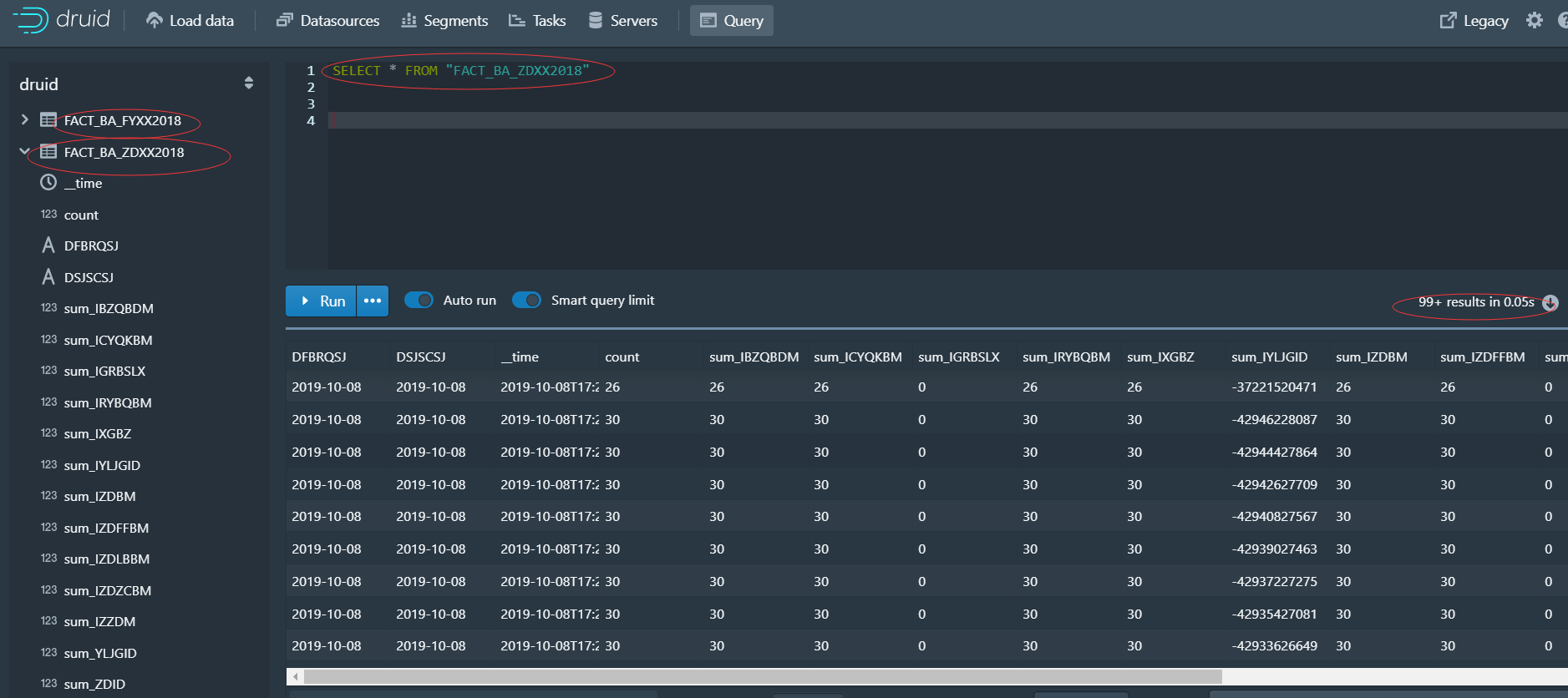
1、界面
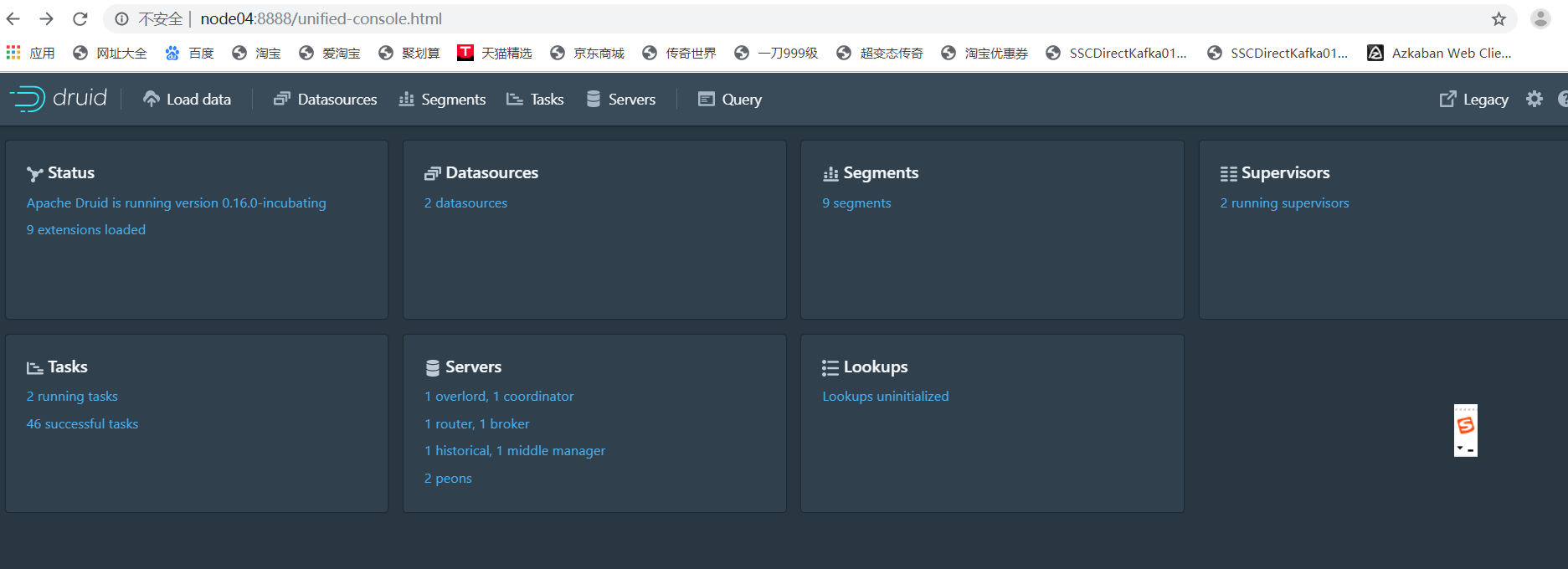
status:
可以看见apache druid的版本号,现在是0.16.0,里面有9个扩展项
datasource:
监控数据源:我提交了两次索引服务,所以现在有两个2个DataSource
segment:
监控segment:里面有9个Segment,每个Datasource由多个segment组成
supervisors:
