

HA的2种部署方式
一种是将etcd与Master节点组件混布在一起
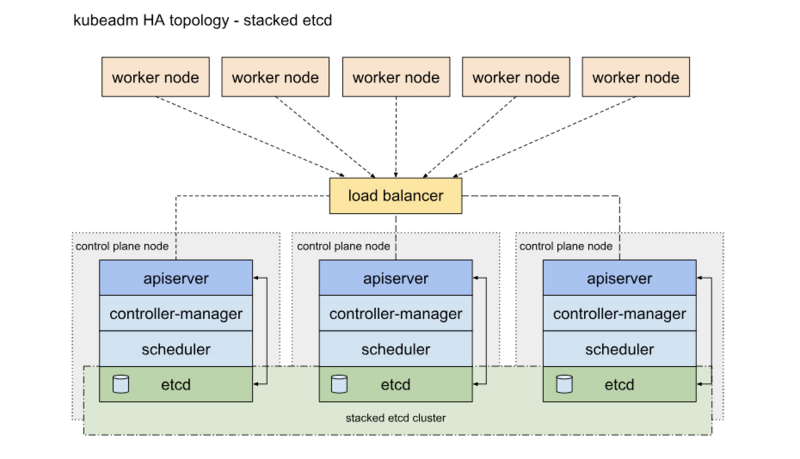
另外一种方式是,使用独立的Etcd集群,不与Master节点混布

本章是用第一种叠加式安装的
通过 kubeadm 搭建一个高可用的 k8s 集群,kubeadm 可以帮助我们快速的搭建 k8s 集群,高可用主要体现在对 master 节点组件及 etcd 存储的高可用,文中使用到的服务器 ip 及角色对应如下:
| master 节点 | etcd 节点 | node 节点 | vip |
|---|---|---|---|
| 192.168.200.3 | 192.168.200.3 | 192.168.200.6 | 192.168.200.16 |
| 192.168.200.4 | 192.168.200.4 | ||
| 192.168.200.5 | 192.168.200.5 |
1、更改各节点主机名
hostnamectl set-hostname 主机名
2、配置各节点 hosts 文件
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.200.3 master1
192.168.200.4 master2
192.168.200.5 master3
192.168.200.6 node1
3、关闭各个节点防火墙
systemctl stop firewalld && systemctl disable firewalld
4、关闭各节点 SElinux (需要重启服务器)
sed -i 's/^ *SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
5、关闭各节点 swap 分区 (需要重启服务器)
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
6、各节点安装 ipset 服务
yum -y install ipvsadm ipset sysstat conntrack libseccomp
7、各节点开启 ipvs 模块
cat /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
8、各节点内核调整,将桥接的 IPv4 流量传递到 iptables 的链
cat /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
modprobe br_netfilter && sysctl -p /etc/sysctl.d/k8s.conf
9、安装 chrony 并编辑 chrony.conf
yum -y install chrony
cat /etc/chrony.conf
server ntp.aliyun.com iburst
allow 0.0.0.0/0
