
该篇幅主要记录linux的操作,常见就不记录了,主要记录一些不太常用、难用或者自己忘记了的点。
看到https://www.cnblogs.com/resn/p/5800922.html这篇幅讲解的不错,我这里借鉴部分内容,详细的可以查看那篇博客。
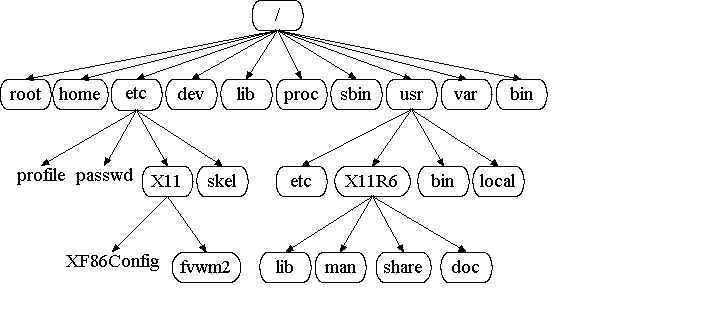
LInux目录结构:
/ : 所有目录都在
/boot : boot 配置文件、内核和其它启动 时所需的文件
/etc : 存放系统配置有关的文件
/home : 存放普通用户目录
/mnt : 硬盘上手动 挂载的文件系统
/media : 自动挂载(加载)的硬盘分区以及类似CD、数码相机等可移动介质。
/cdrom : 挂载光盘?
/opt : 存放一些可选程序,如某个程序测试版本,安装到该目录的程序的所有数据,库文件都存在同个目录下
/root : 系统管理员的目录,对于系统来说,系统管理员好比上帝,他可以对系统做任何操作,比如删除你的文件,一般情况下不要使用root用户。
/bin : 存放常用的程序文件(命令文件)。
/sbin : 系统管理命令,这里存放的是系统管理员使用的管理程序
/tmp : 临时目录,存放临时文件,系统会定期清理该目录下的文件。
/usr : 在这个目录下,你可以找到那些不适合放在/bin或/etc目录下的额外的工具。比如游戏、打印工具等。/usr目录包含了许多子目录: /usr/bin目录用于存放程序;/usr/share用于存放一些共享的数据,比如音乐文件或者图标等等;/usr/lib目录用于存放那些不能直接 运行的,但却是许多程序运行所必需的一些函数库文件。/usr/local : 这个目录一般是用来存放用户自编译安装软件的存放目录;一般是通过源码包安装的软件,如果没有特别指定安装目录的话,一般是安装在这个目录中。
/usr/bin/ 非必要可执行文件 (在单用户模式中不需要);面向所有用户。
/usr/include/ 标准包含文件。
/usr/lib/ /usr/bin/和/usr/sbin/中二进制文件的库。
/usr/sbin/ 非必要的系统二进制文件,例如:大量网络服务的守护进程。
/usr/share/ 体系结构无关(共享)数据。
/usr/src/ 源代码,例如:内核源代码及其头文件。
/usr/X11R6/ X Window系统 版本 11, Release 6.
/usr/local/ 本地数据的第三层次, 具体到本台主机。通常而言有进一步的子目录, 例如:bin/、lib/、share/.
