/html;charset=utf-8'); $items = array( 4 => array('id' => 1, 'pid' => 0, 'name' => '江西省'), 6 => array('id' => 2, 'pid' => 0, 'name' => '黑龙江省'), 13 => array('id' => 3, 'pid' => 1, 'name' => '南昌市'), 17 => array('id' => 4, 'pid' => 2, 'name' => '哈尔滨市'), 25 => array('id' => 5, 'pid' => 2, 'name' => '鸡西市'), 64 => array('id' => 6, 'pid' => 4, 'name' => '香坊区'), 65 => array('id' => 7, 'pid' => 4, 'name' => '南岗区'), 83 => array('id' => 8, 'pid' => 6, 'name' => '和兴路'), 84 => array('id' => 9, 'pid' => 7, 'name' => '西大直街'), 85 => array('id' => 10, 'pid' => 8, 'name' => '东北林业大学'), 86=> array('id' => 11, 'pid' => 9, 'name' => '哈尔滨工业大学'), 124 => array('id' => 12, 'pid' => 8, 'name' => '哈尔滨师范大学'), 132 => array('id' => 13, 'pid' => 1, 'name' => '赣州市'), 144 => array('id' => 14, 'pid' => 13, 'name' => '赣县'), 154 => array('id' => 15, 'pid' => 13, 'name' => '于都县'), 162 => array('id' => 16, 'pid' => 14, 'name' => '茅店镇'), 174 => array('id' => 17, 'pid' => 14, 'name' => '大田乡'), 184 => array('id' => 18, 'pid' => 16, 'name' => '义源村'), 191 => array('id' => 19, 'pid' => 16, 'name' => '上坝村'), ); //先整理格式 $data = array(); foreach($items as $k=>$v){ $data[$v['id']] = $v; } $res = array(); //格式化 foreach($data as $k=>$v){ if($v['pid']){ $data[$v['pid']]['son'][] = &$data[$k]; }else{ //顶级节点 $res[] = &$data[$k]; } }
第二种数据库设计,在表字段中增加一个 path 字段
| 列名 | 数据类型 | 默认值 | 备注 |
| Id | int | 自增主键 | |
| Name | varchar(20) | 分类类别名称 | |
| ParentId | int | 0 | 父母分类Id |
| Depth | tinyint | 1 | 深度,从1递增 |
| Status | tinyint | 0 | 状态:0禁用,1启用 |
| Path | varchar(255) | 记录从根分类到父类的路径,eg:0-1-5,数字是id |
示例数据:
id name pid path depth
1 电脑 0 0 1
2 手机 0 0 1
3 笔记本 1 0-1 2
4 超级本 3 0-1-3 3
5 游戏本 3 0-1-3 3
这种方式,假设我们要查询电脑下的所有后代分类,只需要一条sql语句:
select id,name from category where path like ( select concat(path,'-',id,'%') path from category where id=1 );
优点:查询容易,效率高,path字段可以加索引。
缺点:更新节点关系麻烦,需要更新所有后辈的path字段。
第三种数据库设计(利用前序遍历树实现)
数据库如下:
| 列名 | 数据类型 | 默认值 | 备注 |
| Id | int | 自增主键 | |
| Name | varcahr(20) | 分类类别名称 | |
| Lft | int | 节点左值 | |
| Rft | int | 节点右值 |
数据结构图:
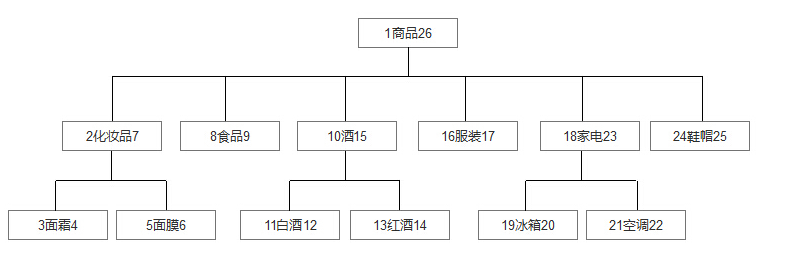
对应上图示示例数据:
id name lft rft
1 商品 1 26
2 化妆品 2 7
3 食品 8 9
4 酒 10 15
5 服装 16 17
6 家电 18 23
7 鞋帽 24 25
8 面霜 3 4
9 面膜 5 6
10 白酒 11 12
11 红酒 13 14
12 冰箱 19 20
13 空调 21 22
具体代码实现参考:https://www.jianshu.com/p/48f6db8ea524