local stratum 10
加入开机启动并重启
systemctl enable chronyd && systemctl start chronyd
timedatectl set-timezone Asia/Shanghai && chronyc -a makestep
10、所有 master 节点安装 haproxy 和 keepalived 服务
yum -y install keepalived haproxy
12、修改 master1 节点 keepalived 配置文件(其他两个 master 节点只修改权重,把 master 改成 backup)
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
# 添加如下内容
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh" # 检测脚本路径
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER # MASTER
interface ens33 # 本机网卡名
virtual_router_id 51
priority 100 # 权重100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.200.16 # 虚拟IP
}
track_script {
check_haproxy # 模块
}
}
13、三台 master 节点 haproxy 配置都一样
cat /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# http://haproxy.1wt.eu/download/1.4/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master1 192.168.200.3:6443 check
server master2 192.168.200.4:6443 check
server master3 192.168.200.5:6443 check
14、每台 master 节点编写健康检测脚本
cat /etc/keepalived/check_haproxy.sh
#!/bin/bash
# HAPROXY down
A=`ps -C haproxy --no-header | wc -l`
if [ $A -eq 0 ]
then
systmectl start haproxy
if [ ps -C haproxy --no-header | wc -l -eq 0 ]
then
killall -9 haproxy
echo "HAPROXY down" | mail -s "haproxy"
sleep 3600
fi
fi
15、给脚本增加执行权限
chmod +x /etc/keepalived/check_haproxy.sh