监控提交的任务:提交索引服务会使用到这个主管,我提交了两次,所以现在有两个正在运行
Tasks:
运行的任务监控
servers:
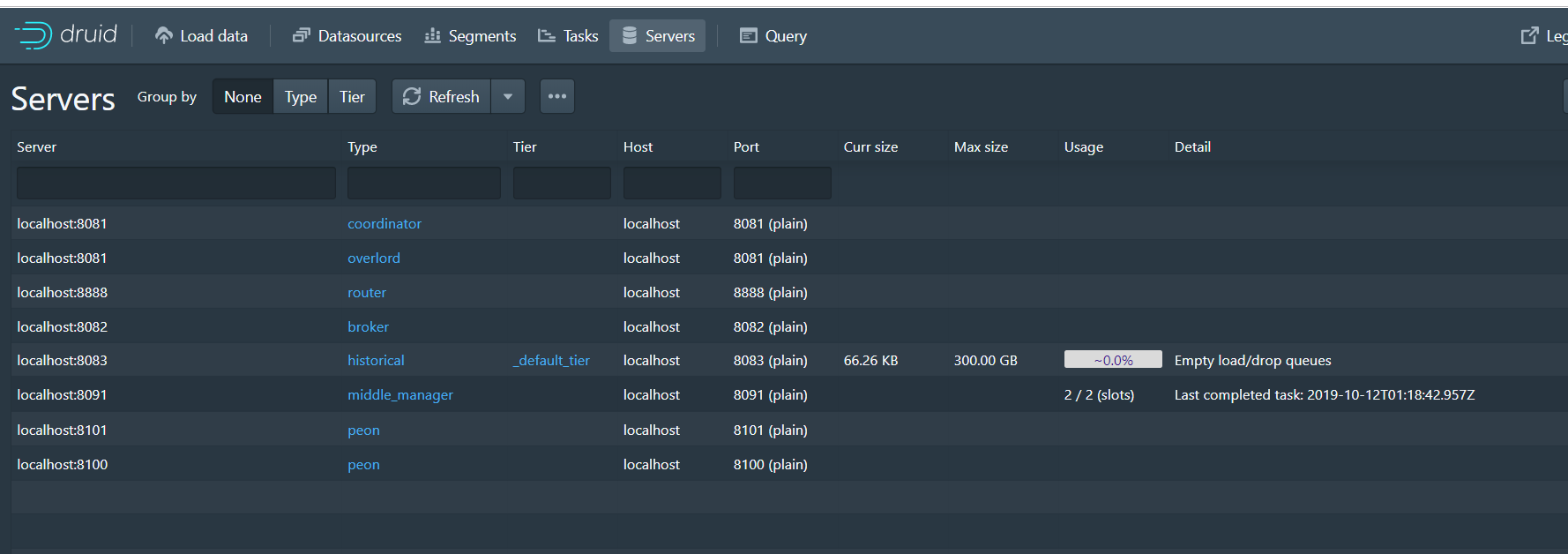
druid上运行的服务监控:1个统治节点、一个协调节点、一个路由节点、一个查询节点、一个历史节点、一个中间管理者、2个苦工
Lookups:
Apache Druid(正在孵化)中的一个概念,其中维度值(可选)被新值替代,譬如四川省的编码为01,能够通过维度表,可以直接更改为四川省!
eg:
