

4.2.0 头文件
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
4.2.1 下载fashion_mnist数据集
# 定义批量大小
batch_size = 256
# 下载fashion_mnist,并对数据集进行打乱和按批量大小进行切割的操作,得到可迭代的训练集和测试集(训练集和测试集的形式都为(特征数据集合,数字标签集合))
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
4.2.2 初始化模型参数
# 输入维度(28×28)、输出类别数、隐藏单元数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# W1权重规模为(784行,256列)
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
# b1偏移量规模为256个
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# W1权重规模为(256行,10列)
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
# b2偏移量规模为10个
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
# 将模型参数打包
params = [W1, b1, W2, b2]
4.2.3 网络模型
# 定义relu激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 定义网络模型
def net(X):
X = X.reshape((-1, num_inputs)) #将输入特征压平成一行
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法 一个全连接层加relu激活函数
return (H@W2 + b2) # 一个全连接层加relu激活函数
4.2.4 损失函数
# 定义交叉熵损失函数,得到的结果为每个样本的损失
loss = nn.CrossEntropyLoss(reduction='none')
4.2.4 优化器
# 定义学习率
lr = 0.1
# 定义小批量梯度下降优化器
updater = torch.optim.SGD(params, lr=lr)
4.2.6 训练过程
# 定义训练轮数
num_epochs = 10
# 开始训练
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
4.2.7 训练结果可视化
plt.savefig('Output.png')
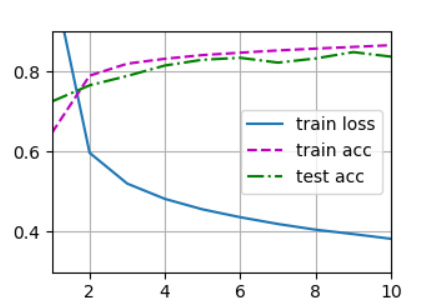
本小节完整代码如下所示
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
# ------------------------------下载fashion_mnist数据集------------------------------------
# 定义批量大小
batch_size = 256
# 下载fashion_mnist,并对数据集进行打乱和按批量大小进行切割的操作,得到可迭代的训练集和测试集(训练集和测试集的形式都为(特征数据集合,数字标签集合))
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# ------------------------------初始化模型参数------------------------------------
# 输入维度(28×28)、输出类别数、隐藏单元数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# W1权重规模为(784行,256列)
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
# b1偏移量规模为256个
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# W1权重规模为(256行,10列)
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
# b2偏移量规模为10个
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
# 将模型参数打包
params = [W1, b1, W2, b2]
# ------------------------------网络模型------------------------------------
# 定义relu激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 定义网络模型
def net(X):
X = X.reshape((-1, num_inputs)) #将输入特征压平成一行
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法 一个全连接层加relu激活函数
return (H@W2 + b2) # 一个全连接层加relu激活函数
# ------------------------------损失函数------------------------------------
# 定义交叉熵损失函数,得到的结果为每个样本的损失
loss = nn.CrossEntropyLoss(reduction='none')
# ------------------------------优化器------------------------------------
# 定义学习率
lr = 0.1
# 定义小批量梯度下降优化器
updater = torch.optim.SGD(params, lr=lr)
# ------------------------------训练过程------------------------------------
# 定义训练轮数
num_epochs = 10
# 开始训练
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
# ------------------------------训练结果可视化------------------------------------
plt.savefig('Output.png')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号