
有点时间没更新博客了,今天就开始学习类了,今天主要是面向对象(类),我们知道面向对象的三大特性,那就是封装,继承和多态。内容参考该博客https://www.cnblogs.com/wupeiqi/p/4493506.html
之前我们写的都是函数,可以说是面向过程的编程,需要啥功能就直接写啥,但是我们在编写程序的过程中会发现如果多个函数有共同的参数或数据时,我们也必须多次重复去写,此时如果用面向对象的编程方式就会好很多,这也是面向对象的适用场景。
面向对象三大特性:
一、封装(顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容,具体看下面的代码)
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: Xiaobai Lei class Person: def __init__(self, name, age): self.name = name self.age = age def get_msg(self): print(self.name) print(self.age) p1 = Person('xiaobai', 18) p1.get_msg() # Python默认会将p1传给self参数,即:p1.get_msg(p1),所以,此时方法内部的 self = p1 p2 = Person('xiaoming', 88) p2.get_msg() # 此处一样将p2传给self参数 # 对于面向对象的封装来说,其实就是使用构造方法将内容封装到对象中,然后通过对象直接或者self间接获取被封装的内容。
二、继承(通俗来说就是继承父类的所有东西,与现实一致)
# 2、继承 """ 1.经典类的写法: 父类名称.__init__(self,参数1,参数2,...) 2. 新式类的写法:super(子类,self).__init__(参数1,参数2,....) """ class Person: def __init__(self, name, age): self.name = name self.age = age def eat(self): print("%s在吃饭" %self.name) # 在类后面括号中写入另外一个类名,表示当前类继承另外一个类 class Teacher(Person): def __init__(self, name, age): super(Teacher, self).__init__(name, age) def teacher(self): print("%s岁的%s在教书" %(self.age, self.name)) t1 = Teacher("小白", 18) t1.eat() t1.teacher() # 对于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
除了上面的单继承以外还有多继承,ython的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先,详情往下看:

- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。


经典类多继承如下:
class D: def bar(self): print('D.bar') class C(D): def bar(self): print('C.bar') class B(D): def bar(self): print('B.bar') class A(B, C): def bar(self): print('A.bar') a = A() # 执行bar方法时 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错 # 所以,查找顺序:A --> B --> D --> C # 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 a.bar() # 对于同一个根需要注意 class D: def bar1(self): print('D.bar') class C(D): def bar1(self): print('C.bar') class B(D): def bar(self): print('B.bar') class A(B, C): def bar(self): print('A.bar') a = A() # 执行bar1方法时 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中没有,按理说应该去D类中找了,但是D类是B和C的同一个根类,所以先不找,先找C,C找不到才会最后找D这个共同的根类 # 所以,查找顺序:A --> B --> C --> D # 在上述查找bar1方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 a.bar1()
新式类多继承如下:
class D(object): def bar(self): print('D.bar') class C(D): def bar(self): print('C.bar') class B(D): def bar(self): print('B.bar') class A(B, C): def bar(self): print('A.bar') a = A() # 执行bar方法时 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错 # 所以,查找顺序:A --> B --> C --> D # 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 a.bar()
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
三、多态(Pyhon不支持Java和C#这一类强类型语言中多态的写法,但是原生多态,其Python崇尚“鸭子类型”。)