/var : 该目录存放那些经常被修改的文件,包括各种日志、数据文件;
/var/cache/ 应用程序缓存数据。这些数据是在本地生成的一个耗时的I/O或计算结果。应用程序必须能够再生或恢复数据。缓存的文件可以被删除而不导致数据丢失。
/var/lib/ 状态信息。 由程序在运行时维护的持久性数据。 例如:数据库、包装的系统元数据等。
/var/lock/ 锁文件,一类跟踪当前使用中资源的文件。
/var/log/ 日志文件,包含大量日志文件。
/var/mail/ 用户的电子邮箱。
/var/run/ 自最后一次启动以来运行中的系统的信息,例如:当前登录的用户和运行中的守护进程。现已经被/run代替[13]。
/var/spool/ 等待处理的任务的脱机文件,例如:打印队列和未读的邮件。
/var/spool/mail/ 用户的邮箱(不鼓励的存储位置)
/var/tmp/ 在系统重启过程中可以保留的临时文件。
/lib : 目录是根文件系统上的程序所需的共享库,存放了根文件系统程序运行所需的共享文件。这些文件包含了可被许多程序共享的代码,以避免每个程序都包含有相同的子程序的副本,故可以使得可执行文件变得更小,节省空间。
/lib32 : 同上
/lib64 : 同上
/lost+found : 该目录在大多数情况下都是空的。但当突然停电、或者非正常关机后,有些文件就临时存放在;
/dev : 存放设备文件
/run : 代替/var/run目录,
/proc : 虚拟文件系统,可以在该目录下获取系统信息,这些信息是在内存中由系统自己产生的,该目录的内容不在硬盘上而在内存里;
/sys : 和proc一样,虚拟文件系统,可以在该目录下获取系统信息,这些信息是在内存中由系统自己产生的,该目录的内容不在硬盘上而在内存里;
软件管理 apt ( Advanced Packaging Tool ) , 他可以自动下载、配置、安装软件包;简化了Linux系统上的。Debian及衍生版中都包含了apt , RedHat系列的linux的则使用yum来进行管理,其中Fedora22中Centos7中开始使用dnf 来替代yum。
apt-cache search package 搜索包 apt-cache show package 获取包的相关信息,如说明、大小、版本等 sudo apt-get install package 安装包 sudo apt-get install package –reinstall 重新安装包 sudo apt-get -f install 强制安装 sudo apt-get remove package 删除包 sudo apt-get remove package –purge 删除包,包括删除配置文件等 sudo apt-get autoremove 自动删除不需要的包 sudo apt-get update 更新源 sudo apt-get upgrade 更新已安装的包 sudo apt-get dist-upgrade 升级系统 sudo apt-get dselect-upgrade 使用 dselect 升级 apt-cache depends package 了解使用依赖 apt-cache rdepends package 了解某个具体的依赖 sudo apt-get build-dep package 安装相关的编译环境 apt-get source package 下载该包的源代码 sudo apt-get clean && sudo apt-get autoclean 清理下载文件的存档 sudo apt-get check 检查是否有损坏的依赖
linux中快捷键是很重要的,因为会很方便:
快捷键 ctrl-a : 把光标移动到命令行最开始的地方。 ctrl-e : 把光标移动到命令行末尾。 ctrl-u : 清除命令行中光标所处位置之前的所有字符。 ctrl-k : 清除从提示符所在位置到行末尾之间的字符 ctrl-w : 清除左边的字段 ctrl-y : 将会贴上被ctrl-u 或者 ctrl-k 或者 ctrl-w清除的部分。 ctrl-r : 将自动在命令历史缓存中增量搜索后面入的字符。 tab : 命令行自动补全-自动补全当前的命令行。如果启用自动补全脚本命令参数和选项也可以自动补齐。 ctrl-l : 清屏
我们如果不是很懂一个命令的用法的时候我们可以 xx --h 或者 info xx 或者 man xx
date //显示当前日期 # 日期格式化 # %Y year # %m month (01..12) # %d day of month (e.g., 01) # %H hour (00..23) # %I hour (01..12) # %M minute (00..59) # %S second (00..60) date +"%Y%m%d %H%M%S" (必须有+号,固定表达式) 223856 date +"%Y-%m-%d %H:%M:%S" 2016-08-24 22:39:07 date -s //设置当前时间,只有root权限才能设置,其他只能查看。 date -s 20061010 //设置成20061010,这样会把具体时间设置成空00:00:00 date -s 12:23:23 //设置具体时间,不会对日期做更改 date -s “12:12:23 2006-10-10″ //这样可以设置全部时间 # 注意: 重新设置时间后需要将时间同步到硬件时钟。方式如下: hwclock -w
#显示日历
cal # 现实当前月份的日历 cal -y # 显示当年的日历 cal 2016 # # 显示指定年份的日历
#设置时区
tzselect # 或者 cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
stat : 查看文件相信信息
stat filename # Access time(atime):是指取用文件的时间,所谓取用,常见的操作有:使用编辑器查看文件内容,使用cat命令显示文件内容,使用cp命令把该文件(即来源文件)复制成其他文件,或者在这个文件上运用grep sed more less tail head 等命令,凡是读取而不修改文件的操作,均衡改变文件的Access time. # Modify time(mtime):是指修改文件内容的时间,只要文件内容有改动(如使用转向输出或转向附加的方式)或存盘的操作,就会改变文件的Modify time,平常我们使用ls –l查看文件时,显示的时间就是Modify time # Change time(ctime):是指文件属性或文件位置改动的时间,如使用chmod,chown,mv指令集使用ln做文件的硬是连接,就会改变文件的Change time.
