
一.所花时间
3h
二.代码量
200行
三.博客量
1篇
四.了解到的知识点
题目描述】以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:
(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;
(2)结合matplotlib库,对2015-2019年间前10位大学的排名信息进行可视化展示。
(3附加)编写一个查询程序,根据从键盘输入的大学名称和年份,输出该大学相应的排名信息。如果所爬取的数据中不包含该大学或该年份信息,则输出相应的提示信息,并让用户选择重新输入还是结束查询;
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from matplotlib import pyplot as plt
from pyecharts.charts import Line
from pyecharts.charts import Bar
from pyecharts.charts import PictorialBar
from pyecharts.charts import Map
from pyecharts.charts import Pie
from pyecharts.charts import Grid
from pyecharts import options as opts
def get_rank(url):
count = 0
rank = []
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.3"
}
resp = requests.get(url, headers=headers).content.decode()
soup = bs(resp, "lxml")
univname = soup.find_all('a', class_="name-cn")
for i in univname:
if count != 10:
university = i.text.replace(" ", "")
score = soup.select("#content-box > div.rk-table-box > table > tbody > tr:nth-child({}) > td:nth-child(5)"
.format(count + 1))[0].text.strip()
rank.append([university, score])
else:
break
count += 1
return rank
total = []
u_year = 2015
for i in range(15, 20):
url = "https://www.shanghairanking.cn/rankings/bcur/20{}11".format(i)
print(url)
title = ['学校名称', '总分']
df = pd.DataFrame(get_rank(url), columns=title)
total.append(df)
for i in total:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
x = list(i["学校名称"])[::-1]
y = list(i["总分"])[::-1]
# 1.创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2.绘制图像
y = [float(value) for value in y]
plt.ylim(min(y)-10, max(y)+10)
plt.bar(x, y, label="大学排名")
#plt.plot(x, y, label="大学排名")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.5)
# 2.3 添加描述信息
plt.xlabel("大学名称")
plt.ylabel("总分")
plt.title(str(u_year) + "年软科中国最好大学排名Top10", fontsize=20)
# 2.5 添加图例
plt.legend(loc="best")
# 3.图像显示
plt.show()
u_year += 1
while True:
info = input("请输入要查询的大学名称和年份:")
count = 0
university, year = info.split()
year = int(year)
judge = 2019 - year
tmp = total[::-1]
if 4 >= judge >= 0:
name = list(total[judge - 1]["学校名称"])
for j in name:
if university == j.strip():
print(university + "在{0}年排名第{1}".format(year, count + 1))
break
count += 1
if count ==10:
print("很抱歉,没有该学校的排名记录!!!")
print("请选择以下选项:")
print(" 1.继续查询")
print(" 2.结束查询")
select = int(input(""))
if select == 1:
continue
elif select == 2:
break
else:
break
else:
print("很抱歉,没有该年份的排名记录!!!")
print("请选择以下选项:")
print(" 1.继续查询")
print(" 2.结束查询")
select = int(input(""))
if select == 1:
continue
elif select == 2:
break
题目描述】豆瓣图书评论数据爬取。以《平凡的世界》、《都挺好》等为分析对象,编写程序爬取豆瓣读书上针对该图书的短评信息,要求:
(1)对前3页短评信息进行跨页连续爬取;
(2)爬取的数据包含用户名、短评内容、评论时间、评分和点赞数(有用数);
(3)能够根据选择的排序方式(热门或最新)进行爬取,并分别针对热门和最新排序,输出前10位短评信息(包括用户名、短评内容、评论时间、评分和点赞数)。
(4)根据点赞数的多少,按照从多到少的顺序将排名前10位的短评信息输出;
(5附加)结合中文分词和词云生成,对前3页的短评内容进行文本分析:按照词语出现的次数从高到低排序,输出前10位排序结果;并生成一个属于自己的词云图形。
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import re
from collections import Counter
import requests
from lxml import etree
import pandas as pd
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39"
}
comments = []
words = []
def regex_change(line):
# 前缀的正则
username_regex = re.compile(r"^\d+::")
# URL,为了防止对中文的过滤,所以使用[a-zA-Z0-9]而不是\w
url_regex = re.compile(r"""
(https?://)?