# Python的鸭子类型 class Duck(object): #Duck类型 def walk(self): print('i am a duck,and i can walk') def swim(self): print('i am a duck,and i can swim') class Cat(object): #Cat类型 def walk(self): print('i am a cat,and i can walk') def swim(self): print('i am a cat,and i can swim') # 实现一个动物walk和swim的功能函数 def walk_swim(animal): animal.walk() animal.swim() d = Duck() c = Cat() walk_swim(d) walk_swim(c)
以上就是本节对于面向对象初级知识的介绍,总结如下:
- 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用
- 类 是一个模板,模板中包装了多个“函数”供使用
- 对象,根据模板创建的实例(即:对象),实例用于调用被包装在类中的函数
- 面向对象三大特性:封装、继承和多态
Python 类的成员、成员修饰符及类的特殊成员
类的成员可以分为三大类:字段、方法和属性
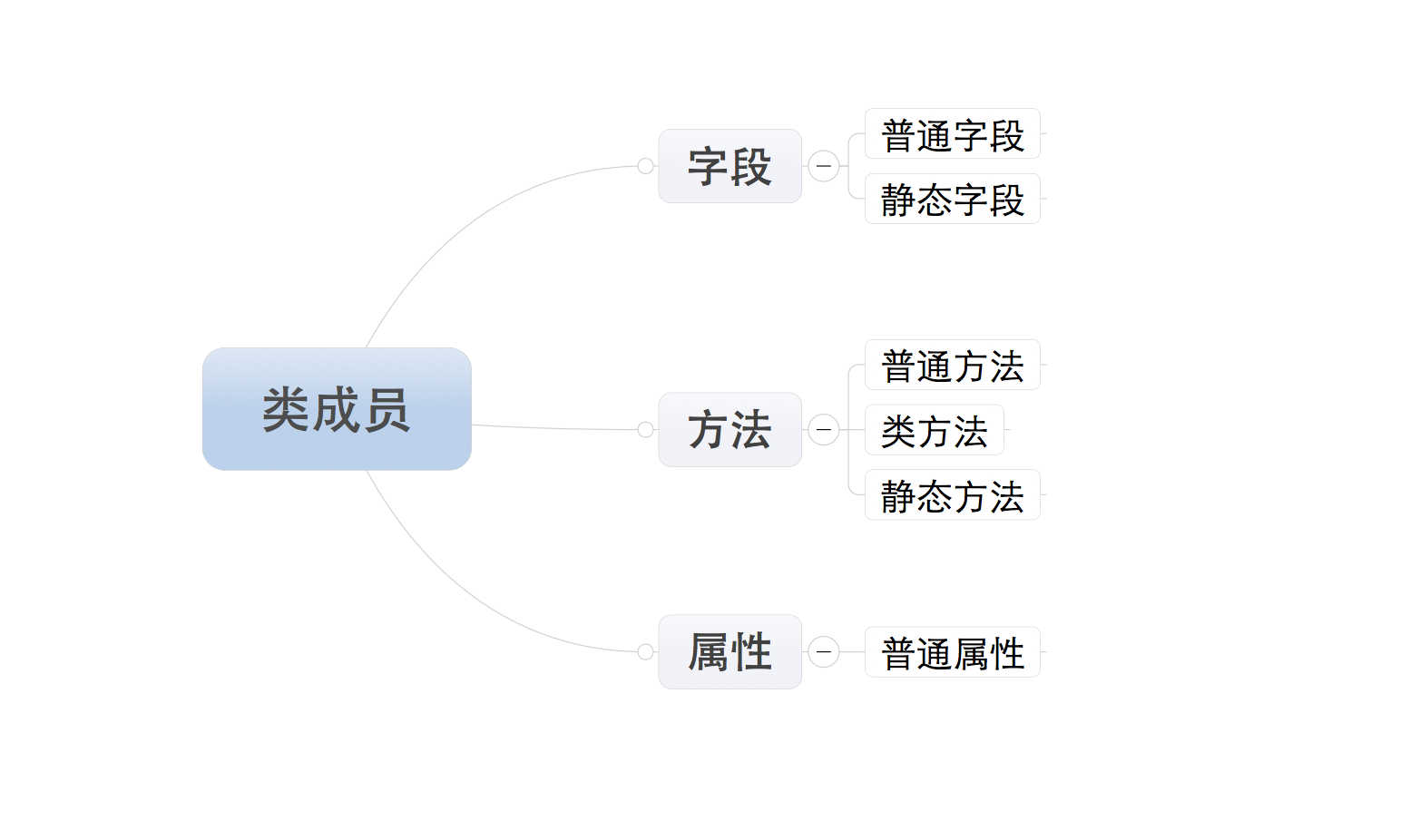
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
一、字段
字段包括:普通字段和静态字段,他们在定义和使用中有所区别,而最本质的区别是内存中保存的位置不同,
- 普通字段属于对象
- 静态字段属于类
# 字段的定义和使用 class Province: # 静态字段 country = '中国' def __init__(self, name): # 普通字段 self.name = name # 直接访问普通字段 obj = Province('河北省') print obj.name # 直接访问静态字段 Province.country
应用场景: 通过类创建对象时,如果每个对象都具有相同的字段,那么就使用静态字段
二、方法
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
- 静态方法:由类调用;无默认参数;
class Foo: def __init__(self, name): self.name = name def ord_func(self): """ 定义普通方法,至少有一个self参数 """ # print self.name print('普通方法') @classmethod def class_func(cls): """ 定义类方法,至少有一个cls参数 """ print('类方法') @staticmethod def static_func(): """ 定义静态方法 ,无默认参数""" print('静态方法') # 调用普通方法 f = Foo('xiaobai') f.ord_func() # 调用类方法 Foo.class_func() f.class_func() # 实例也能调用类方法 # 调用静态方法 Foo.static_func() f.static_func() # 实例也能调用静态方法
三、属性
如果你已经了解Python类中的方法,那么属性就非常简单了,因为Python中的属性其实是普通方法的变种。
对于属性,有以下几个知识点:
- 属性的基本使用
- 属性的两种定义方式
# ############### 定义 ############### class Foo: def func(self): pass # 定义属性 @property def prop(self): pass # ############### 调用 ############### foo_obj = Foo() foo_obj.func() foo_obj.prop #调用属性
由属性的定义和调用要注意一下几点:
- 定义时,在普通方法的基础上添加 @property 装饰器;
- 定义时,属性仅有一个self参数
- 调用时,无需括号
方法:foo_obj.func()
属性:foo_obj.prop
注意:属性存在意义是:访问属性时可以制造出和访问字段完全相同的假象
属性由方法变种而来,如果Python中没有属性,方法完全可以代替其功能。
实例:对于主机列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据(即:limit m,n),这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
# ############### 定义 ############### class Pager: def __init__(self, current_page): # 用户当前请求的页码(第一页、第二页...) self.current_page = current_page # 每页默认显示10条数据 self.per_items = 10 @property def start(self): val = (self.current_page - 1) * self.per_items + 1 return val @property def end(self): val = self.current_page * self.per_items return val # ############### 调用 ############### p = Pager(1) p.start 就是起始值,即:m p.end 就是结束值,即:n
从上述可见,Python的属性的功能是:属性内部进行一系列的逻辑计算,最终将计算结果返回。
2、属性的两种定义方式
属性的定义有两种方式:
- 装饰器 即:在方法上应用装饰器
- 静态字段 即:在类中定义值为property对象的静态字段
装饰器方式:在类的普通方法上应用@property装饰器
类中具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Goods(object): def __init__(self): # 原价 self.original_price = 100 # 折扣 self.discount = 0.8 @property def price(self): # 实际价格 = 原价 * 折扣 new_price = self.original_price * self.discount return new_price @price.setter def price(self, value): self.original_price = value @price.deltter def price(self, value): del self.original_price obj = Goods() obj.price # 获取商品价格 obj.price = 200 # 修改商品原价 del obj.price # 删除商品原价
