

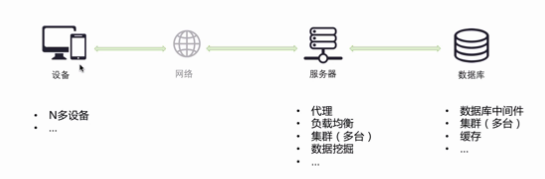
前端:WEB端、客户端(iOS、Android)
后端:后台
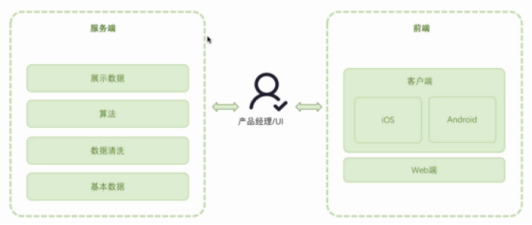
服务器:展示数据、算法、数据清洗、基本数据
域名(Domain Name),是由一串用“点”分隔的字符组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置,地理上的域名,指代有行政自主权的一个地方区域)。域名是一个IP地址上有“面具” 。
域名的目的是便于记忆和沟通的一组服务器的地址(网站,电子邮件,FTP等)
域名解析:至少有7种常用解析,了解前2种就够了
A记录、CNAME记录、MX记录、NS记录、TXT记录、TTL值….
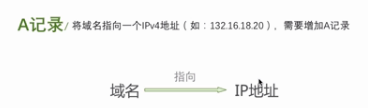
A记录:将域名指向一个IPv4地址(如132.16.18.20),需要增加A记录
域名→IP地址
IPv4:4小段(132.16.18.20)
IPv6:6小段

一级域名:http://baidu.com
二级域名:http://c.baidu.com
特别的二级域名:www.baidu.com
三级域名:www.www.baidu.com

CNAME记录:将一个域名指向另一个域名,实现与被指向域名相同的访问效果
100域名同时指向另一个域名,另一个域名指向一个IP地址,只要另一个域名到IP的指向不出错,前100个域名都不会有问题,如果另一个域名指向IP出错,那么只有一个域名是错误,剩余99个域名还是正常的;如果想修改IP地址,可以只修改一次IP地址就可以实现100个域名都修改的效果。

URL:统一资源定位符(Uniform Resource Locator,缩写为URL),又叫做网页地址,是互联网上标准的资源的地址(Address)。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。

http:80端口(传统)
https:443端口(更安全一些)
ftp:FTP 是File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的FTP应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在FTP的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。"下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用Internet语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
thunder:迅雷
主机名:可以当成域名来理解。
端口:不指定端口就默认80和443
端口其实就是队,操作系统为各个进程分配了不同的队,数据包按照目标端口被推入相应的队中,等待被进程取用。
路径:一般指资源的位置。资源存放的位置
参数:在URL上带一些本地信息给服务器,例如可以在广告位置加参数统计点击。
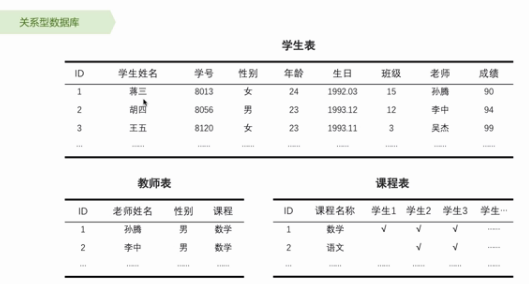
数据库:database 按照数据结构来组织、储存和管理数据的建立在计算机存储设备上的仓库。(存东西)
数据各种多,存储方法各种多,什么时候需要使用数据库?(以关系型数据库为例)什么场景下需要使用数据库?