SELECT LOOKUP(column_name, 'lookup-name'), COUNT(*) FROM datasource GROUP BY 1
2、DataSource
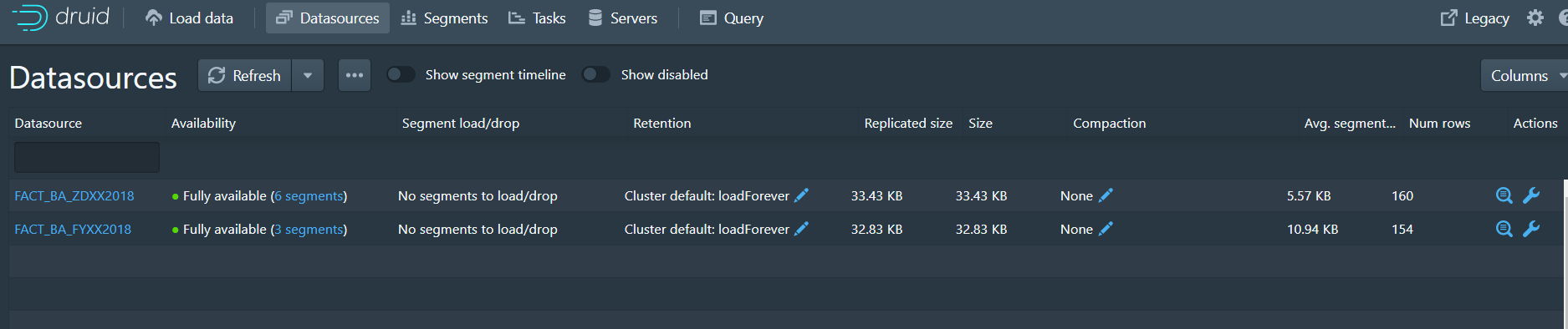
Available:
datasource中的那些segment可用
Segment load/drop:
segment的加载和删除情况,受retention影响
retention:
配置segment的规则,现在上面的规则是:无论何时集群都加载
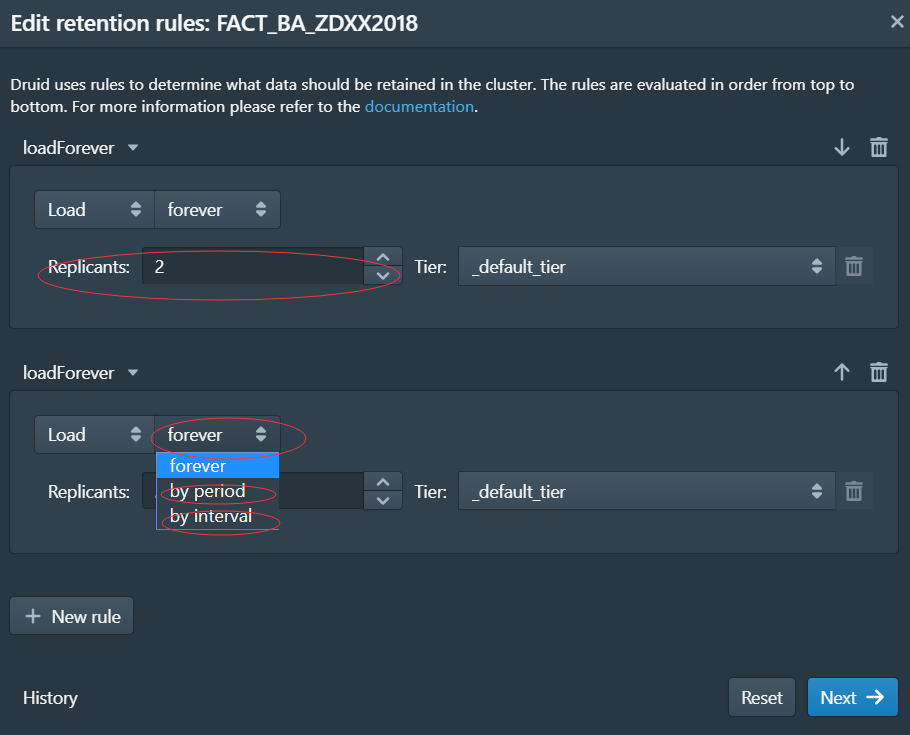