静态字段方式,创建值为property对象的静态字段
class Foo: def get_bar(self): return 'haha' BAR = property(get_bar) obj = Foo() reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值 print reuslt
property的构造方法中有个四个参数
- 第一个参数是方法名,调用
对象.属性时自动触发执行方法 - 第二个参数是方法名,调用
对象.属性 = XXX时自动触发执行方法 - 第三个参数是方法名,调用
del 对象.属性时自动触发执行方法 - 第四个参数是字符串,调用
对象.属性.__doc__,此参数是该属性的描述信息
由于静态字段方式创建属性具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Goods(object): def __init__(self): self.price = 10 def get_price(self): "sss" print(self.price) def set_price(self, val): self.price = val def del_price(self): del self.price PRICE = property(get_price, set_price, del_price, doc='test') obj = Goods() obj.PRICE obj.PRICE = 20 obj.PRICE.__doc__ del obj.PRICE
注意:Python WEB框架 Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性
class WSGIRequest(http.HttpRequest): def __init__(self, environ): script_name = get_script_name(environ) path_info = get_path_info(environ) if not path_info: # Sometimes PATH_INFO exists, but is empty (e.g. accessing # the SCRIPT_NAME URL without a trailing slash). We really need to # operate as if they'd requested '/'. Not amazingly nice to force # the path like this, but should be harmless. path_info = '/' self.environ = environ self.path_info = path_info self.path = '%s/%s' % (script_name.rstrip('/'), path_info.lstrip('/')) self.META = environ self.META['PATH_INFO'] = path_info self.META['SCRIPT_NAME'] = script_name self.method = environ['REQUEST_METHOD'].upper() _, content_params = cgi.parse_header(environ.get('CONTENT_TYPE', '')) if 'charset' in content_params: try: codecs.lookup(content_params['charset']) except LookupError: pass else: self.encoding = content_params['charset'] self._post_parse_error = False try: content_length = int(environ.get('CONTENT_LENGTH')) except (ValueError, TypeError): content_length = 0 self._stream = LimitedStream(self.environ['wsgi.input'], content_length) self._read_started = False self.resolver_match = None def _get_scheme(self): return self.environ.get('wsgi.url_scheme') def _get_request(self): warnings.warn('`request.REQUEST` is deprecated, use `request.GET` or ' '`request.POST` instead.', RemovedInDjango19Warning, 2) if not hasattr(self, '_request'): self._request = datastructures.MergeDict(self.POST, self.GET) return self._request @cached_property def GET(self): # The WSGI spec says 'QUERY_STRING' may be absent. raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '') return http.QueryDict(raw_query_string, encoding=self._encoding) # ############### 看这里看这里 ############### def _get_post(self): if not hasattr(self, '_post'): self._load_post_and_files() return self._post # ############### 