


-
[ ceph ] 基本概念、原理、架构介绍
-
三种存储类型
块设备:主要是将裸磁盘空间映射给主机使用,类似于SAN存储,使用场景主要是文件存储,日志存储,虚拟化镜像文件等。
文件存储:典型代表:FTP 、NFS 为了克服块存储无法共享的问题,所以有了文件存储。
对象存储:具备块存储的读写高速和文件存储的共享等特性并且通过 Restful API 访问,通常适合图片、流媒体存储。 -
Ceph 支持三种接口
Object:有原生的API,而且也兼容 Swift 和 S3 的 API
Block:支持精简配置、快照、克隆
File:Posix 接口,支持快照 -
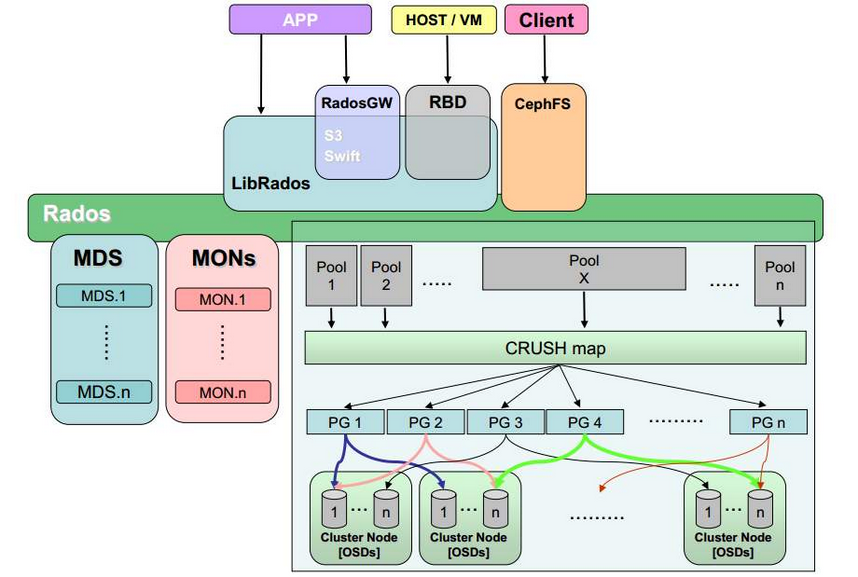
Ceph 核心组件及概念介绍
Monitor:一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
OSD:OSD 全称 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程,一个Ceph集群一般有很多个OSD。
CRUSH:CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的位置。
PG:PG全称 Placement Groups,是一个逻辑的概念,一个PG 包含多个 OSD 。引入 PG 这一层其实是为了更好的分配数据和定位数据。
Object:Ceph 最底层的存储单元是 Object对象,每个 Object 包含元数据和原始数据。
RADOS:实现数据分配、Failover 等集群操作。
Libradio:Libradio 是RADOS提供库,因为 RADOS 是协议,很难直接访问,因此上层的 RBD、RGW和CephFS都是通过libradios访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++的支持。
MDS:MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
RBD:RBD全称 RADOS Block Device,是 Ceph 对外提供的块设备服务。
RGW:RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
CephFS:CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。 -
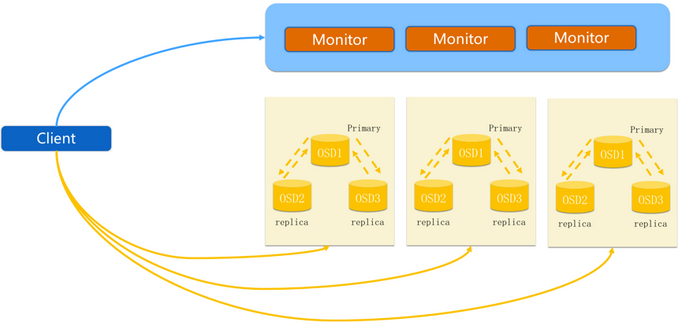
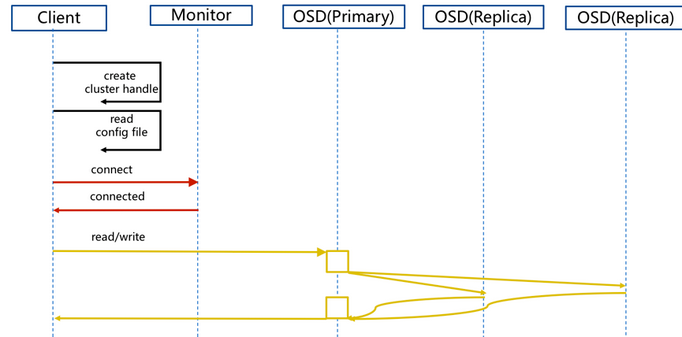
Ceph IO流程及数据分布
- 步骤
6.1 client 创建cluster handler。
6.2 client 读取配置文件。
6.3 client 连接上monitor,获取集群map信息。
6.4 client 读写io 根据crushmap 算法请求对应的主osd数据节点。
6.5 主osd数据节点同时写入另外两个副本节点数据。
6.6 等待主节点以及另外两个副本节点写完数据状态。
6.7 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
部署集群
注意:安装ceph集群之前要修改所有服务器主机名并修改/etc/hosts文件(如果安装了k8s集群就不用配置了)
环境:
node1 - osd节点和mon节点 (添加磁盘随意1-n)
node2 - osd节点和mon节点 (添加磁盘随意1-n)
node3 - osd节点和mon节点 (添加磁盘随意1-n)
master2 - client 客户端访问节点
master1 - 部署节点(deploy)、MDS节点、osd (添加磁盘随意1-n)
一.关闭防火墙 略(所有节点)
二.关闭selinux 略(所有节点)
三.配置服务器master1到node3的免密登陆
https://www.cnblogs.com/lfl17718347843/p/13883867.html
四.添加磁盘并格式化(除了客户端)
https://www.cnblogs.com/lfl17718347843/p/13879177.html
五.所有节点创建ceph用户(这步不需要可以忽略,随意)
useradd cephfsd
echo "miller" |passwd cephfsd --stdin
echo "cephfsd ALL = (root,ceph) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephfsd
chmod 0440 /etc/sudoers.d/cephfsd
六.所有节点添加yum源
vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
七.在master1部署节点切换ceph用户,没创建的不用切换,直接用root
su - cephfsd
八.在所有节点安装依赖包
yum -y install epel-release
yum -y install ceph ceph-radosgw ceph-deploy
yum -y install htop sysstat iotop iftop ntpdate net-tools
九.在mastert1节点部署ceph集群
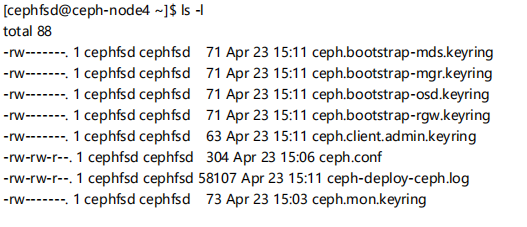
ceph-deploy new node1 node2 node3 (初始化集群配置)
ls -l