可以配置
segment的副本数、
通过间隔时间加载:经常用于流处理
通过时间段加载: 经常用于批处理,比如离线数据我们只是加载我们想要的时间段的数据
Compaction:
配置合并规则,用与合并segment
actions:
放大镜里面是数据列和数据类型
设置里面可以删除、禁用DataSource
3、segment
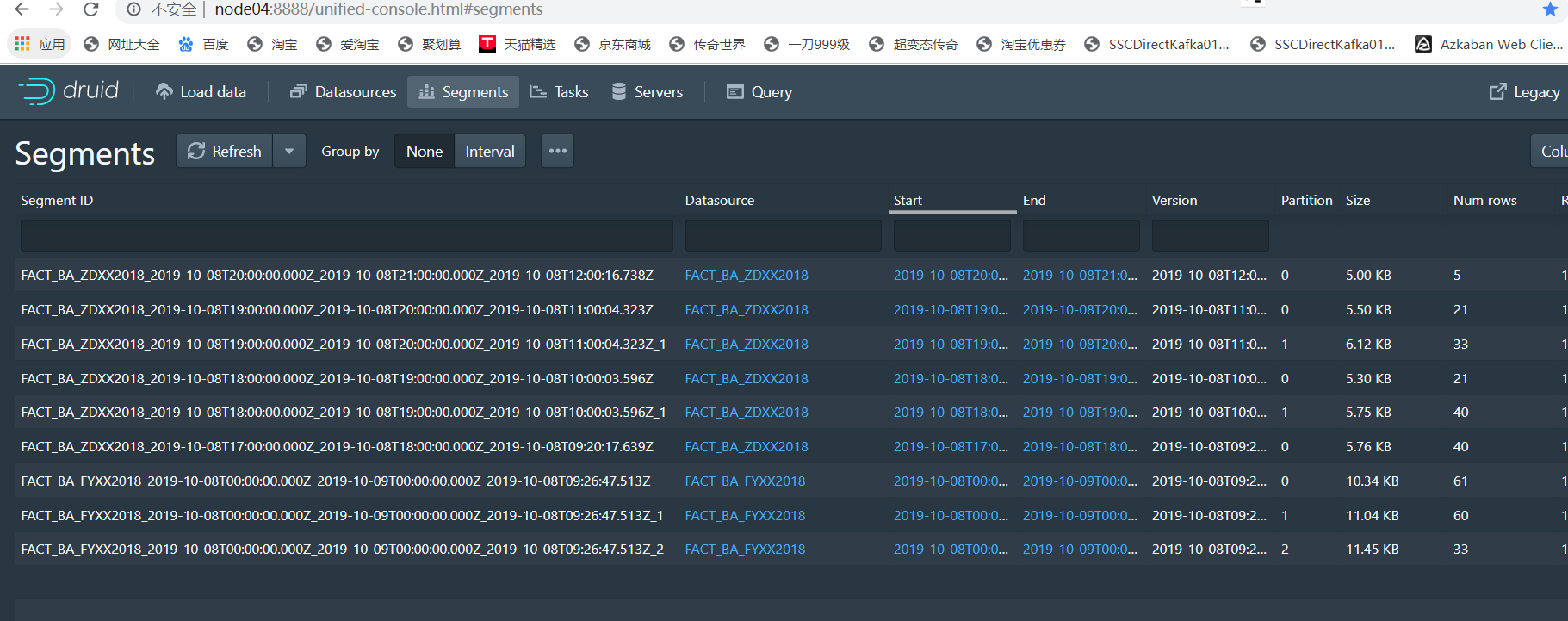
Segment ID:
在上一篇博客中说了,由四部分组成:
DataSource 名称 + segment时间间隔(数据的起始时间 + 数据的结束时间) + 版本号 (此segment的启动时间) + 分区号
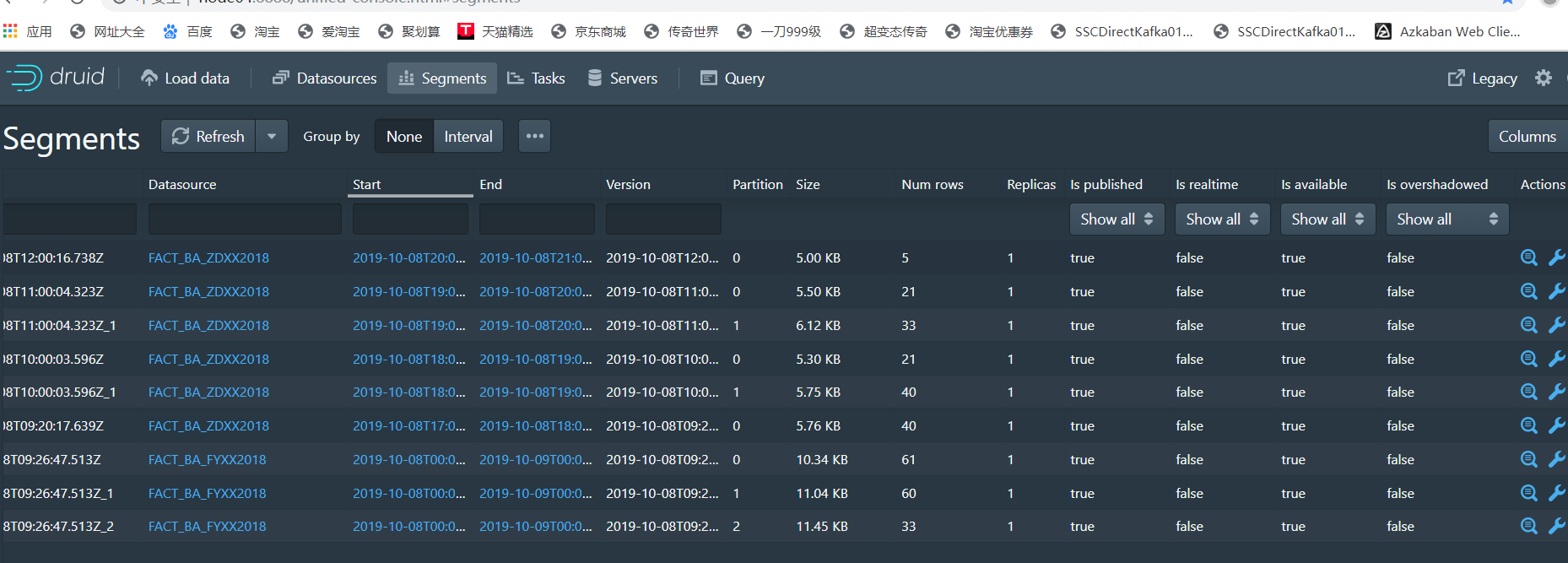
is published:
是否发布:当索引服务将数据生成segment并且写入到了元数据,那么就是true
is realtime:
如果是由实时任务产生的,那么会为true,但是一段时间之后,也会变为false,所以估计是segment是否存在于实时节点
is available:
如果Segment当前可用于查询(实时任务或历史进程),则为true。
