阅读框架源码可以从官方代码的例子入手,对于Mapreduce我们可以从官方WordCount为例。源码目录结构如下:

进入WordCount代码:
`/**
- Licensed to the Apache Software Foundation (ASF) under one
- or more contributor license agreements. See the NOTICE file
- distributed with this work for additional information
- regarding copyright ownership. The ASF licenses this file
- to you under the Apache License, Version 2.0 (the
- "License"); you may not use this file except in compliance
- with the License. You may obtain a copy of the License at
-
http://www.apache.org/licenses/LICENSE-2.0 - Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//job.waitForCompletion是提交任务,并且获取到进度信息
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
进入job.waitForCompletion方法/**
- Submit the job to the cluster and wait for it to finish.
- @param verbose print the progress to the user
- @return true if the job succeeded
- @throws IOException thrown if the communication with the
-
<code>JobTracker</code> is lost
/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}我们重点关注submit()方法,进入其内部: /*
- Submit the job to the cluster and return immediately.
- @throws IOException
/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
//确保任务是defined状态,public static enum JobState {DEFINE, RUNNING},枚举中定义了job的两种状态:defined,running
ensureState(JobState.DEFINE);
//使用新版API,新旧:旧主要都是定义的接口,现在都定义成普通和抽象类
setUseNewAPI();
//连接Yarn集群,在connect方法中声明了一个连接Yarn集群的客户端
/*- connect中有一个cluster成员变量,cluster初始化的时候会构建一个成员变量client,基于不同运行模式赋值:LocalJobRunner,YarnRunner
*/
connect();
//获取job提交器
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
//提交job
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}connect方法private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
//cluster就是指明运行模式,比如Yarn集群
if (cluster == null) {
//构造一个cluster对象,该对象成员变量有个client
cluster =
ugi.doAs(new PrivilegedExceptionAction() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}进入cluster的创建方法public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
//初始化时构造jobrunner
initialize(jobTrackAddr, conf);
}关注initialize方法private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
- connect中有一个cluster成员变量,cluster初始化的时候会构建一个成员变量client,基于不同运行模式赋值:LocalJobRunner,YarnRunner
initProviderList();
final IOException initEx = new IOException(
"Cannot initialize Cluster. Please check your configuration for "
+ MRConfig.FRAMEWORK_NAME
+ " and the correspond server addresses.");
if (jobTrackAddr != null) {
LOG.info(
"Initializing cluster for Job Tracker=" + jobTrackAddr.toString());
}
//相较于之前不再添加同步锁
/**
* ClientProtocolProvider是一个抽象类,主要是用来构建一个客户端请求协议,有两个实现类
* - LocalClientProtocolProvider
* -YarnClientProtocolProvider
*/
for (ClientProtocolProvider provider : providerList) {
LOG.debug("Trying ClientProtocolProvider : "
+ provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
//
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
//把构建出的clientProtocol赋值给cluster的成员变量client
client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName()
+ " as the ClientProtocolProvider");
break;
} else {
LOG.debug("Cannot pick " + provider.getClass().getName()
+ " as the ClientProtocolProvider - returned null protocol");
}
} catch (Exception e) {
final String errMsg = "Failed to use " + provider.getClass().getName()
+ " due to error: ";
initEx.addSuppressed(new IOException(errMsg, e));
LOG.info(errMsg, e);
}
}
if (null == clientProtocolProvider || null == client) {
throw initEx;
}
}关注submitter.submitJobInternal方法 /**
- Internal method for submitting jobs to the system.
-
The job submission process involves:
-
- Checking the input and output specifications of the job.
- Computing the {@link InputSplit}s for the job.
- Setup the requisite accounting information for the
- {@link DistributedCache} of the job, if necessary.
- Copying the job's jar and configuration to the map-reduce system
- directory on the distributed file-system.
- Submitting the job to the
JobTrackerand optionally - monitoring it's status.
- @param job the configuration to submit
- @param cluster the handle to the Cluster
- @throws ClassNotFoundException
- @throws InterruptedException
- @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
//校验输出目录
checkSpecs(job);
Configuration conf = job.getConfiguration();
//添加缓存
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
//生成任务id
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file.
//获取任务执行的队列
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
//真正提交任务步骤,我们关注YarnRunner的submitJob
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}进入submitJob方法 @Override
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
//提交任务到rs,进入submitapplication
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
}继续进入submitApplication方法,在YarnClient中 @Override
public ApplicationId
submitApplication(ApplicationSubmissionContext appContext)
throws YarnException, IOException {
ApplicationId applicationId = appContext.getApplicationId();
if (applicationId == null) {
throw new ApplicationIdNotProvidedException(
"ApplicationId is not provided in ApplicationSubmissionContext");
}
SubmitApplicationRequest request =
Records.newRecord(SubmitApplicationRequest.class);
request.setApplicationSubmissionContext(appContext);
// Automatically add the timeline DT into the CLC
// Only when the security and the timeline service are both enabled
if (isSecurityEnabled() && timelineV1ServiceEnabled) {
addTimelineDelegationToken(appContext.getAMContainerSpec());
}
//TODO: YARN-1763:Handle RM failovers during the submitApplication call.