wc :统计指定文件中的字节数、字数、行数,并将统计结果显示输出
-c 统计字节数。 -l 统计行数。 -m 统计字符数。这个标志不能与 -c 标志一起使用。 -w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串
uniq : 忽略或报告重复行
uniq [-icu] 选项与参数: -i :忽略大小写字符的不同; -c :进行计数 -u :只显示唯一的行
cut命令可以从一个文本文件或者文本流中提取文本列。
选项与参数: -d :后面接分隔字符。与 -f 一起使用; -f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思; -c :以字符 (characters) 的单位取出固定字符区间;
cut -d: -f 2 xx.txt(以:分隔xx.txt的每一行,然后取第二列)
tee : 读取标准输入的数据,并将其内容输出成文件。
cat sec.log | tee file1 # 读取sec.log ,并生成file1文件 cat sec.log | tee - a file1 # 读取sec.log ,并追加, cat sec.log |tee file1 file2
user开头操作用户
# -c 备注 加上备注。并会将此备注文字加在/etc/passwd中的第5项字段中 # -d 用户主文件夹。指定用户登录所进入的目录,并赋予用户对该目录的的完全控制权 # -e 有效期限。指定帐号的有效期限。格式为YYYY-MM -DD,将存储在/etc/shadow # -f 缓冲天数。限定密码过期后多少天,将该用户帐号停用 # -g 主要组。设置用户所属的主要组 www.cit.cn # -G 次要组。设置用户所属的次要组,可设置多组 # -M 强制不创建用户主文件夹 # -m 强制建立用户主文件夹,并将/etc/skel/当中的文件复制到用户的根目录下 # -p 密码。输入该帐号的密码 # -s shell。用户登录所使用的shell # -u uid。指定帐号的标志符user id,简称uid useradd user1 # 添加用户 user1 useradd -d /home/userTT user2 userdel user1 # userdel -r user1 # -r, --remove 用户主目录中的文件将随用户主目录和用户邮箱一起删除。在其它文件系统中的文件必须手动搜索并删除。 # -f, --force 此选项强制删除用户账户,甚至用户仍然在登录状态。它也强制删除用户的主目录和邮箱,即使其它用户也使用同一个主目录或邮箱不属于指定的用户 # -c<备注> 修改用户帐号的备注文字。 # -d登入目录> 修改用户登入时的目录。 # -e<有效期限> 修改帐号的有效期限。 # -f<缓冲天数> 修改在密码过期后多少天即关闭该帐号。 # -g<群组> 修改用户所属的群组。 # -G<群组> 修改用户所属的附加群组。 # -l<帐号名称> 修改用户帐号名称。 # -L 锁定用户密码,使密码无效。 # -s<shell> 修改用户登入后所使用的shell。 # -u<uid> 修改用户ID。 # -U 解除密码锁定。 usermod -G staff user2 # 将 newuser2 添加到组 staff 中 usermod -l newuser1 newuser # 修改 newuser 的用户名为 newuser1 usermod -L newuser1 # 锁定账号 newuser1 usermod -U newuser1 # 解除对 newuser1 的锁定
alias : 给命令起别名
alias ll='ls -alF' alias la='ls -A' alias l='ls -CF'
如果需要别名永久生效,需要保存到 .bashrc 文件
我们用到的终端默认使用的shell 是bash 其他的shell 有dash 、csh 、tcsh、zsh等等
Shell本身是一个用C语言编写的程序,它是用户使用Unix/Linux的桥梁,用户的大部分工作都是通过Shell完成的。Shell既是一种命令语言,又是一种程序设计语言。作为命令语言,它交互式地解释和执行用户输入的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
自定义账户的个性化环境的三个重要文件
.bash_history .bash_logout .bashrc
刚登录Linux时,首先启动 /etc/profile 文件 , ~/.bash_profile、 ~/.bash_login、 ~/.profile。 如果 ~/.bash_profile文件存在的话,一般还会执行 ~/.bashrc文件。
关于各个文件的作用域,在网上找到了以下说明:
(1) /etc/profile: 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行. 并从/etc/profile.d目录的配置文件中搜集shell的设置。
(2) /etc/bashrc: 为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取(即每次新开一个终端,都会执行bashrc)。