注意:对于游戏等可能牵扯到经济利益的应用来说,使用客户端的缓存运算来分担服务器压力的时候,更想好哪些是可以放在客户端的,不然容易被篡改数据导致游戏不公平。
2、关系型数据库与非关系型数据库
关系型数据库通过外界关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。(百度知道)
关系型数据库:表与表
非关系型数据库:对象



货车类似关系型数据库
跑车类似非关系型数据库

 速度慢的原因:表连接
速度慢的原因:表连接
3、SQL操作:增删改查
根据二八定律,关系型数据库可以覆盖大多数应用场景,此处只讲关系型数据库
数据库这门学科的教学课程是很多范本中都会拿关系型数据库去做典型。

关系型数据库是由一张一张表组成。
分表:将一个表结构分为多少个表。
由于业务场景、业务扩展、查找效率等....需要进行分表。
某些场景下表之间一定需要相互连接,即一对多或多对多的关系
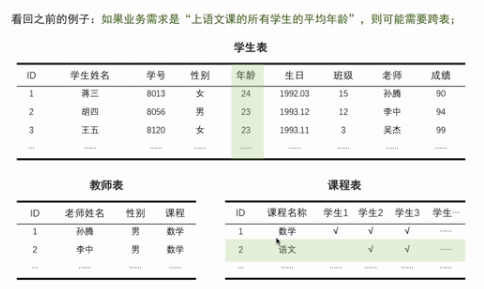
关于数据库,产品经理需要注意的几点:
1.定好表结构后再加数据非常难:注意要提前想好未来业务扩展可能性
2.增删改查是数据库语言的常见4操作:注意效率
3.产品的用户量级和频率影响表结构:针对某些复杂的业务模型,如运营的特殊需求可采用离线查询的方式
4.表的行数超过一定限制可能出问题:注意预估业务规模
4、数据库结构的变化

从多方爬取的数据在格式上不统一:比如薪资有的是10,000,有的是10000,有的是1w
在内容上与初步需求不完全符合:比如有的公司有简介,有的没有

新增字段:改字段的时候,在末支表中改;如果在主干表中改,表连接什么的可能会出现问题。(表连接比较少的为主干表,表连接比较多的一般为支干表)
5、数据库的索引


6、离线的数据

离线:一般指非实时的代称
运营的需求:运营数据查看的需求
7、数据库的优化

不建议把所有字段都加索引
学一些通用性的东西,营运、技术、线下活动的设计;学习代码,和程序员交流

用缓存的方法就可以高速查询。
硬盘的读写速度没有内存快。Redis可以做持久化,不怕突然断电等情况。
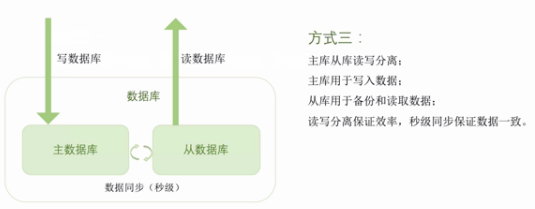
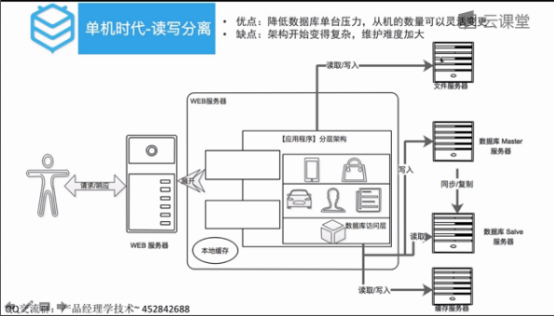
读写分离:读的数据库,写的数据库两个数据库分开,主库用来写,从库用来读;秒级主从库数据不一致的问题怎么解决?
8、大数据