rmClient.submitApplication(request);
int pollCount = 0;
long startTime = System.currentTimeMillis();
EnumSet<YarnApplicationState> waitingStates =
EnumSet.of(YarnApplicationState.NEW,
YarnApplicationState.NEW_SAVING,
YarnApplicationState.SUBMITTED);
EnumSet<YarnApplicationState> failToSubmitStates =
EnumSet.of(YarnApplicationState.FAILED,
YarnApplicationState.KILLED);
while (true) {
/**
* TODO 提交任务到这基本OK
* * 所谓提交任务,其实就是RM的一个客户端代理对象,给RM发送了一个事件,告诉RM 我 提交了一个应用程序
* * 这个事件当中,会包含很多信息: jobid submitDir
* * 整个任务提交接下来就是yarn的事情了,剩下的事情比较复杂,也超出了我的能力范围,但是不妨碍我们理解啊的提交流程
*/
try {
ApplicationReport appReport = getApplicationReport(applicationId);
YarnApplicationState state = appReport.getYarnApplicationState();
if (!waitingStates.contains(state)) {
if(failToSubmitStates.contains(state)) {
throw new YarnException("Failed to submit " + applicationId +
" to YARN : " + appReport.getDiagnostics());
}
LOG.info("Submitted application " + applicationId);
break;
}
long elapsedMillis = System.currentTimeMillis() - startTime;
if (enforceAsyncAPITimeout() &&
elapsedMillis >= asyncApiPollTimeoutMillis) {
throw new YarnException("Timed out while waiting for application " +
applicationId + " to be submitted successfully");
}
// Notify the client through the log every 10 poll, in case the client
// is blocked here too long.
if (++pollCount % 10 == 0) {
LOG.info("Application submission is not finished, " +
"submitted application " + applicationId +
" is still in " + state);
}
try {
Thread.sleep(submitPollIntervalMillis);
} catch (InterruptedException ie) {
String msg = "Interrupted while waiting for application "
+ applicationId + " to be successfully submitted.";
LOG.error(msg);
throw new YarnException(msg, ie);
}
} catch (ApplicationNotFoundException ex) {
// FailOver or RM restart happens before RMStateStore saves
// ApplicationState
LOG.info("Re-submit application " + applicationId + "with the " +
"same ApplicationSubmissionContext");
rmClient.submitApplication(request);
}
}
return applicationId;
}`
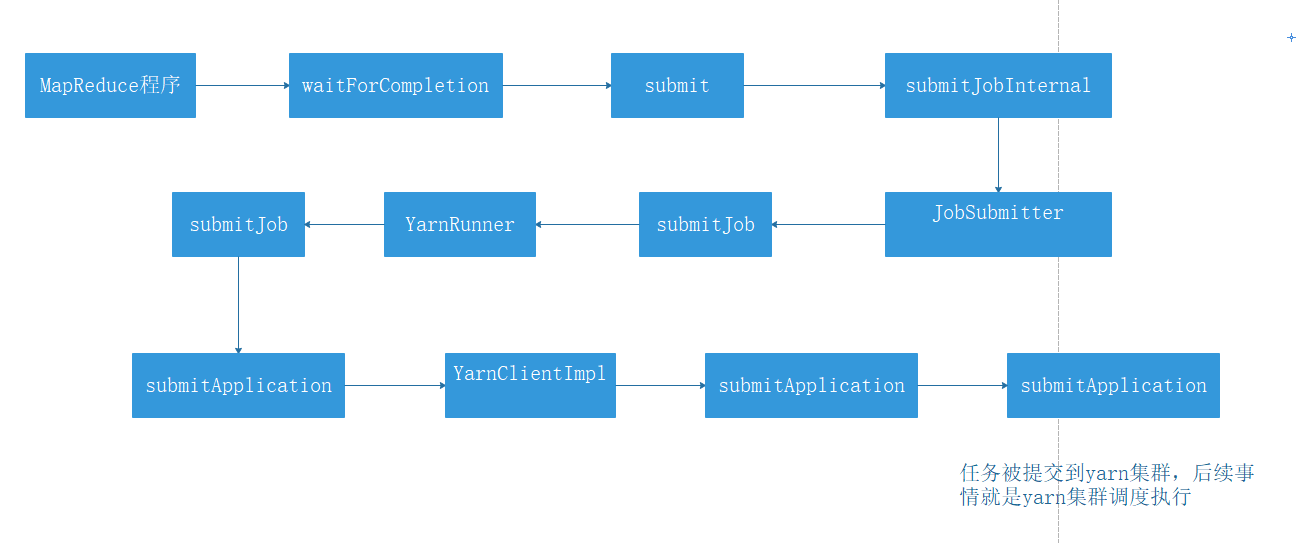
至此,整个提交流程到Yarn已经完成,其余的工作则交由Yarn完成,任务提交大致流程