16、启动 keepalived 和 haproxy 服务并加入开机启动
systemctl enable keepalived && systemctl start keepalived
systemctl enable haproxy && systemctl start haproxy
17、各节点下载 docker 源
wget https://download.docker.com/linux/centos/docker-ce.repo -O /etc/yum.repo.d/
18、k8s 版本与 docker 版本兼容关系 (本章接用的docker-ce版本是18.06)
如果kubernetes的版本为1.8-1.11,docker版本必须为1.11.2-1.13.1和docker-ce版本为17.03.x
如果kubernetes的版本从1.12开始,docker版本必须为17.06/17.09/18.06
19、查看 docker-ce 版本
yum list docker-ce --showduplicates | sort -r
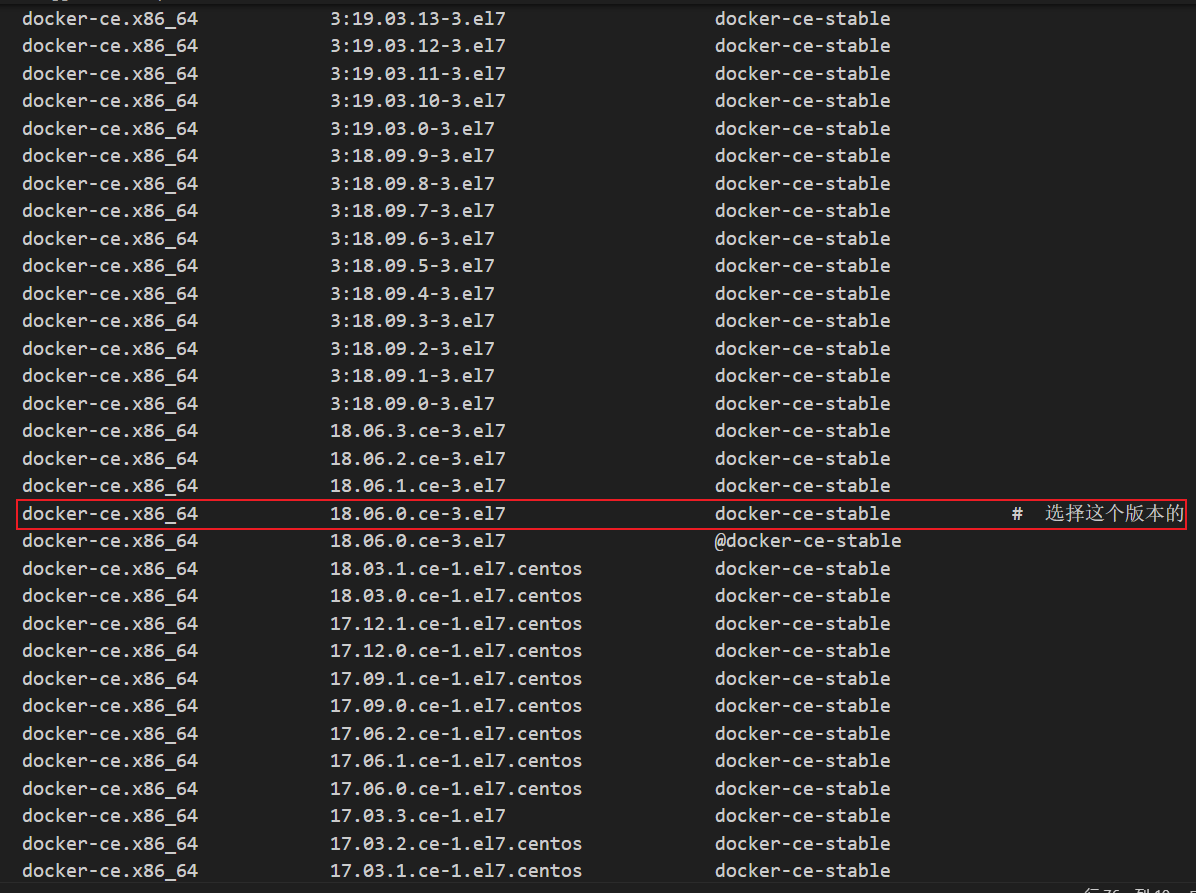
20、各节点安装 docker 服务并加入开机启动
yum -y install docker-ce-18.06.0.ce-3.el7 && systemctl enable docker && systemctl start docker
21、各节点配置 docker 加速器并修改成 k8s 驱动
daemon.json 文件如果没有自己创建
cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
22、重启 docker 服务查看 docker 驱动是否和 k8s 集群驱动一致
systemctl restart docker && docker info | grep Cgroup
Cgroup Driver: systemd # 出现systemd说明驱动对了
23、配置各节点 k8s 的 yum 源
cat /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
24、每个节点安装 kubeadm,kubelet 和 kubectl # 安装的 kubeadm、kubectl 和 kubelet 要和 kubernetes 版本一致,kubelet 加入开机启动之后不要手动启动,要不然会报错,初始化集群之后集群会自动启动 kubelet 服务!!!
yum -y install kubeadm-1.18.2 kubelet-1.18.2 kubectl-1.18.2 && systemctl enable kubelet && systemctl daemon-reload
25、获取默认配置文件