([a-zA-Z0-9]+)
(\.[a-zA-Z0-9]+)
(\.[a-zA-Z0-9]+)*
(/[a-zA-Z0-9]+)*
""", re.VERBOSE | re.IGNORECASE)
# 剔除日期
data_regex = re.compile(u""" #utf-8编码
年 |
月 |
日 |
(周一) |
(周二) |
(周三) |
(周四) |
(周五) |
(周六)
""", re.VERBOSE)
# 剔除所有数字
decimal_regex = re.compile(r"[^a-zA-Z]\d+")
# 剔除空格
space_regex = re.compile(r"\s+")
regEx = "[\n”“|,,;;''/?! 。的了是]" # 去除字符串中的换行符、中文冒号、|,需要去除什么字符就在里面写什么字符
line = re.sub(regEx, "", line)
line = username_regex.sub(r"", line)
line = url_regex.sub(r"", line)
line = data_regex.sub(r"", line)
line = decimal_regex.sub(r"", line)
line = space_regex.sub(r"", line)
return line
def getComments(url):
score = 0
resp = requests.get(url, headers=headers).text
html = etree.HTML(resp)
comment_list = html.xpath(".//div[@class='comment']")
for comment in comment_list:
status = ""
name = comment.xpath(".//span[@class='comment-info']/a/text()")[0] # 用户名
content = comment.xpath(".//p[@class='comment-content']/span[@class='short']/text()")[0] # 短评内容
content = str(content).strip()
word = jieba.cut(content, cut_all=False, HMM=False)
time = comment.xpath(".//span[@class='comment-info']/a/text()")[1] # 评论时间
mark = comment.xpath(".//span[@class='comment-info']/span/@title") # 评分
if len(mark) == 0:
score = 0
else:
for i in mark:
status = str(i)
if status == "力荐":
score = 5
elif status == "推荐":
score = 4
elif status == "还行":
score = 3
elif status == "较差":
score = 2
elif status == "很差":
score = 1
good = comment.xpath(".//span[@class='comment-vote']/span[@class='vote-count']/text()")[0] # 点赞数(有用数)
comments.append([str(name), content, str(time), score, int(good)])
for i in word:
if len(regex_change(i)) >= 2:
words.append(regex_change(i))
def getWordCloud(words):
# 生成词云
all_words = []
all_words += [word for word in words]
dict_words = dict(Counter(all_words))
bow_words = sorted(dict_words.items(), key=lambda d: d[1], reverse=True)
print("热词前10位:")
for i in range(10):
print(bow_words[i])
text = ' '.join(words)
w = WordCloud(background_color='white',
width=1000,
height=700,
font_path='simhei.ttf',
margin=10).generate(text)
plt.show()
plt.imshow(w)
w.to_file('wordcloud.png')
print("请选择以下选项:")
print(" 1.热门评论")
print(" 2.最新评论")
info = int(input())
title = ['用户名', '短评内容', '评论时间', '评分', '点赞数']
if info == 1:
comments = []
words = []
for i in range(0, 60, 20):
url = "https://book.douban.com/subject/20492971/comments/?start={}&limit=20&status=P&sort=new_score".format(
i) # 前3页短评信息(热门)
getComments(url)
df = pd.DataFrame(comments, columns=title)
print("前10位短评信息:")
print(df.head(10))
print("点赞数前10位的短评信息:")
df = df.sort_values(by='点赞数', ascending=False)
print(df.head(10))
getWordCloud(words)
elif info == 2:
comments = []
words=[]
for i in range(0, 60, 20):
url = "https://book.douban.com/subject/20492971/comments/?start={}&limit=20&status=P&sort=time".format(
i) # 前3页短评信息(最新)
getComments(url)
df = pd.DataFrame(comments, columns=title)
print("前10位短评信息:")
print(df.head(10))
print("点赞数前10位的短评信息:")
df = df.sort_values(by='点赞数', ascending=False)
print(df.head(10))
getWordCloud(words)
题目描述】设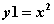
,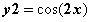
,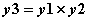
,其中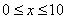
,完成下列操作:
(1)在同一坐标系下用不同的颜色和线型绘制y1、y2和y3三条曲线;
(2)在同一绘图框内以子图形式绘制y1、y2和y3三条曲线。
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0, 10, 0.0001)
y1 = x ** 2
y2 = np.cos(x * 2)
y3 = y1 * y2
plt.plot(x, y1,linestyle='-.')
plt.plot(x, y2,linestyle=':')
plt.plot(x, y3,linestyle='--')
plt.savefig("3-1.png")
plt.show()
fig, subs = plt.subplots(2, 2)
subs[0][0].plot(x, y1)
subs[0][1].plot(x, y2)
subs[1][0].plot(x, y3)
plt.savefig("3-2.png")
plt.show()
【题目描述】已知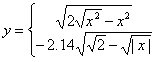
,在区间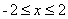
绘制该分段函数的曲线,以及由该曲线所包围的填充图形。
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-2, 2, 0.0001)
y1 = np.sqrt(2 * np.sqrt(x ** 2) - x ** 2)
y2 = (-2.14) * np.sqrt(np.sqrt(2) - np.sqrt(np.abs(x)))
plt.plot(x, y1, 'r', x, y2, 'r')
plt.fill_between(x, y1, y2, facecolor='red')
plt.savefig("heart.png")
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号