Hadoop查的是文件,
9、技术架构入门级
单机时代

web服务器的应用程序是混在一起的
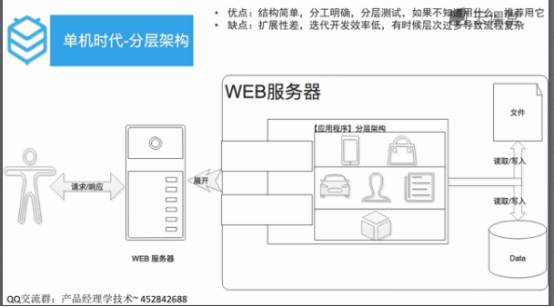
对web服务器的应用成进行了分层架构
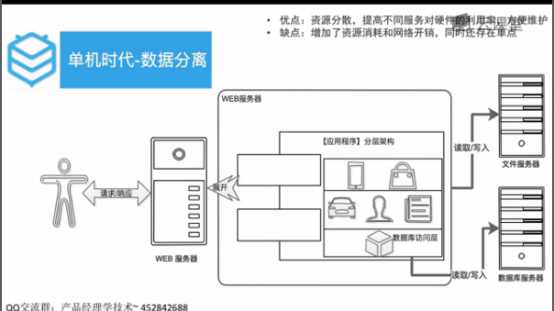
对文件服务器和数据服务器进行分层管理
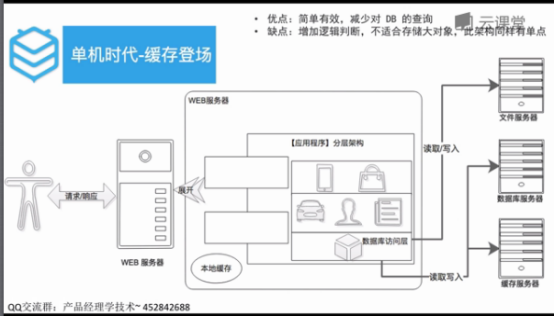
在数据服务器中将缓存服务器单分出来。
加缓存是区分高低频
集群时代
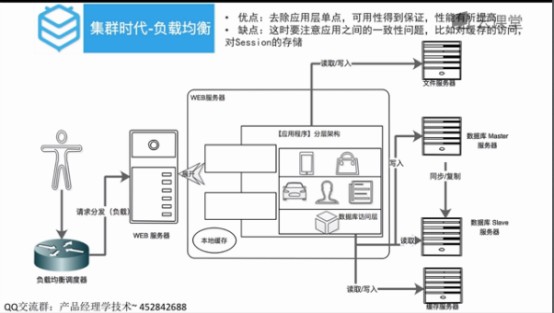
负载均衡:会话保持在同一台

把不变的资源和变的资源进行动静分离,把静态的资源缓存一下,动的走分发途径
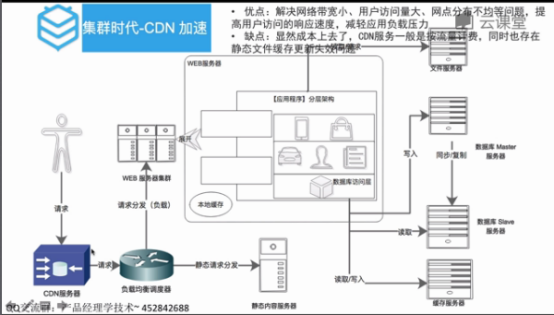
加CDN服务器:把资源分配全国各地
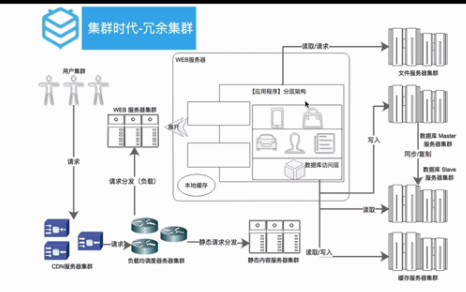
集群化:高可用确保没有单点(一个坏掉另外一个可以替补,保证正常运行)
分布式时代

先硬件后软件,然后软件在拆分,硬件扩
解耦合