kubeadm config print init-defaults > kubeadm-config.yaml
26、修改初始化配置文件
cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.200.3 # 本机IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.200.16:16443 # 虚拟IP和haproxy端口
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 镜像仓库源要根据自己实际情况修改
kind: ClusterConfiguration
kubernetesVersion: v1.18.2 # k8s版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates: # k8s1.19和1.20版本可能需要删掉这两行代码
SupportIPVSProxyMode: true ######
mode: ipvs
27、下载相关镜像
kubeadm config images pull --config kubeadm-config.yaml
28、初始化集群
kubeadm init --config kubeadm-config.yaml
30、在其它两个 master 节点创建以下目录
mkdir -p /etc/kubernetes/pki/etcd
31、把主 master 节点证书分别复制到其他 master 节点
ip="192.168.200.4 192.168.200.5"
for host in $ip
do
scp /etc/kubernetes/pki/ca.* root@192.168.200.4:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@192.168.200.4:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@192.168.200.4:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@192.168.200.4:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@192.168.200.4:/etc/kubernetes/
scp /etc/kubernetes/pki/ca.* root@192.168.200.5:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@192.168.200.5:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@192.168.200.5:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@192.168.200.5:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@192.168.200.5:/etc/kubernetes/
done
32、把 master 主节点的 admin.conf 复制到其他 node 节点
scp /etc/kubernetes/admin.conf root@192.168.200.6:/etc/kubernetes/
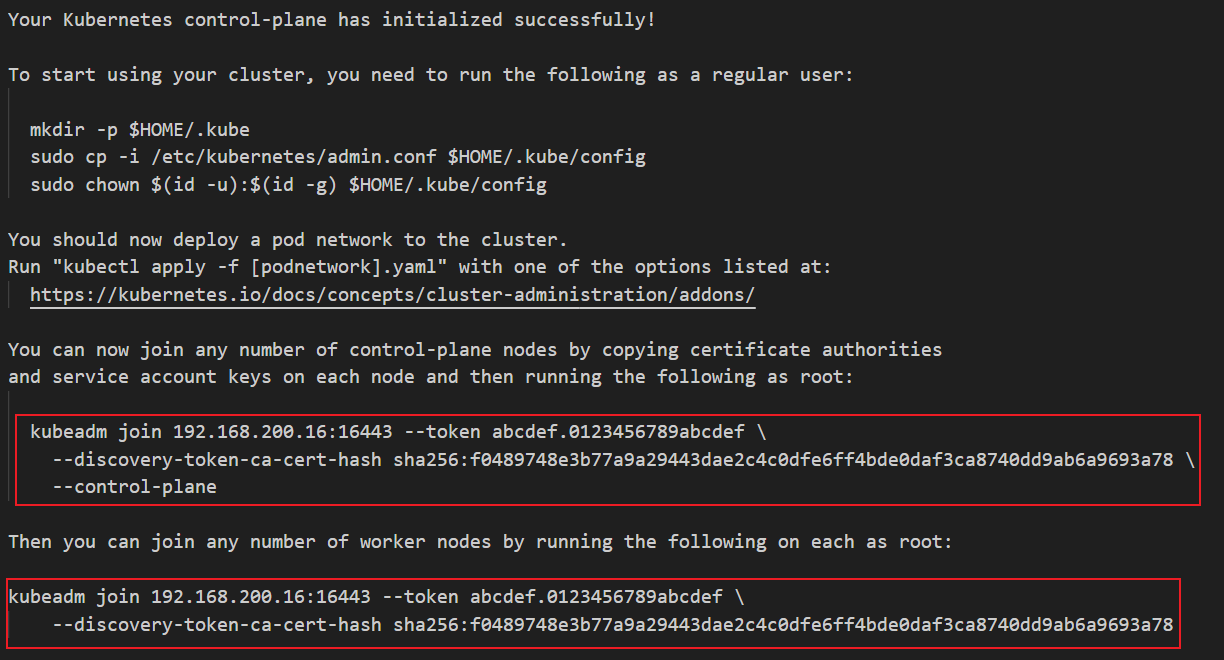
33、master 节点加入集群执行以下命令
kubeadm join 192.168.200.16:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:f0489748e3b77a9a29443dae2c4c0dfe6ff4bde0daf3ca8740dd9ab6a9693a78 \
--control-plane
34、node 节点加入集群执行以下命令
kubeadm join 192.168.200.16:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:f0489748e3b77a9a29443dae2c4c0dfe6ff4bde0daf3ca8740dd9ab6a9693a78
35、所有 master 节点执行以下命令,node 节点随意
root 用户执行以下命令
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source .bash_profile
非 root 用户执行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
36、查看所有节点状态
kubectl get nodes

37、安装网络插件
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
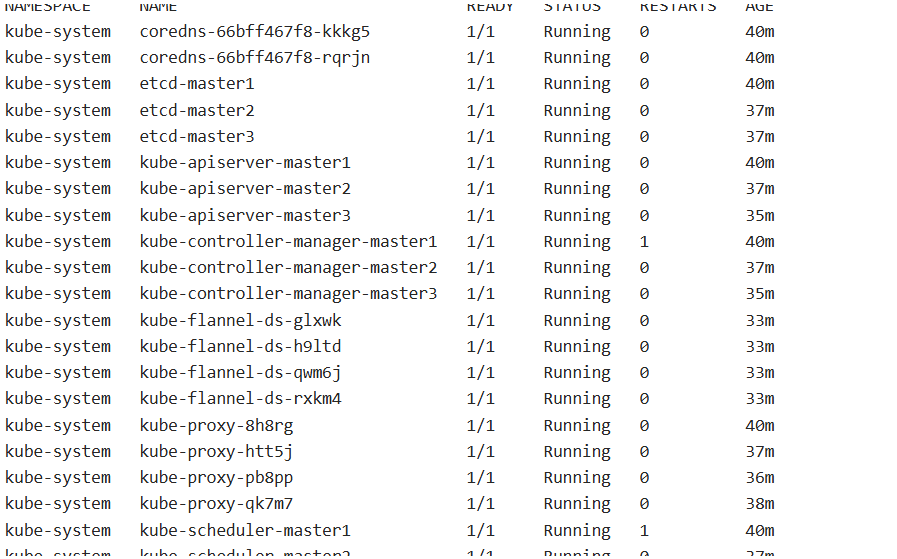
38、查看节点状态
kubectl get nodes

kubectl get pods --all-namespaces
39、下载 etcdctl 客户端命令行工具
wget https://github.com/etcd-io/etcd/releases/download/v3.4.14/etcd-v3.4.14-linux-amd64.tar.gz
40、解压并加入环境变量
tar -zxf etcd-v3.4.14-linux-amd64.tar.gz
mv etcd-v3.4.14-linux-amd64/etcdctl /usr/local/bin
chmod +x /usr/local/bin/
41、验证 etcdctl 是否能用,出现以下结果代表已经成功了