(3) ~/.bash_profile: 每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次。默认情况下,设置一些环境变量,执行用户的.bashrc文件。
(4) ~/.bashrc: 该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。
(5) ~/.bash_logout: 当每次退出系统(退出bash shell)时,执行该文件. 另外,/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承 /etc/profile中的变量,他们是"父子"关系。(6) ~/.bash_profile: 也可能是 .profile 是交互式、login 方式进入 bash 运行的~/.bashrc 是交互式 non-login 方式进入 bash 运行的通常二者设置大致相同,所以通常前者会调用后者。
PATH变量的设置
env : 查看当前环境变量
export : 设置或显示环境变量,临时修改。
source : 在当前bash环境下读取并执行FileName中的命令。该filename文件可以无"执行权限"
env export name = "SN" source /etv/profile
重定向
> 重定向,如果的文件存在,则覆盖文件内容,文件不存在时创建文件
>> 重定向,如果的文件存在,则向文件追加内容,文件不存在时创建文件
1> 标准正确输出,同上
1>> 标准正确输出,同上
2> 标准错误输出,同上
2>> 标准错误输出,同上
&> 标准正确输出和标准错误输出,同上
locate # 查找文件(通过数据库查找,不查找磁盘,每晚自动更新,要是新建的文件需要被查到,需要通过命令updatedb更新数据库)
locate /etc/sh # 搜索包含/etc/sh的文件。 locate ~/a # 搜索用户主目录下,所有以a开头的文件。 locate -i ~/a # 搜索用户主目录下,所有以a开头的文件,并且忽略大小写。
find 查找(直接磁盘查找)
使用方法: find path -option [-print ] [ -exec -ok command ] {} \; ###### 根据文件名查找 ####### find / -name filename 再根目录里面搜索文件名为filename的文件 find /home -name "*.txt" find /home -iname "*.txt" # 忽略大小写 ###### 根据文件类型查找 ####### f 普通文件 l 符号连接 d 目录 c 字符设备 b 块设备 s 套接字 p Fifo ###### 根据目录深度查找 ####### find . -maxdepth 3 -type f # 最大深度为3 find . -mindepth 2 -type f # 最小深度为2 ######### 根据文件的权限或者大小名字类型进行查找 ########### find . -type f -size (+|-)文件大小 # +表示大于 -表示小于 b —— 块(512字节) c —— 字节 w —— 字(2字节) k —— 千字节 M —— 兆字节 G —— 吉字节 ######### 按照时间查找 ############ -atime(+|-)n # 此选项代表查找出n天以前被读取过的文件。 -mtime(+|-)n # 此选项代表查找出n天以前文件内容发生改变的文件。 -ctime(+|-)n # 此选项代表查找出n天以前的文件的属性发生改变的文件。 -newer file # 此选项代表查找出所有比file新的文件。 -newer file1 ! –newer file2 # 此选项代表查找比file1文件时间新但是没有file2时间新的文件。 # 注意: # n为数字,如果前面没有+或者-号,代表的是查找出n天以前的,但是只是一天之内的范围内发生变化的文件。 # 如果n前面有+号,则代表查找距离n天之前的发生变化的文件。如果是减号,则代表查找距离n天之内的所有发生变化的文件。 # -newer file1 ! –newer file2中的!是逻辑非运算符 ######### 按照用户/权限查找 ############ -user 用户名:根据文件的属主名查找文件。 -group 组名:根据文件的属组名查找文件。 -uid n:根据文件属主的UID进行查找文件。 -gid n:根据文件属组的GID进行查找文件。 -nouser:查询文件属主在/etc/passwd文件中不存在的文件。 -nogroup:查询文件属组在/etc/group文件中不存在的文件 -perm 777: 查询权限为777的文件 来自: http://man.linuxde.net/find ######## 查找时指定多个条件 ############ -o:逻辑或,两个条件只要满足一个即可。 -a:逻辑与,两个条件必须同时满足。 find /etc -size +2M -a -size -10M ######### 对查找结果进行处理 ############# -exec shell命令 {} \; -ok shell命令 {} \; 其中-exec就是代表要执行shell命令,后面加的是shell指令,再后面的“{}”表示的是要对前面查询到的结果进行查询,最后的“\;”表示命令结束。需要注意的是“{}”和“\”之间是要有空格的。而-ok选项与-exec的唯一区别就是它在执行shell命令的时候会事先进行询问,-print选项是将结果显示在标准输入上 find /home -name “*.txt” -ok ls -l {} \; find /home -name “*.txt” -ok rm {} \;
