


昨晚用dom4j中的selectSingleNode解析xml,匹配节点。
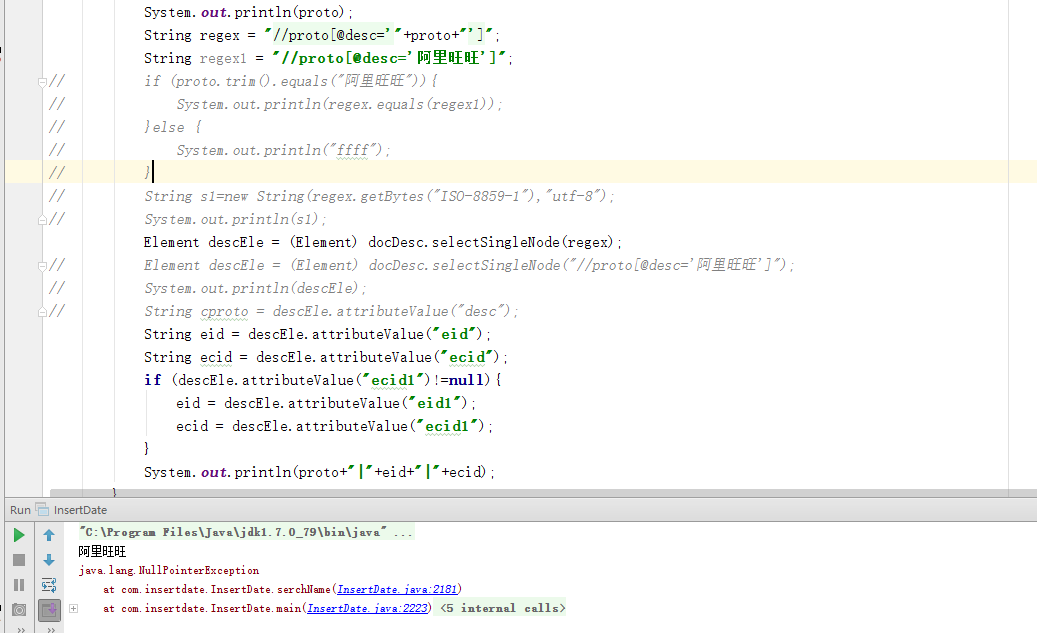
发现匹配不到,但是确实存在该节点
将regex改为regex1后则可以匹配,也就是说文件中的“阿里旺旺”和程序中的“阿里旺旺”不相等。
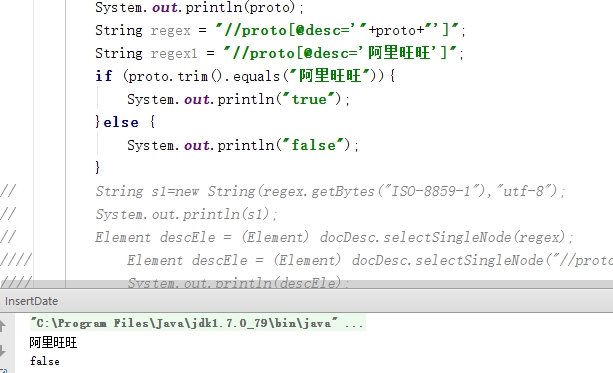
此时有经验的人都会想到编码问题,于是我尝试各种编码发现都不行,结果最后在此处发现UTF-8还有两种格式

尝试讲文件换成UTF-8无BOM格式则匹配成功
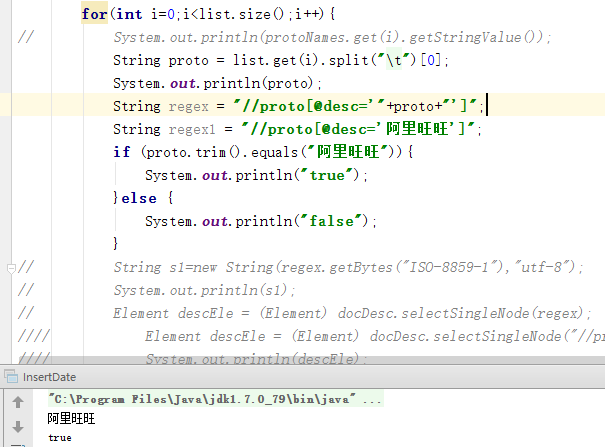
查阅资料发现BOM其实是一个编码标识符,用来标识该文件的编码的,因此windows下程序读取文件的时候会有编码问题,因此在需要读取中文并且做匹配的时候,请使用UTF-8无BOM格式编码的文件。
人生苦短,远离IT脱离苦海