is_overshadowed:
标记该段是否已被其他段覆盖!处于此状态的段很快就会将其used标志自动设置为false。
4、task
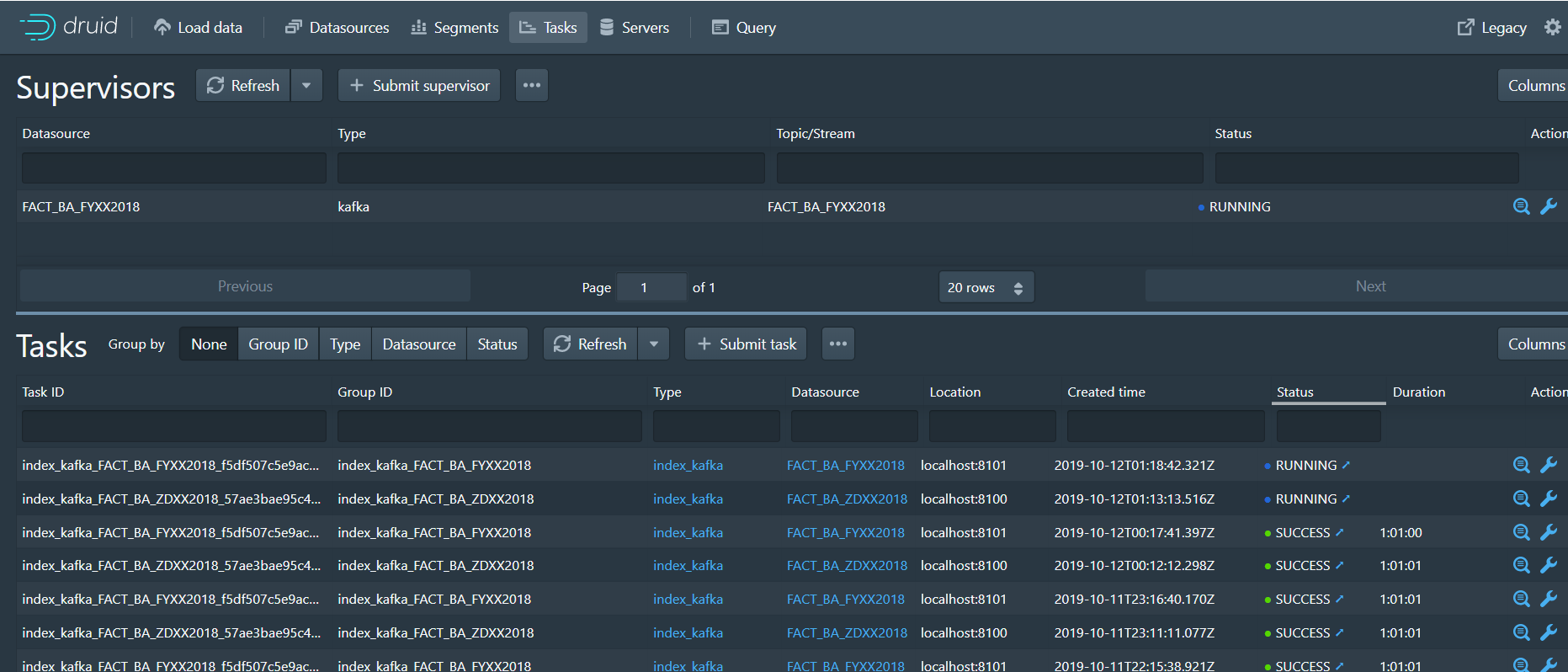
我现在有一个任务运行,他接受kafka的数据,DataSource叫FACT_BA_FYXX2018,每隔一个小时产生一个segment,所以每一个小时会触发一个task
这并不代表我一个小时之后才能查询出数据,如果任务没触发,但是我们仍然可以从实时节点查询出数据
5、Servers
6、query