df
-T : 显示文件系统类型 -h : 以能显示的最大单位显示 df -Th
du 查看目录的大小
-s : 如果后面是目录,只显示一层 -h : 以能显示的最大单位显示 du dirname # 显示dirname下所有目录及其子目录的大小 du -sh dirname 显示dirname的大小
mount / umount 挂载和卸载设备
mount # 查询挂在设备及属性 # 挂载光盘 mount -t iso9660 /dev/cerom /mnt mount /dev/sr0 /mnt # 重新挂载设备 mount -o remount,rw /mnt # 重新挂载设备并设置rw属性 # 挂载iso文件 mount a.iso -o loop /mnt umount /mnt # 卸载设备 umount -l /mnt # 强制卸载
crontab 设置定时任务
* * * * * command to be executed - - - - - - | | | | | | | | | | | --- 预执行的命令 | | | | ----- 表示星期0~7(其中星期天可以用0或7表示) | | | ------- 表示月份1~12 | | --------- 表示日期1~31 | ----------- 表示小时1~23(0表示0点) ------------- 表示分钟1~59 每分钟用*或者 */1表示 -u user:用来设定某个用户的crontab服务; -e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。 -l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。 -r:从/var/spool/cron目录中删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。 -i:在删除用户的crontab文件时给确认提示
tar 打包、解压包
-c :建立一个压缩文件的参数指令(create 的意思); -x :解开一个压缩文件的参数指令! -t :查看 tarfile 里面的文件! 特别注意 c/x/t 同时仅能存在一个,因为不可能同时压缩与解压缩。 -z :是否同时具有 gzip 的属性?亦即是否需要用 gzip 压缩? -j :是否同时具有 bzip2 的属性?亦即是否需要用 bzip2 压缩? -v :压缩的过程中显示文件!这个常用,但不建议用在背景执行过程! -f :使用档名,请留意,在 f 之后要立即接文件名 -p :使用原文件的原来属性(属性不会依据使用者而变) -P :可以使用绝对路径来压缩! -N :比后面接的日期(yyyy/mm/dd)还要新的才会被打包进新建的文件中! # 将当前目录下所有.txt文件打包并压缩归档到文件this.tar.gz tar czvf this.tar.gz ./*.txt # 将当前目录下的this.tar.gz中的文件解压到当前目录 tar xzvf this.tar.gz ./ # 将整个 /etc 目录下的文件全部打包成为 /tmp/etc.tar tar -cvf /tmp/etc.tar /etc # 仅打包,不压缩! tar -zcvf /tmp/etc.tar.gz /etc # 打包后,以 gzip 压缩 tar -jcvf /tmp/etc.tar.bz2 /etc # 打包后,以 bzip2 压缩 # 解压文件 tar -xf a.tar.gz # tar -xf a.tar.gz -C /tmp # 指定解包路径
grep 查找
格式: grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN] [FILE...] 参数: -c --count #计算符合样式的列数 -l --file-with-matches #列出文件内容符合指定的样式的文件名称。 -v --revert-match #显示不包含匹配文本的所有行。 -i --ignore-case #忽略字符大小写的差别。 -o # 只显示匹配到的关键字 -n # 现实行号 -E 使用正则表达式 简单的正则表达式 ^ : 匹配开头 $ : 匹配结尾 [] : 范围匹配 [a-z] : 匹配有小写字母 [A-Z] : 匹配所有大写字母 [0-9] : 匹配所有数字 . : 匹配单个字符 * : 表示*前面的内容出现0次或多次 + : 表示+前面的内容出现1次或多次 ? : 表示?前面的内容出现0次或1次 cat a.txt |grep hat$ # 匹配以hat结尾的行 cat a.txt |grep ^hat # 匹配以hat开头的行 cat a.txt | grep -E "[0-9]*" # 匹配有0到多个数字的行 cat a.txt | grep -E "[0-9]+" # 匹配有至少有1个数字的行 cat a.txt | grep -E "[0-9]?" # 匹配有0到1个数字的行