看这里看这里 ############### def _set_post(self, post): self._post = post @cached_property def COOKIES(self): raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '') return http.parse_cookie(raw_cookie) def _get_files(self): if not hasattr(self, '_files'): self._load_post_and_files() return self._files # ############### 看这里看这里 ############### POST = property(_get_post, _set_post) FILES = property(_get_files) REQUEST = property(_get_request)
所以,定义属性共有两种方式,分别是【装饰器】和【静态字段】。
上面说的是类的成员,接着来学习下类成员的修饰符。
类的所有成员在上一步骤中已经做了详细的介绍,对于每一个类的成员而言都有两种形式:
- 公有成员,在任何地方都能访问
- 私有成员,只有在类的内部才能方法
私有成员和公有成员的定义不同:私有成员命名时,前两个字符是下划线。(特殊成员除外,例如:__init__、__call__、__dict__等)
# -*- coding:utf-8 -*- # @__author__ : Loris # @Time : 2018/12/22 11:55 # 公有和私有类字段(普通字段和静态字段)的访问权限 """ 公有字段:类可以访问;类内部可以访问;派生类中可以访问 私有字段:仅类内部可以访问 """ class A: name = "公有静态字段" __age = "私有静态字段" def __init__(self): self.__addr = "私有普通字段" self.num = "公有普通字段" def show(self): print(A.name, A.__age, self.__addr, self.num) class B(A): def show(self): print(A.name, self.num) print(A.name) # 类访问 test1 = A() test2 = B() test1.show() # 类内部访问所有公有和私有字段 test2.show() # 派生类中只可以访问公有字段,访问私有报错 # 如果想要强制访问私有字段,可以通过 【对象._类名__私有字段明 】访问(如:test2._A__age),不建议强制访问私有成员。 print(test2._A__age) # 强制访问私有字段,不建议
上文介绍了Python的类成员以及成员修饰符,从而了解到类中有字段、方法和属性三大类成员,并且成员名前如果有两个下划线,则表示该成员是私有成员,私有成员只能由类内部调用。无论人或事物往往都有不按套路出牌的情况,Python的类成员也是如此,存在着一些具有特殊含义的成员,详情如下:
# -*- coding:utf-8 -*- # @__author__ : Loris # @Time : 2018/12/23 15:36 class Person: """这是一个人的类""" # 类的描述信息 def __init__(self, name): # 构造方法,通过类创建对象时,自动触发执行。 self.name = name def __str__(self): return "__str__方法" # 在打印 对象 时,默认输出该方法的返回值 def __call__(self, *args, **kwargs): # 对象后面加括号,触发执行。 print("__call__方法") def func(self): pass def __del__(self): # 析构方法,当对象在内存中被释放时,自动触发执行,此方法一般无须定义 print("__del__") p1 = Person('liu') # 1、自动执行类中的 __init__ 方法 print(p1) # 2、默认输出__str__方法的返回值 p1() # 3、执行 __call__方法 print(p1.__doc__) # 4、输出:类的描述信息 print(p1.__module__) # 5、__module__表示当前操作的对象在那个模块,即:输出模块__main__ print(p1.__class__) # 6、__class__表示当前操作的对象的类是什么,即:输出类 print(p1.__dict__) # 7、__dict__类或对象中的所有成员,这里打印的是对象的所有成员,即{'name': 'liu'} print(Person.__dict__) # 8、__dict__类或对象中的所有成员,这里打印的是类的所有成员,如下: # {'__module__': '__main__', '__doc__': '这是一个人的类', '__init__': <function Person.__init__ at 0x0000000002986620>, '__call__': <function Person.__call__ at 0x00000000029866A8>, 'func': <function Person.func at 0x0000000002986730>, '__del__': <function Person.__del__ at 0x00000000029867B8>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>} # 上文中我们知道:类的普通字段属于对象;类中的静态字段和方法等属于类,所以我们可以看到类打印出来的较多
上面说了七个,分别是__init__、__str__、__call__、__doc__、__module__、__class__、__dict__,接下来再说剩下的常用的几个;