vim ceph.conf (配置文件增加内容)
[global]
fsid = 54a9ee80-2339-407d-8fb8-e0b04480b132 ## 集群ID
mon_initial_members = ceph-node1, ceph-node2, ceph-node3 ## mon节点信息
mon_host = 192.168.4.81,192.168.4.83,192.168.4.84 ## mon节点ip
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx ## auth = cephx 开启认证
osd_pool_default_size = 2 ## 集群副本数
osd_pool_default_min_size = 1 ## 集群最小副本数
mon_osd_full_ratio = .95 ## osd使用率

ceph-deploy mon create-initial (创建monitor)
ls -l
ceph-deploy admin node1 node2 node3 (分发集群keyring)
ceph-deploy mgr create node1 node2 node3 (创建mgr)
ceph-deploy osd create --data /dev/sdb node1 (创建osd)
十.查看集群是否成功(不能使用部署节点和客户端节点查看,切换到集群节点node1-node3)
ceph -s
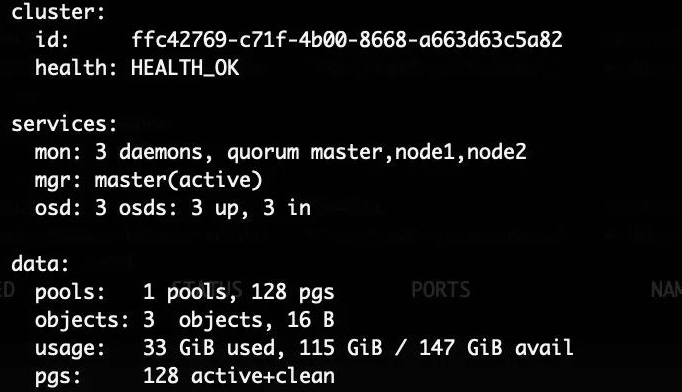
备注:出现health_ok代表集群健康 (到此ceph集群部署完成)