sed : 流编辑器,一次处理一行内容
sed [-nefr] [动作] [文件] 选项与参数: -n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来 -e :直接在命令列模式上进行 sed 的动作编辑 -f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作 -r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法) -i :直接修改读取的文件内容,而不是输出到终端。 动作说明: [n1[,n2]] 动作: n1, n2 :不一定存在,一般代表选择进行动作的行数,比如,如果我的动作是需要在 10 到 20 行之间进行的,则10,20[动作行为] 动作: #a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行) #c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! #d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; sed "3d" file # 删除第三行 sed "1,3d" # 删除前三行 sed "1d;3d;5d" # 删除1、3、5行 sed "/^$/d" #删除空行 sed "/abc/d" #删除所有含有abc的行 sed "/abc/,/def/d" #删除abc 和 def 之间的行,包括其自身 sed "1,/def/d" #删除第一行到 def 之间的行,包括其自身 sed "/abc/,+3d " # 删除含有abc的行之后,在删除3行 sed "/abc/,~3d" #从含有abc的行开始,共删除3行 sed "1~2d" # 从第1行开始,每2行删除一行, 删除奇数行 sed "2~2d" # 从第2行开始,每2行删除一行, 删除偶数行 sed "\$d" # 删除最后一行 sed "/dd\|cc/d" #删除有dd或者cc的行 #i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); #p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行 sed -n "3p" file # 显示第三行 sed -n "1,3p" # 显示前三行 sed -n "2,+3p" # 显示第二行,及后面的三行 sed -n "\$p" # 显示最后一行 sed -n "1p;3p;5p" # 只显示文件1、3、5行 sed -n "$=" # 显示文件行数 #s :替换,可以直接进行取代的工作。通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 's/old/new/g' sed "s/\(all\)/bb/" sed -r "s/(all)/bb/"
awk : 一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
# 命令行调用方式 awk [-F field-separator] 'commands' input-file(s) # commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 # awk工作流程: # 读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。 cat /etc/passwd |awk -F ':' '{print $1}' cat /etc/passwd |awk -F ':' '{print $1"\t"$7}' awk 常用内置变量 ARGC 命令行参数个数 ARGV 命令行参数排列, ARGV[0] ARGV[1] ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 # 统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容: #awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd # 使用printf替代print,可以让代码更加简洁,易读 awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
#将1、2列原来是冒号分割变成下划线_分割
awk 'BEGIN{FS=":";OFS="_";} {print $1,$2;}' /etc/passwd
vi/vim : 强大的编辑器


 浙公网安备 33010602011771号
浙公网安备 33010602011771号