etcdctl

42、查看 etcd 高可用集群健康状态
ETCDCTL_API=3 etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --write-out=table --endpoints=192.168.200.3:2379,192.168.200.4:2379,192.168.200.5:2379 endpoint health

43、查看 etcd 高可用集群列表
ETCDCTL_API=3 etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --write-out=table --endpoints=192.168.200.3:2379,192.168.200.4:2379,192.168.200.5:2379 member list

44、查看 etcd 高可用集群 leader
ETCDCTL_API=3 etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --write-out=table --endpoints=192.168.200.3:2379,192.168.200.4:2379,192.168.200.5:2379 endpoint status

45、部署 k8s 的 dashboard
1.1、下载 recommended.yaml 文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
1.2、修改recommended.yaml文件
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #增加
ports:
- port: 443
targetPort: 8443
nodePort: 30000 #增加
selector:
k8s-app: kubernetes-dashboard
1.3、创建证书
mkdir dashboard-certs && cd dashboard-certs/
创建命名空间
kubectl create namespace kubernetes-dashboard
创建key文件
openssl genrsa -out dashboard.key 2048
证书请求
openssl req -days 36000 -new -out dashboard.csr -key dashboard.key -subj '/CN=dashboard-cert'
自签证书
openssl x509 -req -in dashboard.csr -signkey dashboard.key -out dashboard.crt
创建 kubernetes-dashboard-certs 对象
kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.key --from-file=dashboard.crt -n kubernetes-dashboard
1.4、安装 dashboard (如果报错:Error from server (AlreadyExists): error when creating "./recommended.yaml": namespaces "kubernetes-dashboard" already exists这个忽略不计,不影响。)
kubectl apply -f recommended.yaml
1.5、查看安装结果
kubectl get pods -A -o wide
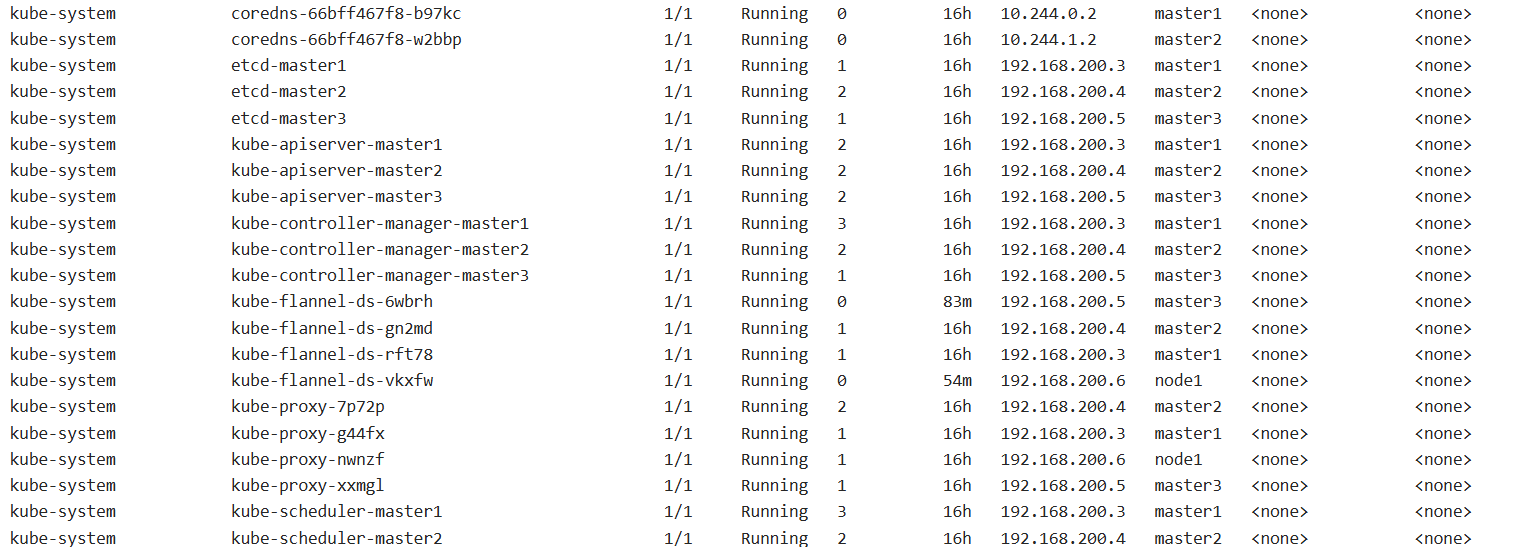
kubectl get service -n kubernetes-dashboard -o wide

1.6、创建 dashboard 管理员
cat dashboard-admin.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: dashboard-admin
namespace: kubernetes-dashboard
1.7、部署 dashboard-admin.yaml 文件
kubectl apply -f dashboard-admin.yaml
1.8、为用户分配权限
cat dashboard-admin-bind-cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin-bind-cluster-role
labels:
k8s-app: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard
1.9、部署 dashboard-admin-bind-cluster-role.yaml
kubectl apply -f dashboard-admin-bind-cluster-role.yaml
2.0、查看并复制用户 Token
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep dashboard-admin | awk '{print $1}')
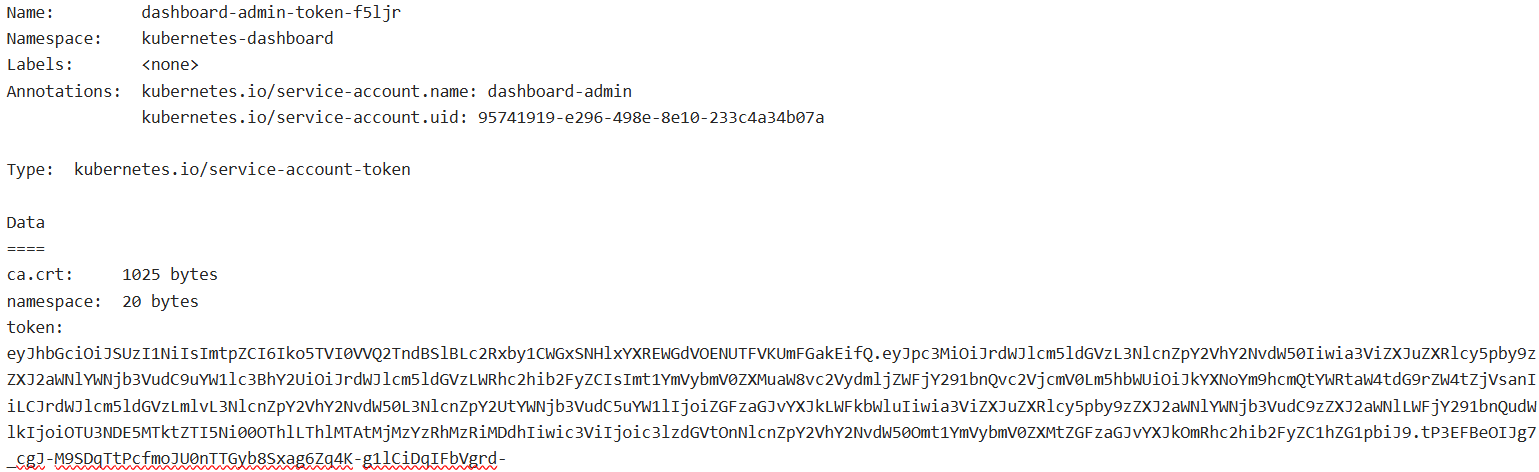
2.1、复制 token 并访问 dashboard
ip:30000
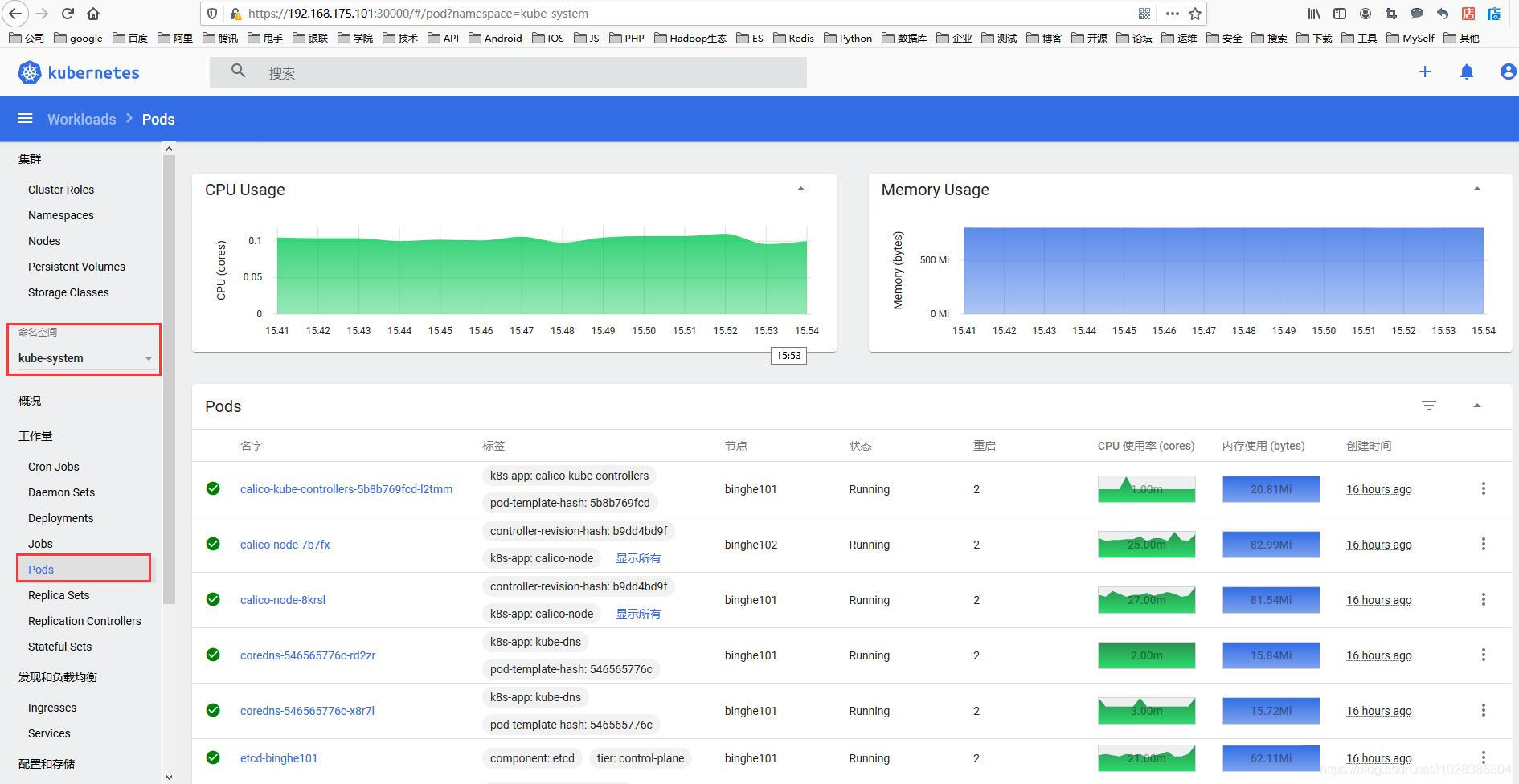
4、上图中的cpu和内存使用情况必须部署 Metrics-Server 才能出现,部署链接:https://www.cnblogs.com/lfl17718347843/p/14283796.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App