
先卖弄一些基础的知识:
表变量
变量都以@或@@为前缀,表变量是变量的一种,另外一种变量被称为标量(可以理解为标准变量,就是标准数据类型的变量,例如整型int或者日期型DateTime)。以@前缀的表变量是本地的,因此只有在当前用户会话中才可以访问,而@@前缀的表变量是全局的,通常都是系统变量,比如说@@error代表最近的一个T-SQL语句的报错号。当然因为表变量首先是个变量,因此它只能在一个Batch中生存,也就是我们所说的边界,超出了这个边界,表变量也就消亡了。
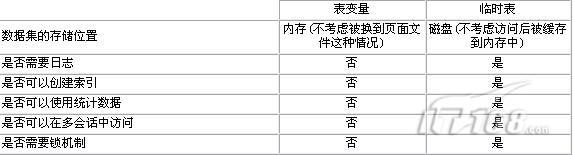
表变量存放在内存中,正是因为这一点所有用户访问表变量的时候SQL Server是不需要生成日志。同时变量是不需要考虑其他会话访问的问题,因此也不需要锁机制,对于非常繁忙的系统来说,避免锁的使用可以减少一部分系统负载。
表变量另外还有一个限制就是不能创建索引,当然也不存在统计数据的问题,因此在用户访问表变量的时候也就不存在执行计划选择的问题了(也就是以为着编译阶段后就没有优化阶段了),这一特性有的时候是件好事,而有些时候却会造成一些麻烦。
临时表
临时对象都以#或##为前缀,临时表是临时对象的一种,还有例如临时存储过程、临时函数之类的临时对象,临时对象都存储在tempdb中。以#前缀的临时表为本地的,因此只有在当前用户会话中才可以访问,而##前缀的临时表是全局的,因此所有用户会话都可以访问。临时表以会话为边界,只要创建临时表的会话没有结束,临时表就会持续存在,当然用户在会话中可以通过DROP TABLE命令提前销毁临时表。
我们前面说过临时表存储在tempdb中,因此临时表的访问是有可能造成物理IO的,当然在修改时也需要生成日志来确保一致性,同时锁机制也是不可缺少的。
跟表变量另外一个显著去别就是临时表可以创建索引,也可以定义统计数据,因此SQL Server在处理访问临时表的语句时需要考虑执行计划优化的问题。
表变量 vs. 临时表
结论
综上所述,大家会发现临时表和表变量在底层处理机制上是有很多差别的。
简单地总结,我们对于较小的临时计算用数据集推荐使用表变量。如果数据集比较大,如果在代码中用于临时计算,同时这种临时使用永远都是简单的全数据集扫描而不需要考虑什么优化,比如说没有分组或分组很少的聚合(比如说COUNT、SUM、AVERAGE、MAX等),也可以考虑使用表变量。使用表变量另外一个考虑因素是应用环境的内存压力,如果代码的运行实例很多,就要特别注意内存变量对内存的消耗。
一般对于大的数据集我们推荐使用临时表,同时创建索引,或者通过SQL Server的统计数据(Statisitcs)自动创建和维护功能来提供访问SQL语句的优化。如果需要在多个用户会话间交换数据,当然临时表就是唯一的选择了。需要提及的是,由于临时表存放在tempdb中,因此要注意tempdb的调优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号