# -*- coding:utf-8 -*- # @__author__ : Loris # @Time : 2018/12/23 17:36 # 8、__getitem__、__setitem__、__delitem__用于索引操作,如字典和列表。以上分别表示获取、设置、删除数据 # 9、__setslice__、__delslice__该两个个方法用于分片操作,如:列表,注意,在py3中__getslice__已经融入__getitem__里面去了 class Person: def __getitem__(self, item): if isinstance(item, slice): # 如果传入为slice则执行切片的操作 print("slice",item) else: print("__getitem__",item) def __setitem__(self, key, value): print("__setitem__",key,value) def __delitem__(self, key): print("__delitem__",key) def __setslice__(self, i, j, sequence): print("__setslice__",i,j) def __delslice__(self, i, j): print("__delslice__",i,j) p1 = Person() p1[3:4] # 自动触发执行 __getitem__中的slice逻辑 p1['name'] # 自动触发执行 __getitem__中的索引获取逻辑 p1['name'] = "xiaobai" # 自动触发执行 __setitem__ del p1['name'] # 自动触发执行 __delitem__ p1[0:2] = [11,22,33] # 自动触发执行 __setslice__ del p1[0:2] # 自动触发执行 __delslice__
# 10. __iter__ 用于迭代器,之所以列表、字典、元组可以进行for循环,是因为类型内部定义了 __iter__ class Person: def __init__(self, name): self.name = name def __iter__(self): # 如果没写就执行for,会报错:TypeError: 'Person' object is not iterable return iter(self.name) p1 = Person([1,2,3,4]) for i in p1: # for循环迭代的其实是 iter([1,2,3,4]) print(i)
我们知道在python中一切皆是对象,我们上面每次都是类然后实例化,那么我们想一下,类是不是也是一个对象呢?那他是谁的实例呢?
# 11. __new__ 和 __metaclass__ class Person: def __init__(self): pass p1 = Person() print(type(p1)) # <class '__main__.Person'>,表示p1 对象由Person类创建 print(type(Person)) # <class 'type'>,表示Person 对象由type类创建 # 所以,p1对象是Person类的一个实例,Person类对象是 type 类的一个实例,即:Person类对象 是通过type类的构造方法创建
那么,创建类就可以有两种方式:
# 第一种方法 class Person: def func(self): print("test") # 第二种方法,特殊方式(type类的构造函数) def func(self): print("test") Person = type('Person',(object,), {'func': func}) # type第一个参数:类名 # type第二个参数:当前类的基类 # type第三个参数:类的成员
类 是由 type 类实例化产生,那么问题来了,类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性 metaclass(py2中是__metaclass__),其用来表示该类由 谁 来实例化创建,所以,我们可以为metaclass 设置一个type类的派生类,从而查看 类 创建的过程。
class MyType(type): def __init__(self, what, bases=None, dict=None): print("MyType.__init__") super(MyType, self).__init__(what, bases, dict) # 继承type的构造方法,写法也是模仿type的 def __call__(self, *args, **kwargs): print("MyType.__call__") # return super().__call__(*args, **kwargs) # #self是Meta_Type的实例,也就是Person # 调用Person的__new__方法,因为每个类都默认继承object,所以可以调用__new__(Person)方法来实例化一个对象obj1 == object.__new__(Person) ==> obj1 obj = self.__new__(self, *args, **kwargs) # 调用Person的构造函数实例化对象 == Person.__init__(obj1,*args,**kwargs) self.__init__(obj, *args, **kwargs) # 最后返回obj对象 return obj # 会触发MyType的 __init__ class Person(metaclass=MyType): # 表示Person类由MyTpye来实例化 def __init__(self, name): print("Person.__init__") self.name = name def __new__(cls, *args, **kwargs): return object.__new__(cls) # Person()时,表示执行了Person,则会调用元类的__call__,__call__中会生成对象obj1,并且调用Person下的__init__方法,最终完成实例化 obj1 = Person("liu") print(obj1.name) # 第一阶段:解释器从上到下执行代码创建Person类 # 第二阶段:通过Person类创建obj对象 """ 结果如下: MyType.__init__ MyType.__call__ Person.__init__ liu """

 浙公网安备 33010602011771号
浙公网安备 33010602011771号